大语言模型---第六章 强化学习
奖励模型:通过为文本序列的最后一个标记分配标量奖励值,评估生成文本的质量。配对比较数据集:使用首选样本和非首选样本的配对比较数据集,训练奖励模型。损失函数:通过最小化损失函数,模型可以学习到如何区分高质量和低质量的生成文本。b.2)模仿学习:通过使用输入和期望输出的配对数据,模型可以学习从输入到输出的映射。损失函数:结合了奖励模型损失和自回归语言模型损失,通过最小化损失函数,模型可以同时提高区分能
综述:通过有监督微调,大语言模型已经初步具备了服从人类指令,并完成各类型的任务能力。有监督微调通常采用交叉熵损失作为损失函数,目标是调整参数使用模型输出与标准答案完全相同,不能从整体上对模型输出质量进行判断。
为了解决模型不能适用自然语言多样性,和微小变化的敏感问题,强化学习则将模型速出文本作为一个整体考虑,模型通过生成回复并接收反馈进行学习。
主要内容
-->基于类人反馈的强化学习基础概念,
-->奖励模型,
-->近端策略优化方法,
-->面向大语言模型强化学习的PPO-Max框架实践
1)基于人类反馈的强化学习
a)概述
强化学习(Reinforcement Learning,RL)研究的问题是智能体(Agent)与环境(Environment)交互的问题,其目标是使智能体在复杂且不确定的环境中最大化奖励(Reward)。
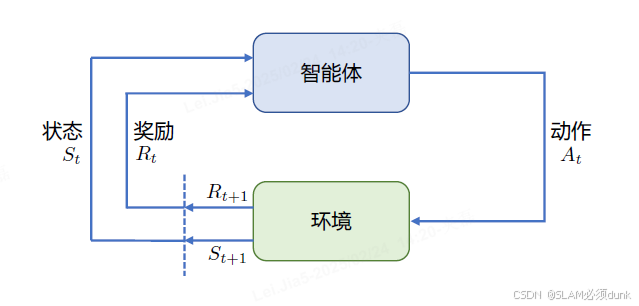
强化学习基本概念:
(1)智能体和环境:环境会根据智能体的行为反馈,通常以奖励的形式
(2)状态,行为与奖励:评估当前状态,采取什么样子的行为,获得什么样子奖励
(3)策略与价值:策略是一套指导其如何在特定状态下行动的规则,并预测在未来采取某一行为所带来的奖励
o1,a1,r1,...,ot,at,rt定义历史Ht是观测,动作,奖励的序列
环境状态St看作关于历史的函数:
随机性策略: =
,输入一个状态s,输出一个频率,表示智能体所有动作的概率
确定性策略:即智能体直接采取最优可能的动作 即a* =
价值函数的值是对未来奖励的预测,可以用它来评估状态的好坏
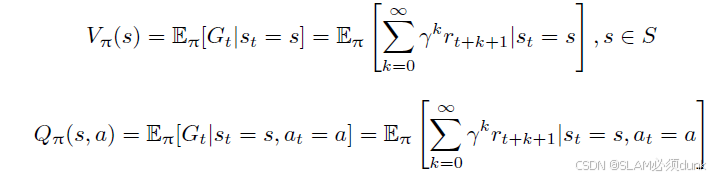
为折扣因子,针对短期奖励和远期奖励进行折中,期望
的下标为
函数,其值反映在使用策略
时所能获得奖励值。
智能体:基于价值的智能体、基于策略的智能体和演员-评论员智能体
--基于价值的智能体(Value-based Agent)显式地学习价值函数,隐式地学习策略。其策略是从所学到的价值函数推算得到的。
--基于策略的智能体(Policy-based Agent)则是直接学习策略函数。策略函数的输入为一个状态,输出为对应动作的概率,并不学习价值函数,价值函数隐式的表达在策略函数中。
--演员-评论员智能体(Actor-critic Agent)则是把基于价值的智能体和基于策略的智能体结合起来,既学习策略函数又学习价值函数都,通过两者的交互得到最佳的动作。
b)强化学习与有监督学习的区别
-
有监督学习:从标注数据中学习输入与输出的映射关系,适用于分类、回归等任务。
-
强化学习:通过与环境的交互,学习最优的决策策略,适用于决策和控制任务。
强化学习重要性:
(1)强化学习比有监督学习更可以考虑整体影响
(2)强化学习更容易解决幻觉问题
(3)强化学习可以更好的解决多轮对话奖励累积问题
有监督学习:像老师教学生,有明确的“输入”和“正确答案”,目标是让模型预测得尽量准确。
强化学习:像训练宠物,没有明确的“正确答案”,模型通过试错和奖励机制,学会如何做出最佳决策。
C)基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)
RLHF输出结果具有3H(Helpfulness,Honesty,Harmless)
俩个步骤,奖励模型和近端策略优化
-->奖励模型通过由人类反馈标注的偏好数据来学习人类的偏好,判断模型回复的有用性以及保证内容的无害性
-->PPO(Proximal Policy Optimization)近端策略优化可以根据奖励模型获得的反馈优化模型,通过不断的迭代,让模型探索和发现更符合人类偏好的回复策略
-->策略模型(PolicyModel)生成模型回复
-->奖励模型(RewardModel)输出奖励分数评估回复质量的好坏
-->评论模型(CriticModel)来预测回复的好坏,可以在训练过程中实时调整模型,选择对未来累积收益最大的行为
-->参考模型(Reference Model)提供了SFT模型的备份,帮助模型不会出现过于极端的变化
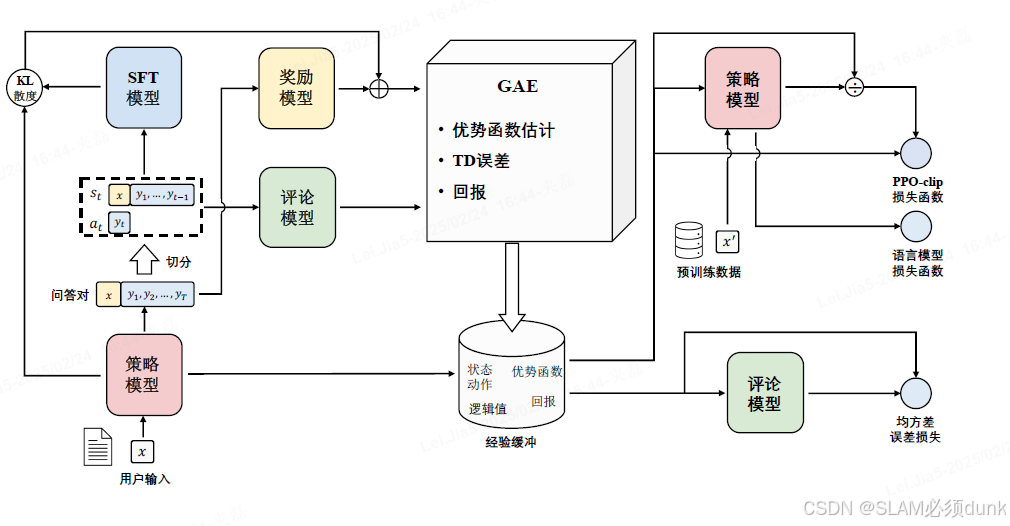
步骤:
a) 环境采样 b)优势估计 c)优化调整
2)奖励模型
模拟人类评估过程,决定了智能体如何从与环境的交互中学习并优化策略,以实现预定的任务目标。
a)数据收集
-->有用性:能够从少量的示例提示或其他可解释的模式中推断出意图
-->无害性:在数据收集过程中,让标注人员通过一些敌对性的询问,比如计划抢银行,引诱模型给出一些违背规则的有害性回答。
Anthropic 的数据收集:
(1) 标注者向模型写聊天消息,要求它们执行任务、回答问题,或者讨论感兴趣的话题。
(2) 标注者看到两种不同的回答,并被要求选择更有帮助和真实的回答(或者在无害性测试情况
下,选择更有害的回答)包含chosen和rejected
b)模型训练
奖励模型是一个用来评估某个行为或结果好坏的模型。你可以把它想象成一个“打分器”,它根据一些标准给不同的行为或结果打分,分数越高表示越好。
举个例子
假设你在训练一个聊天机器人,目标是让它生成有用的回答。你可以用奖励模型来评估它的回答质量。比如:
-
好的回答:准确回答了问题,用户满意,奖励模型会给高分。
-
不好的回答:答非所问,用户不满意,奖励模型会给低分。
如何训练奖励模型?
训练奖励模型通常分为以下几个步骤:
-
收集数据:
-
你需要一些带标签的数据,比如人类对聊天机器人回答的评分(1到5分)。
-
例如:
-
问题:“如何煮鸡蛋?”
-
回答:“把鸡蛋放进沸水煮8分钟。” → 人类评分:5分
-
回答:“鸡蛋可以炒着吃。” → 人类评分:2分
-
-
-
设计模型:
-
选择一个模型(如神经网络),输入是问题和回答,输出是一个分数。
-
-
训练模型:
-
用收集到的数据训练模型,目标是让模型预测的分数尽量接近人类的评分。
-
例如:
-
输入:“如何煮鸡蛋?”和“把鸡蛋放进沸水煮8分钟。” → 模型输出:4.8分(接近人类给的5分)
-
输入:“如何煮鸡蛋?”和“鸡蛋可以炒着吃。” → 模型输出:2.3分(接近人类给的2分)
-
-
-
测试和调整:
-
用新数据测试模型,看看它的打分是否合理。如果不行,调整模型或数据。
-
b.1)
采用transformer架构的预训练语言模型,在奖励模型中,移除最后一个非嵌入层,并在最终的Tranformer层上叠加了一个额外的线性层。无论输入的是何种文本,奖励模型都能为文本序列中的最后一个标记分配一个标量奖励值,样本质量高,奖励值越大。

总结
-
奖励模型:通过为文本序列的最后一个标记分配标量奖励值,评估生成文本的质量。
-
配对比较数据集:使用首选样本和非首选样本的配对比较数据集,训练奖励模型。
-
损失函数:通过最小化损失函数,模型可以学习到如何区分高质量和低质量的生成文本。
b.2)

损失函数由2部分组成:对比损失项 + 语言模型正则化项
对比损失项: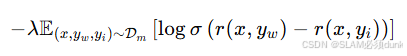
对于同一个输入x,首选样本yw的奖励值r(x,yw)大约非首选样本yi的奖励值r(x,yi),通过sigmod函数蒋奖励值的差映射到(0,1)区间,然后取对数并求期望,使得模型更倾向于让首选样本的奖励高于非首选样本
语言正则化项: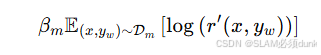
结合了自回归语言模型对首选样本的奖励值r’(x,yw),通过取对数并求期望,鼓励奖励模型的输出与语言模型奖励值保持一致,有助于在优化奖励模型时,保持其与语言模型生成特性的兼容性
-
模仿学习:通过使用输入和期望输出的配对数据,模型可以学习从输入到输出的映射。
-
损失函数:结合了奖励模型损失和自回归语言模型损失,通过最小化损失函数,模型可以同时提高区分能力和生成能力,需要调整系数
和
m,可以平衡对比损失和语言模型正则化之间的贡献,从而在不同的任务和数据集上达到最佳的训练结果。
b.3)引入一个附加项到奖励函

总结
-
KL 散度:通过引入 KL 散度项,可以在强化学习中引入一种惩罚机制,防止策略过早地收敛到局部最优解,同时保持与初始监督模型的一致性。
-
总奖励:总奖励由原始奖励和 KL 散度项组成,通过调整 KL 奖励系数 η,可以控制 KL 惩罚的强度。
-
作用:KL 散度项作为一个熵奖励,促进了策略空间中的探索,避免了策略过早地收敛到单一模式,同时确保了学习过程的稳定性和一致性。
c)开源数据
WebGPT,HH-RLHF,Stanford Human Preferences(SHP)
3)近端策略优化
PPO是对强化学习中策略梯度方法的改进,可以解决传统的策略梯度方法中存在的高方差,低数据效率,易发散等问题,从而提高了强化学习算法的可靠性和适用性。
a)策略梯度
演员(Actor),环境和奖励函数
演员可以采取各种可能动作与环境交互,在交互的过程中环境会依据当前环境的状态和演员的动作给出相应的奖励(reward)并修改自身状态。演员的目的就是自愈调整策略(policy),即根据环境信息决定采取什么动作以最大化奖励。
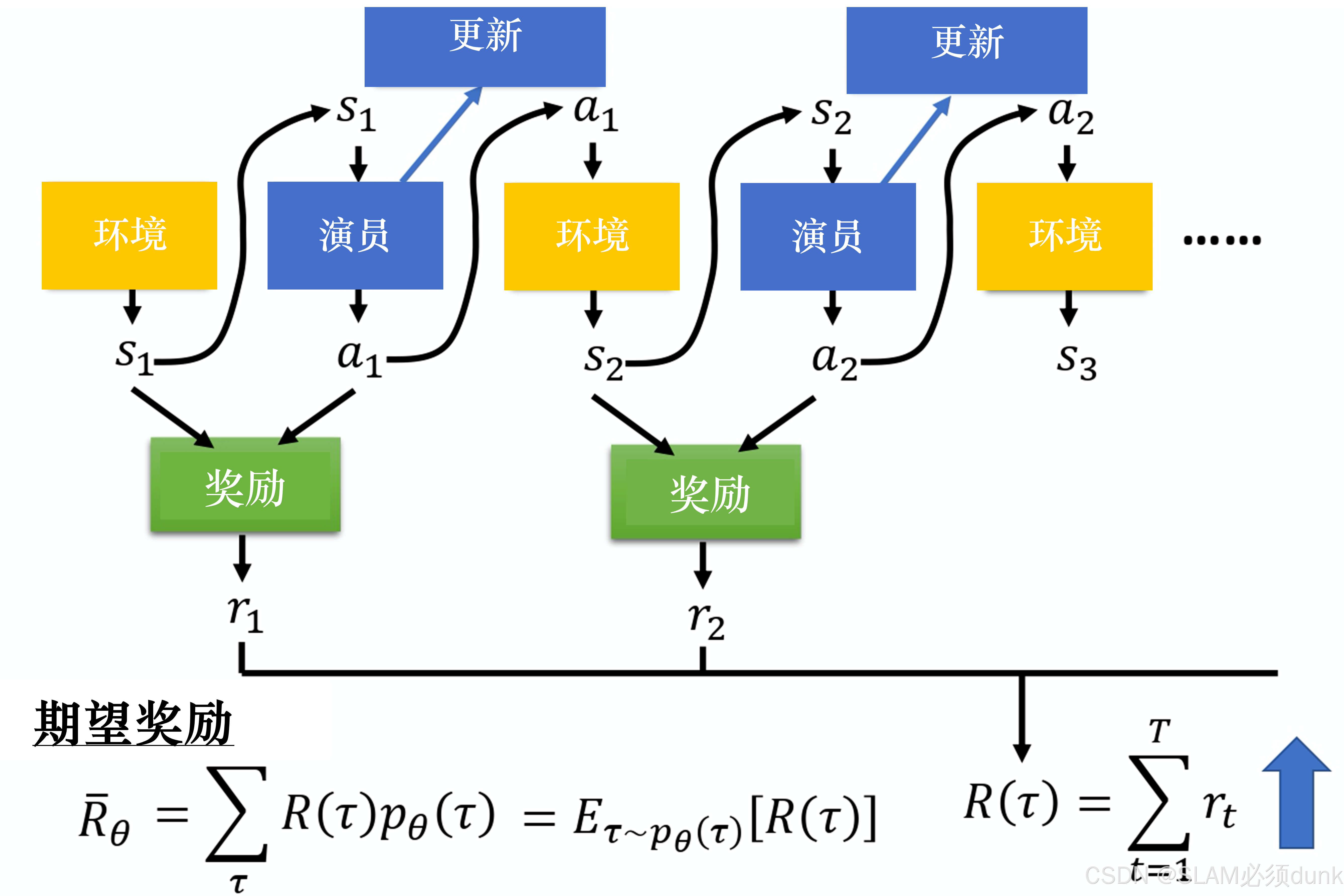
其中是初始状态s1发生的概率,
为给定状态st策略函数采取动作at的概率,
为给定当前状态st和动作at,环境转移到状态st+1的概率
给定轨迹,累计奖励为
累计奖励称为回报(return),回报并非是一个标量值,因为演员采取哪一个动作以及环境转移到哪一个状态均以概率形式发生,因为轨迹
和对应回报
均为随机变量,只能计算回报期望:
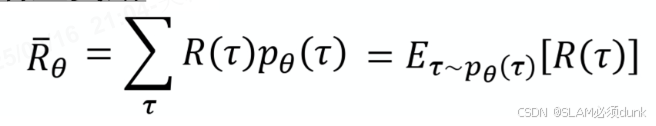
其中表示使用参数为
的策略与环境交互的期望回报,轨迹
服从
的概率分布
给定一条轨迹,回报总是固定的,因此智能调整策略函数使得高回报的轨迹发生概率尽可能大,而低回报的轨迹发生概率尽可能小。为了优化参数
,可以使用梯度上升方法,优化
使得期望回报
尽可能大:
b)广义优势估计
c)近端策略优化

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)