【论文阅读07】-大语言模型在复杂设备故障诊断的应用
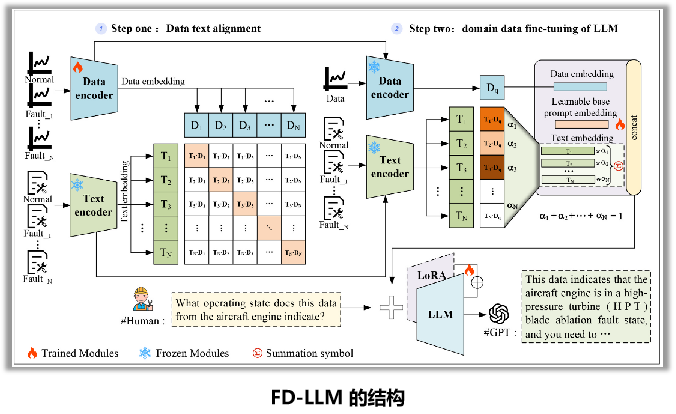
大模型故障诊断微调:冻结数据编码器和LLM主干网络,仅使用LoRA等技术微调少量参数,使LLM学会根据对齐后的数据嵌入进行故障诊断推理。数据-文本模态对齐: 训练一个数据编码器,使其能够将工程数据编码成与LLM文本特征空间对齐的嵌入向量,让LLM能“读懂”传感器信号。: 由两个网络组成,一个“伪造者”网络生成假数据,一个“鉴别者”网络鉴别真伪,两者相互博弈,最终使“伪造者”能生成非常逼真的数据
😊文章背景
题目:FD-LLM: Large language model for fault diagnosis of complex equipment
期刊:《Advanced Engineering Informatics》
检索情况:IF 9.9 工程技术TOP EI检索 SCI升级版工程技术1区 SCI基础版工程技术2区 SWITU A+
作者:Lin Lin , Sihao Zhang *, Song Fu *, Yikun Liu
单位:哈尔滨工业大学
发表年份:2025年
网址:https://www.sciencedirect.com/science/article/pii/S1474034625001016
❓ 研究问题
工业故障诊断领域面临的痛点:
- “一场景一模型”的局限:传统深度学习模型(CNN, LSTM等)泛化能力差,换一个设备或工况就需要重新训练,费时费力。
- 对“模式混叠”故障束手无策:当不同故障的特征非常相似时,传统模型容易误判,因为它只能进行“非黑即白”的硬分类。
- 大语言模型的“知识壁垒”:多模态大语言模型无法直接理解振动、温度等工程时间序列数据,缺乏工业领域的“常识”。
📌 研究目标
提出FD-LLM框架,实现一个通用、精准、可解释的智能诊断模型。
🧠 所用方法
FD-LLM整体框架
数据-文本模态对齐: 训练一个数据编码器,使其能够将工程数据编码成与LLM文本特征空间对齐的嵌入向量,让LLM能“读懂”传感器信号。
大模型故障诊断微调:冻结数据编码器和LLM主干网络,仅使用LoRA等技术微调少量参数,使LLM学会根据对齐后的数据嵌入进行故障诊断推理。
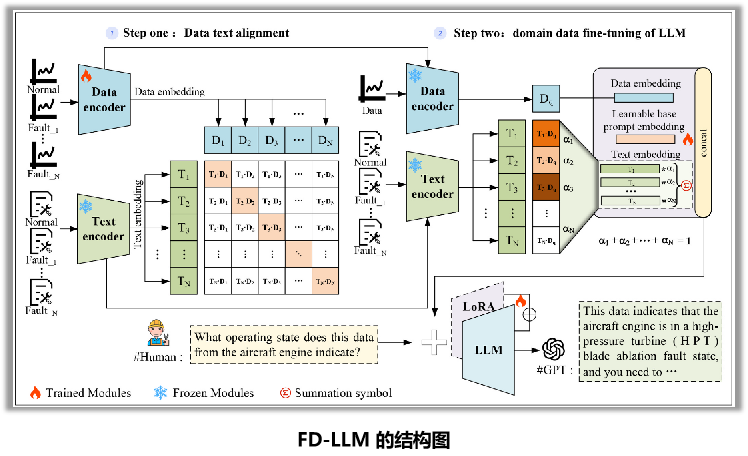
一、数据——文本对齐:让LLM能“读懂” 传感器信号
生成文本→数据编码→ 文本编码→ 对齐训练:打通了从工程数据到语言模型理解的通路。
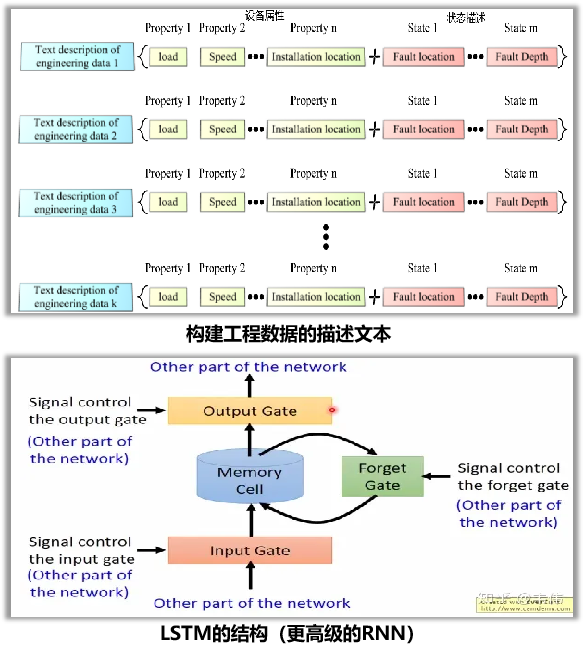
- 描述文本生成:为解决工程数据缺乏自然语义的问题,采用预定义的提示模板,将设备属性和状态描述组合成标准化的描述文本,形成数据-文本对。
- 数据编码:使用LSTM网络作为数据编码器,将预处理后的时间序列工程数据转换为特征嵌入向量。
- 选择长短期记忆网络(LSTM):工程数据通常是时间序列数据,LSTM可以捕获长期和短期依赖关系,是建模时间序列数据的有效方法。
- 文本编码:直接使用预训练LLM自身的文本编码器,为生成的描述文本生成语义特征嵌入向量。
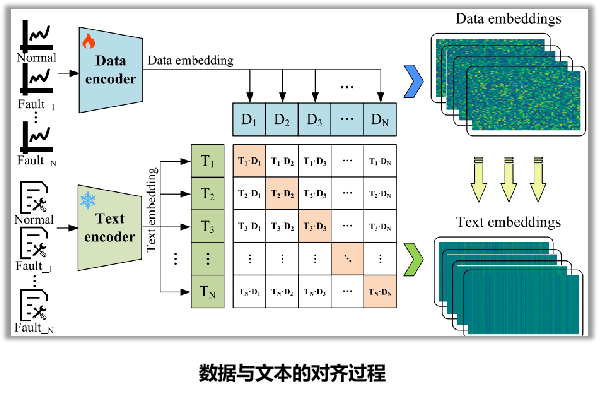
- 数据-文本对齐训练:采用对比学习的方法,冻结文本编码器,只训练数据编码器。
- 对比学习:通过计算数据嵌入和文本嵌入之间的余弦相似度,构建对比损失函数,目标是拉近正样本对(匹配的数据-文本对)的距离,推远负样本对(不匹配的对)的距离,从而实现两个模态在特征空间的对齐。
- 对比学习:通过计算数据嵌入和文本嵌入之间的余弦相似度,构建对比损失函数,目标是拉近正样本对(匹配的数据-文本对)的距离,推远负样本对(不匹配的对)的距离,从而实现两个模态在特征空间的对齐。
二、模糊语义嵌入:解决“模式混叠”大难题
- 传统故障诊断方法:简单的相似度匹配,只选择最相似的那一个类型作为诊断结果。
- 模糊语义:
- 计算相似度:计算测试样本的数据嵌入与所有已知故障类别标准语义的相似度。
- 计算权重:通过Softmax函数进行归一化处理得到一组模糊权重(即属于每个类别的概率分布)。
- 生成模糊语义:对所有已知故障类型的标准语义特征进行加权求和。
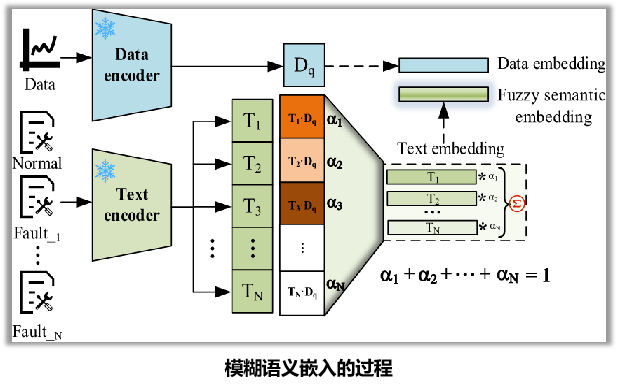
Dq :一个需要诊断的工程数据
TN: 一组包含设备各种运行状态的文本描述信息
三、核心技术:参数高效微调(LoRA,Low-Rank Adaptation低秩自适应)
- 提示学习器:设计了一个结合了连续提示和离散提示的输入模板。将工程数据嵌入、可学习的提示嵌入(用于引入额外诊断知识)和模糊语义嵌入共同组织成一个自然语言提示,输入给LLM。
- LoRA :仅训练极少量(<1%)的额外参数,即可让模型学会诊断任务,使其能够正确处理提示学习器提供的结构化输入,并输出我们期望的故障诊断答案。
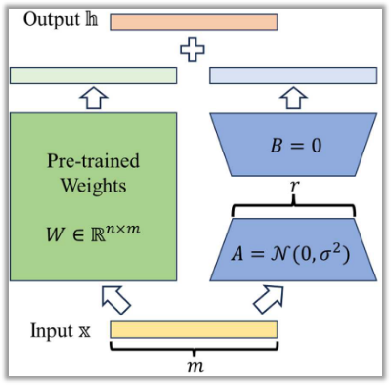
LoRA的原理图
LoRA原理图说明
预训练权重矩阵 W (n×m):冻结主干,避免灾难性遗忘,极大地减少了计算开销;
低秩矩阵A( r×m):将高维信息压缩到核心维度r,提取关键特征;
低秩矩阵B( n×r):将核心特征还原,放大有用特征,并学习如何调整最终输出;
关键技巧:B初始为0,确保训练从零影响开始,非常稳定;
最终输出: h= 原始输出 (Wx) + 适配器输出 (BAx)
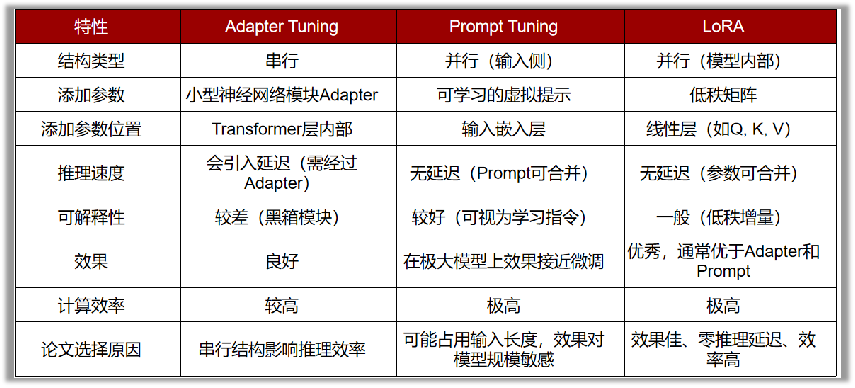
LoRA与其他两项微调技术的对比结果
🧪 实验设计与结果
一、实验设计
- 数据集:为验证泛化性,我们在三个不同领域的数据集上测试:
- 主实验:航空发动机数据
- 跨域验证:CWRU轴承数据 + 液压凿岩机数据
- 对比基线:与多种主流方法对比,包括CNN, ResNet, Transformer, SimCLR等。
- 评价指标:准确率,精确率,F1分数。
二、实验结果
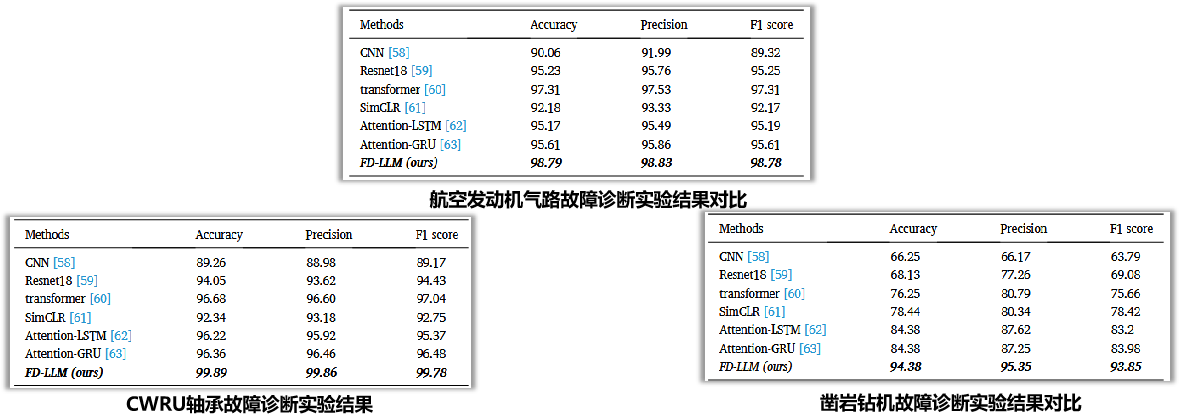
实验结果一:性能碾压——定量分析
- FD-LLM在所有数据集上的诊断准确率均显著优于所有对比基线。
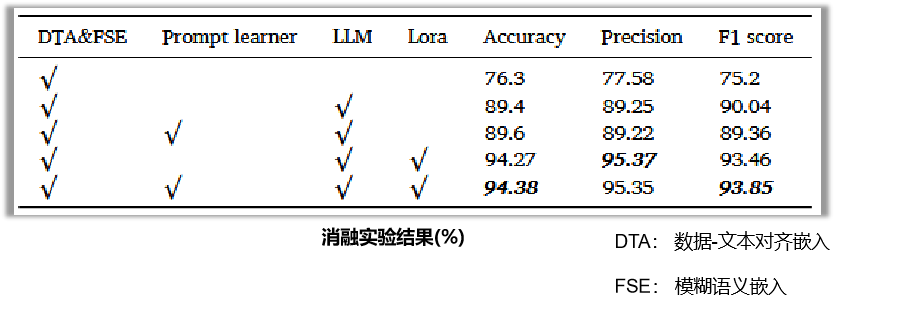
实验结果二:消融实验——验证创新点的必要性
- 实验设计:我们割掉FD-LLM的某个创新点,看性能是否下降。
- 验证了模态对齐与模糊语义嵌入、提示学习器、使用LLM推理和LoRA微调各个模块的必要性。
✅ 研究结论
本研究成功提出了FD-LLM,它通过模态对齐和模糊语义嵌入,首次有效激 活了大语言模型对复杂工业设备进行故障诊断的能力。
📈 研究意义
- 更高精度:显著提升了诊断准确率,尤其在复杂、模糊故障场景下。
- 更强泛化:一个模型可适应多种设备,打破了“一场景一模型”的束缚。
- 更好解释性:开启了可交互、可解释的故障诊断新范式。
🔮 未来研究方向
- 领域大模型: 探索训练面向整个运维领域的垂直领域大模型,提供从诊断、预测到决策的全链条支持。
- 轻量化部署: 研究如何将模型轻量化,以便在资源受限的边缘设备(如车载终端)上部署。
📕专业名词
一、 核心领域与任务
-
PHM (Prognostics and Health Management) / prognostics and health management
外行定义: 一套用于监控、预测和管理设备健康状态的技术和方法。通俗讲,就是让机器能“自己感觉不舒服”,并“预测自己什么时候会生病”,以便提前维护,避免停机。
文中角色: 本文研究的故障诊断是PHM的核心环节之一。 -
FD (Fault Diagnosis) / Fault Diagnosis
外行定义: 故障诊断。指识别系统中是否发生了故障、故障的类型以及严重程度的过程。就像医生根据病人的症状(如发烧、咳嗽)来判断得了什么病。 -
Complex Systems / 复杂系统
外行定义: 由大量相互关联、相互作用的部件组成的系统,其整体行为难以通过单个部件来预测。例如,高速列车、化工厂都是复杂系统,一个地方的小问题可能会引发连锁反应。
二、 人工智能与模型方法
-
LLM (Large Language Model) / 大语言模型
外行定义: 一种在海量文本数据上训练出来的巨型人工智能模型,能够理解、生成和处理人类语言。ChatGPT就是LLM的典型代表。
文中角色: 本文的核心研究对象,探索其用于故障诊断的可行性。 -
NLP (Natural Language Processing) / 自然语言处理
外行定义: 人工智能的一个分支,专注于让计算机能够理解、解释和操纵人类语言。 -
ML (Machine Learning) / 机器学习 与 DL (Deep Learning) / 深度学习
外行定义:-
DL: ML的一个子领域,使用类似于人脑神经元的深层网络结构来学习数据中复杂的模式。它在图像识别、语音处理等方面表现突出。
-
ML: 让计算机从数据中自动学习规律,而无需显式编程的方法。
-
-
NN (Neural Network) / 神经网络
外行定义: 一种受大脑结构启发的计算模型,是DL的基础。它由多层“神经元”组成,通过调整神经元之间的连接强度来学习。 -
ANN (Artificial Neural Network) / 人工神经网络, CNN (Convolutional Neural Network) / 卷积神经网络, RNN (Recurrent Neural Network) / 循环神经网络
外行定义: 神经网络的几种不同类型,分别擅长处理不同的数据:-
RNN: 专为处理像时间序列或句子这样有顺序的数据而设计。
-
CNN: 特别擅长处理像图片这样具有网格结构的数据。
-
ANN: 最基础的形式,适合处理表格数据。
-
-
AE (Autoencoder) / 自编码器 与 GAN (Generative Adversarial Network) / 生成对抗网络
外行定义:-
GAN: 由两个网络组成,一个“伪造者”网络生成假数据,一个“鉴别者”网络鉴别真伪,两者相互博弈,最终使“伪造者”能生成非常逼真的数据。
-
AE: 一种通过将数据压缩再还原来学习数据核心特征的神经网络。
-
-
BERT (Bidirectional Encoder Representations from Transformers) / 双向编码器表示模型 与 GPT (Generative Pre-trained Transformer) / 生成式预训练模型
外行定义: 两种最著名的LLM架构。BERT更擅长理解语言(如搜索引擎),而GPT更擅长生成语言(如聊天机器人)。
三、 技术实现与评估
-
Fine-tuning / 微调
外行定义: 在一个已经预训练好的大模型(如GPT)基础上,用特定领域的小规模数据(如故障记录)对其进行额外训练,使其适应新任务的过程。就像让一个通才博士生去学习一门具体的选修课。 -
LoRA (Low-Rank Adaptation) / 低秩自适应
外行定义: 一种高效的微调技术。它不像传统方法那样改动整个大模型,而是像给模型加一个轻量的“外挂”或“适配器”,只训练这个“外挂”来学习新任务,大大节省了计算资源。
文中角色: 本文用于微调LLaMa-2模型的核心技术。其原理如图所示,通过注入低秩矩阵来调整模型输出。 -
Prompt / 提示
外行定义: 输入给LLM的指令或问题,用于引导模型产生期望的输出。在本文中,作者将传感器数据转换成一段描述性文字作为提示。 -
ACC (Accuracy) / 准确率, F1-score / F1分数, G-mean / 几何平均数, MCC (Matthews Correlation Coefficient) / 马修斯相关系数
外行定义: 这些都是用于评估分类模型(如故障诊断模型)性能的指标。-
MCC: 一个非常稳健的指标,即使各类别的样本数量差异很大,也能给出公平的评价。
-
G-mean: 也是针对数据不平衡问题的评估指标。
-
F1-score: 精确率和召回率的调和平均数,在数据不平衡时比ACC更可靠。
-
ACC: 所有预测中正确的比例。
-
四、 数据集与案例
-
HST (High-speed Train) / 高速列车
文中角色: 本文使用的真实世界故障诊断案例。 -
TEP (Tennessee Eastman Process) / 田纳西伊斯曼过程
外行定义: 一个著名的化工过程模拟仿真平台,被广泛用于测试过程控制和故障诊断算法,是学术界的标准“考题”。
文中角色: 本文使用的仿真故障诊断案例,其流程如图所示。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)