一文理解大语言模型推理和相关优化
本文拆解大语言模型推理的工作流程,计算时间分布和显存占用分布,进而分析对应的优化策略,可以通过本文理解为什么优化策略朝着这个方向做。本文数据和内容引用自A Survey on Efficient Inference for Large Language Models,感兴趣的读者可以参考更多细节信息。(1)工作流和步骤分解:最受欢迎的大型语言模型(LLMs),即仅解码器结构的LLMs,通常采用自回
本文拆解大语言模型推理的工作流程,计算时间分布和显存占用分布,进而分析对应的优化策略,可以通过本文理解为什么优化策略朝着这个方向做。本文数据和内容引用自A Survey on Efficient Inference for Large Language Models,感兴趣的读者可以参考更多细节信息。
(1)工作流和步骤分解:
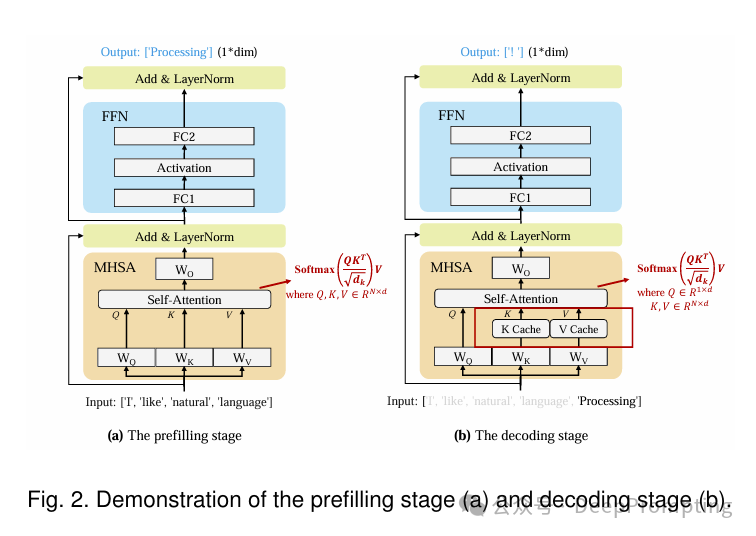
最受欢迎的大型语言模型(LLMs),即仅解码器结构的LLMs,通常采用自回归方法来生成输出句子。具体来说,自回归方法是逐个生成词元。在每一步生成过程中,LLM会将整个词元序列作为输入,包括输入的词元和之前生成的词元,然后生成下一个词元。随着序列长度的增加,生成过程的时间成本急剧增加。为了解决这一挑战,引入了一项关键技术,即键值(KV)缓存,以加快生成过程。正如其名称所示,KV缓存技术涉及在多头自注意力(MHSA)模块中存储和重用之前的键(K)和值(V)对。由于这一技术显著优化了生成时延,它被广泛应用于LLM推理引擎和系统中。
基于上述方法和技术,LLM的推理过程可分为两个阶段:
-
预填充阶段:LLM计算并存储初始输入词元的KV缓存,并生成第一个输出词元,如图2(a)所示。
-
解码阶段:LLM使用KV缓存逐个生成输出词元,然后用新生成词元的键(K)和值(V)对更新缓存,如图2(b)所示。
图中区别在关键的红色公式部分的向量和矩阵维度可以对比。
(2)显存占用和解码每个token阶段时间占比分析
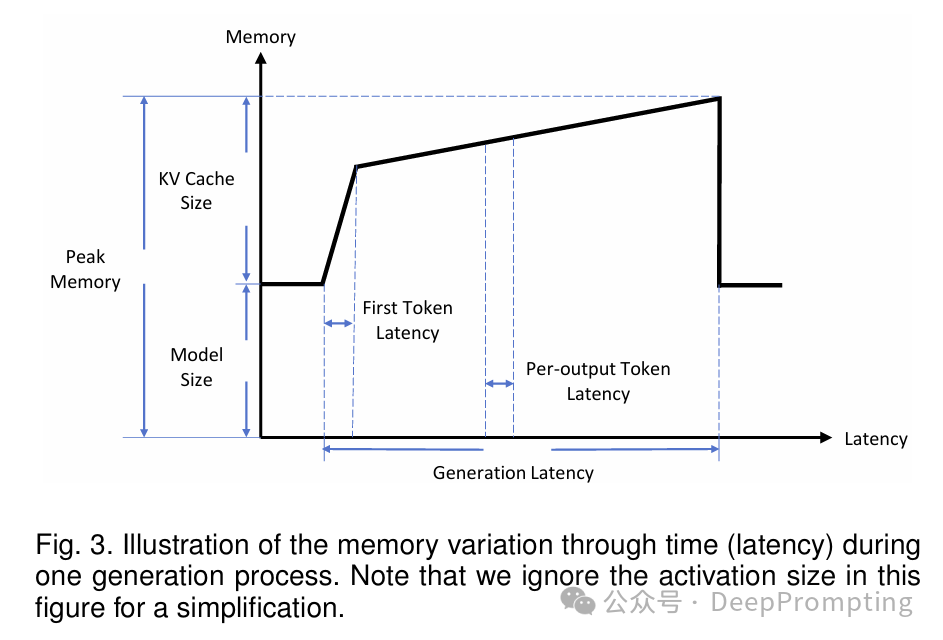
如图3所示,我们展示了一些关键的效率指标。对于时延,我们将首个词元时延定义为预填充阶段生成首个输出词元的时延,而将每词元时延定义为解码阶段生成单个输出词元的平均时延。此外,我们使用生成时延来表示生成整个输出词元序列的时延。对于内存,我们用模型大小来表示存储模型权重所需的内存,KV缓存大小表示存储KV缓存所需的内存。此外,峰值内存表示生成过程中使用的最大内存,大致等于模型权重和KV缓存的内存总和。除了时延和内存,吞吐量也是LLM服务系统中广泛使用的一个指标。我们用词元吞吐量表示每秒生成的词元数量,用请求吞吐量表示每秒完成的请求数量。
显存方面围绕如何优化KV Cache,和优化模型尺寸做压缩优化。
时间方面可以优化prefilling部分和后续拆解不同操作符类型(Attention和Linear)进行优化。
(3)计算时间按运算符类型分解
注意力机制的优化:
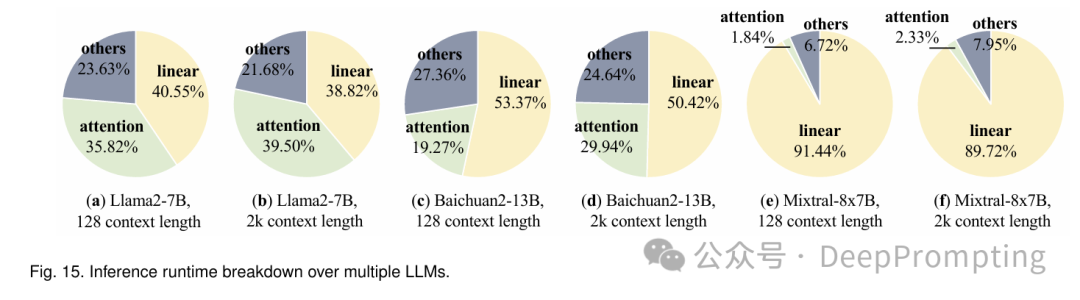
如图15所示,随着上下文长度的增加,注意力操作的时间占比也随之增加。这对内存大小和计算能力提出了较高的要求,尤其是在处理长序列时。为了应对标准注意力计算在GPU上带来的计算和内存开销,定制化的注意力操作符变得至关重要。FlashAttention [255], [256] 将整个注意力操作融合成一个高效的内存操作符,以减少内存访问的开销。输入矩阵(Q, K, V)和注意力矩阵被划分为多个块,从而避免了完整数据加载的需求。在FlashAttention的基础上,FlashDecoding [259] 旨在最大化解码过程中的计算并行性。由于在解码过程中应用了特定方法,Q矩阵在解码时退化为一批向量,这使得如果并行性仅限于批量大小维度时,填充计算单元变得困难。FlashDecoding通过在序列维度上引入并行计算解决了这一问题。虽然这给softmax计算引入了一些同步开销,但在小批量大小和长序列的情况下,显著提升了并行性。后续的研究工作FlashDecoding++ [253] 观察到,在之前的研究[255], [256], [259]中,softmax中的最大值仅作为一个缩放因子,用于防止数据溢出。然而,动态的最大值会带来显著的同步开销。此外,大量实验表明,在典型的大语言模型(如Llama2 [261], ChatGLM [262])中,99.99%的softmax输入都落在某个特定范围内。因此,FlashDecoding++提出基于预先的统计数据来确定缩放因子。这样可以消除softmax计算中的同步开销,从而实现softmax计算与后续操作的并行执行。
线性层优化:
线性算子在LLM推理中扮演着至关重要的角色,主要用于特征投影和前馈神经网络(FFN)。在传统的神经网络中,线性算子可以抽象为一般矩阵-矩阵乘法(GEMM)操作。然而,在LLM中,解码方法的应用导致维度显著降低,与传统的GEMM工作负载有所不同。传统GEMM的低级实现已经高度优化,主流的LLM框架(例如DeepSpeed [258]、vLLM [51]、OpenPPL [263]等)主要调用cuBLAS [264]提供的GEMM API来执行线性算子。如果没有针对降维GEMM的专门实现,解码过程中的线性算子会面临效率问题。为了解决这一问题,最新发布的TensorRT-LLM [222]引入了一种专用的矩阵-向量乘法(GEMV)实现,有望提高解码步骤的效率。
最近的研究FlashDecoding++ [253]进一步解决了cuBLAS [264]和CUTLASS [265]库在解码步骤中处理小批量时的低效率问题。研究人员首先引入了FlatGEMM操作的概念,用于表示具有高度降维的GEMM工作负载(维度大小<8)。由于FlatGEMM具有新的计算特性,传统GEMM的分块策略需要进行修改。研究人员观察到,随着工作负载的变化,存在两个挑战:低并行性和内存访问瓶颈。为了解决这些挑战,FlashDecoding++采用了细粒度的分块策略来提高并行性,并利用双缓冲技术隐藏内存访问延迟。此外,鉴于典型LLM(如Llama2 [261]、ChatGLM [262])中的线性操作通常具有固定的形状,FlashDecoding++建立了一种启发式选择机制,动态地根据输入大小在不同的线性算子之间进行选择。可选的算子包括FastGEMV [266]、FlatGEMM和cuBLAS [264]、[265]库提供的GEMM。该方法确保为给定的线性工作负载选择最有效的算子,从而可能提高端到端的性能。
近年来,应用MoE FFN(专家前馈神经网络)来增强模型能力已成为LLM中的一种趋势 [12]。这种模型结构对算子优化提出了新的要求。如图15所示,在采用MoE FFN的Mixtral模型中,由于HuggingFace实现中的FFN计算未优化,线性算子主导了运行时。此外,Mixtral采用的GQA注意力结构减少了注意力算子的运行时比例,进一步指出了优化FFN层的迫切需求。MegaBlocks [254]是首个优化MoE FFN层计算的工作。该工作将MoE FFN计算公式化为块稀疏操作,并提出了针对GPU加速的定制内核。然而,MegaBlocks集中于MoE模型的高效训练,因此忽视了推理阶段的特点(例如解码方法)。现有的框架正在努力优化MoE FFN推理阶段的计算。vLLM [51]的官方仓库将MoE FFN的融合内核集成到Triton [267]中,顺利地去除了索引开销。
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。


三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


四、LLM面试题


五、AI产品经理面试题

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]👈

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 15
15 0
0- 0



 已为社区贡献140条内容
已为社区贡献140条内容

所有评论(0)