从零开始搭建智能客服 Agent 系统,大模型入门到精通,收藏这篇就足够了!
知识库是智能客服系统的"大脑",高效的知识检索和管理直接影响响应质量。这里我们实现一个基于向量数据库的知识库系统。
系统架构概览
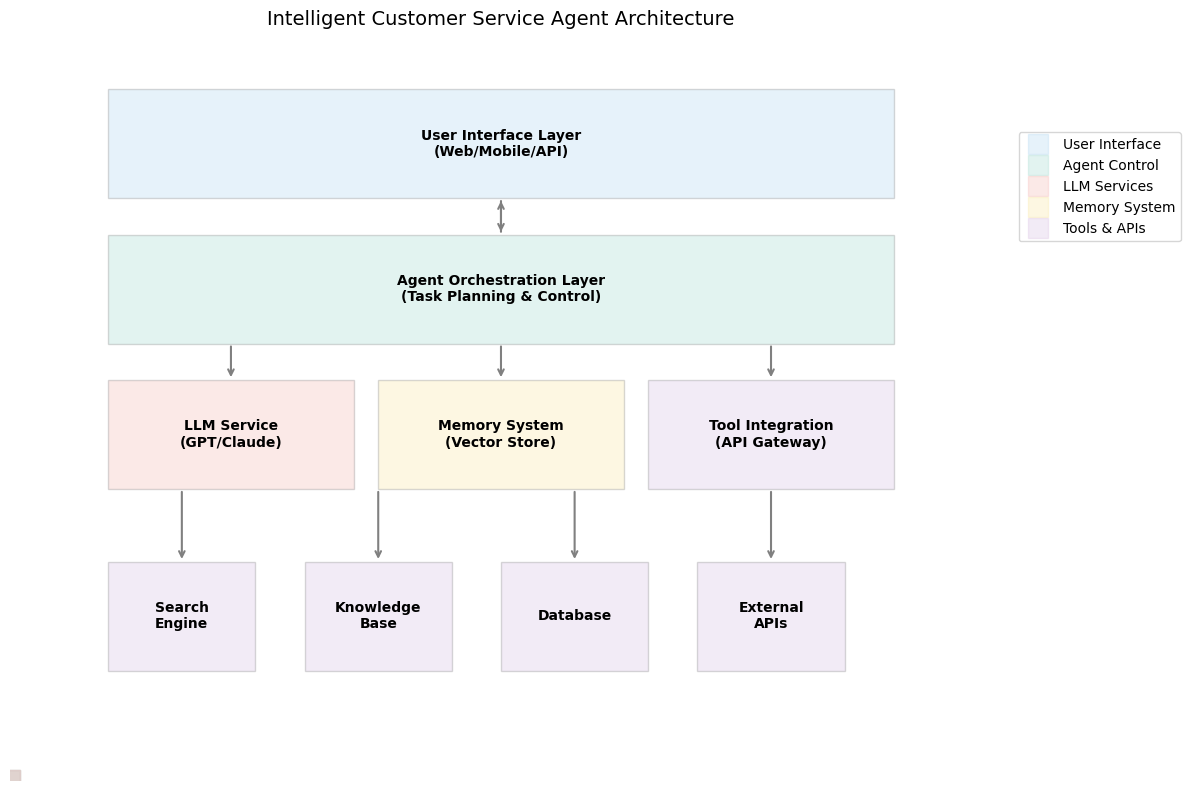
1. 多轮对话管理设计
多轮对话管理是智能客服系统的核心,良好的对话管理可以让系统"记住"上下文,提供连贯的对话体验。
fromimportDictListOptionalfromimportfromimport@dataclassclassDialogueContextstrstrListDictOptionalstrNoneDictNonefloat0.0classDialogueManagerdef__init__self, llm_service, knowledge_baseDictstrasyncdefhandle_messageself, session_id:
str
, message:
strstrstrstr"""处理用户消息"""# 获取或创建会话上下文# 更新对话历史"role""user""content""timestamp"# 意图识别await# 实体提取await# 情绪分析await# 生成响应await# 更新对话历史"role""assistant""content""timestamp"returnasyncdef_identify_intentself, message:
str
, context: DialogueContextstrstr"""意图识别"""f"""
对话历史:
{context.conversation_history[-
3
:]}
当前用户消息:
{message}
请识别用户意图,可能的意图包括:
- inquiry_product: 产品咨询
- technical_support: 技术支持
- complaint: 投诉
- general_chat: 闲聊
- other: 其他
仅返回意图标识符。
"""{context.conversation_history[-
3
:]}3{message}returnawait
💡 实践小贴士
- 对话历史建议只保留最近3-5轮对话,这样可以提供足够的上下文同时避免提示词过长
- 实体提取结果缓存可以提高系统响应速度
- 情绪分析结果可以用于动态调整响应策略
- 定期清理过期会话可以优化内存使用
⚠️ 常见陷阱
- 过度依赖历史上下文可能导致对话偏离主题
- 实体提取规则过于严格可能遗漏重要信息
- 情绪分析不应过度影响系统的专业性
- 会话状态管理需要考虑并发安全
2. 知识库集成方案
知识库是智能客服系统的"大脑",高效的知识检索和管理直接影响响应质量。这里我们实现一个基于向量数据库的知识库系统。
fromimportListTupleimportimportasclassKnowledgeBasedef__init__self, embedding_model384# 向量维度asyncdefadd_documentself, document:
strstr"""添加文档到知识库"""# 文档分块# 生成向量嵌入await# 添加到索引asyncdefsearchself, query:
str
, top_k:
int
=
3strint3ListTuplestrfloat"""搜索相关文档"""# 生成查询向量await# 执行向量搜索# 返回结果floatforinzip00returndef_split_documentself, document:
strstrListstr"""文档分块策略"""# 实现文档分块逻辑# ... 分块逻辑 ...return
💡 优化建议
- 文档分块时考虑语义完整性,不要机械地按字数切分
- 向量索引可以使用 IVF 或 HNSW 等算法提升检索效率
- 实现定期重建索引机制,优化向量分布
- 考虑引入文档版本控制,支持知识的更新和回滚
🔧 性能调优
- 批量生成向量嵌入,减少模型调用次数
- 使用异步操作处理 I/O 密集任务
- 实现智能缓存策略,提高热点知识的访问速度
- 定期清理过期缓存和文档,优化内存使用
⚠️ 注意事项
- 向量维度要与模型输出保持一致
- 大规模知识库考虑分片存储
- 定期备份知识库数据
- 监控索引质量和检索性能
3. 情绪识别与处理
准确的情绪识别和恰当的情绪处理是智能客服系统的重要差异化能力。这里我们实现一个综合的情绪管理系统。
classEmotionHandlerdef__init__self, llm_service"anger"0.7"frustration"0.6"satisfaction"0.8asyncdefanalyze_emotionself, message:
strstrDictstrfloat"""分析用户情绪"""f"""
用户消息:
{message}
请分析用户情绪,返回以下情绪的概率值(0-1):
- anger: 愤怒
- frustration: 沮丧
- satisfaction: 满意
"""{message}awaitreturnasyncdefgenerate_emotional_response
self,
message:
str
,
emotion_scores:
Dict
[
str
,
float
],
base_response:
str
strDictstrfloatstrstr"""生成情绪适应的回复"""if"anger""anger"returnawaitelif"frustration""frustration"returnawaitelsereturnasyncdef_handle_angry_customerself, base_response:
strstrstr"""处理愤怒情绪"""f"""
原始回复:
{base_response}
用户当前情绪愤怒,请调整回复语气,要:
1. 表示理解和歉意
2. 明确解决方案
3. 语气诚恳平和
"""{base_response}returnawait
💡 最佳实践
- 情绪分析要结合上下文,不要孤立判断单条消息
- 对高风险情绪(如愤怒)建立快速响应机制
- 设置情绪升级阈值,及时转人工服务
- 保存情绪分析日志,用于系统优化
🎯 优化方向
- 引入多模态情绪识别(文本+语音+表情)
- 建立个性化情绪基线,提高识别准确度
- 优化响应策略的动态调整机制
- 增加情绪预测能力,提前干预
⚠️ 常见问题
- 过度依赖单一情绪标签
- 忽视文化差异对情绪表达的影响
- 机械式的情绪响应模板
- 未及时识别情绪升级信号
4. 性能优化实践
智能客服系统的性能直接影响用户体验,这里我们从多个维度实现系统优化。
classPerformanceOptimizerdef__init__self10005000asyncdefoptimize_response_generation
self,
context: DialogueContext,
knowledge_base: KnowledgeBase
str"""优化响应生成过程"""# 1. 缓存查找ifreturn# 2. 批量处理ifreturnawait# 3. 并行处理await# 4. 生成最终响应await# 5. 更新缓存setreturn
💡 性能优化要点
- 采用多级缓存策略,减少重复计算
- 实现智能预加载,提前准备高概率请求的响应
- 使用异步编程和协程,提高并发处理能力
- 建立完整的监控和告警体系
🔍 监控指标
- 平均响应时间(P95、P99)
- CPU和内存使用率
- 并发请求数
- 错误率和异常分布
- 缓存命中率
- Token使用量
⚡ 性能提升技巧
- 使用连接池复用数据库连接
- 实现请求合并(Request Batching)
- 采用渐进式加载策略
- 优化数据序列化方式
- 实现智能负载均衡
实战经验总结
-
系统设计原则
- 模块化设计,便于扩展
- 关注性能和可伸缩性
- 重视监控和运维
- 持续优化和迭代
-
常见挑战及解决方案
- 多轮对话上下文管理
- 知识库实时更新
- 高并发处理
- 情绪识别准确性
-
性能优化技巧
- 合理使用缓存
- 批量处理请求
- 异步并行处理
- 资源动态扩缩容
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 4
4 0
0- 0



 已为社区贡献135条内容
已为社区贡献135条内容

所有评论(0)