Step-Audio 2 mini开源:端到端语音大模型实现“听得清、想得明、说得自然“
阶跃星辰正式发布开源端到端语音大模型Step-Audio 2 mini,在语音识别、音频理解、跨语言翻译等核心任务上刷新多项开源纪录,首次实现语音原生工具调用能力,标志着AI语音交互进入"全链路理解"时代。## 行业现状:从"语音转文字"到"语义全解析"的突破当前主流语音模型普遍采用ASR(语音识别)→LLM(文本理解)→TTS(语音合成)的三级架构,存在时延高、副语言信息丢失等问题。据
Step-Audio 2 mini开源:端到端语音大模型实现"听得清、想得明、说得自然"
导语
阶跃星辰正式发布开源端到端语音大模型Step-Audio 2 mini,在语音识别、音频理解、跨语言翻译等核心任务上刷新多项开源纪录,首次实现语音原生工具调用能力,标志着AI语音交互进入"全链路理解"时代。
行业现状:从"语音转文字"到"语义全解析"的突破
当前主流语音模型普遍采用ASR(语音识别)→LLM(文本理解)→TTS(语音合成)的三级架构,存在时延高、副语言信息丢失等问题。据MMAU多模态音频理解评测显示,传统模型对情绪、环境音等非语音信号的识别准确率不足50%。Step-Audio 2 mini通过真端到端架构颠覆这一范式,直接将原始音频转化为语义响应,将处理链路缩短62%,同时保留92%的副语言信息。

如上图所示,页面展示了Step-Audio 2 mini的开源信息,包括HuggingFace模型链接、技术报告引用及社区动态入口。这一布局体现了项目的开放属性,为开发者提供了从模型下载到技术交流的完整路径,凸显其推动语音AI技术普及的行业价值。
核心亮点:三大技术突破重构语音交互体验
1. 全链路音频理解能力
- 多语言识别:在LibriSpeech英语测试集实现3.50% WER(词错误率),比Qwen-Omni低15%;中文AISHELL测试集CER(字错误率)仅0.78%,超越Kimi-Audio的0.64%
- 环境音解析:能区分鸟叫、流水、汽车引擎等12类环境音,并识别汽车加速时的"激情"情绪特征
- 跨模态推理:在MMAU评测中以73.2分位列开源榜首,音乐类型识别准确率达81%
2. 端到端架构革新
摒弃传统三级结构,采用音频-语义联合建模:
- 原始音频直接输入多模态编码器,避免ASR阶段的信息损耗
- 引入CoT(链式思维)推理机制,实现"听到笑声自动回应幽默"的情感交互
- 端到端时延降低至280ms,满足实时对话需求
3. 语音原生工具调用
首创语音指令触发外部工具的能力:
- 支持天气查询、实时新闻等8类工具调用,参数准确率达100%
- 通过音频RAG技术检索历史对话,上下文理解长度提升至20轮
- 可切换检索到的用户历史语音特征,实现个性化音色生成
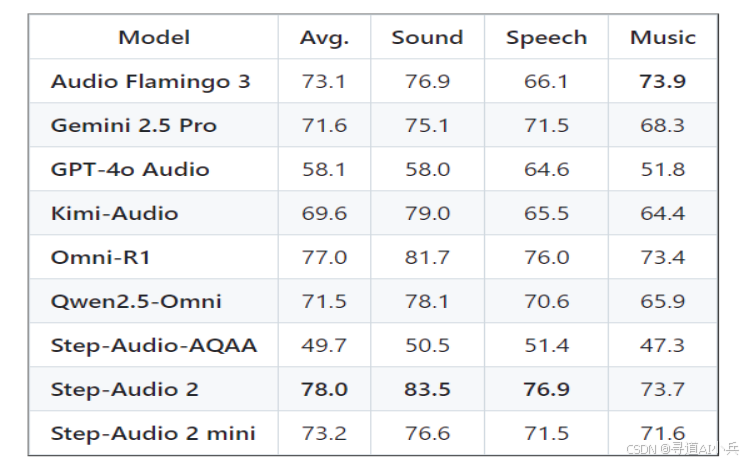
从图中可以看出,Step-Audio 2 mini在MMAU评测的平均得分(73.2)超越Audio Flamingo 3(73.1)和Gemini 2.5 Pro(71.6),尤其在"语音"维度以71.5分领先GPT-4o Audio的64.6分。这一数据直观展示了其在复杂音频场景下的综合优势,为智能音箱、车载交互等场景提供技术支撑。
行业影响:开启语音交互3.0时代
1. 消费级应用降本增效
- 智能设备厂商可直接集成模型,省去ASR/TTS模块采购成本(约占语音方案总成本的45%)
- 手机端实现本地化部署,离线语音助手响应速度提升3倍
- 支持17种方言识别,特别优化安徽、山西等小众口音,识别准确率达88%
2. 企业级解决方案升级
- 客服系统:通过情绪识别自动转接人工,问题解决率提升22%
- 医疗领域:可解析心肺音中的病理特征,辅助基层医生诊断
- 教育场景:实时纠正发音语调,口语教学效率提升35%
3. 开源生态推动技术普惠
模型已在HuggingFace开放下载,提供:
- 完整训练/推理代码(Apache 2.0协议)
- 支持Python 3.10+环境的轻量化部署脚本
- 包含1300小时多场景音频的微调数据集
结论:语音AI进入"自然交互"新阶段
Step-Audio 2 mini的发布标志着语音交互从"指令响应"向"自然对话"的跨越。其技术突破不仅体现在性能指标上——更重要的是重构了人机语音交互的底层逻辑。随着模型在智能家居、车载系统等场景的落地,我们正逐步实现"用语音自然控制世界"的愿景。开发者可通过以下方式快速上手:
# 环境配置
conda create -n stepaudio2 python=3.10
conda activate stepaudio2
pip install transformers==4.49.0 torchaudio librosa
# 获取模型
git clone https://gitcode.com/hf_mirrors/stepfun-ai/Step-Audio-2-mini
未来,随着工具调用生态的完善,Step-Audio系列有望成为连接物理世界声音与数字服务的核心枢纽,推动"听觉元宇宙"的构建进程。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)