Orpheus-TTS - 像真人一样自然逼真的语音合成系统 文本转语音,TTS 本地一键整合包下载
它能够生成自然、富有情感且接近人类水平的语音,具备零样本语音克隆能力,无需预训练即可模仿特定语音。超低延迟:Orpheus TTS的默认延迟约为200毫秒,通过优化输入流与模型的KV缓存,可以将延迟降低至25-50毫秒,完全满足实时对话的需求。零样本语音克隆:Orpheus TTS基于Llama-3b架构,具备零样本复刻任何人声的能力,无需预训练即可模仿特定语音。情感表达:该模型能够生成
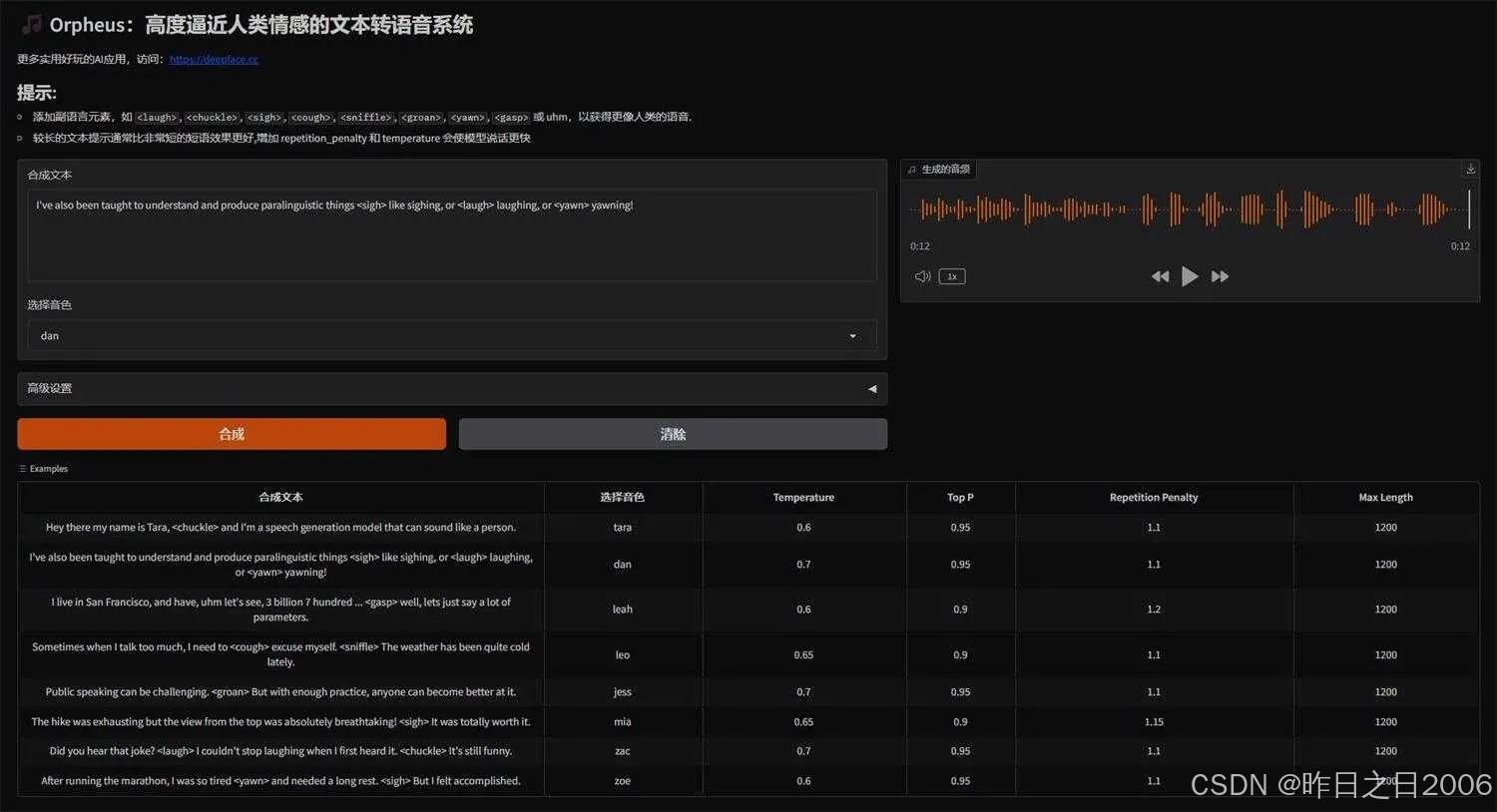
Orpheus TTS 是一款开源的文本转语音(TTS)模型,基于 Llama-3b 架构。它能够生成自然、富有情感且接近人类水平的语音,具备零样本语音克隆能力,无需预训练即可模仿特定语音。Orpheus TTS 的延迟低至约 200 毫秒,适合实时应用。该模型以其接近人类的情感表达、自然流畅的语音效果以及超低延迟的实时输出流特性而闻名。
主要特点和优势
超低延迟:Orpheus TTS的默认延迟约为200毫秒,通过优化输入流与模型的KV缓存,可以将延迟降低至25-50毫秒,完全满足实时对话的需求 。
情感表达:该模型能够生成自然、富有情感的语音,支持丰富的语调变化,能够细腻地捕捉人类的情感,显著提升用户的交互体验 。
实时输出流:支持流式音频生成,确保语音生成与输入信息同步,适用于虚拟助手、客户服务系统等需要即时响应的场景 。
零样本语音克隆:Orpheus TTS基于Llama-3b架构,具备零样本复刻任何人声的能力,无需预训练即可模仿特定语音 。
应用场景
智能语音助手:提供更人性化的交互体验。
在线教育平台:用于有声读物的生成和在线课程的语音指导。
虚拟主播和游戏角色配音:为虚拟人物提供自然流畅的声音。
实时对话应用:如客服系统和直播连麦等场景
使用教程:(建议N卡,显存8G起。基于CUDA12.4)
输入需要转换的文本(目前只支持英文),可以插入情感标签,比如 <laugh>, <chuckle>, <sigh>, <cough>, <sniffle>, <groan>, <yawn>, <gasp> 或 uhm,以获得更像人类的语音
选择音色,合成。
支持自定义模型训练,可以训练中文模型和指定音色,这个我还在研究,等跑通了再发教程。
下载地址:私信获取

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)