多模态大模型入门到精通:从核心原理到最新进展,收藏这篇就够了!
这篇论文提出了一种名为“Brain-like Space”的创新概念,旨在为不同类型的AI模型创建一个统一的几何空间,以便与人类大脑的功能网络进行比较。动机是解决现有脑与AI系统对比研究中输入和任务依赖的问题。
- A Unified Geometric Space Bridging AI Models and the Human Brain
- Video-Thinker: Sparking “Thinking with Videos” via Reinforcement Learning
- RoboOmni: Proactive Robot Manipulation in Omni-modal Context
- FairJudge: MLLM Judging for Social Attributes and Prompt Image Alignment
- S-Chain: Structured Visual Chain-of-Thought For Medicine
- Evaluating Multimodal Large Language Models on Core Music Perception Tasks
- Toward Socially-Aware LLMs: A Survey of Multimodal Approaches to Human Behavior Understanding
- Latent Sketchpad: Sketching Visual Thoughts to Elicit Multimodal Reasoning in MLLMs
- DynaSolidGeo: A Dynamic Benchmark for Genuine Spatial Mathematical Reasoning of VLMs in Solid Geometry
- BLM: A Boundless Large Model for Cross-Space, Cross-Task, and Cross-Embodiment Learning
1.A Unified Geometric Space Bridging AI Models and the Human Brain
Authors: Silin Chen, Yuzhong Chen, Zifan Wang, Junhao Wang, Zifeng Jia, Keith M Kendrick, Tuo Zhang, Lin Zhao, Dezhong Yao, Tianming Liu, Xi Jiang
Affiliations: University of Electronic Science and Technology of China; Northwestern Polytechnical University; New Jersey Institute of Technology; University of Georgia
https://arxiv.org/abs/2510.24342
论文摘要
For decades, neuroscientists and computer scientists have pursued a shared ambition: to understand intelligence and build it. Modern artificial neural networks now rival humans in language, perception, and reasoning, yet it is still largely unknown whether these artificial systems organize information as the brain does. Existing brain-AI alignment studies have shown the striking correspondence between the two systems, but such comparisons remain bound to specific inputs and tasks, offering no common ground for comparing how AI models with different kinds of modalities-vision, language, or multimodal-are intrinsically organized. Here we introduce a groundbreaking concept of Brain-like Space: a unified geometric space in which every AI model can be precisely situated and compared by mapping its intrinsic spatial attention topological organization onto canonical human functional brain networks, regardless of input modality, task, or sensory domain. Our extensive analysis of 151 Transformer-based models spanning state-of-the-art large vision models, large language models, and large multimodal models uncovers a continuous arc-shaped geometry within this space, reflecting a gradual increase of brain-likeness; different models exhibit distinct distribution patterns within this geometry associated with different degrees of brain-likeness, shaped not merely by their modality but by whether the pretraining paradigm emphasizes global semantic abstraction and whether the positional encoding scheme facilitates deep fusion across different modalities. Moreover, the degree of brain-likeness for a model and its downstream task performance are not “identical twins”. The Brain-like Space provides the first unified framework for situating, quantifying, and comparing intelligence across domains, revealing the deep organizational principles that bridge machines and the brain.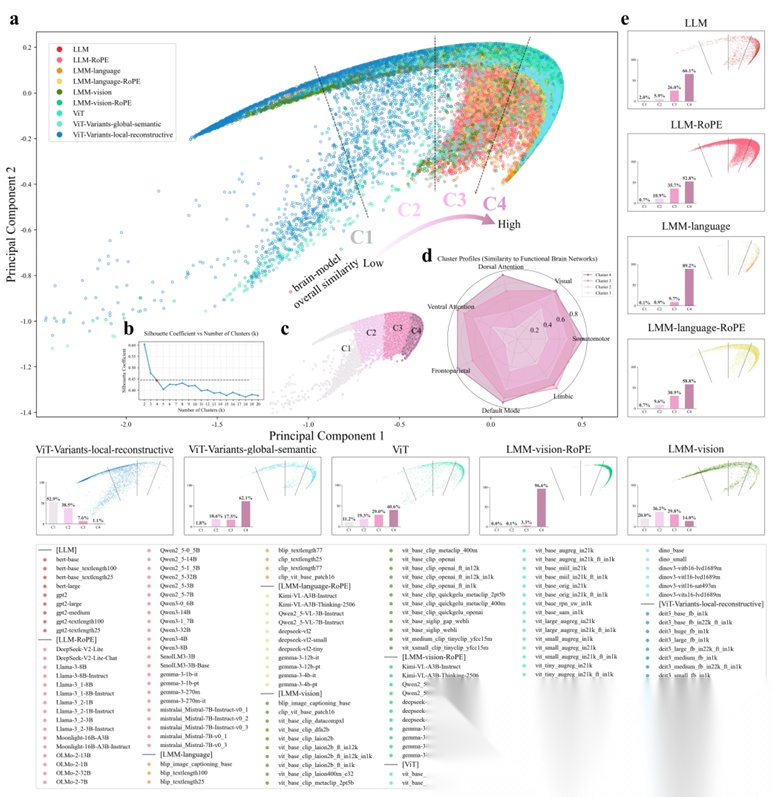
论文简评: 这篇论文提出了一种名为“Brain-like Space”的创新概念,旨在为不同类型的AI模型创建一个统一的几何空间,以便与人类大脑的功能网络进行比较。动机是解决现有脑与AI系统对比研究中输入和任务依赖的问题。通过将Transformer模型的空间注意力模式映射到基于人类大脑网络的拓扑结构,作者发现了一种反映模型脑相似度的连续几何结构。实验结果表明,不同的模型在该空间中展示出不同的分布模式,受到模型的模态、预训练范式及位置编码方案的影响。这一框架为跨领域比较智能提供了新的基础。
2.Video-Thinker: Sparking “Thinking with Videos” via Reinforcement Learning
Authors: Shijian Wang, Jiarui Jin, Xingjian Wang, Linxin Song, Runhao Fu, Hecheng Wang, Zongyuan Ge, Yuan Lu, Xuelian Cheng
Affiliations: Southeast University; Monash University; Xiaohongshu Inc.; University of Southern California; Fudan University
https://arxiv.org/abs/2510.23473
论文摘要
Recent advances in image reasoning methods, particularly “Thinking with Images”, have demonstrated remarkable success in Multimodal Large Language Models (MLLMs); however, this dynamic reasoning paradigm has not yet been extended to video reasoning tasks. In this paper, we propose Video-Thinker, which empowers MLLMs to think with videos by autonomously leveraging their intrinsic “grounding” and “captioning” capabilities to generate reasoning clues throughout the inference process. To spark this capability, we construct Video-Thinker-10K, a curated dataset featuring autonomous tool usage within chain-of-thought reasoning sequences. Our training strategy begins with Supervised Fine-Tuning (SFT) to learn the reasoning format, followed by Group Relative Policy Optimization (GRPO) to strengthen this reasoning capability. Through this approach, Video-Thinker enables MLLMs to autonomously navigate grounding and captioning tasks for video reasoning, eliminating the need for constructing and calling external tools. Extensive experiments demonstrate that Video-Thinker achieves significant performance gains on both in-domain tasks and challenging out-of-domain video reasoning benchmarks, including Video-Holmes, CG-Bench-Reasoning, and VRBench. Our Video-Thinker-7B substantially outperforms existing baselines such as Video-R1 and establishes state-of-the-art performance among 7B-sized MLLMs.

论文简评: 这篇论文探讨了如何在多模态大型语言模型(MLLMs)中实现视频推理的能力。为此,作者提出了Video-Thinker框架,利用“定位”和“字幕生成”操作来增强模型的推理能力,并构建了一个新的数据集Video-Thinker-10K。通过监督微调和群体相对策略优化的训练策略,该框架能够在无需外部工具的情况下实现视频推理。在多个视频推理基准测试中,Video-Thinker-7B在7B大小的MLLMs中表现优异,超越了现有的基线模型。
3.RoboOmni: Proactive Robot Manipulation in Omni-modal Context
Authors: Siyin Wang, Jinlan Fu, Feihong Liu, Xinzhe He, Huangxuan Wu, Junhao Shi, Kexin Huang, Zhaoye Fei, Jingjing Gong, Zuxuan Wu, Yugang Jiang, See-Kiong Ng, Tat-Seng Chua, Xipeng Qi
Affiliations: Fudan University; Shanghai Innovation Institute; National University of Singapore
https://arxiv.org/abs/2510.23763
论文摘要
Recent advances in Multimodal Large Language Models (MLLMs) have driven rapid progress in Vision-Language-Action (VLA) models for robotic manipulation. Although effective in many scenarios, current approaches largely rely on explicit instructions, whereas in real-world interactions, humans rarely issue instructions directly. Effective collaboration requires robots to infer user intentions proactively. In this work, we introduce cross-modal contextual instructions, a new setting where intent is derived from spoken dialogue, environmental sounds, and visual cues rather than explicit commands. To address this new setting, we present RoboOmni, a Perceiver-Thinker-Talker-Executor framework based on end-to-end omni-modal LLMs that unifies intention recognition, interaction confirmation, and action execution. RoboOmni fuses auditory and visual signals spatiotemporally for robust intention recognition, while supporting direct speech interaction. To address the absence of training data for proactive intention recognition in robotic manipulation, we build OmniAction, comprising 140k episodes, 5k+ speakers, 2.4k event sounds, 640 backgrounds, and six contextual instruction types. Experiments in simulation and real-world settings show that RoboOmni surpasses text- and ASR-based baselines in success rate, inference speed, intention recognition, and proactive assistance.
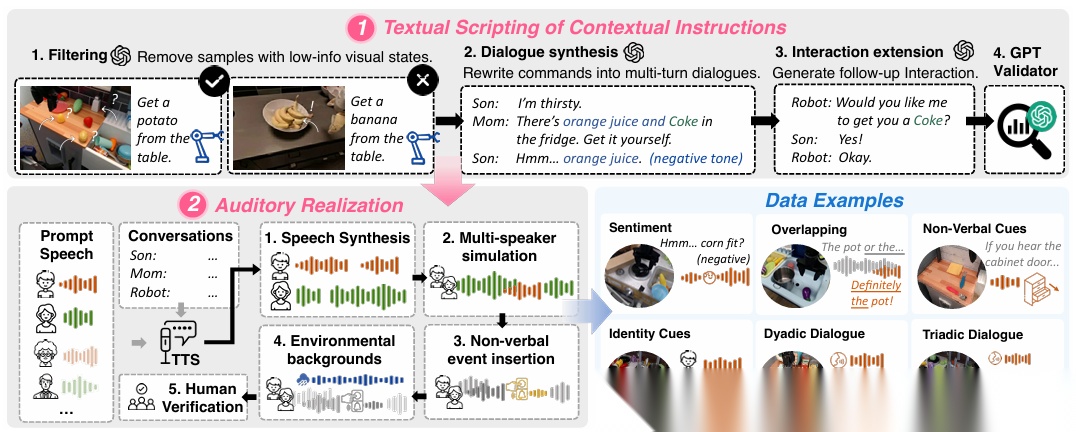
论文简评: 该论文旨在解决机器人在真实世界中需要主动推断用户意图的问题,提出了一种名为RoboOmni的新框架。RoboOmni结合视觉、听觉和语言信号,通过端到端的多模态大语言模型实现意图识别、交互确认和动作执行。为应对数据稀缺,该研究构建了OmniAction数据集,并通过实验验证RoboOmni在成功率、推理速度和主动帮助等方面优于基于文本和语音识别的基线模型。
4.FairJudge: MLLM Judging for Social Attributes and Prompt Image Alignment
Authors: Zahraa Al Sahili, Maryam Fetanat, Maimuna Nowaz, Ioannis Patras, Matthew Purve
Affiliations: Queen Mary University of London; Imperial College London; Institut Jožef Stefan
https://arxiv.org/abs/2510.22827
论文摘要
Text-to-image (T2I) systems lack simple, reproducible ways to evaluate how well images match prompts and how models treat social attributes. Common proxies – face classifiers and contrastive similarity – reward surface cues, lack calibrated abstention, and miss attributes only weakly visible (for example, religion, culture, disability). We present FairJudge, a lightweight protocol that treats instruction-following multimodal LLMs as fair judges. It scores alignment with an explanation-oriented rubric mapped to [-1, 1]; constrains judgments to a closed label set; requires evidence grounded in the visible content; and mandates abstention when cues are insufficient. Unlike CLIP-only pipelines, FairJudge yields accountable, evidence-aware decisions; unlike mitigation that alters generators, it targets evaluation fairness. We evaluate gender, race, and age on FairFace, PaTA, and FairCoT; extend to religion, culture, and disability; and assess profession correctness and alignment on IdenProf, FairCoT-Professions, and our new DIVERSIFY-Professions. We also release DIVERSIFY, a 469-image corpus of diverse, non-iconic scenes. Across datasets, judge models outperform contrastive and face-centric baselines on demographic prediction and improve mean alignment while maintaining high profession accuracy, enabling more reliable, reproducible fairness audits.
论文简评: 这篇论文提出了一种名为FairJudge的协议,用于评估文本到图像(T2I)系统的公平性和准确性。动机在于现有的评估方法容易产生表面相关性,无法有效处理弱可视化属性。通过使用多模态大语言模型作为评估者,该方法强制要求模型基于明确的视觉证据做出判断,并在证据不足时选择不作答。实验结果表明,FairJudge在多个数据集上相较于传统方法显著提高了社会属性预测的准确性和图像生成的对齐度。研究还贡献了两个新数据集DIVERSIFY和DIVERSIFY-Professions,用于进一步测试评估方法的公平性。
5.S-Chain: Structured Visual Chain-of-Thought For Medicine
Authors: Khai Le-Duc, Duy M. H. Nguyen, Phuong T. H. Trinh, Tien-Phat Nguyen, Nghiem T. Diep, An Ngo, Tung Vu, Trinh Vuong, Anh-Tien Nguyen, Mau Nguyen, Van Trung Hoang, Khai-Nguyen Nguyen, Hy Nguyen, Chris Ngo, Anji Liu, Nhat Ho, Anne-Christin Hauschild, Khanh Xuan Nguyen, Thanh Nguyen-Tang, Pengtao Xie, Daniel Sonntag, James Zou, Mathias Niepert, Anh Totti Nguyen
Affiliations: University of Toronto; Knovel Engineering Lab; German Research Centre for Artificial Intelligence; University of Stuttgart; Chonnam National University; Singapore University of Technology and Design; Bucknell University; Concordia University; Korea University; Justus Liebig University Giessen; University Medical Center Göttingen; Japan Advanced Institute of Science and Technology; Hue University; College of William & Mary; Deakin University; National University of Singapore; University of Texas at Austin; University of California, Berkeley; New Jersey Institute of Technology; University of California San Diego; MBZUAI; Oldenburg University; Stanford University; Max Planck Research School for Intelligent Systems (IMPRS-IS); Auburn University
https://arxiv.org/abs/2510.22728
论文摘要
Faithful reasoning in medical vision-language models (VLMs) requires not only accurate predictions but also transparent alignment between textual rationales and visual evidence. While Chain-of-Thought (CoT) prompting has shown promise in medical visual question answering (VQA), no large-scale expert-level dataset has captured stepwise reasoning with precise visual grounding. We introduce S-Chain, the first large-scale dataset of 12,000 expert-annotated medical images with bounding boxes and structured visual CoT (SV-CoT), explicitly linking visual regions to reasoning steps. The dataset further supports 16 languages, totaling over 700k VQA pairs for broad multilingual applicability. Using S-Chain, we benchmark state-of-the-art medical VLMs (ExGra-Med, LLaVA-Med) and general-purpose VLMs (Qwen2.5-VL, InternVL2.5), showing that SV-CoT supervision significantly improves interpretability, grounding fidelity, and robustness. Beyond benchmarking, we study its synergy with retrieval-augmented generation, revealing how domain knowledge and visual grounding interact during autoregressive reasoning. Finally, we propose a new mechanism that strengthens the alignment between visual evidence and reasoning, improving both reliability and efficiency. S-Chain establishes a new benchmark for grounded medical reasoning and paves the way toward more trustworthy and explainable medical VLMs.
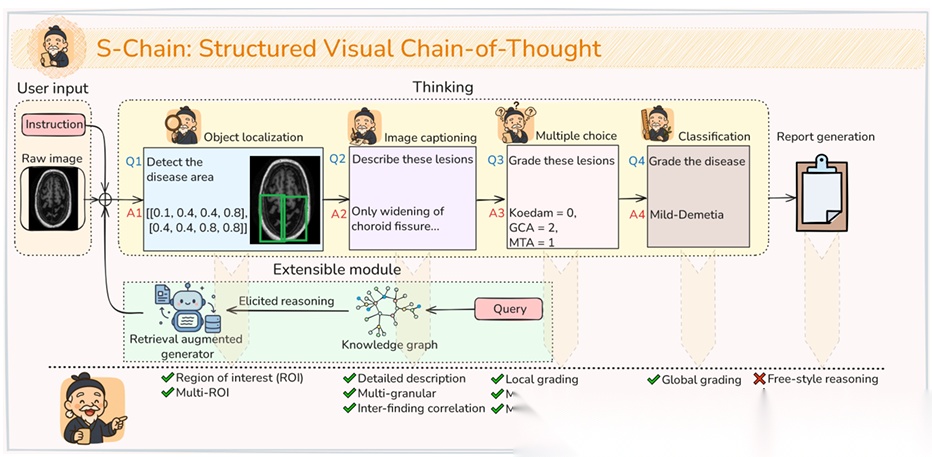
论文简评: 这篇论文提出了S-Chain,一个包含12,000个专家注释的医学图像的数据集,旨在提升医学视觉语言模型的推理能力。动机在于当前的医学视觉问答模型缺乏视觉证据与推理步骤的透明对齐。S-Chain通过提供显式的视觉链式推理,显著提高了模型的可解释性和鲁棒性。实验结果表明,使用S-Chain数据集进行监督训练的模型在推理准确性和视觉对齐方面表现优于基于GPT生成的合成数据,展示了专家验证注释的重要性。该研究为更可信赖和可解释的医学视觉语言模型奠定了基础。
6.Evaluating Multimodal Large Language Models on Core Music Perception Tasks
Authors: Brandon James Carone, Iran R. Roman, Pablo Ripollé
Affiliations: New York University; Queen Mary University of London
https://arxiv.org/abs/2510.22455
论文摘要
Multimodal Large Language Models (LLMs) claim “musical understanding” via evaluations that conflate listening with score reading. We benchmark three SOTA LLMs (Gemini 2.5 Pro, Gemini 2.5 Flash, and Qwen2.5-Omni) across three core music skills: Syncopation Scoring, Transposition Detection, and Chord Quality Identification. Moreover, we separate three sources of variability: (i) perceptual limitations (audio vs. MIDI inputs), (ii) exposure to examples (zero- vs. few-shot manipulations), and (iii) reasoning strategies (Standalone, CoT, LogicLM). For the latter we adapt LogicLM, a framework combining LLMs with symbolic solvers to perform structured reasoning, to music. Results reveal a clear perceptual gap: models perform near ceiling on MIDI but show accuracy drops on audio. Reasoning and few-shot prompting offer minimal gains. This is expected for MIDI, where performance reaches saturation, but more surprising for audio, where LogicLM, despite near-perfect MIDI accuracy, remains notably brittle. Among models, Gemini Pro achieves the highest performance across most conditions. Overall, current systems reason well over symbols (MIDI) but do not yet “listen” reliably from audio. Our method and dataset make the perception-reasoning boundary explicit and offer actionable guidance for building robust, audio-first music systems.
论文简评: 这篇论文探讨了多模态大语言模型在音乐感知任务中的表现,动机是评估这些模型是否能够真正理解音乐结构而不是仅仅依赖表面特征。作者通过三个核心音乐任务(切分音评分、转调检测和和弦质量识别)评估了几种最先进的多模态大语言模型,并引入了LogicLM框架以提高逻辑推理的准确性。实验结果显示,模型在MIDI输入上的表现接近上限,但在音频输入上准确率显著下降,表明模型在解析音频方面仍存在显著的感知瓶颈。Gemini Pro在多数情况下表现最佳,研究为构建更稳健的音频优先音乐系统提供了指导。
7.Toward Socially-Aware LLMs: A Survey of Multimodal Approaches to Human Behavior Understanding
Authors: Zihan Liu, Parisa Rabbani, Veda Duddu, Kyle Fan, Madison Lee, Yun Huang
Affiliations: University of Illinois Urbana-Champaign
https://arxiv.org/abs/2510.23947
论文摘要
LLM-powered multimodal systems are increasingly used to interpret human social behavior, yet how researchers apply the models’ ‘social competence’ remains poorly understood. This paper presents a systematic literature review of 176 publications across different application domains (e.g., healthcare, education, and entertainment). Using a four-dimensional coding framework (application, technical, evaluative, and ethical), we find (1) frequent use of pattern recognition and information extraction from multimodal sources, but limited support for adaptive, interactive reasoning; (2) a dominant ‘modality-to-text’ pipeline that privileges language over rich audiovisual cues, striping away nuanced social cues; (3) evaluation practices reliant on static benchmarks, with socially grounded, human-centered assessments rare; and (4) Ethical discussions focused mainly on legal and rights-related risks (e.g., privacy), leaving societal risks (e.g., deception) overlooked–or at best acknowledged but left unaddressed. We outline a research agenda for evaluating socially competent, ethically informed, and interaction-aware multi-modal systems.
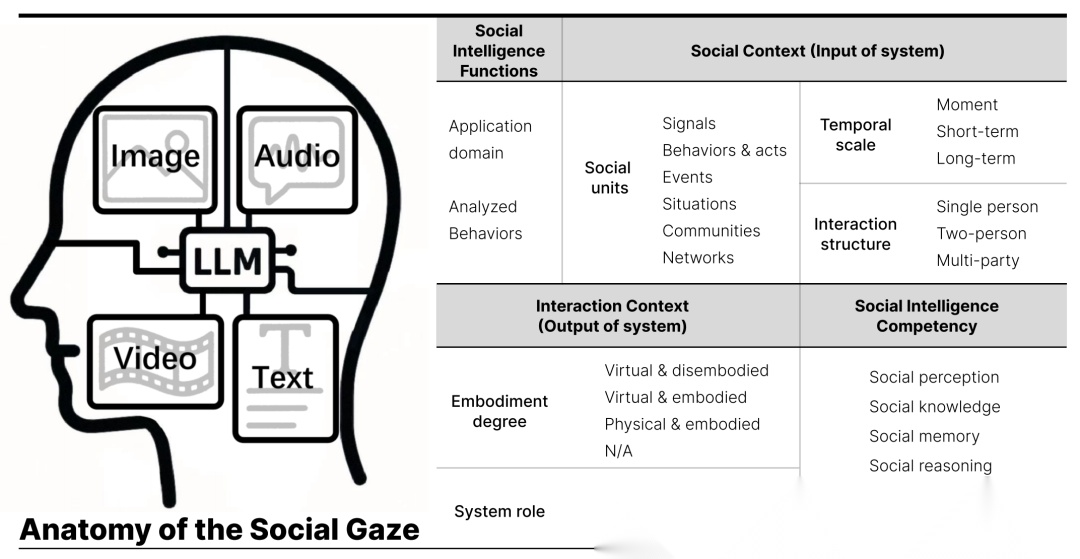
论文简评: 这篇论文系统性地回顾了176项研究,探讨如何利用大型语言模型(LLM)驱动的多模态系统理解人类社会行为。作者通过四维编码框架分析了这些系统在不同领域中的应用,如医疗、教育和娱乐。研究发现目前的系统多依赖于模式识别和信息提取,但在适应性互动推理方面支持有限。论文提出了社会智能、多模态信息整合以及伦理风险的研究议程,强调需要更丰富的多模态整合和以人为中心的评估方法。
8.Latent Sketchpad: Sketching Visual Thoughts to Elicit Multimodal Reasoning in MLLMs
Authors: Huanyu Zhang, Wenshan Wu, Chengzu Li, Ning Shang, Yan Xia, Yangyu Huang, Yifan Zhang, Li Dong, Zhang Zhang, Liang Wang, Tieniu Tan, Furu Wei
Affiliations: Microsoft Research; University of Chinese Academy of Sciences; Cambridge University; Chinese Academy of Sciences Institute of Automation; Nanjing University
https://arxiv.org/abs/2510.24514
论文摘要
While Multimodal Large Language Models (MLLMs) excel at visual understanding, they often struggle in complex scenarios that require visual planning and imagination. Inspired by how humans use sketching as a form of visual thinking to develop and communicate ideas, we introduce Latent Sketchpad, a framework that equips MLLMs with an internal visual scratchpad. The internal visual representations of MLLMs have traditionally been confined to perceptual understanding. We repurpose them to support generative visual thought without compromising reasoning ability. Building on frontier MLLMs, our approach integrates visual generation directly into their native autoregressive reasoning process. It allows the model to interleave textual reasoning with the generation of visual latents. These latents guide the internal thought process and can be translated into sketch images for interpretability. To realize this, we introduce two components: a Context-Aware Vision Head autoregressively produces visual representations, and a pretrained Sketch Decoder renders these into human-interpretable images. We evaluate the framework on our new dataset MazePlanning. Experiments across various MLLMs show that Latent Sketchpad delivers comparable or even superior reasoning performance to their backbone. It further generalizes across distinct frontier MLLMs, including Gemma3 and Qwen2.5-VL. By extending model’s textual reasoning to visual thinking, our framework opens new opportunities for richer human-computer interaction and broader applications. More details and resources are available on our project page: https://latent-sketchpad.github.io/.
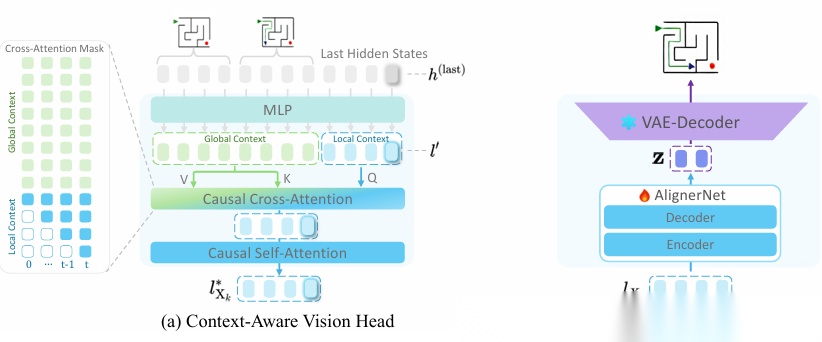
论文简评: 该论文提出了Latent Sketchpad框架,以解决多模态大模型(MLLMs)在复杂视觉推理任务中的不足。受人类通过草图进行视觉思维的启发,Latent Sketchpad为MLLMs引入了内部视觉“草稿本”,在推理过程中生成视觉潜在变量,并通过预训练的草图解码器将其转化为可解释的图像。实验表明,该框架在新构建的MAZE PLANNING数据集上表现出色,与基础模型相比,推理性能相当或更优。Latent Sketchpad能够扩展文本推理至视觉思维,提升了人机交互的丰富性和适用范围。
9.DynaSolidGeo: A Dynamic Benchmark for Genuine Spatial Mathematical Reasoning of VLMs in Solid Geometry
Authors: Changti Wu, Shijie Lian, Zihao Liu, Lei Zhang, Laurence Tianruo Yang, Kai Chen
Affiliations: East China Normal University; Huazhong University of Science and Technology; Peking University; Zhengzhou University; Zhongguancun Institute of Artificial Intelligence
https://arxiv.org/abs/2510.22340
论文摘要
Solid geometry problem solving demands spatial mathematical reasoning that integrates spatial intelligence and symbolic reasoning. However, most existing multimodal mathematical reasoning benchmarks focus primarily on 2D plane geometry, rely on static datasets prone to data contamination and memorization, and evaluate models solely by final answers, overlooking the reasoning process. To address these limitations, we introduce DynaSolidGeo, the first dynamic benchmark for evaluating genuine spatial reasoning in Vision-Language Models (VLMs). Constructed through a semi-automatic annotation pipeline, DynaSolidGeo contains 503 expert-curated seed questions that can, in principle, dynamically generate an unbounded number of diverse multimodal text-visual instances. Beyond answer accuracy, we incorporate process evaluation based on expert-annotated reasoning chains to measure logical validity and causal coherence. Experiments across representative open-source and closed-source VLMs reveal large performance gaps, severe degradation in dynamic settings, and poor performance on tasks requiring high-level spatial intelligence, such as mental rotation and visualization. The code and dataset are available at \href{https://zgca-ai4edu.github.io/DynaSolidGeo/}{DynaSolidGeo}.
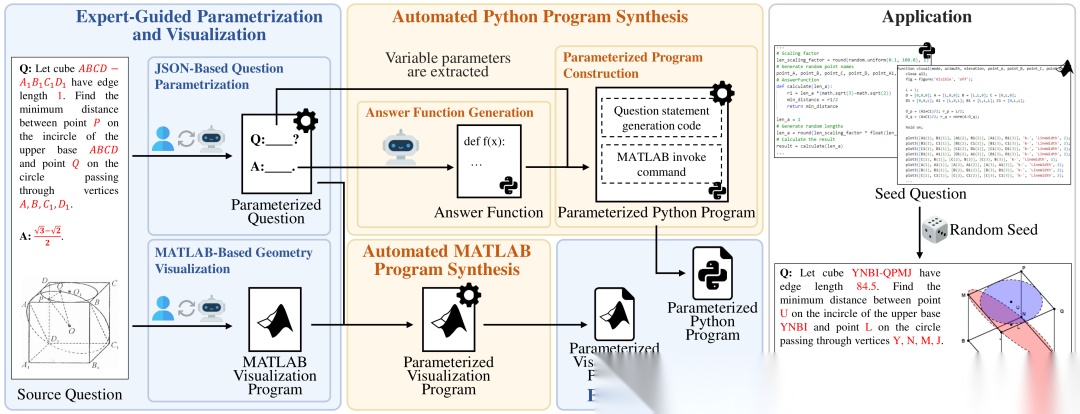
论文简评: 论文提出了DynaSolidGeo,这是第一个用于评估视觉语言模型(VLM)在立体几何中的真实空间推理能力的动态基准。通过半自动化的注释流程,DynaSolidGeo包含503个专家策划的问题种子,能够动态生成无限多样的多模态实例。除了答案准确性外,该基准还通过专家注释的推理链进行过程评估,以测量逻辑有效性和因果一致性。实验结果表明,现有模型在动态环境下表现出显著的性能差距,尤其在需要高级空间智能的任务上,如心智旋转和可视化。
10.BLM: A Boundless Large Model for Cross-Space, Cross-Task, and Cross-Embodiment Learning
Authors: Wentao Tan, Bowen Wang, Heng Zhi, Chenyu Liu, Zhe Li, Jian Liu, Zengrong Lin, Yukun Dai, Yipeng Chen, Wenjie Yang, Enci Xie, Hao Xue, Baixu Ji, Chen Xu, Zhibin Wang, Tianshi Wang, Lei Zhu, Heng Tao Shen
Affiliations: Tongji University; Shanghai Magic; Koala Uran
https://arxiv.org/abs/2510.24161
论文摘要
Multimodal large language models (MLLMs) have advanced vision-language reasoning and are increasingly deployed in embodied agents. However, significant limitations remain: MLLMs generalize poorly across digital-physical spaces and embodiments; vision-language-action models (VLAs) produce low-level actions yet lack robust high-level embodied reasoning; and most embodied large language models (ELLMs) are constrained to digital-space with poor generalization to the physical world. Thus, unified models that operate seamlessly across digital and physical spaces while generalizing across embodiments and tasks remain absent. We introduce the \textbf{Boundless Large Model (BLM)}, a multimodal spatial foundation model that preserves instruction following and reasoning, incorporates embodied knowledge, and supports robust cross-embodiment control. BLM integrates three key capabilities – \textit{cross-space transfer, cross-task learning, and cross-embodiment generalization} – via a two-stage training paradigm. Stage I injects embodied knowledge into the MLLM through curated digital corpora while maintaining language competence. Stage II trains a policy module through an intent-bridging interface that extracts high-level semantics from the MLLM to guide control, without fine-tuning the MLLM backbone. This process is supported by a self-collected cross-embodiment demonstration suite spanning four robot embodiments and six progressively challenging tasks. Evaluations across digital and physical benchmarks show that a single BLM instance outperforms four model families – MLLMs, ELLMs, VLAs, and GMLMs – achieving gains in digital tasks and in physical tasks.
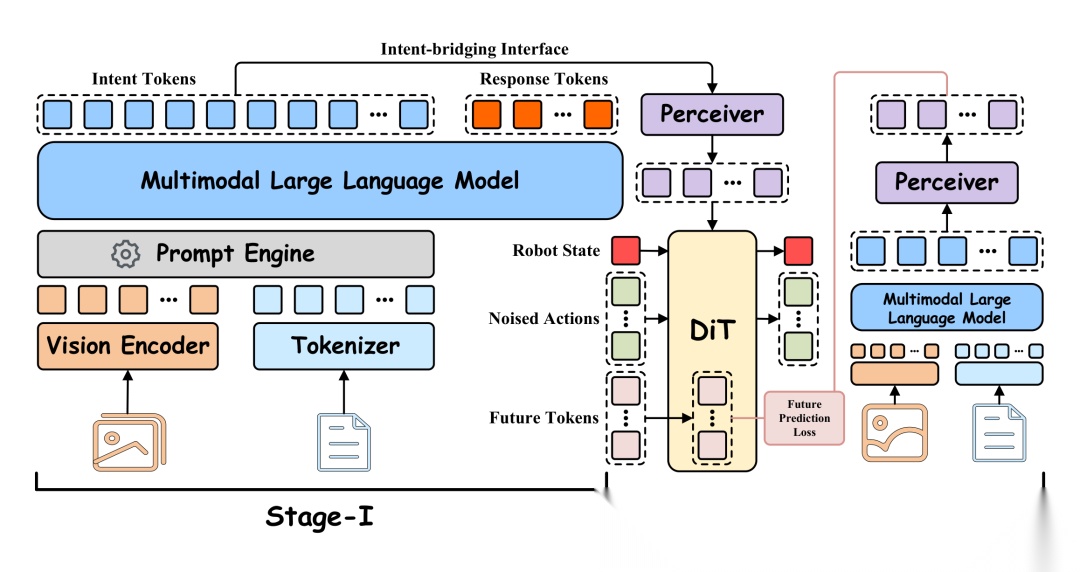
论文简评: 这篇论文探讨了多模态大语言模型(MLLMs)的局限性,特别是在跨越数字和物理空间及不同体现时的泛化能力不足。为此,作者提出了Boundless Large Model(BLM 1),一个多模态空间基础模型,能够在不降低原生推理和指令跟随能力的情况下,注入体现知识并支持跨体现控制。BLM 1采用两阶段训练方法:第一阶段通过精心挑选的数字语料库向MLLM注入体现知识,第二阶段通过意图桥接接口提取高层语义指导控制,避免对MLLM主干进行微调。实验结果表明,BLM 1在数字和物理任务中均超过现有模型,分别实现了约6%和3%的性能提升。
如何学习大模型 AI ?
我国在AI大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着Al技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国Al产业的创新步伐。加强人才培养,优化教育体系,国际合作并进,是破解困局、推动AI发展的关键。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

2025最新大模型学习路线
明确的学习路线至关重要。它能指引新人起点、规划学习顺序、明确核心知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
对于从来没有接触过AI大模型的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线。

针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
大模型经典PDF书籍
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路!

配套大模型项目实战
所有视频教程所涉及的实战项目和项目源码等
博主介绍+AI项目案例集锦
MoPaaS专注于Al技术能力建设与应用场景开发,与智学优课联合孵化,培养适合未来发展需求的技术性人才和应用型领袖。


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么要学习大模型?
2025人工智能大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。

适合人群
- 在校学生:包括专科、本科、硕士和博士研究生。学生应具备扎实的编程基础和一定的数学基础,有志于深入AGI大模型行业,希望开展相关的研究和开发工作。
- IT行业从业人员:包括在职或失业者,涵盖开发、测试、运维、产品经理等职务。拥有一定的IT从业经验,至少1年以上的编程工作经验,对大模型技术感兴趣或有业务需求,希望通过课程提升自身在IT领域的竞争力。
- IT管理及技术研究领域人员:包括技术经理、技术负责人、CTO、架构师、研究员等角色。这些人员需要跟随技术发展趋势,主导技术创新,推动大模型技术在企业业务中的应用与改造。
- 传统AI从业人员:包括算法工程师、机器视觉工程师、深度学习工程师等。这些AI技术人才原先从事机器视觉、自然语言处理、推荐系统等领域工作,现需要快速补充大模型技术能力,获得大模型训练微调的实操技能,以适应新的技术发展趋势。

课程精彩瞬间
大模型核心原理与Prompt:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为Al应用开发打下坚实基础。
RAG应用开发工程:掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
Agent应用架构进阶实践:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
模型微调与私有化大模型:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。




顶尖师资,深耕AI大模型前沿技术
实战专家亲授,让你少走弯路
一对一学习规划,职业生涯指导
- 真实商业项目实训
- 大厂绿色直通车
人才库优秀学员参与真实商业项目实训
以商业交付标准作为学习标准,具备真实大模型项目实践操作经验可写入简历,支持项目背调
大厂绿色直通车,冲击行业高薪岗位


文中涉及到的完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 20
20 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)