探索ToolLLM:让大语言模型掌握1.6万+真实世界API的强大框架
在人工智能领域,大语言模型(LLMs)的发展日新月异,但开源LLMs在工具使用能力方面,与闭源的先进模型(如ChatGPT)相比,仍存在明显差距。清华大学等机构的研究团队推出了ToolLLM框架,旨在填补这一空白,让开源LLMs能够熟练掌握各种API工具。下面将详细介绍这一具有创新性的研究成果。
探索ToolLLM:让大语言模型掌握1.6万+真实世界API的强大框架
在人工智能领域,大语言模型(LLMs)的发展日新月异,但开源LLMs在工具使用能力方面,与闭源的先进模型(如ChatGPT)相比,仍存在明显差距。清华大学等机构的研究团队推出了ToolLLM框架,旨在填补这一空白,让开源LLMs能够熟练掌握各种API工具。下面将详细介绍这一具有创新性的研究成果。
研究背景与目标
当前,开源LLMs(如LLaMA)通过指令微调已具备多种能力,但在工具使用方面,即利用外部工具(API)完成人类指令的能力上,表现仍不尽如人意。造成这一现象的主要原因是,当前的指令微调大多聚焦于基础语言任务,而忽视了工具使用领域。与之形成对比的是,最先进的闭源LLMs(如ChatGPT和GPT-4)在工具使用方面展现出了卓越能力,但它们的内部机制不透明,这在一定程度上限制了AI技术的民主化以及社区驱动的创新与发展。
有鉴于此,研究团队致力于赋予开源LLMs熟练掌握各种API的能力,推出了ToolLLM这一通用工具使用框架,该框架涵盖了数据构建、模型训练和评估等方面,旨在提升开源LLMs的工具使用能力,使其能更好地满足实际应用需求。
ToolLLM框架详解
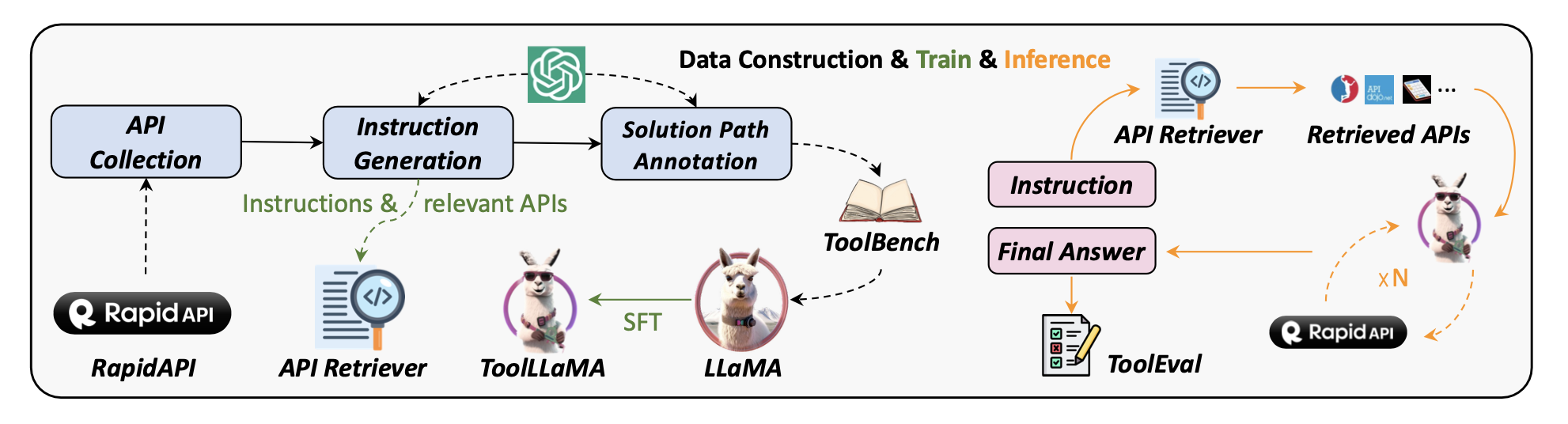
ToolBench数据集:开启工具学习的大门
ToolBench是一个用于工具使用的指令微调数据集,它的构建过程颇具创新性,主要借助ChatGPT自动完成,具体可分为三个阶段:
- API收集:研究团队从RapidAPI Hub收集了16,464个真实的RESTful API,这些API横跨49个类别,涵盖了社交媒体、电子商务、天气等多个领域。对于每个API,都爬取了详细的文档,包括功能描述、所需参数、API调用代码片段等。这些丰富的信息为LLMs理解和执行API提供了有力支持,使其能够在训练后泛化到未见过的新API。

- 指令生成:先从整个API集合中抽样,然后提示ChatGPT为这些API生成多样化的指令,覆盖单工具和多工具场景。为了确保指令的多样性和实用性,采用了不同的抽样策略。例如,对于单工具指令,遍历每个工具为其API生成指令;对于多工具场景,利用RapidAPI的层次结构信息,从同一类别或集合中随机选择2-5个工具,每个工具最多抽样3个API来生成指令,这样生成的指令更符合真实世界的复杂任务需求。
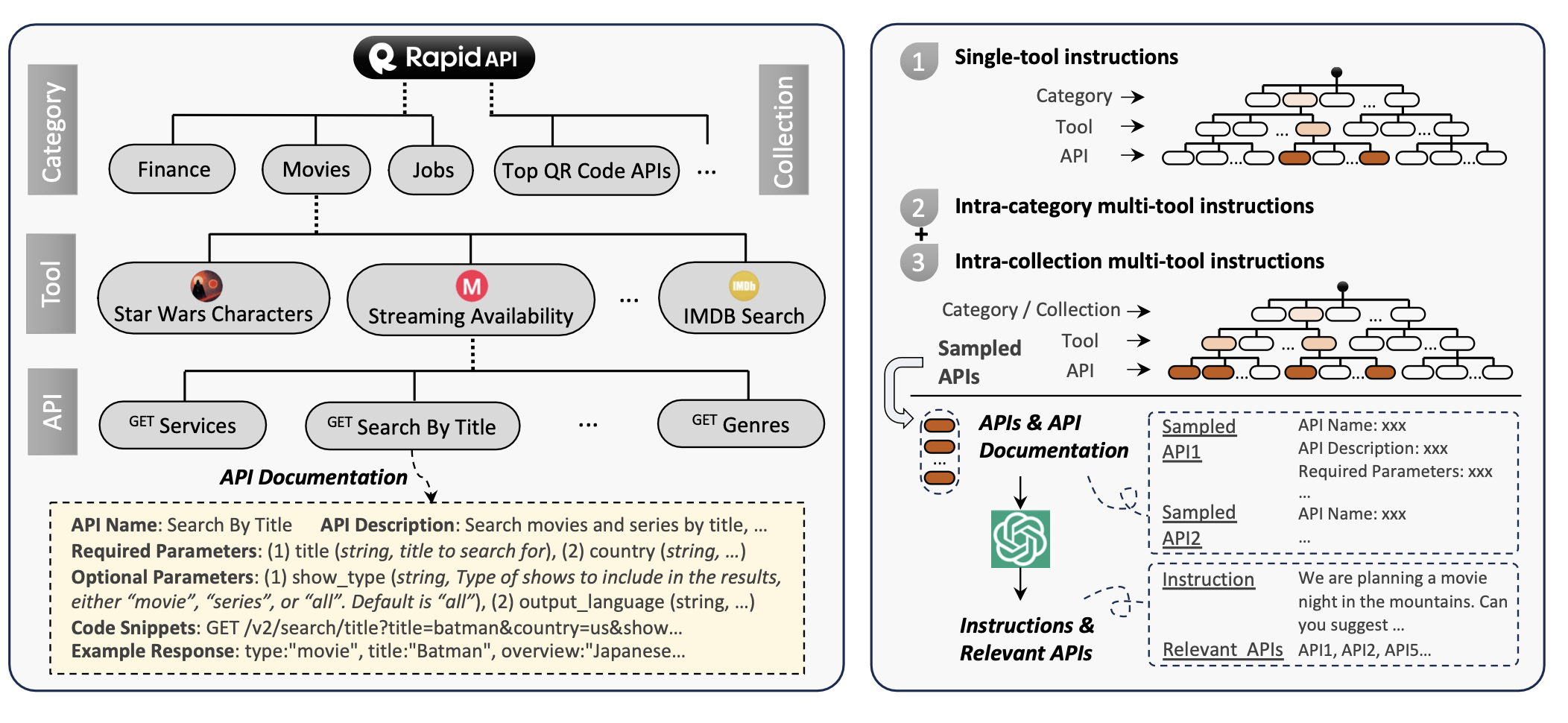
3. 解决方案路径标注:为每个指令标注解决方案路径是一项具有挑战性的任务,即使是最先进的LLM(如GPT-4)在处理复杂人类指令时通过率也较低。为此,研究团队开发了一种基于深度优先搜索的决策树算法(DFSDT),它使LLMs能够评估多个推理路径,扩展搜索空间,有效提高了标注效率,成功完成了许多仅用ReACT无法满足的复杂指令标注。最终生成了126,486个(指令,解决方案路径)对,用于训练ToolLLaMA。
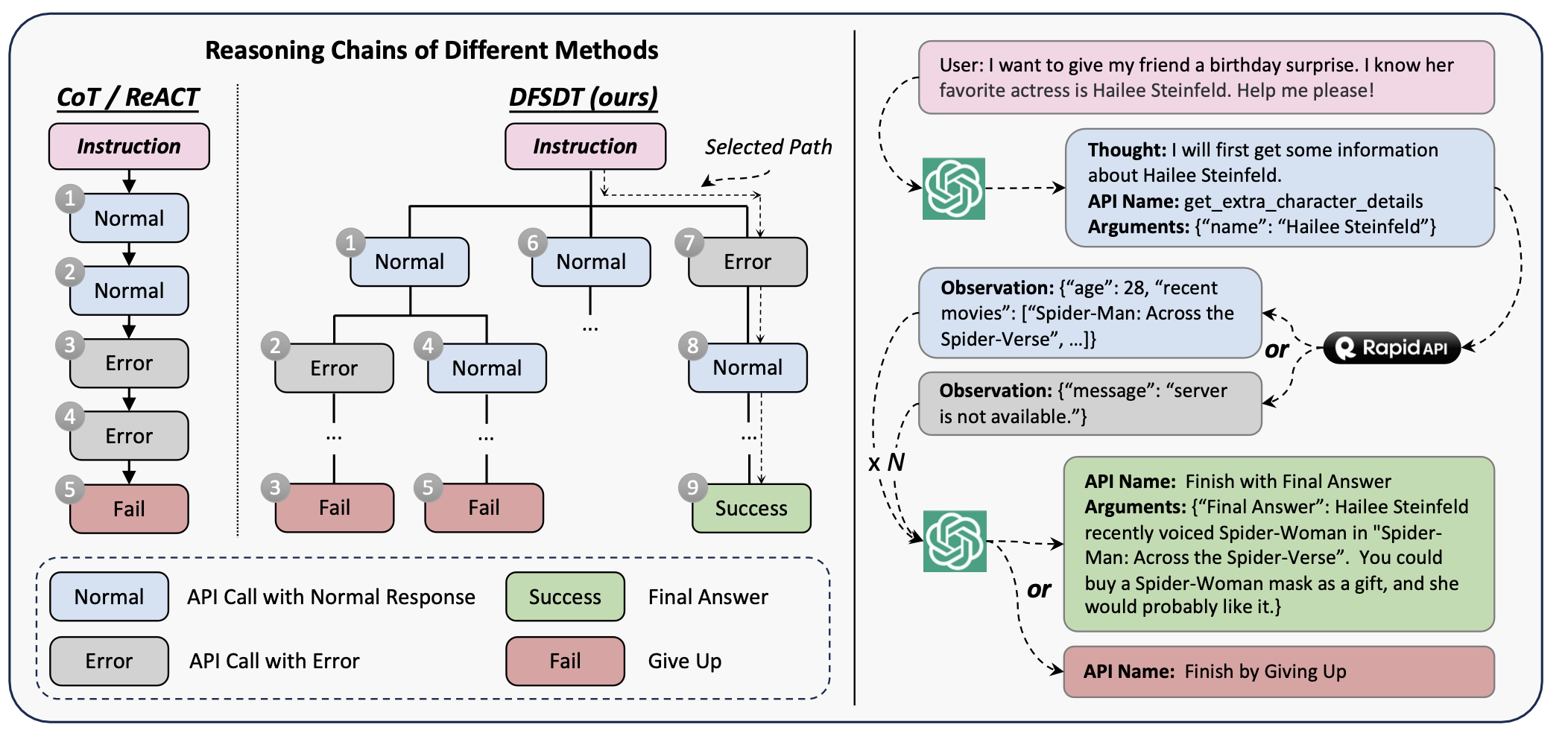
DFSDT算法:提升LLMs的推理能力
传统的CoT(思维链)或ReACT(推理与行动结合)方法在模型推理中存在明显局限性。一方面,错误容易传播,一个错误的行动可能会进一步传播错误,导致模型陷入错误循环;另一方面,探索范围有限,只能探索一个可能的方向,难以找到有效的解决方案路径。
DFSDT算法的提出很好地解决了这些问题。它允许模型评估不同的推理路径,并选择是沿着有希望的路径继续前进,还是通过调用“Finish by Giving Up”函数放弃现有节点并扩展新节点。在节点扩展过程中,通过提示ChatGPT生成不同的节点来多样化子节点,扩展搜索空间。在搜索过程中,采用深度优先搜索(DFS)而非广度优先搜索(BFS),因为只要找到一条有效路径即可完成标注,能节省大量的OpenAI API调用成本。实验表明,DFSDT在所有场景下都显著优于传统的ReACT方法,尤其在处理较难的指令时,性能提升更为明显。
ToolEval:高效的工具使用评估器
由于API具有时间可变性,且每个指令可能有无限的潜在解决方案路径,为每个测试指令标注固定的地面真实解决方案路径是不可行的。同时,人工评估耗时费力。因此,研究团队开发了基于ChatGPT的自动评估器ToolEval,它包含两个关键指标:
-
通过率:计算在有限预算内成功完成指令的比例,衡量LLM执行指令的能力,是理想工具使用的基本要求。
-
胜率:向ChatGPT评估器提供一个指令和两个解决方案路径,获取其偏好,比较两个解决方案路径的质量和有用性。
经过严格测试,ToolEval与人类注释者在通过率上的一致性为87.1%,在胜率上的一致性为80.3%,能够在很大程度上反映和代表人类评估,为机器工具使用提供了稳健、可扩展和可靠的评估。
ToolLLaMA:性能卓越的工具使用模型
通过在ToolBench上对LLaMA进行微调,得到了ToolLLaMA模型。为了适应API响应可能很长的情况,使用位置插值将上下文长度扩展到8192。
ToolLLaMA在处理单工具和复杂多工具指令方面表现出强大能力。实验结果显示,它超越了Text-Davinci-003和Claude-2,性能与“教师模型”ChatGPT相当,仅略逊于GPT-4。此外,它对以前未见过的API具有强大的泛化能力,只需API文档即可有效适应新API,这使得用户能够无缝集成新API,增强了模型的实际实用性。
API检索器:智能推荐合适的API
在实际应用中,让用户从大量API中手动选择相关API并不现实。为此,研究团队训练了一个神经API检索器,它基于Sentence-BERT,将指令和API文档编码为两个嵌入,并通过嵌入相似度计算它们的相关性。实验表明,该检索器在所有设置下都始终优于BM25和OpenAI的text-embedding-ada-002等基线方法,具有出色的检索精度,能够返回与地面真实情况紧密一致的API。当将检索器与ToolLLaMA集成时,即使使用检索到的API(而非地面真实API集),性能也得到了提升,这表明检索器能够扩展相关API的搜索空间,为当前指令找到更合适的API。
实验与评估
主要实验结果
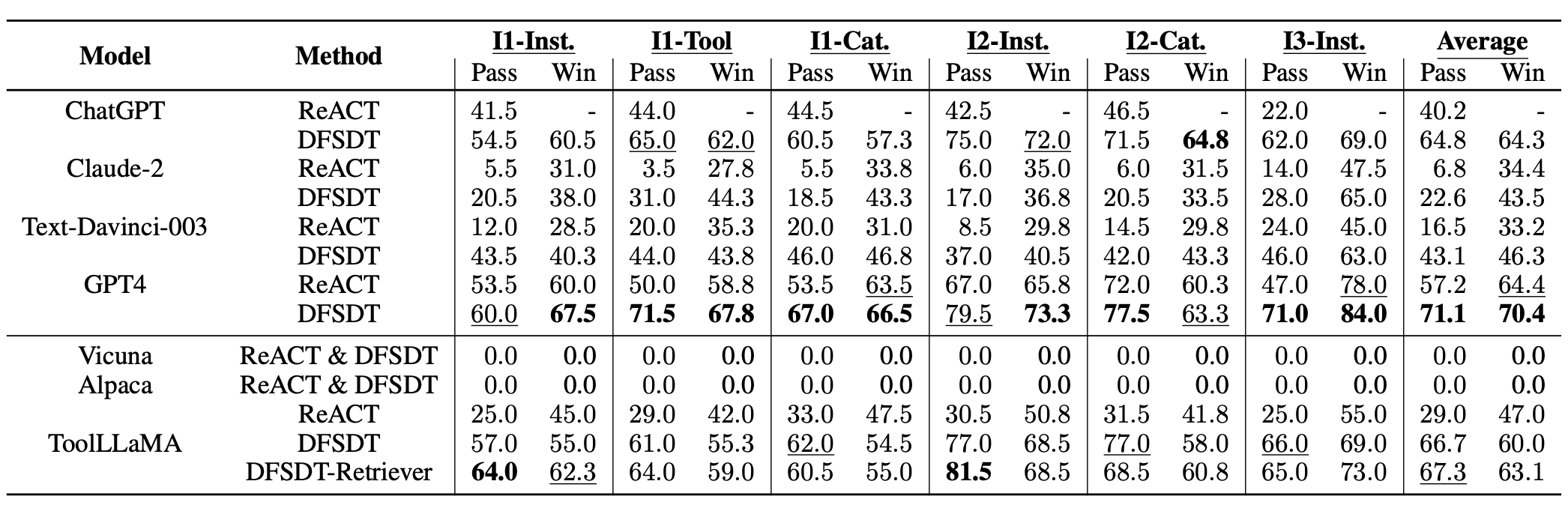
在ToolBench上的实验表明,Vicuna和Alpaca在工具使用方面表现不佳,通过率和胜率均为0,这凸显了当前指令微调的不足,即主要关注语言技能,而忽视了工具使用领域。对于所有LLMs,使用DFSDT在通过率和胜率上都显著优于ReACT。ToolLLaMA在使用DFSDT时,性能远超Text-Davinci-003和Claude-2,与ChatGPT表现相当,在所有场景下都展现出了具有竞争力的泛化性能,通过率仅次于GPT4+DFSDT。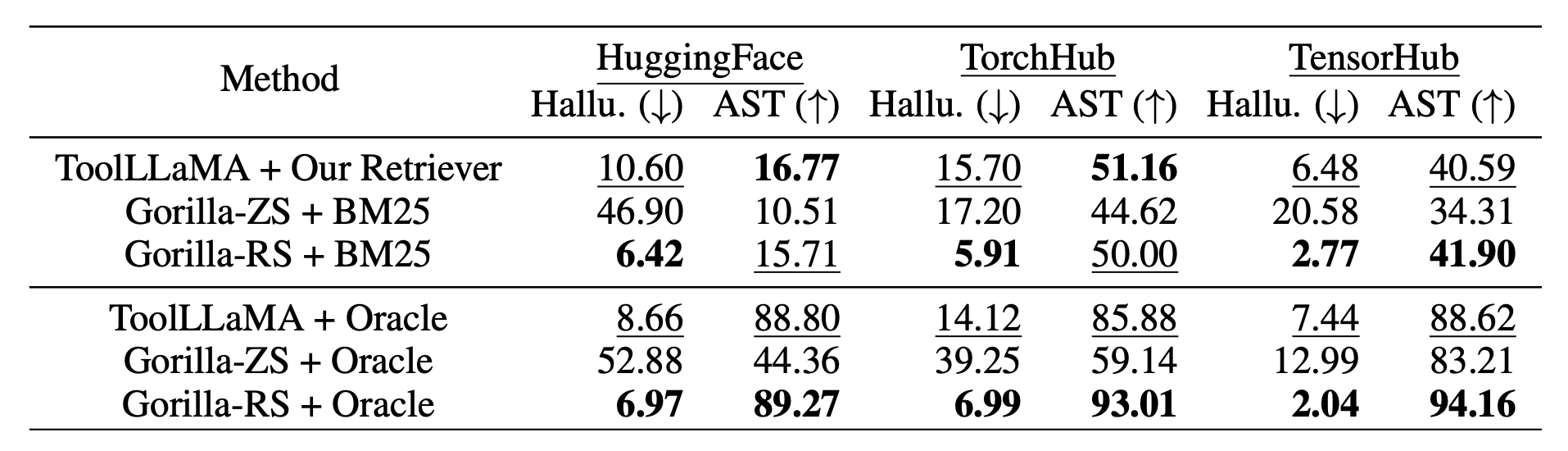
跨领域泛化能力
为了验证ToolLLaMA的跨领域泛化能力,研究团队在OOD数据集APIBench上进行了实验。结果显示,尽管ToolLLaMA是在完全不同的API领域和指令领域进行训练的,但在所有三个数据集(HuggingFace、TorchHub和TensorHub)上都取得了显著的泛化性能。在HuggingFace和TorchHub上,ToolLLaMA+API检索器在AST准确性上优于Gorilla+BM25(无论是零-shot还是检索感知设置)。在相同的oracle检索器下,ToolLLaMA始终优于Gorilla-ZS。
结论与未来展望
ToolLLM框架为开源LLMs的工具使用能力提升开辟了新途径。通过构建大规模、高质量的ToolBench数据集,开发DFSDT推理算法和ToolEval评估器,以及训练ToolLLaMA模型和API检索器,研究团队成功提升了开源LLMs的工具使用能力,使其在复杂指令处理和新API泛化方面表现出色。
未来,该领域还有许多值得探索的方向。例如,可以进一步扩大数据集的规模和覆盖范围,探索更高效的模型训练方法,研究如何让LLMs更好地处理更复杂的工具组合和动态变化的环境,以及如何进一步提高评估的准确性和公平性等。ToolLLM的研究成果为LLMs与真实世界工具的深度集成奠定了坚实基础,有望在更多实际应用场景中发挥重要作用。
如果你对ToolLLM的具体实现细节感兴趣,可以访问项目的GitHub页面(https://github.com/OpenBMB/ToolBench),获取代码、训练模型和演示示例。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 20
20 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)