FineScope : 使用SAE引导的自数据培育对领域专用大语言模型进行精确剪枝
从头开始训练大语言模型(LLMs)需要显著的计算资源,这推动了开发更小、领域专用的LLMs的兴趣,这些模型既要保持效率又要具备强大的任务性能。中型模型如LLaMA (Touvron等人, 2023b;a) 已成为领域特定适应的起点,但当在专门的数据集上测试时,它们通常会遭遇准确性的下降。我们介绍了FineScope,这是一种从更大的预训练模型中提取紧凑、领域优化的LLM框架。
Chaitali Bhattacharyya 1{ }^{1}1 Yeseong Kim 1{ }^{1}1
摘要
从头开始训练大语言模型(LLMs)需要显著的计算资源,这推动了开发更小、领域专用的LLMs的兴趣,这些模型既要保持效率又要具备强大的任务性能。中型模型如LLaMA (Touvron等人, 2023b;a) 已成为领域特定适应的起点,但当在专门的数据集上测试时,它们通常会遭遇准确性的下降。我们介绍了FineScope,这是一种从更大的预训练模型中提取紧凑、领域优化的LLM框架。FineScope利用稀疏自动编码器(SAE)框架,受其生成可解释特征表示能力的启发(Templeton等人, 2024),从大型数据集中提取领域特定子集。我们应用带有领域特定约束的结构化剪枝,确保剪枝后的模型保留目标领域的关键知识。为进一步提升性能,这些剪枝后的模型通过自数据蒸馏进行微调,利用SAE策划的数据集恢复剪枝过程中丢失的关键领域特定信息。广泛的实验和消融研究表明,FineScope实现了极具竞争力的性能,在领域特定任务中超越了几种大规模最先进的LLMs。此外,我们的结果表明,FineScope使剪枝后的模型在使用SAE策划的数据集进行微调时能够恢复其大部分原始性能。此外,即使不进行剪枝,将这些数据集用于预训练LLMs的微调也能提高其领域特定的准确性,突显了我们方法的稳健性。代码将会发布。
1. 引言
基于Transformer的大语言模型(LLMs)通过利用广泛且异构的数据集,在各种自然语言处理(NLP)任务中表现出卓越的泛化能力(Vaswani, 2017)。然而,在特定领域应用这些模型仍然具有挑战性。基础模型通常体积庞大,通常包含数百亿到万亿个参数(RBC Borealis AI, 2024; Adler等人, 2024; Dubey等人, 2024),需要大量的计算资源(Kim等人, 2023; Dubey等人, 2024; Wang等人, 2024)。此外,通用目的LLMs由于其通用的训练数据,往往无法捕捉精细的领域知识(Xu等人, 2022; Nijkamp等人, 2022)。这一挑战推动了对领域专用、资源高效的模型的需求,这些模型能够在减少计算成本的同时保持强大的任务性能(Talmor等人, 2018; Clark等人, 2018; Gu等人, 2024)。
最近在模型优化技术方面的进展,例如剪枝和参数高效微调,使得LLMs可以以较少的资源开销适应特定领域(Ma等人, 2023)。然而,这些方法严重依赖高质量领域特定数据集的可用性,而这些数据集往往稀缺或昂贵。因此,领域适应的瓶颈不仅在于优化模型架构,还在于从有限的初始监督中构建有效的领域特定数据集。鉴于潜在应用领域的广泛性,为每个场景手动策划数据集是不切实际的,这提出了一个关键问题:如何在使用最少的人类监督的情况下有效地构建领域特定的训练数据集,同时保持适应性和可扩展性?
最近的研究表明,大规模指令调整可能并非有效微调所必需。例如,LIMA(Zhou等人, 2024)证明,仅在精心策划的1000个示例上微调LLM即可获得有竞争力的性能,这表明预训练模型已经编码了丰富的知识,领域适应主要需要高质量的任务特定监督,而不是大量数据。然而,获取这样一个高质量的数据集仍然是瓶颈:现有的
1{ }^{1}1 大邱庆北科学技术院电气电子与计算机工程系,韩国。联系人:Yeseong Kim <<< yeseongkim@dgist.ac.kr >>>。
FineScope : 使用SAE引导的自数据培育对领域专用大语言模型进行精确剪枝
方法要么需要手动标注,要么依赖人类专家,这在需要多种语言模型的众多领域中难以应用。
在本文中,我们提出了一种替代的学习范式——自数据培育,它通过扩展用户定义的小种子集来自动化数据集构建,形成高质量的领域相关语料库。我们假设一小部分精心选择的种子数据集可以作为自动构建领域特定数据集的基础。如果我们可以从更广泛的语料库中使用少量代表性样本策划高质量的训练示例,就可以显著减少领域适应所需的手动工作量。然而,这种情境下的数据集策划不仅仅是选择子集——它还必须精炼数据集,以确保顺利集成到微调过程中。通过以符合预训练模型学习动态的方式组织数据,我们可以提高适应效率和任务特定的泛化能力。
自数据培育的有效性取决于克服几个关键的技术挑战。首先,从大型语料库中高效提取领域相关样本并非易事,因为暴力相似性搜索在计算上不可行。其次,训练有效的数据选择模型需要一种机制,可以从一个小种子集中泛化以检索语义上有意义的示例。第三,数据集必须确保在策划的数据集上进行微调依然稳定且有效,保持预训练模型的泛化能力,同时提高任务特定的性能。
为了解决这些问题,我们引入了FineScope,这是一个新颖的自数据培育框架,通过自动化领域特定数据集的构建来学习计算高效的领域特定语言模型。FineScope利用稀疏自动编码器(SAE)学习压缩的领域相关特征表示(Templeton等人, 2024; Kissane等人, 2024; Yan等人, 2024)。与典型的SAE不同,FineScope仅使用前$ k $激活来学习我们的SAE,这从大型通用语料库中选择语义相似的数据点,形成领域优化的数据集。它允许FineScope学习潜在的领域结构,而非静态嵌入相似性,使其在多样化应用领域中更具可扩展性和适应性。策划的数据集随后被用来微调剪枝后的领域专用LLM,确保计算效率和高任务相关性。为了辅助剪枝模型的微调过程,FineScope进一步使用自数据蒸馏技术(Yang等人, 2024)细化策划的数据集,使参数较少的模型能够无缝学习目标领域知识。
我们在多个领域特定的
NLP任务上评估了FineScope,并展示了它在显著降低计算成本的同时实现强大的领域适应。我们的结果显示,使用SAE策划的数据集微调的模型始终优于传统微调方法,在较小模型尺寸下实现更高的准确性。此外,FineScope实现了细粒度多领域专业化,使LLMs能够在无需从头重新训练的情况下适应不同的子领域。例如,在Math数据集上的测试显示所有模型的平均性能提高了11.45%。
我们的主要贡献如下:
- 我们引入了FineScope,这是一个用于自我监督领域数据集策划的新框架,能够从最小的种子数据集实现可扩展的领域适应。
-
- 我们正式提出了自数据培育的概念,假设一个小的、代表性的种子数据集可以通过最少的监督扩展为高质量的领域语料库。
-
- 我们开发了一个由SAE指导的数据集选择机制,该机制学习潜在的领域结构并高效选择高相关的训练样本。
-
- 我们展示了结构化剪枝与策划的数据集相结合,可以产生既保持高任务性能又减少计算成本的高效领域专用LLMs。
2. 相关工作
2.1. 领域特定的语言模型
领域适配的LLMs通过在领域特定数据集上训练,增强了在专业化领域中的表现。值得注意的例子包括PharmaGPT13B/70B(Chen等人, 2024)用于生物制药和化学应用,SaufLM-54B/141B(Colombo等人, 2024)用于法律任务,Shai-10B(Guo等人, 2023)用于资产管理,BloombergGPT(Wu等人, 2023)用于金融分析,以及MedPalm(Singhal等人, 2023)用于医学问答。其他模型如ClimateBERT(Webersinke等人, 2021)、ChatLaw(Cui等人, 2023)和FinGPT(Yang等人, 2023)分别专注于气候科学、法律文本处理和金融分析。然而,构建这样的模型很大程度上依赖于获取高质量的领域特定数据集,而这通常是稀缺且成本高昂的。此外,这些模型通常包含数十亿个参数,使得使用更新数据集进行连续再训练高度GPU密集。这些限制凸显了对更高效微调策略的需求,这些策略可以有效适应LLMs到特定领域应用,而不过度依赖人工标注或计算资源。
表1. 各模型及其参数数量和训练数据集描述。TDs: 训练数据集;⋆\star⋆ : FineScope
| 模型 | 参数 | TDs |
|---|---|---|
| Vicuna | 6.7B | ShareGPT |
| MC-CL | 6.9B | MathCodeInstruct |
| LLaMa 3.1 | 8.0B | 多样数据集 |
| Vicuna* | 4.7B | SAE策划 |
| MC-CL* | 4.7B | SAE策划 |
| LLaMa3.1* | 6.0B | SAE策划 |
2.2. 小型语言模型(SLMs).
尽管大型语言模型(LLMs)在各种NLP任务中达到了最先进水平,小型语言模型(SLMs)作为一种资源高效的替代方案已引起关注。几种技术已被探索以减少模型大小和计算成本,同时保持性能。轻量级架构使用参数高效的设 计,如MobileBERT(Sun等人, 2020)和DistilBERT(Sanh, 2019)用于仅编码器模型,以及基于GPT的模型(Radford, 2018; Radford等人, 2019; Touvron等人, 2023a;b; Dubey等人, 2024)用于仅解码器结构。量化(Jacob等人, 2018; Frantar等人, 2022; Liu等人, 2023; Hu等人, 2021)将精度降低到低位表示,提高效率同时最小化准确性损失。权重绑定(Thawakar等人, 2024)通过在模型组件之间共享权重进一步减少参数数量。
剪枝已成为一种广泛使用的减少模型复杂度同时保留基本功能的方法。受彩票假设(Frankle & Carbin, 2018)的启发,剪枝旨在识别可以实现与原始模型相当性能的较小子网络(“获胜票”)。提出了各种结构化和非结构化剪枝方法(Wang等人, 2019; Xia等人, 2022; Zafrir等人, 2021; Kurtic等人, 2022; Ashkboos等人, 2024; Xia等人, 2023),以去除非关键参数,同时保留网络的表示能力。与其他优化技术不同,后者要求从头学习模型或统一降低精度,剪枝允许模型有选择地保留关键组件,使其特别适合领域适应。因此,在这项工作中,我们将剪枝作为FineScope的核心组件之一,以构建计算高效的领域专用模型。
3. 方法学
图1提供了FineScope的概述,这是我们提出的领域特定LLM适应框架。FineScope包含两个关键阶段:(1) 领域特定数据培养,其中我们在预训练LLM的Top- KKK 激活上训练稀疏自动编码器(SAE),并用它来策划
基于与一组用户定义的种子样本的余弦相似性的一个领域特定数据集;以及(2) 剪枝感知微调与自数据蒸馏,其中根据策划的数据集应用结构化剪枝,然后使用自数据蒸馏微调剪枝后的模型以进一步改进任务性能。以下各节详细解释每个阶段。
3.1. 领域特定数据培养
训练SAE: 稀疏自动编码器(SAE)是一种神经网络,设计用于在输入数据上学习压缩表示,同时对隐藏单元施加稀疏性约束(EleutherAI, 2024)。在我们的框架中,SAE充当一种机制,用于从预训练LLM激活中提取领域相关特征,以从大型语料库中识别领域相关样本。我们不是直接在原始模型输出上操作,而是训练SAE在LLM中间层的激活上,从而捕获模型编码的底层知识的结构化、低维表示。此外,由于处理所有激活对于大型语料库来说在计算上不可行,我们的SAE被调整为仅学习最具代表性的激活,这种方式突出最重要的神经元,提高可解释性同时丢弃不太相关的信号。
在仅解码器的变压器模型如GPT-2和LLaMa中,激活流可以形式化定义如下(Braun等人, 2024):
act(l)(x)=f(l)(act(l−1)(x))a c t^{(l)}(x)=f^{(l)}\left(a c t^{(l-1)}(x)\right)act(l)(x)=f(l)(act(l−1)(x)),对于l=1,…,L−1l=1, \ldots, L-1l=1,…,L−1
其中act(l)(x)a c t^{(l)}(x)act(l)(x)表示给定输入xxx时第lll层的激活,f(l)f^{(l)}f(l)表示第lll层的变换函数,通常包括多头自注意力、前馈运算和残差连接。最终模型输出计算如下:
y=softmax(f(L)(act(L−1)(x))) y=\operatorname{softmax}\left(f^{(L)}\left(a c t^{(L-1)}(x)\right)\right) y=softmax(f(L)(act(L−1)(x)))
为了训练SAE,我们从预训练LLM选定层提取激活act(l)(x)a c t^{(l)}(x)act(l)(x)并将它们输入到编码器网络:
Enc(act(l)(x))=ReLU(Weact(l)(x)+be) \operatorname{Enc}\left(a c t^{(l)}(x)\right)=\operatorname{ReLU}\left(W_{e} a c t^{(l)}(x)+b_{e}\right) Enc(act(l)(x))=ReLU(Weact(l)(x)+be)
相应的解码器重建由下式给出:
SAE(act(l)(x))=D⊤Enc(act(l)(x))+bd \operatorname{SAE}\left(a c t^{(l)}(x)\right)=D^{\top} \operatorname{Enc}\left(a c t^{(l)}(x)\right)+b_{d} SAE(act(l)(x))=D⊤Enc(act(l)(x))+bd
这里,Enc表示SAE的编码器,WeW_{e}We和beb_{e}be是编码器的权重和偏置,D⊤D^{\top}D⊤和bdb_{d}bd对应于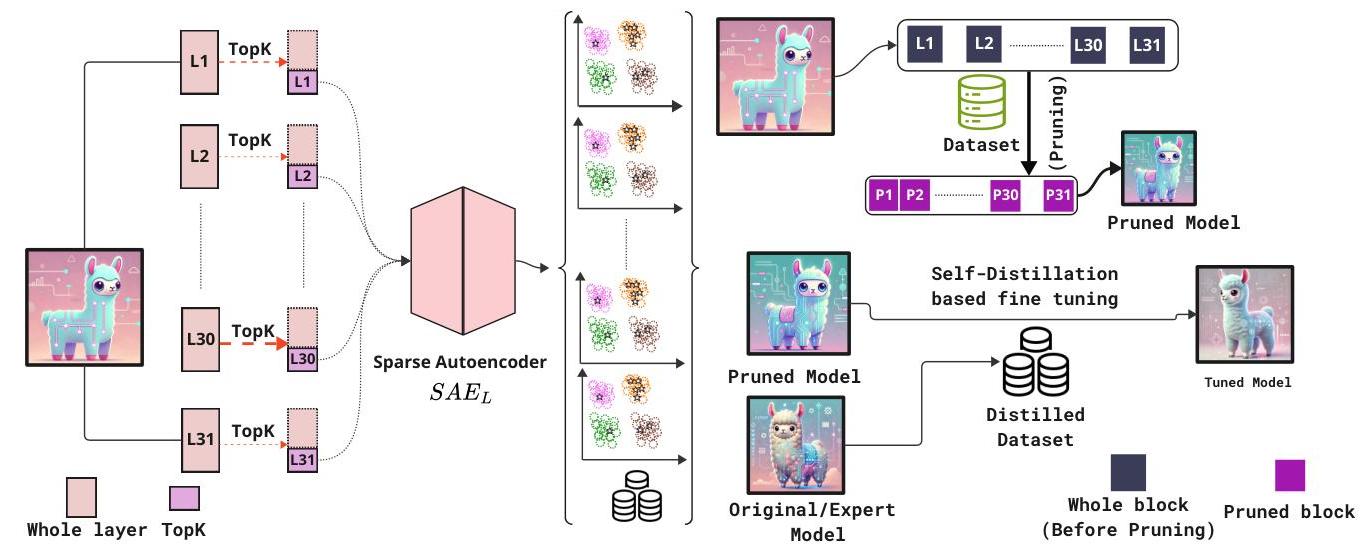
图1. FineScope框架概述。该方法包括两个阶段:(1) 领域特定数据策划,其中在预训练LLM的Top- KKK 激活上训练稀疏自动编码器(SAE),然后用于从一组用户定义的种子样本中策划领域特定数据集;(2) 剪枝感知微调与自数据蒸馏,其中根据策划的数据集应用结构化剪枝,然后使用自数据蒸馏微调剪枝后的模型以增强领域适应。
解码器参数。SAE被训练以最小化重建损失:
LSAE =∥SAE(act(l)(x))−act(l)(x)∥2+λ∥Enc(act(l)(x))∥1 \begin{aligned} \mathcal{L}_{\text {SAE }}= & \left\|\operatorname{SAE}\left(a c t^{(l)}(x)\right)-a c t^{(l)}(x)\right\|^{2} \\ & +\lambda\left\|\operatorname{Enc}\left(a c t^{(l)}(x)\right)\right\|_{1} \end{aligned} LSAE = SAE(act(l)(x))−act(l)(x) 2+λ Enc(act(l)(x)) 1
其中第二项通过对编码器的激活幅度进行惩罚来强制执行稀疏性。
Top-K激活选择以实现高效SAE训练:我们不使用全层激活训练SAE,而是应用Top-K过滤机制,在将激活输入编码器之前选择最重要的激活。给定包含mmm个样本的数据集DDD,D={x1,x2,…,xm}D=\left\{x_{1}, x_{2}, \ldots, x_{m}\right\}D={x1,x2,…,xm},我们基于梯度幅度计算KKK个最重要的激活:
TopK(act(l)(x),K)={ai∈act(l)(x)∣ai 对应于 K 个最大的 ∣ ∂acti(l)(x)∂x} \begin{aligned} & \operatorname{TopK}\left(a c t^{(l)}(x), K\right)=\left\{a_{i} \in a c t^{(l)}(x) \mid\right. \\ & a_{i} \text { 对应于 } K \text { 个最大的 }\left.\left\lvert\, \frac{\partial a c t_{i}^{(l)}(x)}{\partial x}\right.\right\} \end{aligned} TopK(act(l)(x),K)={ai∈act(l)(x)∣ai 对应于 K 个最大的 ∂x∂acti(l)(x)}
仅使用TopKT o p KTopK激活减少了SAE的输入维度,显著降低了计算开销,从而能够在大规模语料库上高效训练。此外,过滤掉噪声激活通过专注于最有信息的神经元改善了泛化能力,增强了与领域相关信息一致的提取特征的可解释性。
编码器随后在这些过滤后的激活上操作如下:
Enc(TopK(act(l)(x),K))=ReLU(We⋅TopK(act(l)(x),K)+be) \begin{aligned} & \operatorname{Enc}\left(\operatorname{TopK}\left(a c t^{(l)}(x), K\right)\right)= \\ & \quad \operatorname{ReLU}\left(W_{e} \cdot \operatorname{TopK}\left(a c t^{(l)}(x), K\right)+b_{e}\right) \end{aligned} Enc(TopK(act(l)(x),K))=ReLU(We⋅TopK(act(l)(x),K)+be)
对于LLM中的每一层lll,我们单独训练一个SAE,总共得到LLL个SAE。一旦训练完成,这些SAE就作为数据策划的特征提取器,我们在下一节中描述。
数据策划:图2提供了使用训练好的SAE进行数据策划的过程概述。给定目标领域的一小部分种子样本(例如,大约十个样本),我们的目标是从较大的混合领域数据集UUU中提取一个子集Ds⊆UD_{s} \subseteq UDs⊆U,通过选择与种子样本DtD_{t}Dt在学习的嵌入空间中最相似的样本。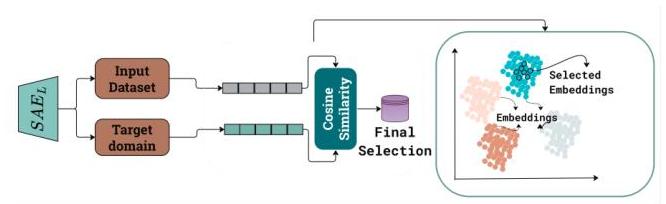
图2. 使用基于SAE的嵌入和余弦相似度进行数据策划。
使用训练好的SAE,我们计算DtD_{t}Dt和UUU中所有样本的嵌入。目标领域的嵌入由Et={SAE(x)∣x∈Dt}E_{t}=\left\{\operatorname{SAE}(x) \mid x \in D_{t}\right\}Et={SAE(x)∣x∈Dt}给出。类似地,
我们计算较大数据集UUU中所有样本的嵌入,EU={SAE(x)∣x∈U}E_{U}=\{\operatorname{SAE}(x) \mid x \in U\}EU={SAE(x)∣x∈U}。
为了识别UUU中最类似于DtD_{t}Dt的样本,我们计算每个嵌入eu∈EUe_{u} \in E_{U}eu∈EU与每个嵌入et∈Ete_{t} \in E_{t}et∈Et之间的余弦相似度。使用此相似度度量,我们选择那些嵌入在与EtE_{t}Et中的嵌入比较时落在Top-K最高余弦相似度分数内的样本xu∈Ux_{u} \in Uxu∈U。具体来说,我们定义所选数据集DsD_{s}Ds如下:
Ds={xu∈U∣eu∈TopK({CosSim(SAE(xu),et):et∈Et})} \begin{gathered} D_{s}=\left\{x_{u} \in U \mid e_{u} \in\right. \\ \left.\left.\operatorname{TopK}\left(\left\{\operatorname{CosSim}\left(\operatorname{SAE}\left(x_{u}\right), e_{t}\right): e_{t} \in E_{t}\right\}\right)\right\}\right. \end{gathered} Ds={xu∈U∣eu∈TopK({CosSim(SAE(xu),et):et∈Et})}
其中CosSim(eu,et)\operatorname{CosSim}\left(e_{u}, e_{t}\right)CosSim(eu,et)表示余弦相似度。
最终数据集DsD_{s}Ds包含来自UUU的样本,这些样本在语义上与目标领域DtD_{t}Dt最相似,基于它们的SAE嵌入的余弦相似度。为了确保DsD_{s}Ds仍然是高质量的领域特定数据集,我们还应用相似度阈值τ\tauτ以排除低相似度得分的样本,并删除重复和误分类的样本以防止冗余和噪声。在我们的评估中,所有SAE中的KKK值都设置为100,以保持选择的一致性。
3.2. 剪枝与自数据蒸馏微调
剪枝:为了在提高模型效率的同时保留领域特定知识,我们应用结构化剪枝以去除不重要的参数。我们不是执行全局剪枝,而是识别并保留对领域特定数据集DsD_{s}Ds贡献最大的模型组件。这确保了剪枝保留与目标领域相关知识,同时丢弃不那么有用的参数。
我们利用LLM-Pruner(Ma等人, 2023),它执行块状结构化剪枝以去除冗余模型组件,同时保持计算效率。这种方法确保剪枝后的模型保留领域相关的表示,同时显著降低推理成本。
正式地,令M\mathcal{M}M表示完整模型,A(Ds,m)\mathcal{A}\left(D_{s}, m\right)A(Ds,m)表示一个活动函数,该函数量化每个组件m∈Mm \in \mathcal{M}m∈M对数据集DsD_{s}Ds的贡献。我们将剪枝后的模型Mr\mathcal{M}_{r}Mr定义为:
Mr={m∈M∣A(Ds,m)>τ} \mathcal{M}_{r}=\left\{m \in \mathcal{M} \mid \mathcal{A}\left(D_{s}, m\right)>\tau\right\} Mr={m∈M∣A(Ds,m)>τ}
其中τ\tauτ是一个预定义的阈值,确定哪些组件被保留。剪枝比率,记为rrr,被视为一个超参数,并被优化以平衡模型大小和性能。
自数据蒸馏和微调:自数据蒸馏(SDFT)是一种技术,其中生成的数据集匹配原始模型的输出分布,有效提高泛化能力。虽然SDFT在知识转移方面有效,但在FineScope中的作用超出了数据集细化。由于剪枝移除了模型的大量参数,这可能导致丢失对领域特定知识有贡献的重要表示。为缓解这一点,我们使用自数据蒸馏恢复丢失的信息并通过重新引入强/未剪枝教师模型的高置信度输出来强化剪枝后的模型。
剪枝后的模型可能会因参数减少而失去关键的任务相关特征。在自蒸馏输出上进行训练有助于从教师模型恢复软知识,确保剪枝后的模型在不需要额外标注数据的情况下保留领域特定模式。此外,与仅基于策划数据集进行标准微调相比,自数据蒸馏通过保留模型输出分布的一致性平滑了学习过程。这减少了对较小策划数据集的过拟合,同时保持与原始领域表示的一致性。
在我们的框架中,我们调整SDFT以进一步细化剪枝后的模型。具体来说,我们使用(i)原始模型(针对表3)或(ii)预训练的最先进模型(针对表4)生成蒸馏数据集。然后使用该数据集微调剪枝后的模型,确保其在受益于改进的泛化能力的同时保留关键领域特定知识。
在原始SDFT提案(Yang等人, 2024)中,对于输入xxx,上下文ctc^{t}ct和教师模型的输出yty^{t}yt,生成(蒸馏)输出定义为:
y′∼f(y∣ct,xt,yt) y^{\prime} \sim f\left(y \mid c^{t}, x^{t}, y^{t}\right) y′∼f(y∣ct,xt,yt)
相应地,在我们提出的FineScope框架的微调过程中的修改损失函数为:
Lmsdft =−logfp(y′∣ct,yt) L_{\text {msdft }}=-\log f_{p}\left(y^{\prime} \mid c^{t}, y^{t}\right) Lmsdft =−logfp(y′∣ct,yt)
其中fpf_{p}fp是剪枝后的模型,Lmsdft L_{\text {msdft }}Lmsdft 代表自蒸馏损失。
4. 评估
4.1. 模型
我们使用三种模型评估我们的方法:Vicuna7B(Zheng等人, 2023),LLaMa 2(Touvron等人, 2023b)的微调版本;MathCoder-CL-7B(Wang等人, 2023),CodeLlama(Roziere等人, 2023)变体;以及LLaMa 3.1-8B(Dubey等人, 2024)。表1总结了这些模型。
表2. 每个表的实验设置摘要
| SAE(训练) | SAE(策划) | LLM(训练) | LLM(测试) | 数据蒸馏微调 | |
|---|---|---|---|---|---|
| 表3 | RedPajama(Computer, 2023) | OpenInstruct(hakurei, 2023) | 策划领域(STEM、社会科学、人文学科) | MMLU(STEM、社会科学、人文学科) | 预训练模型 |
| 表4 | MetaMathQA(Yu等人, 2023) | 数学(Hendrycks等人, 2021c) | 策划领域(预代数、代数、计数和概率) | 数学(预代数、代数、计数和概率) | OpenMath- Nvidia(Toshniwal等人, 2024)(数学),Notus 7B(Tunstall等人, 2023)(Alpaca) |
表3. 不同模型在不同领域的性能。预训练:基线。∗∗* *∗∗ :基线微调(a);∗*∗ :基线微调(b);Δ\DeltaΔ :领域特定微调。
| 模型 | 版本 | STEM | 社会科学 | 人文学科 |
|---|---|---|---|---|
| Vicuna(Zheng等人, 2023) | 预训练 | 33.10 | 40.23 | 43.69 |
| 剪枝 | 17.17 | 20.11 | 20.80 | |
| 微调 * | 30.61 | 35.44 | 36.11 | |
| 微调 ** (FineScope) | 34.01 | 42.39 | 44.51 | |
| 微调 Δ{ }^{\Delta}Δ (完整FineScope) | 32.29 | 36.13 | 37.34 | |
| MathCoder-CL(Wang等人, 2023) | 预训练(无微调) | 31.14 | 11.11 | 9.22 |
| 剪枝 | 13.32 | 8.02 | 3.67 | |
| 微调 * | 25.14 | 13.11 | 12.33 | |
| 微调 ** (FineScope) | 35.71 | 33.33 | 32.57 | |
| 微调 Δ{ }^{\Delta}Δ (完整FineScope) | 25.37 | 13.52 | 13.06 | |
| LLaMa3.1(Dubey等人, 2024) | 预训练 | 48.01 | 49.61 | 49.32 |
| 剪枝 | 30.59 | 31.33 | 33.62 | |
| 微调 * | 38.22 | 40.19 | 39.79 | |
| 微调 ** (FineScope) | 49.69 | 52.13 | 52.37 | |
| 微调 Δ{ }^{\Delta}Δ (完整FineScope) | 40.52 | 40.87 | 42.53 | |
| GPT-3(6.7B)(Brown等人, 2020) | 预训练 | 35.10 | 49.20 | 42.10 |
| OLMO(Groeneveld等人, 2024) | 预训练 | 22.19 | 31.01 | 30.26 |
| GPT-3(175B)(Brown等人, 2020) | 预训练 | 36.70 | 50.40 | 40.80 |
表4. 不同模型在基于数学的领域中的性能。预训练:原始预训练模型;* :使用Alpaca微调;△\triangle△ :使用SAE数据集微调;剪枝:剪枝后的模型;FS :少量镜头
| 模型 | 版本 | 预代数 | 代数 | 计数和概率 |
|---|---|---|---|---|
| Vicuna(Zheng等人, 2023) | 预训练 | 14.31 | 10.17 | 8.11 |
| 剪枝 | 0.11 | 0.00 | 0.00 | |
| 微调 * | 5.56 | 0.30 | 0.21 | |
| 微调 Δ{ }^{\Delta}Δ (完整FineScope) | 13.17 | 9.28 | 6.13 | |
| MathCoder-CL(Wang等人, 2023) | 预训练 | 11.60 | 16.77 | 13.38 |
| 剪枝 | 0.59 | 2.33 | 0.29 | |
| 微调 * | 1.29 | 6.94 | 3.33 | |
| 微调 Δ{ }^{\Delta}Δ (完整FineScope) | 8.01 | 15.73 | 12.28 | |
| LLaMa3.1(Dubey等人, 2024) | 预训练 | 32.77 | 29.87 | 20.35 |
| 剪枝 | 11.41 | 7.99 | 5.01 | |
| 微调 * | 9.23 | 5.56 | 9.10 | |
| 微调 Δ{ }^{\Delta}Δ (完整FineScope) | 31.17 | 29.73 | 19.41 | |
| GPT-3(13B)(Brown等人, 2020) | 预训练 | 6.80 | 5.30 | 4.50 |
| GPT-3(175B)(Brown等人, 2020) | 预训练(FS) | 7.70 | 6.00 | 4.70 |
4.2. 实验设置
我们在四种实验设置下评估FineScope。
(1) 领域特定微调 我们使用我们的SAE策划的领域特定数据集(第3.1节)进行模型剪枝。SAEs在RedPajama数据集(Computer, 2023)上进行训练,该数据集包括来自CommonCrawl、C4、GitHub、Wikipedia、Books3、ArXiv和StackExchange的数据,确保在多个领域中的泛化。使用这些SAEs,我们从OpenInstruct(hakurei, 2023)策划一个领域特定数据集,该数据集包括Alpaca(Lan, 2019)、Self-Instruct(Wang等人, 2022)、GPT-4 Instruct、Roleplay(Teknium, 2023)、Code Alpaca(Chaudhary, 2023)、Dolly(Ouyang等人, 2022)和其他指令数据集。我们提取STEM、社会科学和人文学科子集,每个策划的数据集都是从15个GPT-4o生成的种子样本中策划出来的,其中每个策划的数据集都通过Grok API(xAI, 2023)进行了扩充。最终策划的数据集大小分别为2,703(STEM)、3,327(社会科学)和3,522(人文学科)。
(2) 基线微调 我们与两种基线进行比较:(a) 使用SAE策划的数据集微调预训练模型。(b) 剪枝模型并使用Alpaca数据进行微调,采用与第3.2节相同的剪枝策略。
(3) 基线(预训练) 评估未经微调的预训练模型,作为基线。我们与GPT-3(6.7B, 175B)(Brown等人, 2020)和OLMO-7B(Groeneveld等人, 2024)(表3),以及GPT-3(13B, 175B)(表4)进行比较。
(4) 子领域微调(数学) 为了在更细粒度级别上评估微调,我们在数学内策划子领域。我们在MetaMath(Yu等人, 2023)上训练SAEs,并从数学数据集(Hendrycks等人, 2021c)策划数据集。与之前的设置不同,所有数学子领域都被合并成一个统一的数据集。策划后,我们提取预代数、代数和计数与概率子集。模型使用OpenMath2(Toshniwal等人, 2024)进行微调,而Notus-7B(Tunstall等人, 2023)用于基于Alpaca的微调。每个子领域的评估分别进行(表4)。
为了量化评估,我们利用MMLU(Hendrycks等人, 2020; 2021b;a)和数学测试集(Hendrycks等人, 2021c),使用lm-evaluation-harness(MMLU)和bigcode-evaluation-harness(数学)。我们呈现两个主要结果表:(i) 表3比较设置(1),(2a, 2b),(3)和最先进技术模型,以及(i) 表4评估设置(2b),(3)和(4)。实验设置的摘要见表2。
4.3. 结果
表3展示了在三个领域上的MMLU数据集的评估结果。结果显示,
经过FineScope使用我们的SAE策划的领域特定数据集微调的领域专用剪枝模型,在所有模型中平均性能分别比Alpaca微调高出4.13%(STEM)、2.25%(社会科学)和5.40%(人文学科)。在三个评估模型中,MathCoder-CL显示出最高的改进(+16.71),得益于接触更更新的数据集,其次是LLaMa 3.1(+2.41)和Vicuna(+1.2)。这表明SAE策划的数据集可以在没有重大人力投入的情况下有效增强领域特定适应。
值得注意的是,剪枝后模型性能显著下降,例如在所有领域中平均下降50%(Vicuna)、48%(MathCoder-CL)和35%(LLaMa 3.1)。LLaMa 3.1表现出最小的性能下降,可能是由于其更均衡的初始性能和领域感知剪枝,保留了更大比例的关键特征。与GPT-3(6.7B, 175B)和OLMO-7B相比,尽管我们的剪枝模型参数较少,但在大多数情况下仍优于这些模型。然而,GPT-3在社会科学领域超过了我们的方法,GPT-3(175B)在人文学科领域表现更好,而我们的微调模型始终优于OLMO-7B。
表4展示了在基于数学领域的性能,我们的领域特定微调显著提升了结果。与使用Alpaca微调的模型相比,性能提升分别为+7.50(Vicuna)、+8.15(MathCoder-CL)和+18.70(LLaMa 3.1)。值得注意的是,剪枝对Vicuna和MathCoder-CL造成严重性能下降,而Alpaca微调由于缺乏特定数学数据,无法完全恢复其丢失的性能。LLaMa 3.1在使用Alpaca微调时表现也较差,可能是因为灾难性遗忘。
与GPT模型相比,我们的微调模型取得了具有竞争力的结果,显著差异可能源于GPT模型中不平衡的训练数据集,这可能限制了它们在多样化数学领域中的泛化能力。
4.4. 消融研究
剪枝比率:表5展示了剪枝比率对模型性能的影响。以Vicuna为例,我们评估了不同剪枝比率下的领域特定微调。结果证实更高的剪枝比率会导致更大的性能下降,强化了选择最佳剪枝阈值的重要性。结果显示,与剪枝比例为30%的模型相比,剪枝比例为50%和70%的模型表现出显著的性能退化。相反,仅剪枝10%参数的模型获得了最佳性能;然而,由于参数数量较大,该模型在计算上仍然昂贵。为了平衡效率和性能,我们选择了30%的剪枝比率,它在模型大小和准确性之间实现了有利的权衡。
表5. 不同剪枝比率下剪枝模型的比较性能分析。PR(%) : 剪枝比率, Params (B) : 参数数量(十亿),STEM : 科学、技术、工程、数学;SS : 社会科学;Hum : 人文学科(MMLU)
| 模型 | PR(%) | Params(B) | STEM | SS | Hum |
|---|---|---|---|---|---|
| Vicuna | 10 | 6.1 | 34.18 | 38.17 | 41.60 |
| 30 | 4.7 | 32.29 | 36.13 | 37.34 | |
| 50 | 3.6 | 20.75 | 24.33 | 25.91 | |
| 70 | 2.4 | 10.10 | 9.82 | 8.21 |
SAE的TopK:为了确定KKK的最佳值,我们训练了具有不同KKK值的SAEs,并监测重建损失,平衡计算效率和训练质量。图3显示了KKK对重建损失的影响。出于演示目的,我们选择了初始、中间和最终层中的三个。尽管较大的KKK值直观地策划了更多样本进行训练,但对于K>96K>96K>96的情况,性能差异不大。因此,在我们的评估中选择K=96K=96K=96,它提供了平衡的折衷。其他层的结果可在附录中找到。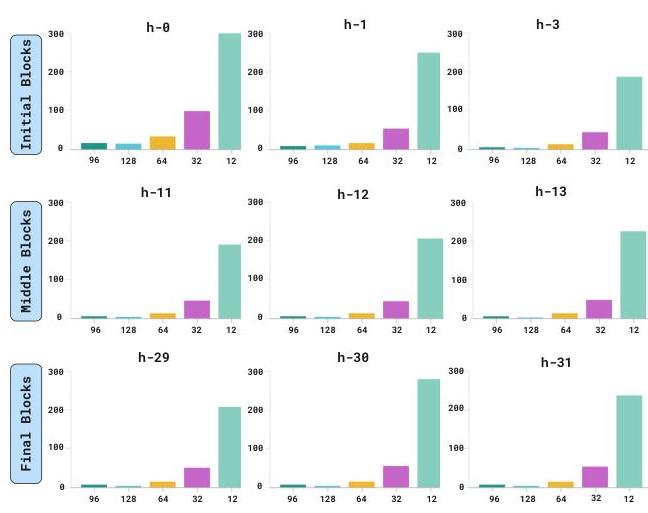
图3. KKK对重建损失的影响
种子选择:我们使用聚类分析可视化种子选择过程,如图4所示。特征解释因初始、中间和最终层而异,反映了模型中表示的变化。结果表明,我们的策划数据集与不同层表示中的聚类虚拟目标领域一致。较低层倾向于捕捉广泛的、通用的特征,通常编码句法结构或常见的语言模式。相比之下,较深层则关注越来越抽象和领域特定的属性,导致更紧凑和语义上有意义的聚类。
这种逐步细化表明,领域相关信息在后续层中更为明显,其中特征表示变得更加专业化。我们的方法利用这一层次结构,从平衡泛化和领域特异性的层中选择种子。通过使用基于SAE的表示而非原始嵌入,我们确保种子选择过程更具可解释性,并与高级领域知识一致,而不受表面令牌级相似性的影响。这强化了我们在数据集策划中识别最具信息量的种子样本的方法的有效性。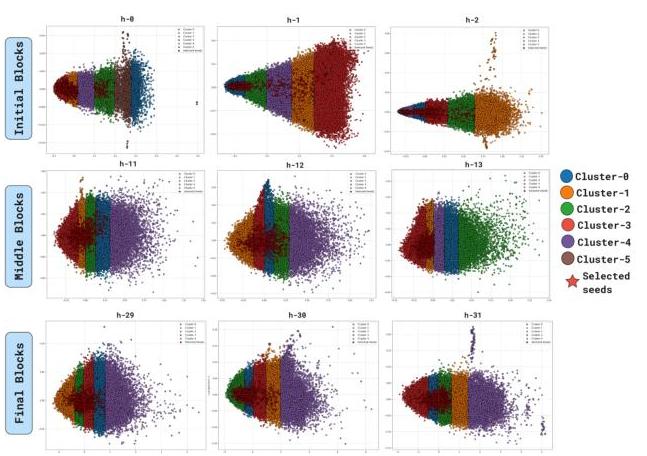
图4. 数据集策划的种子选择聚类可视化(针对STEM)
5. 结论
我们介绍了FineScope,这是一个通过SAE引导的数据集策划、领域感知剪枝和自蒸馏微调开发领域特定模型的框架。FineScope解决了领域适应中的一个关键挑战:如何在保持微调LLMs计算效率的同时高效构建高质量的领域特定数据集。我们的方法包括三个关键步骤:(1) 训练SAE以学习压缩的领域表示,(2) 使用训练好的SAE从大型语料库中策划领域特定数据集,以及(3) 应用领域感知剪枝,然后进行自数据蒸馏以恢复丢失的知识并增强微调稳定性。FineScope确保模型保留领域相关特征,同时显著降低计算成本。实验表明,FineScope在大多数情况下优于最先进的方法。我们的方法有助于恢复剪枝模型的性能,同时显著增强领域特定适应。此外,使用SAE策划的数据集微调预训练模型使其在领域特定任务中超越原始模型。
参考文献
Adler, B., Agarwal, N., Aithal, A., Anh, D. H., Bhattacharya, P., Brundyn, A., Casper, J., Catanzaro, B., Clay, S., Cohen, J., 等人. Nemotron-4 340b 技术报告. arXiv 预印本 arXiv:2406.11704, 2024.
Ashkboos, S., Croci, M. L., Nascimento, M. G. d., Hoefler, T., 和 Hensman, J. Slicegpt: 通过删除行和列压缩大型语言模型. arXiv 预印本 arXiv:2401.15024, 2024.
Braun, D., Taylor, J., Goldowsky-Dill, N., 和 Sharkey, L. 通过端到端稀疏字典学习识别功能性重要特征. arXiv 预印本 arXiv:2405.12241, 2024.
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., 等人. 语言模型是少量样本学习者. Advances in neural information processing systems, 33: 1877-1901, 2020.
Chaudhary, S. Code alpaca: 一个用于代码生成的指令跟随型Llama模型. https://github.com/sahil280114/codealpaca, 2023.
Chen, L., Wang, W., Bai, Z., Xu, P., Fang, Y., Fang, J., Wu, W., Zhou, L., Zhang, R., Xia, Y., Xu, C., Hu, R., Xu, L., Cai, Q., Hua, H., Sun, J., Liu, J., Qiu, T., Liu, H., Hu, M., Li, X., Gao, F., Wang, Y., Tie, L., Wang, C., Lu, J., Sun, C., Wang, Y., Yang, S., Li, Y., Jin, L., Zhang, L., Bian, F., Ye, Z., Pei, L., 和 Tu, C. Pharmagpt: 生物制药和化学领域的专用大语言模型. arXiv 预印本 arXiv:2406.18045, 2024.
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., 和 Tafjord, O. 你认为已经解决了问答问题吗?试试ARC,AI2推理挑战. arXiv:1803.05457v1, 2018.
Colombo, P., Pires, T., Boudiaf, M., Melo, R., Culver, D., Morgado, S., Malaboeuf, E., Hautreux, G., Charpentier, J., 和 Desa, M. Saullm-54b & saullm-141b: 扩大规模法律领域的域适应. arXiv 预印本 arXiv:2407.19584, 2024.
Computer, T. Redpajama: 一个开源方案重现llama训练数据集, 2023. URL https://github.com/togethercomputer/ RedPajama-Data.
Cui, J., Li, Z., Yan, Y., Chen, B., 和 Yuan, L. Chatlaw: 开源集成外部知识库的法律大型语言模型. arXiv 预印本 arXiv:2306.16092, 2023.
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., 等人. Llama 3模型家族. arXiv 预印本 arXiv:2407.21783, 2024.
EleutherAI. SAE: Stacked autoencoder. https:// github.com/EleutherAI/sae, 2024. Accessed: 2024-12-18.
Frankle, J. 和 Carbin, M. 彩票假设:寻找稀疏、可训练的神经网络. arXiv 预印本 arXiv:1803.03635, 2018.
Frantar, E., Ashkboos, S., Hoefler, T., 和 Alistarh, D. GPTQ: 生成式预训练变压器的准确后训练量化. arXiv 预印本 arXiv:2210.17323, 2022.
Groeneveld, D., Beltagy, I., Walsh, P., Bhagia, A., Kinney, R., Tafjord, O., Jha, A. H., Ivison, H., Magnusson, I., Wang, Y., 等人. Olmo: 加速语言模型的科学研究. arXiv 预印本 arXiv:2402.00838, 2024.
Gu, X., Chen, M., Lin, Y., Hu, Y., Zhang, H., Wan, C., Wei, Z., Xu, Y., 和 Wang, J. 大语言模型在特定领域代码生成中的有效性. ACM Transactions on Software Engineering and Methodology, 2024.
Guo, Z., Jiang, G., Zhang, Z., Li, P., Wang, Z., 和 Wang, Y. Shai: 一种用于资产管理的大语言模型. arXiv 预印本 arXiv:2312.14203, 2023.
hakurei. Open instruct v1: 一个让LLMs遵循指令的数据集. https://huggingface.co/ datasets/hakurei/open-instruct-v1, 2023. Accessed: 2025-01-07.
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., 和 Steinhardt, J. 测量大规模多任务语言理解. arXiv 预印本 arXiv:2009.03300, 2020.
Hendrycks, D., Burns, C., Basart, S., Critch, A., Li, J., Song, D., 和 Steinhardt, J. 对齐AI与共享的人类价值观. 国际学习表征会议(ICLR)论文集, 2021a.
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., 和 Steinhardt, J. 测量大规模多任务语言理解. 国际学习表征会议(ICLR)论文集, 2021b.
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., 和 Steinhardt, J. 使用数学数据集测量数学问题解决能力. NeurIPS, 2021c.
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., 和 Chen, W. LoRA: 大型语言模型的低秩适应. arXiv 预印本 arXiv:2106.09685, 2021.
Jacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., Adam, H., 和 Kalenichenko, D. 用于高效整数运算推断的神经网络量化与训练. IEEE计算机视觉与模式识别会议论文集, 第2704-2713页, 2018.
Kim, D., Park, C., Kim, S., Lee, W., Song, W., Kim, Y., Kim, H., Kim, Y., Lee, H., Kim, J., 等人. Solar 10.7 b: 使用简单而有效的深度扩展缩放大型语言模型. arXiv 预印本 arXiv:2312.15166, 2023.
Kissane, C., Krzyzanowski, R., Bloom, J. I., Conmy, A., 和 Nanda, N. 使用稀疏自动编码器解释注意力层输出. arXiv 预印本 arXiv:2406.17759, 2024.
Kurtic, E., Campos, D., Nguyen, T., Frantar, E., Kurtz, M., Fineran, B., Goin, M., 和 Alistarh, D. 最优BERT外科医生:可扩展且精确的大型语言模型二阶剪枝. arXiv 预印本 arXiv:2203.07259, 2022.
Lan, Z. Albert: 一种轻量级BERT用于自监督学习语言表示. arXiv 预印本 arXiv:1909.11942, 2019.
Liu, Z., Oguz, B., Zhao, C., Chang, E., Stock, P., Mehdad, Y., Shi, Y., Krishnamoorthi, R., 和 Chandra, V. LLM-QAT: 大型语言模型的数据无关量化感知训练. arXiv 预印本 arXiv:2305.17888, 2023.
Ma, X., Fang, G., 和 Wang, X. LLM-Pruner: 关于大型语言模型的结构化剪枝. 在神经信息处理系统进展会议上, 2023.
Nijkamp, E., Pang, B., Hayashi, H., Tu, L., Wang, H., Zhou, Y., Savarese, S., 和 Xiong, C. 一种对话范式用于程序综合. arXiv 预印本, 2022.
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., 等人. 使用人类反馈训练语言模型以遵循指令. 神经信息处理系统进展, 35:27730-27744, 2022.
Radford, A. 通过生成预训练改进语言理解. 2018.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., 等人. 语言模型是无监督的多任务学习者. OpenAI 博客, 1(8):9, 2019.
RBC Borealis AI. 大型语言模型的高层次概述. RBC Borealis AI 研究博客, 2024.
Roziere, B., Gehring, J., Gloeckle, F., Sootla, S., Gat, I., Tan, X. E., Adi, Y., Liu, J., Sauvestre, R., Remez, T., 等人. Code llama: 开源基础模型用于代码. arXiv 预印本 arXiv:2308.12950, 2023.
Sanh, V. Distilbert, 一种精简版的BERT: 更小、更快、更便宜、更轻便. arXiv 预印本 arXiv:1910.01108, 2019.
Singhal, K., Tu, T., Gottweis, J., Sayres, R., Wulczyn, E., Hou, L., Clark, K., Pfohl, S., Cole-Lewis, H., Neal, D., 等人. 使用大型语言模型实现专家级别的医学问题解答. arXiv 预印本 arXiv:2305.09617, 2023.
Sun, Z., Yu, H., Song, X., Liu, R., Yang, Y., 和 Zhou, D. Mobilebert: 一种适用于资源受限设备的紧凑型任务无关BERT. arXiv 预印本 arXiv:2004.02984, 2020.
Talmor, A., Herzig, J., Lourie, N., 和 Berant, J. Commonsenseqa: 针对常识知识的问答挑战. arXiv 预印本 arXiv:1811.00937, 2018.
Teknium. GPTeacher: 由GPT-4生成的模块化数据集集合. https://github.com/ tekniuml/GPTeacher, 2023.
Templeton, A., Conerly, T., Marcus, J., Lindsey, J., Bricken, T., Chen, B., Pearce, A., Citro, C., Ameisen, E., Jones, A., Cunningham, H., Turner, N. L., McDougall, C., MacDiarmid, M., Freeman, C. D., Sumers, T. R., Rees, E., Batson, J., Jermyn, A., Carter, S., Olah, C., 和 Henighan, T. 单义性扩展:从Claude 3十四行诗中提取可解释特征. Transformer Circuits Thread, 2024. URL https: //transformer-circuits.pub/2024/ scaling-monosemanticity/index.html.
Thawakar, O., Vayani, A., Khan, S., Cholakal, H., Anwer, R. M., Felsberg, M., Baldwin, T., Xing, E. P., 和 Khan, F. S. Mobillama: 实现准确且轻量级完全透明的GPT. arXiv 预印本 arXiv:2402.16840, 2024.
Toshniwal, S., Du, W., Moshkov, I., Kisacanin, B., Ayrapetyan, A., 和 Gitman, I. Openmathinstruct-2: 使用大规模开源指令数据加速数学AI. arXiv 预印本 arXiv:2410.01560, 2024.
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., 等人. Llama: 开放且高效的基语言模型. arXiv 预印本 arXiv:2302.13971, 2023a.
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., 等人. Llama 2: 开放的基础和微调聊天模型. arXiv 预印本 arXiv:2307.09288, 2023b.
Tunstall, L., Beeching, E., Lambert, N., Rajani, N., Rush, A. M., 和 Wolf, T. 对齐手册. https://github.com/huggingface/ alignment-handbook, 2023.
Vaswani, A. 注意力就是你所需要的全部. 神经信息处理系统进展, 2017.
Wang, K., Ren, H., Zhou, A., Lu, Z., Luo, S., Shi, W., Zhang, R., Song, L., Zhan, M., 和 Li, H. Mathcoder: 在LLMs中无缝集成代码以增强数学推理. arXiv 预印本 arXiv:2310.03731, 2023.
Wang, Y., Kordi, Y., Mishra, S., Liu, A., Smith, N. A., Khashabi, D., 和 Hajishirzi, H. Self-instruct: 使用自动生成指令对语言模型进行对齐, 2022.
Wang, Z., Wohlwend, J., 和 Lei, T. 大型语言模型的结构化剪枝. arXiv 预印本 arXiv:1910.04732, 2019.
Wang, Z., Bukharin, A., Delalleau, O., Egert, D., Shen, G., Zeng, J., Kuchaiev, O., 和 Dong, Y. Helpsteer2preference: 用偏好补充评分, 2024. URL https://arxiv.org/abs/2410. 01257 .
Webersinke, N., Kraus, M., Bingler, J. A., 和 Leippold, M. Climatebert: 一种用于气候相关文本的预训练语言模型. arXiv 预印本 arXiv:2110.12010, 2021.
Wu, S., Irsoy, O., Lu, S., Dabravolski, V., Dredze, M., Gehrmann, S., Kambadur, P., Rosenberg, D., 和 Mann, G. Bloomberggpt: 一种用于金融的大语言模型. arXiv 预印本 arXiv:2303.17564, 2023.
xAI. Grok-1模型卡, 2023. URL https://x.ai/ blog/grok/model-card.
Xia, M., Zhong, Z., 和 Chen, D. 结构化剪枝学习紧凑且准确的模型. arXiv 预印本 arXiv:2204.00408, 2022.
Xia, M., Gao, T., Zeng, Z., 和 Chen, D. Sheared llama: 通过结构化剪枝加速语言模型预训练. arXiv 预印本 arXiv:2310.06694, 2023.
Xu, F. F., Alon, U., Neubig, G., 和 Hellendoorn, V. J. 大型代码语言模型的系统性评估. 在Deep Learning for Code Workshop中, 2022. URL https: //openreview.net/forum?id=SLcEnoObJZq.
Yan, H., Xiang, Y., Chen, G., Wang, Y., Gui, L., 和 He, Y. 鼓励还是抑制单义性?从特征去相关的角度重新审视单义性. arXiv 预印本 arXiv:2406.17969, 2024.
Yang, H., Liu, X.-Y., 和 Wang, C. D. Fingpt: 开源金融大语言模型. arXiv 预印本 arXiv:2306.06031, 2023.
Yang, Z., Pang, T., Feng, H., Wang, H., Chen, W., Zhu, M., 和 Liu, Q. 自蒸馏弥合语言模型微调中的分布差距. 在 Ku, L.-W., Martins, A., 和 Srikumar, V. (eds.), 计算语言学协会第62届年会论文集(第一卷:长篇论文), 第1028-1043页, 泰国曼谷, 2024年8月. 计算语言学协会. URL https://aclanthology.org/ 2024.acl-long.58.
Yu, L., Jiang, W., Shi, H., Yu, J., Liu, Z., Zhang, Y., Kwok, J. T., Li, Z., Weller, A., 和 Liu, W. Metamath: 引导自己的数学问题给大型语言模型. arXiv 预印本 arXiv:2309.12284, 2023.
Zafrir, O., Larey, A., Boudoukh, G., Shen, H., 和 Wasserblat, M. 一次剪枝即可:稀疏预训练语言模型. arXiv 预印本 arXiv:2111.05754, 2021.
Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., 等人. 用mt-bench和Chatbot Arena评判LLM-as-a-judge. 神经信息处理系统进展, 36: 46595-46623, 2023.
Zhou, C., Liu, P., Xu, P., Iyer, S., Sun, J., Mao, Y., Ma, X., Efrat, A., Yu, P., Yu, L., 等人. Lima: 少即是多的对齐. 神经信息处理系统进展, 36, 2024.
A. 补充材料
A.1. 种子选择
图5展示了LLM中所有块的种子选择过程。从图中可以看出,后期层使选定的种子比初始层更加密集。在初始层中,选定的种子在簇中分布得更广,似乎更通用,而后期层则更具领域特定性。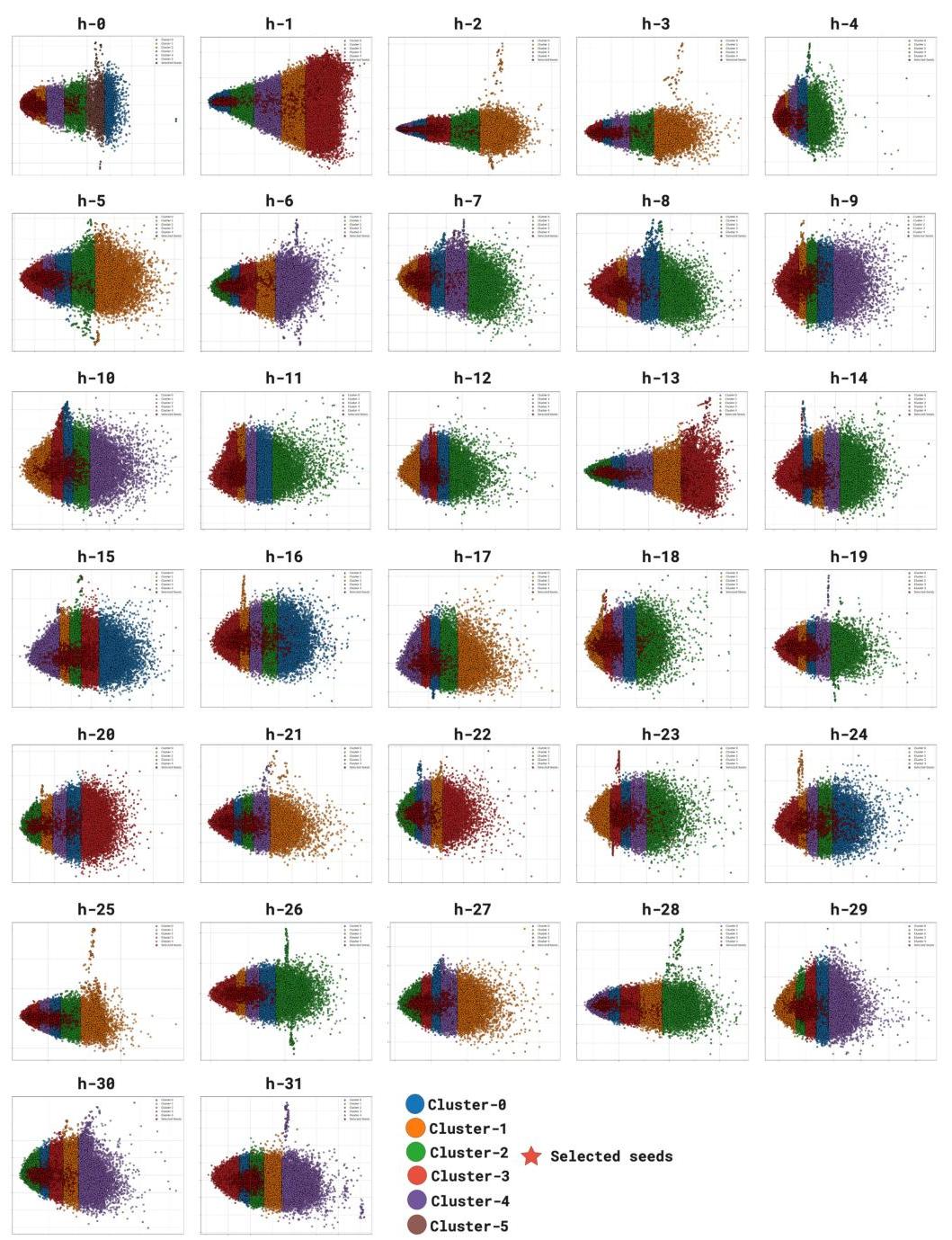
图5. 图4的扩展可视化
A.2. KKK对重建损失的影响
为了研究KKK的影响,我们进行了实验,改变其值并分析相应的重建损失。图6提供了图3的扩展可视化,说明了初始重建损失在不同层和块之间的波动情况。根据结果,我们确定K=96K=96K=96提供了信息保留和计算效率之间的最平衡权衡。在较低的KKK值下,SAE丢弃了太多的激活,导致失去构建高质量数据集所需的临界语义特征。相反,过高的KKK值保留了贡献很少额外信息的激活,增加了计算成本而没有显著提高表示质量。这一趋势在所有评估层中是一致的,强化了K=96K=96K=96在我们的领域特定模型适应任务中提供了最佳平衡。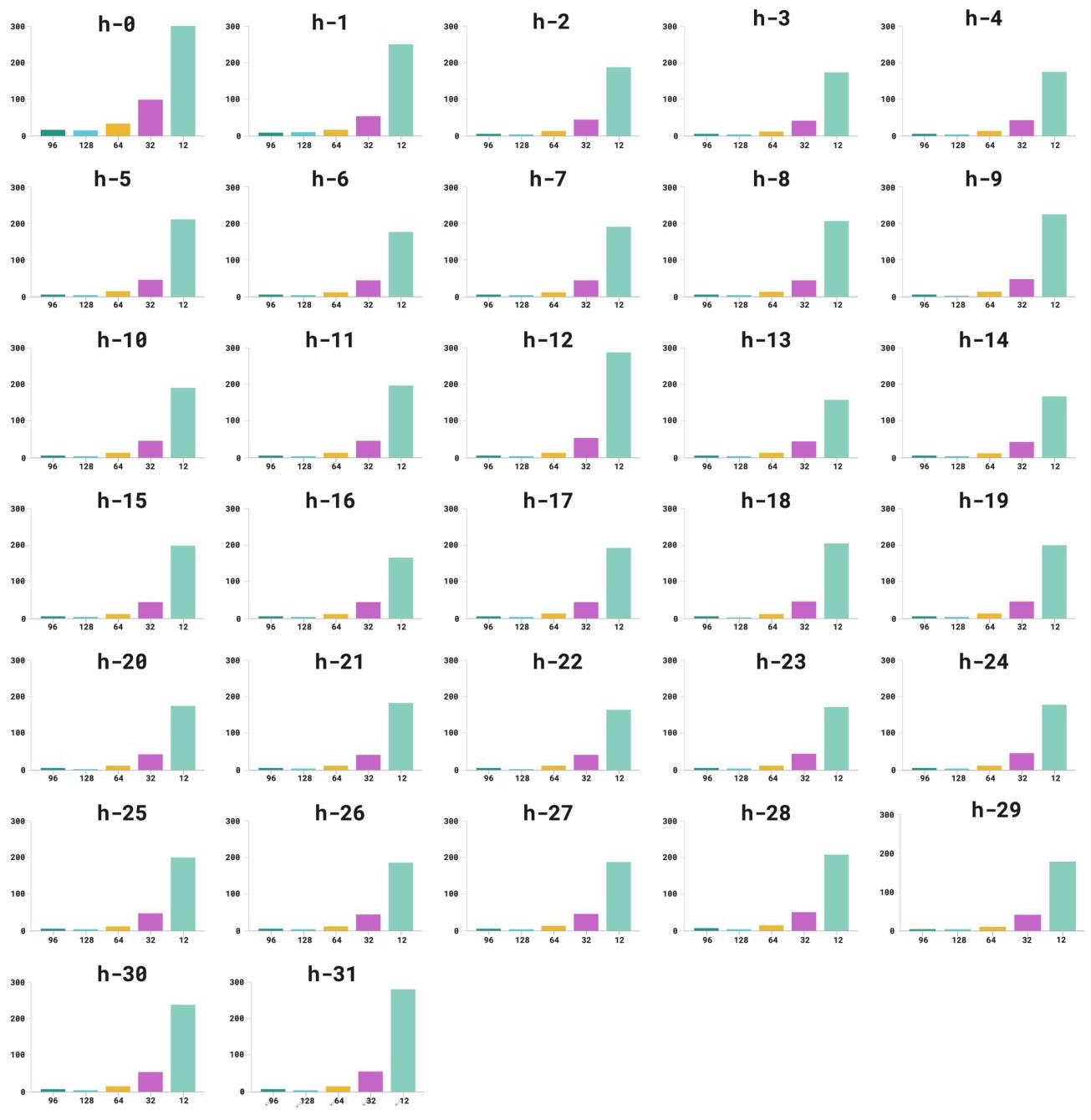
图6. 图3的扩展可视化
参考论文:https://arxiv.org/pdf/2505.00624

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 21
21 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)