大语言模型推测解码技术
论文:https://arxiv.org/pdf/2505.07858
推测解码(Speculative Decoding)是一种用于加速大型语言模型(LLM)推理的前沿技术,其核心思想是通过并行生成和验证机制突破传统自回归解码的串行瓶颈。
1、技术原理
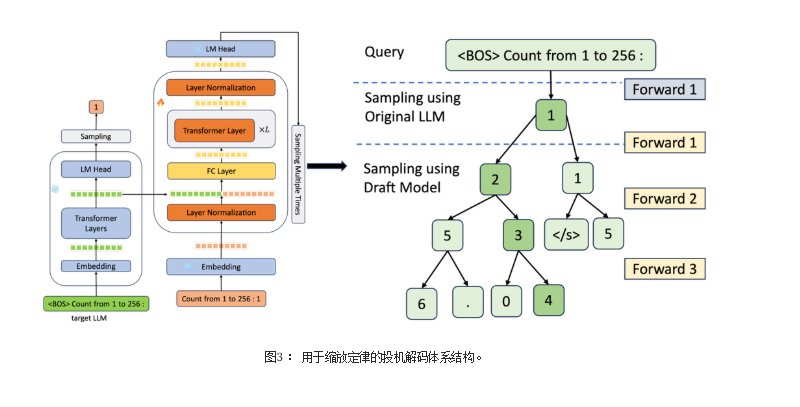
大模型推测解码中的双模型协作是一种通过小型草稿模型与大型目标模型协同工作来加速推理的技术。其核心流程分为两个阶段:
(1)首先,草稿模型(如Llama 7B)基于当前上下文快速生成多个候选token(通常3-5个),这一过程利用其轻量级参数实现低延迟;
(2)随后,目标模型(如Llama 70B)通过并行注意力机制验证所有候选token,计算每个token的接受概率 :
若接受则跳过主模型计算,若拒绝则由目标模型重新生成修正token。这种协作类似"写作助手与主编"的关系:草稿模型快速起草初稿,目标模型精准审核,既保留大模型的质量优势,又通过减少主模型调用次数实现2-6倍加速。
双模型协作的关键在于分布对齐与资源优化。技术上,草稿模型需与目标模型共享词表,并通过知识蒸馏(如序列级KD)使其输出分布逼近大模型,提升接受率;硬件上,两者需共驻同一设备内存,利用KV缓存共享上下文减少数据传输开销。例如在LLaVA多模态模型中,纯文本草稿模型即使不处理图像数据,也能通过文本token预测实现70%的加速比,证明协作机制对跨模态任务同样有效。当前优化方向包括动态调整草稿长度(如EAGLE-2算法)和树状验证(Medusa的多头解码),进一步平衡速度与质量。
2、核心优势
通过并行解码方式可以有效优化推理过程:
- 加速效果:实测推理速度提升2-6倍(如405B模型从25 token/s提升至100+ token/s),且输出质量与纯自回归解码一致。通过小型草稿模型(如Llama 3.1 8B)快速生成候选token序列,再由大型目标模型(如Llama 70B)并行验证,该技术可将生成速度提升2-6倍,例如在405B参数模型上实现从25 token/s到100+ token/s的飞跃。其核心在于草稿模型仅需目标模型1/10的计算量,通过减少主模型调用次数大幅降低内存带宽压力,同时保持输出质量与纯自回归解码完全一致
- 资源优化:草稿模型仅需主模型1/10的计算量,通过减少主模型调用次数降低内存带宽压力。
- 兼容性:支持贪心采样和核采样(Top-k/Top-p),保持生成多样性。推测解码支持贪心采样和概率采样(Top-k/Top-p),适配创意生成与确定性任务等多样化场景。例如在LLaVA多模态模型中,纯文本草稿模型即使不处理图像数据,也能通过协作机制实现70%的加速比。此外,该技术可通过量化(如INT8)和动态批处理进一步优化显存占用,使得70B级模型在消费级GPU(12GB显存)上实现高效部署,为边缘计算和实时交互应用提供可能。
3、应用场景
推测解码技术通过加速模型推理效率,在保证推理效果的情况下,可以有效解决推理和效果的平衡。目前主要运用在以下几个方面:
- 实时交互:聊天机器人、语音助手等低延迟场景。
- 多模态任务:如LLaVA模型结合视觉编码器加速图像描述生成2。
- 边缘设备:在资源受限硬件(如手机)部署大模型。
个人介绍:技术博客名为YUTransformer,8年AI老兵,从事NLP、大语言模型、多模态大模型等相关算法的研发和落地,拥有丰富的算法经验,先后在百度、平安、小鹏汽车从事算法落地的工作,借助平台将个人的一些算法研究和经验分享出来,一起推动技术的进步!加我vx(yx116169)入vlm/vla大模型群和llm群

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)