SparseGPT:大语言模型可精准实现单次剪枝
本研究首次证明,大规模生成式预训练变换器(GPT)家族模型可通过单次剪枝实现至少50%的稀疏度,且无需任何重训练过程,精度损失极低。这一突破源于我们提出的新型剪枝方法SparseGPT——专为海量GPT类模型设计的高效精准剪枝方案。实验表明,SparseGPT可在4.5小时内完成当前最大开源模型OPT-175B和BLOOM-176B的剪枝处理,实现60%非结构化稀疏度的同时困惑度几乎无增长:这意味
本研究首次证明,大规模生成式预训练变换器(GPT)家族模型可通过单次剪枝实现至少50%的稀疏度,且无需任何重训练过程,精度损失极低。这一突破源于我们提出的新型剪枝方法SparseGPT——专为海量GPT类模型设计的高效精准剪枝方案。实验表明,SparseGPT可在4.5小时内完成当前最大开源模型OPT-175B和BLOOM-176B的剪枝处理,实现60%非结构化稀疏度的同时困惑度几乎无增长:这意味着推理阶段可忽略超过1000亿个权重参数。该方法还可推广至半结构化(2:4及4:8)稀疏模式,并与权重量化技术兼容。相关代码已开源:https://github.com/IST-DASLab/sparsegpt。
1. Introduction
生成式预训练变换器(GPT)家族的大语言模型(LLMs)虽在广泛任务中展现出卓越性能,但其庞大的规模与计算成本导致部署困难。以性能顶尖的GPT-175B模型为例,该模型拥有1750亿参数,仅半精度(FP16)格式存储就需占用至少320GB空间(以1024为换算基数),推理时需配备至少5块80GB显存的A100 GPU。因此,通过模型压缩降低成本的尝试备受关注。目前,现有GPT压缩方法几乎全部聚焦于量化技术(Dettmers等,2022;Yao等,2022;Xiao等,2022;Frantar等,2022a),即降低模型数值表示的精度。
作为补充的压缩手段,剪枝技术通过移除网络组件实现压缩——从单个权重(非结构化剪枝)到更高粒度的权重矩阵行列(结构化剪枝)均可操作。尽管剪枝技术历史悠久(LeCun等,1989;Hassibi等,1993)且在视觉和小规模语言模型中成效显著(Hoefler等,2021),但最优剪枝方法仍需大量重训练以恢复精度,这对GPT级模型而言成本极高。虽然存在部分精准的单次剪枝方法(Hubara等,2021a;Frantar等,2022b)可实现免重训练压缩,但当应用于百亿参数模型时,这些方法仍会产生难以承受的计算开销。因此,迄今为止尚未出现针对百亿参数模型的精准剪枝方案。
本文提出SparseGPT——首个能在百亿至千亿参数规模模型上高效实现的精准单次剪枝方法。该方法通过将剪枝问题转化为超大规模稀疏回归问题集,并采用新型近似稀疏回归求解器进行处理,仅需单块GPU即可在数小时内完成当前最大开源GPT模型(1750亿参数)的剪枝处理,且无需微调即可保持精度损失可忽略不计。例如,在最大公开生成语言模型OPT-175B和BLOOM-176B上,SparseGPT单次剪枝即可实现50-60%的稀疏度,无论困惑度还是零样本准确率均仅轻微下降。
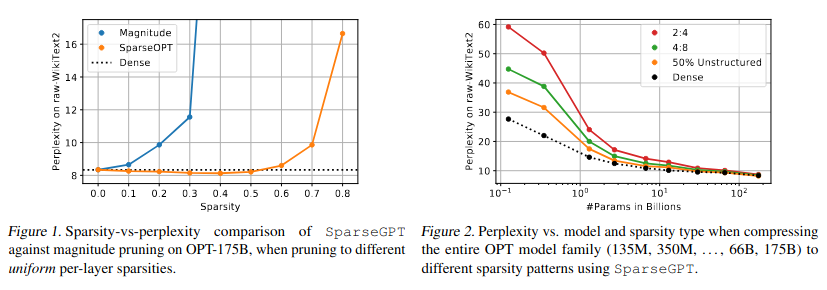
如图1-2所示的核心实验结果揭示:首先,SparseGPT可在OPT-175B等模型上实现各层均匀的60%稀疏度(图1),而传统单次剪枝基线方法Magnitude Pruning(Hagiwara,1994;Han等,2015)仅在10%稀疏度内保持精度,超过30%即完全失效;其次,SparseGPT还能精准实现硬件友好的2:4与4:8半结构化稀疏模式(图2),尽管较小模型会相对稠密模型存在一定精度损失。
如图2所示的核心发现表明:模型规模与可压缩性呈正相关——在相同稀疏度下,大模型比小模型的精度下降更轻微(例如OPT和BLOOM系列的最大模型能在困惑度几乎不变的情况下实现50%稀疏化)。此外,本方法可与权重量化技术(Frantar等,2022a)协同应用:以OPT-175B为例,当联合实施50%权重稀疏化与4比特量化时,困惑度增长仍可忽略不计。
SparseGPT的显著特性在于其完全局部化的计算方式——仅依赖旨在保持各层输入输出关系的权重更新,无需任何全局梯度信息。令人惊讶的是,这种方法能直接在稠密预训练模型的"邻域"中识别出稀疏模型,且其输出与原始稠密模型保持高度一致。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)