langchain 微调
2020年,GPT-3可谓火出了圈。不过,尽管表现惊艳,GPT-3背后到底是实实在在的参数,想要在实际应用场景中落地,难度着实不小。现在,针对这个问题,普林斯顿的师徒和MIT博士生Adam Fisch在最新论文中提出,使用较小的语言模型,并用少量样本来微调语言模型的权重。并且,实验证明,这一名为(better few-shot fine-tuning fo language models)的方法相
2020年,GPT-3可谓火出了圈。
不过,尽管表现惊艳,GPT-3背后到底是实实在在的1750亿参数,想要在实际应用场景中落地,难度着实不小。
现在,针对这个问题,普林斯顿的陈丹琦、高天宇师徒和MIT博士生Adam Fisch在最新论文中提出,使用较小的语言模型,并用少量样本来微调语言模型的权重。

并且,实验证明,这一名为LM-BFF(better few-shot fine-tuning fo language models)的方法相比于普通微调方法,性能最多可以提升30%。
详情如何,一起往下看。
方法原理
首先,研究人员采用了基于提示的预测路线。
所谓基于提示的预测,是将下游任务视为一个有遮盖(mask)的语言建模问题,模型会直接为给定的提示生成文本响应。
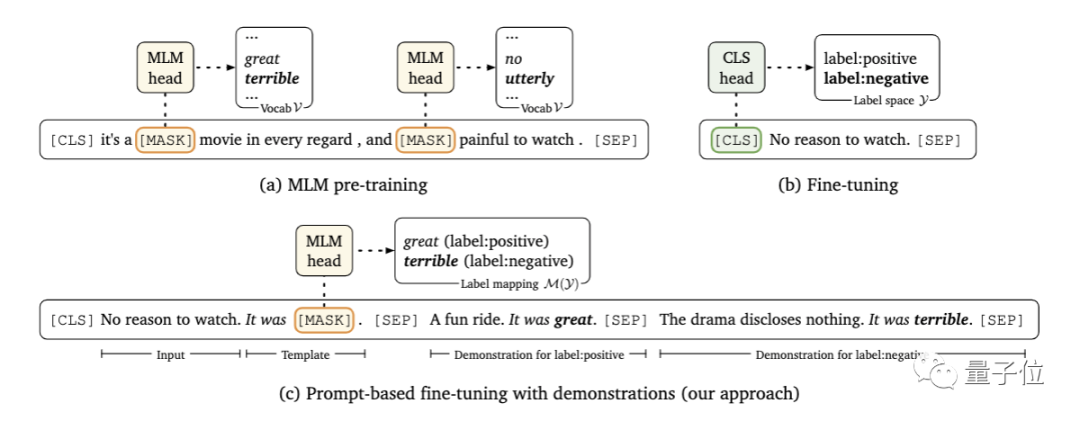
这里要解决的问题,是寻找正确的提示。这既需要该领域的专业知识,也需要对语言模型内部工作原理的理解。
在本文中,研究人员提出引入一个新的解码目标来解决这个问题,即使用谷歌提出的T5模型,在指定的小样本训练数据中自动生成提示。
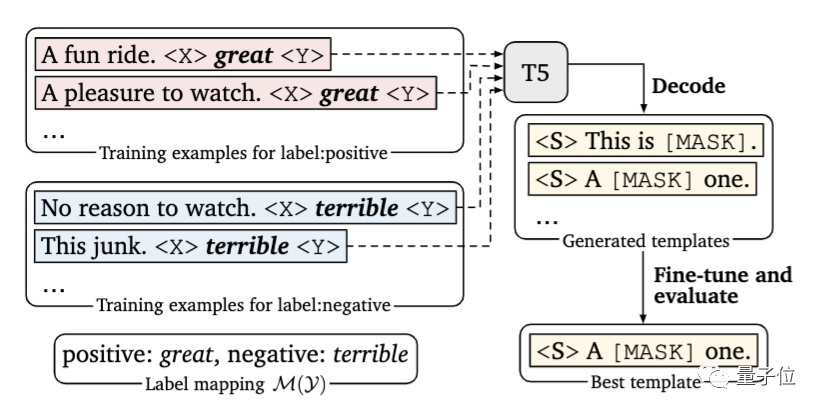
其次,研究人员在每个输入中,以额外上下文的形式添加了示例。
问题的关键在于,要有限考虑信息量大的示例,一方面,因为可用示例的数量会受到模型最大输入长度的限制;另一方面,不同类型的大量随机示例混杂在一起,会产生很长的上下文,不利于模型学习。
为此,研究人员开发了一种动态的、有选择性的精细策略:对于每个输入,从每一类中随机抽取一个样本,以创建多样化的最小演示集。
另外,研究人员还设计了一种新的抽样策略,将输入与相似的样本配对,以此为模型提供更多有价值的比较。
实验结果
那么,这样的小样本学习方法能实现怎样的效果?
研究人员在8个单句、7个句子对NLP任务上,对其进行了系统性评估,这些任务涵盖分类和回归。
结果显示:
- 基于提示的微调在很大程度上优于标准微调;
- 自动提示搜索能匹敌、甚至优于手动提示;
- 加入示例对于微调而言很有效,并提高了少样本学习的性能。
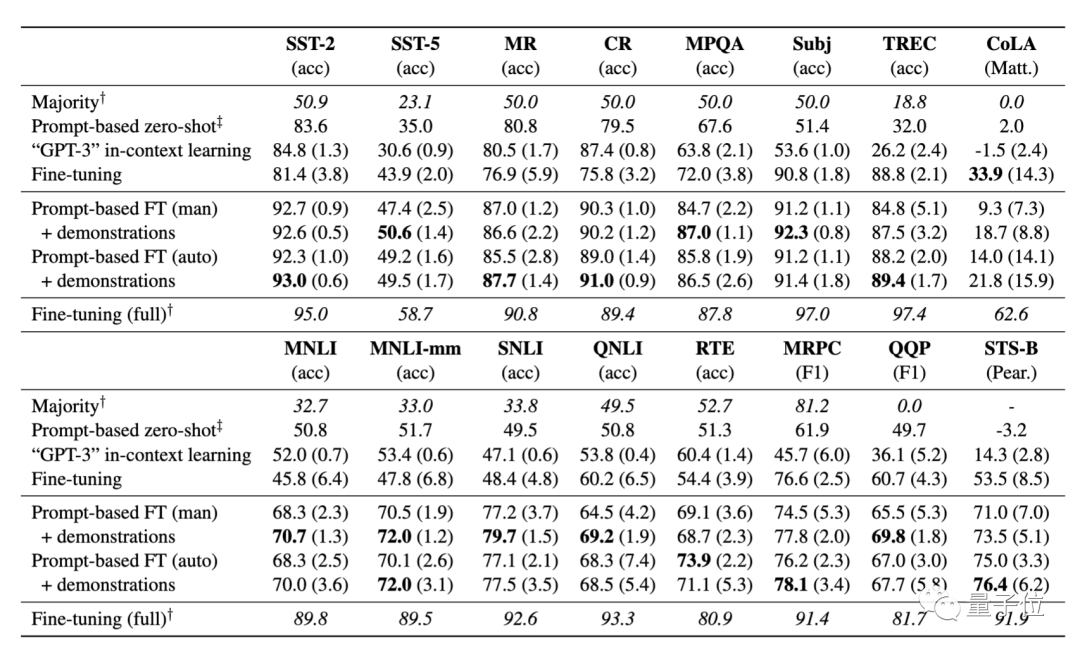
在K=16(即每一类样本数为16)的情况下,从上表结果可以看到,该方法在所有任务中,平均能实现11%的性能增益,显著优于标准微调程序。在SNLI任务中,提升达到30%。
不过,该方法目前仍存在明显的局限性,性能仍大大落后于采用大量样本训练获得的微调结果。
关于作者
论文有两位共同一作。

高天宇,清华大学本科生特等奖学金获得者,本科期间即发表4篇顶会论文,师从THUNLP实验室的刘知远副教授。
今年夏天,他本科毕业后赴普林斯顿攻读博士,师从本文的另一位作者陈丹琦。
此前,量子位曾经分享过他在写论文、做实验、与导师相处方面的经验。

Adam Fisch,MIT电气工程与计算机科学专业在读博士,是CSAIL和NLP研究小组的成员,主要研究方向是应用于NLP的迁移学习和多任务学习。
他本科毕业于普林斯顿大学,2015-2017年期间曾任Facebook AI研究院研究工程师。

至于陈丹琦大神,想必大家已经很熟悉了。她本科毕业于清华姚班,后于斯坦福大学拿下博士学位,2019年秋成为普林斯顿计算机科学系助理教授。
传送门
论文地址:
https://arxiv.org/abs/2012.15723v1
项目地址:
https://github.com/princeton-nlp/LM-BFF
本文章为转载内容,我们尊重原作者对文章享有的著作权。如有内容错误或侵权问题,欢迎原作者联系我们进行内容更正或删除文章。
- [](javascript:;)赞
- [](javascript:;)收藏
- [](javascript:;)评论
- [](javascript:;)分享
- [](javascript:;)举报
上一篇:ubuntu arm架构镜像下载 ubuntu for arm
下一篇:JAVA的成熟分类

提问和评论都可以,用心的回复会被更多人看到 评论
发布评论
全部评论 () 最热 最新
相关文章
-
[
微调技术LORA
微调技术LORA文章链接:arxiv.org/pdf/2106.09685.pdfLORA的思想:在原始 PLM (Pre-trained Language Model) 旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的intrinsic rank。训练的时候固定 PLM 的参数,只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将BA与 PLM 的参数叠加。用随机高斯分布初始化
](https://blog.51cto.com/u_16600817/10061954)
LORA 大模型 微调 人工智能
-
[
Langchain入坑
LangChain是一个用于开发由大型语言模型(LLM)支持的应用程序的框架。LangChain简化了LLM申请生命周期的每个阶段:开发:使用LangChain的开源构建块和组件构建您的应用程序。使用第三方集成和模板开始运行。生产化:使用LangSmith检查、监控和评估您的链,以便您可以充满信心地持续优化和部署。部署:使用LangServe将任何链变成 API 。jupyter具体来说,该框架由
](https://blog.51cto.com/bigdatagrocery/10385800)
语言模型 ide 应用程序
-
[
GPT-2及其微调
GPT-2及其微调
](https://blog.51cto.com/u_16520338/10866655)
json 权重 数据
-
[
LangChain初探
LangChain初探
](https://blog.51cto.com/u_15775105/6671035)
sed List 数据库
-
[
LangChain 学习
一、LangChain定义什么是LangChainLangChain是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。LangChain六大主要领域管理和优化pro
](https://blog.51cto.com/u_6478076/14012868)
LangChain
-
[
langchain如何自动执行python代码 | langchain
在当今的数据科学和人工智能领域,自动化代码生成与执行已成为提升效率与灵活性的重要手段。本文将详细介绍如何使用LangChain中的PythonREPL功能,实现大型语言模型(LLM)生成代码,并自动执行这些代码。通过这一流程,我们能够让大模型生成代码,然后通过代码执行来获取大语言模型通过文本生成本身不能很好完成的任务,特别是一些计算任务。
](https://blog.51cto.com/aiweker/13056491)
语言模型 langchain AIGC
-
[
LangChain简介
LangChain简介
](https://blog.51cto.com/u_16520338/10826888)
开发者 问答系统 数据处理
-
[
langchain LogicFlow
在这个博文中,我们将深入探讨如何使用“langchain LogicFlow”来强化我们的备份和恢复策略。通过一系列的工具与流程,我们可以有效地确保数据的安全性和可恢复性。本次内容包括备份策略、恢复流程、灾难场景、工具链集成、监控告警和最佳实践。准备好了吗?让我们开始吧!## 备份策略首先,我们需要明确一个高效的备份策略。备份策略的设计包括思维导图和存储架构,以便我们能清晰理解备份的整体框
](https://blog.51cto.com/u_16213449/14027588)
数据 System 工具链
-
[
解读LangChain
随着OpenAI在2020年发布了开创性的GPT-3,我们见证了LLM的普及度稳步攀升,如今还在逐渐升温发酵。这些强大的人工智能模型为链式”不同组件的核心概念,LangChain简…
](https://blog.51cto.com/wirelesscom/7808118)
langchain 数据 语言模型 应用程序
-
[
langchain架构
# 学习LangChain架构的第一步LangChain是一个用于构建智能应用程序的框架,特别是在需要自然语言处理(NLP)的场景。 本文将带领你逐步实现一个简单的LangChain架构,帮助你理解整个流程。## 流程概览以下是构建LangChain应用程序的基本步骤:| 步骤 | 描述 ||------|-------------
](https://blog.51cto.com/u_16175468/12035846)
python ci API
-
[
langchain python langchain python doc
简介LangChain是一个开源的应用开发框架。基于该开源框架,我们可以把大模型与各种工具结合从而实现各种功能,比如基本文档的问答,解析网页内容、查询表格数据等。目前支持Python和TypeScript两种编程语言。当前Python框架支持的模型和功能最全面。Modules按照官方wiki的描述,可以将Langchain的支持的功能划分为以下几个模块。Models该模块主要是集成了多个模型。主要
](https://blog.51cto.com/u_16099333/9960461)
langchain python python langchain langchain应用 openai应用
-
[
hanlp NNParserModel 微调 微调模型
一、原理在自己的数据集上训练一个新的深度学习模型时,一般采取在预训练ImageNet上进行微调的方法。什么是微调?这里以VGG16为例进行讲解。VGG16的结构为卷积+全连接层。卷积层分为5个部分共13层,即conv1~conv5。还有三层全连接层,即fc6、fc7、fc8。卷积层加上全连接层合起来一共为16层。如果要将VGG16的结构用于一个新的数据集,首先要去掉fc8这一层。原因是fc8层的输
](https://blog.51cto.com/u_16213579/9497061)
git 数据集 卷积
-
[
bcembeding微调 微调怎么调
文章作者:Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov导言自从BERT横空出世以来,各类预训练模型一直在试图“撼动”BERT的地位,如XLM、XLNet等等,然而,这些模
](https://blog.51cto.com/u_16099304/11852964)
bcembeding微调 pytorch微调bert 数据 数据集
-
[
sam 微调 python pytorch微调
Fine tuning 模型微调一. 什么是微调针对某一个任务,当自己训练数据不多时,我们可以找一个同类的别人训练好的模型,换成自己的数据,调整一下参数,再训练一遍,这就是微调。为什么要微调数据集本身很小,从头开始训练具有几千万参数的大型神经网络是不现实的。降低训练成本站在巨人的肩膀上,没必要重复造轮子迁移学习迁移学习几乎都是用在图像识别方向的。 迁移学习的初衷是节省人工标注样本的时间,让模型可以
](https://blog.51cto.com/u_12192/11638112)
sam 微调 python pytorch 迁移学习 深度学习 数据
-
[
微调代码 resnet 微调数据
数据收集:在数据收集阶段,首先需要确定合适的数据来源。这些来源可以包括新闻网站、博客、论坛、社交媒体等。根据项目需求,可以通过手动下载数据或编写网络爬虫进行自动抓取。在收集数据时,请务必遵守相关网站的使用条款和政策,尊重数据隐私和知识产权。数据清洗:数据清洗是一个关键步骤,因为它可以帮助去除数据中的噪声和无关信息。在这个阶段,可以使用文本处理工具和自然语言处理技术来删除广告、注释、重复内容等不相关
](https://blog.51cto.com/u_16099325/10751139)
微调代码 resnet gpt-3 人工智能 数据集 数据
-
[
langchain function
1、什么是函数式编程语言? 函数式编程语言(functional programming language)或称函数程序设计,又称泛函编程,是一种编程典范,它将计算机运算视为数学上的函数计算,并且避免使用程序状态以及易变对象。函数编程语言最重要的基础是λ演算(lambda calculus)。 函数式编程语言的特征: (1)以“函数”为首,如同命令式语言中的“变量”,函数可以赋值给
](https://blog.51cto.com/u_16213580/13575818)
langchain function 编程语言 函数式 函数式编程
-
[
langchain页面
Landing page也可以称为登陆页(也称着陆页),网站上任何一个接受流量的网页都可以称为landing apge。与普通的网页不同,landing page需要完成不同的使命,它需要把访问者引导到他们需要的网页,landing page并不是目标页,而只是引导访问者到目标页的一个中间页面。如果你租过房子,你可能找过房屋中介,landing page就扮演中介的角色。房屋中介需要了解租房者的需
](https://blog.51cto.com/u_16213698/14018293)
langchain页面 访问者 搜索 搜索引擎
-
[
langchain 异步
AJAX = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)AJAX 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。GET 还是 POST?与 POST 相比,GET 更简单也更快,并且在大部分情况下都能用。然而,在以下情况中,请使用 POST 请求:无法使用缓存文件(更新服务器上的文件或数据库)向服务器发送大量数据(PO
](https://blog.51cto.com/u_16099299/14020810)
langchain 异步 xml 控件 json
-
[
langchain 案例
[易学易懂系列|rustlang语言|零基础|快速入门|(27)|实战4:从零实现BTC区块链]项目实战实战4:从零实现BTC区块链我们今天来开发我们的BTC区块链系统。简单来说,从数据结构的角度上来说,区块链,就是区块组成的链。以下就是BTC区块链典型的结构:那最小单元就是区块:block。这个block包含两部分:区块头,区块体。我们先忽略Merkle树,先简化所有数据结构,只保留最基本的数据
](https://blog.51cto.com/u_16213717/14019615)
langchain 案例 Blockchain 区块链 数据结构
-
[
rust langchain
Chrome可称宇宙最强浏览器,它的市场份额接近70%,如果把使用Blink内核,基于Chromium的,如,Opera,360,UC,QQ,百度,猎豹等一系列换壳浏览器加上,市场份额估计更高!纯净地Chrome不宜食用,需要佐料。正确的做法,是自己安装扩展(小名叫做插件),满足自己的特殊需求。全地球人都知道,国内无法打开Chrome插件商店。不过,国内有很多下载站,用户可以自行搜索,下载插件,然
](https://blog.51cto.com/u_16099209/14018755)
rust langchain Chrome 安装插件 扩展程序
-
[
redis zset差集 java
sets类型及操作 Set是集合,它是string类型的无序集合。set是通过hash table实现的,添加,删除和查找复杂度都是0(1)。对集合我们可以取并集、交集、差集。通过这些操作我们可以实现sns中的好友推荐和blog的tag功能。 sadd:向集合中添加一个元素,通名称为key的set中添
](https://blog.51cto.com/u_16099189/14029963)
redis zset差集 java 数据库 并集 顺序号 删除元素
-
[
android 请在文件管理器中选择正确
Microsoft Windows XP [版本 5.1.2600]© 版权所有 1985-2001 Microsoft Corp. C:\Documents and Settings\Administrator>chkdsk /f P: 文件系统的类型是 exFAT。 由于该卷正在被另一个过程使用,Chkdsk 不能运行。 如果先卸下该卷,Chkdsk 也许可以运行。 该卷
](https://blog.51cto.com/u_16213614/14030390)
Markdown 代码片 流程图
-
[
python循环题基础画图题 python循环语句画图
python的强大在于它有许多的强大的库,turtle就是其中之一。利用turtle,你可以进行交互式的绘画,作为一个艺术白痴,想要画一幅画可能很困难,但是利用python的turtle库,只需要几行代码你就能实现绘画。turtle是python自带的一个库,直接调用就可以了。以下的两种方法都可以进行turtle库的调用。import turtlefrom turtle import *然后接下来
](https://blog.51cto.com/u_16213621/14030903)
python循环题基础画图题 ci python ide
-
[
海豚调度 gitlab 海豚调度api接口有哪些
https://github.com/apache/dolphinscheduler近日,Apache DolphinScheduler 发布了 3.1.2 版本。此版本主要基于 3.1.1 版本进行了 6 处 Python API 优化,19 处 Bug 修复,并更新了 4 个文档。其中较为重要的 Bug 修复为:Worker 杀进程不生效 #12995补数依赖模式会生成错误工作流实例 (#13
](https://blog.51cto.com/u_16099334/14031124)
海豚调度 gitlab apache Python API Apache
-
[
dolphinscheduler 配置hive数据库源 apache dolphinscheduler
关于 Apache DolphinSchedulerApache DolphinScheduler(incubator) 于 17 年在易观数科立项, 19 年 8 月进入 Apache 孵化器,已有 400+ 公司在生产上使用,代码+文档贡献者近 200 位。DolphinScheduler (简称DS)致力于使大数据任务调度开箱即用,它以拖拉拽的可视化方式将各种任务间的关系组装成 DAG(有向
](https://blog.51cto.com/u_16213705/14031172)
数据库 hadoop 大数据 linux docker
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。
掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取
👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 15
15 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)