文本转语音工具 html版
文本转语音工具 Html版 和 Python tkinter 版
·
html版
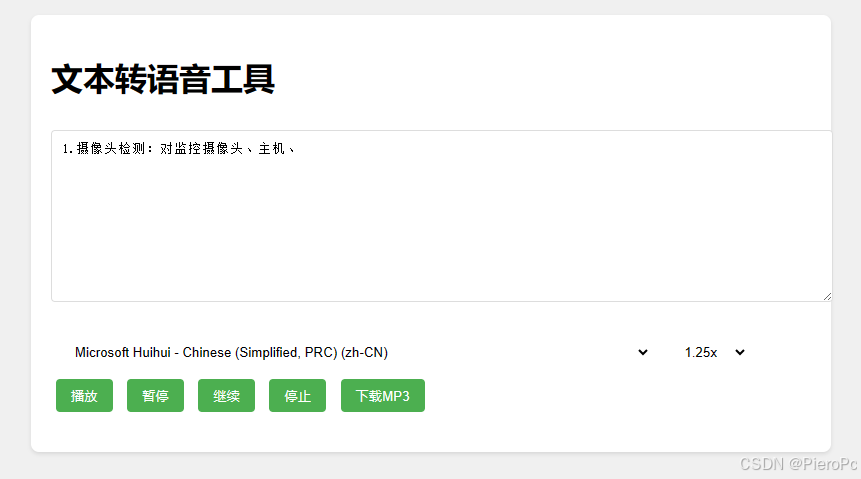
html + js 代码:
注意事项:
1. 由于浏览器安全限制,此功能需要在支持 HTTPS 的环境下运行
2. 某些浏览器可能需要用户授予录音权限
3. 音频质量可能不如专业录音软件
4. 下载的文件格式实际上是基于浏览器支持的音频格式(可能是 mp3 或 wav)
使用方法:
1. 输入要转换的文本
2. 选择语音和语速
3. 点击"下载MP3"按钮
4. 等待语音播放完成后,文件会自动下载
只显示中文语音在下拉菜单中
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>文本转语音工具</title>
<style>
body {
font-family: Arial, sans-serif;
max-width: 800px;
margin: 0 auto;
padding: 20px;
background-color: #f0f0f0;
}
.container {
background-color: white;
padding: 20px;
border-radius: 8px;
box-shadow: 0 2px 4px rgba(0, 0, 0, 0.1);
}
textarea {
width: 100%;
height: 150px;
margin: 10px 0;
padding: 10px;
border: 1px solid #ddd;
border-radius: 4px;
resize: vertical;
}
.controls {
margin: 15px 0;
}
select, button {
padding: 8px 15px;
margin: 5px;
border: none;
border-radius: 4px;
cursor: pointer;
}
button {
background-color: #4CAF50;
color: white;
}
button:hover {
background-color: #45a049;
}
button:disabled {
background-color: #cccccc;
cursor: not-allowed;
}
</style>
</head>
<body>
<div class="container">
<h1>文本转语音工具</h1>
<textarea id="text-input" placeholder="请输入要转换的文本..."></textarea>
<div class="controls">
<select id="voice-select">
<option value="">加载中...</option>
</select>
<select id="rate">
<option value="0.5">0.5x</option>
<option value="0.75">0.75x</option>
<option value="1" selected>1x</option>
<option value="1.25">1.25x</option>
<option value="1.5">1.5x</option>
<option value="2">2x</option>
</select>
<button id="speak-btn">播放</button>
<button id="pause-btn">暂停</button>
<button id="resume-btn">继续</button>
<button id="stop-btn">停止</button>
<button id="download-btn">下载MP3</button>
</div>
</div>
<script>
const textInput = document.getElementById('text-input');
const voiceSelect = document.getElementById('voice-select');
const rateSelect = document.getElementById('rate');
const speakBtn = document.getElementById('speak-btn');
const pauseBtn = document.getElementById('pause-btn');
const resumeBtn = document.getElementById('resume-btn');
const stopBtn = document.getElementById('stop-btn');
const downloadBtn = document.getElementById('download-btn');
let mediaRecorder;
let audioChunks = [];
// 创建音频上下文和音频源
const audioContext = new (window.AudioContext || window.webkitAudioContext)();
const oscillator = audioContext.createOscillator();
const mediaStreamDestination = audioContext.createMediaStreamDestination();
// 初始化录音功能
function initializeRecorder() {
mediaRecorder = new MediaRecorder(mediaStreamDestination.stream);
mediaRecorder.ondataavailable = (event) => {
audioChunks.push(event.data);
};
mediaRecorder.onstop = () => {
const audioBlob = new Blob(audioChunks, { type: 'audio/mp3' });
const audioUrl = URL.createObjectURL(audioBlob);
const link = document.createElement('a');
link.href = audioUrl;
link.download = '语音文件.mp3';
link.click();
audioChunks = [];
};
}
// 初始化语音合成器
const synth = window.speechSynthesis;
let voices = [];
// 加载可用的语音
function loadVoices() {
voices = synth.getVoices();
// 只保留中文语音
const chineseVoices = voices.filter(voice =>
voice.lang.includes('zh') || // 匹配 zh-CN, zh-TW, zh-HK 等
voice.name.toLowerCase().includes('chinese') ||
voice.name.toLowerCase().includes('中文')
);
voiceSelect.innerHTML = chineseVoices
.map(voice => `<option value="${voice.name}">${voice.name} (${voice.lang})</option>`)
.join('');
// 如果没有找到中文语音,显示提示
if (chineseVoices.length === 0) {
voiceSelect.innerHTML = '<option value="">未找到中文语音</option>';
}
}
// 某些浏览器需要等待voices加载完成
speechSynthesis.onvoiceschanged = loadVoices;
// 播放功能
function speak() {
if (synth.speaking) {
synth.cancel();
}
const text = textInput.value;
if (text) {
const utterance = new SpeechSynthesisUtterance(text);
utterance.voice = voices.find(voice => voice.name === voiceSelect.value);
utterance.rate = parseFloat(rateSelect.value);
// 开始录音
audioChunks = [];
try {
mediaRecorder.start();
} catch (e) {
initializeRecorder();
mediaRecorder.start();
}
utterance.onend = () => {
// 停止录音
if (mediaRecorder && mediaRecorder.state === 'recording') {
mediaRecorder.stop();
}
};
synth.speak(utterance);
}
}
// 下载按钮事件
downloadBtn.addEventListener('click', () => {
if (!textInput.value) {
alert('请先输入要转换的文本!');
return;
}
speak();
});
// 事件监听
speakBtn.addEventListener('click', speak);
pauseBtn.addEventListener('click', () => synth.pause());
resumeBtn.addEventListener('click', () => synth.resume());
stopBtn.addEventListener('click', () => synth.cancel());
// 初始加载语音
loadVoices();
// 初始化录音器
initializeRecorder();
</script>
</body>
</html>
Python tkinter 版
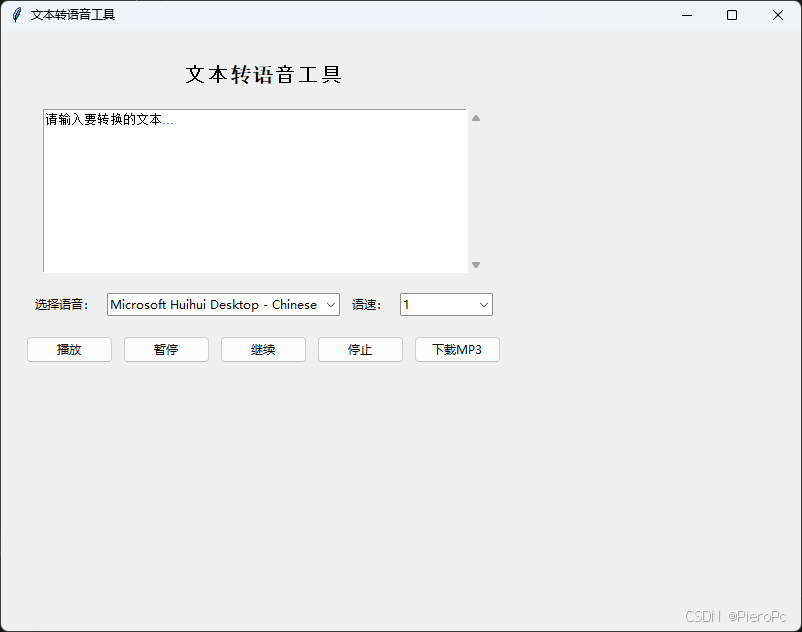
python 代码:
import tkinter as tk
from tkinter import ttk, scrolledtext, filedialog, messagebox
import pyttsx3
from threading import Thread
import tempfile
import os
import shutil
class TextToSpeechApp:
def __init__(self, root):
self.root = root
self.root.title("文本转语音工具")
self.root.geometry("800x600")
# 初始化语音引擎
self.engine = pyttsx3.init()
self.voices = self.engine.getProperty('voices')
# 创建主容器
main_frame = ttk.Frame(root, padding="20")
main_frame.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
# 标题
title_label = ttk.Label(main_frame, text="文本转语音工具", font=('Arial', 16, 'bold'))
title_label.grid(row=0, column=0, columnspan=2, pady=10)
# 文本输入区
self.text_input = scrolledtext.ScrolledText(
main_frame,
width=60,
height=10,
wrap=tk.WORD,
font=('Arial', 10)
)
self.text_input.grid(row=1, column=0, columnspan=2, pady=10)
self.text_input.insert('1.0', '请输入要转换的文本...')
# 控制区域
controls_frame = ttk.Frame(main_frame)
controls_frame.grid(row=2, column=0, columnspan=2, pady=10)
# 语音选择
ttk.Label(controls_frame, text="选择语音:").grid(row=0, column=0, padx=5)
self.voice_var = tk.StringVar()
self.voice_select = ttk.Combobox(
controls_frame,
textvariable=self.voice_var,
state='readonly',
width=30
)
self.voice_select.grid(row=0, column=1, padx=5)
# 语速选择
ttk.Label(controls_frame, text="语速:").grid(row=0, column=2, padx=5)
self.rate_var = tk.StringVar(value='1')
rate_select = ttk.Combobox(
controls_frame,
textvariable=self.rate_var,
values=['0.5', '0.75', '1', '1.25', '1.5', '2'],
state='readonly',
width=10
)
rate_select.grid(row=0, column=3, padx=5)
# 按钮区域
buttons_frame = ttk.Frame(main_frame)
buttons_frame.grid(row=3, column=0, columnspan=2, pady=10)
# 创建按钮
ttk.Button(buttons_frame, text="播放", command=self.speak).grid(row=0, column=0, padx=5)
ttk.Button(buttons_frame, text="暂停", command=self.pause).grid(row=0, column=1, padx=5)
ttk.Button(buttons_frame, text="继续", command=self.resume).grid(row=0, column=2, padx=5)
ttk.Button(buttons_frame, text="停止", command=self.stop).grid(row=0, column=3, padx=5)
ttk.Button(buttons_frame, text="下载MP3", command=self.save_to_file).grid(row=0, column=4, padx=5)
# 初始化语音列表
self.load_voices()
def load_voices(self):
# 获取所有语音
voice_names = []
for voice in self.voices:
# 添加语音名称和语言信息
voice_info = f"{voice.name} ({voice.languages[0] if voice.languages else voice.id})"
voice_names.append(voice_info)
if not voice_names:
voice_names = ['未找到可用语音']
self.voice_select['values'] = voice_names
self.voice_select.set(voice_names[0] if voice_names else '')
def speak(self):
text = self.text_input.get('1.0', tk.END).strip()
if text:
self.stop() # 停止当前播放
# 从选择的语音信息中提取语音名称
voice_info = self.voice_var.get()
voice_name = voice_info.split(' (')[0] # 获取括号前的名称部分
# 设置语音
for voice in self.voices:
if voice.name == voice_name:
self.engine.setProperty('voice', voice.id)
break
self.engine.setProperty('rate',
int(float(self.rate_var.get()) * 200))
# 在新线程中播放语音
Thread(target=self.engine.say, args=(text,), daemon=True).start()
Thread(target=self.engine.runAndWait, daemon=True).start()
def pause(self):
self.engine.pause()
def resume(self):
self.engine.resume()
def stop(self):
self.engine.stop()
def save_to_file(self):
text = self.text_input.get('1.0', tk.END).strip()
if text:
# 创建临时文件
temp_file = tempfile.mktemp(suffix='.mp3')
# 从选择的语音信息中提取语音名称
voice_info = self.voice_var.get()
voice_name = voice_info.split(' (')[0]
# 设置语音
for voice in self.voices:
if voice.name == voice_name:
self.engine.setProperty('voice', voice.id)
break
self.engine.setProperty('rate',
int(float(self.rate_var.get()) * 200))
# 保存为音频文件
self.engine.save_to_file(text, temp_file)
self.engine.runAndWait()
# 将临时文件移动到用户选择的位置
save_path = filedialog.asksaveasfilename(
defaultextension=".mp3",
filetypes=[("MP3 文件", "*.mp3")]
)
if save_path:
if os.path.exists(temp_file):
try:
# 使用shutil.copy2替代os.rename
shutil.copy2(temp_file, save_path)
# 复制完成后删除临时文件
os.remove(temp_file)
except Exception as e:
tk.messagebox.showerror("错误", f"保存文件时出错:{str(e)}")
if __name__ == '__main__':
root = tk.Tk()
app = TextToSpeechApp(root)
root.mainloop()

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)