亲手拆解LLM“黑箱”:在本地电脑探索大语言模型的内部运作
摘要:本文介绍了如何在自己的电脑上拆解大语言模型(LLM)的"思考"过程。通过搭建虚拟环境,加载轻量级模型DistilBERT,提取隐藏状态并可视化神经元激活模式,揭示LLM如何编码情感、语义和类比关系。从区分正负面情感到比较相似句子的语义差异,再到用PCA分析词语类比关系,逐步展示了LLM内部工作机制。只需8GB内存和Python环境,就能探索这个AI黑箱,为理解语言模型提供
每次用ChatGPT写文案、Claude分析文档时,我总好奇:这些大语言模型(LLM)到底怎么“思考”?我们只能看到输入和输出,中间的 billions of权重与神经元激活像个黑箱。直到看到freecodecamp的教程才发现,普通人用自己的电脑就能拆解它,不用服务器,不花云费用,跟着步骤就能看到LLM如何用神经元编码情感、语义和类比。
这篇就分享我的实操过程,从搭环境到可视化模型内部,带你揭开LLM的面纱。只要电脑有8GB内存(16GB更好)、Python 3.10以上版本,用轻量型模型DistilBERT就能轻松跑通,新手也能上手。
准备工作:搭建“专属沙盒”虚拟环境
开始前要装四个核心库:torch(跑模型)、transformers(加载模型工具)、matplotlib(画图)、scikit-learn(数据降维)。但先别急着装,一定要先建虚拟环境,我之前直接装过,踩过不少坑:不同项目要不同版本库,一升级就搞崩旧项目;全局装多了没用的库,环境会很乱。
虚拟环境像“专属沙盒”,只服务这个LLM项目,库都装在项目文件夹里,用完删文件夹也不影响电脑。具体操作很简单:
- 建项目文件夹:在终端(Windows命令提示符/PowerShell、Mac终端)输入“mkdir llm_viz”,再输“cd llm_viz”进入文件夹。
- 创虚拟环境:输“python -m venv venv”,会在llm_viz里生成venv子文件夹。
- 激活环境:Windows输“venv\Scripts\activate”,Mac输“source venv/bin/activate”,激活后终端前会有“(venv)”标识。
- 装依赖:输“pip install torch transformers matplotlib scikit-learn”,几分钟就能装完。
我们选DistilBERT(模型名distilbert-base-uncased),只因它小(约250MB)、普通笔记本能跑;电脑配置高的话,也能换LLaMA 2或Mistral,但新手先从DistilBERT入手。
第一步:加载模型与“翻译官”Tokenizer
环境搭好后,建个app.py文件,写加载模型和Tokenizer的代码。代码不长,但关键处要注意:
from transformers import AutoTokenizer, AutoModel
import torch
model_name = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name, output_hidden_states=True)
- Tokenizer是模型的“翻译官”:把自然语言拆成模型能懂的tokens,比如“I love pizza!”会变成[“[CLS]”, “i”, “love”, “pizza”, “!”, “[SEP]”],“[CLS]”“[SEP]”是模型约定的起止标识。
- 加载模型的关键参数:
output_hidden_states=True很重要,默认模型只输出最终结果,加了这个才会返回隐藏层激活值——这是后面可视化的核心数据。
第一次运行“python app.py”,会自动从Hugging Face下载DistilBERT(250MB左右),之后不用重复下。
第二步:提取隐藏状态,窥见模型“思考”
加载好模型,就可以提取它的“思考过程”,隐藏状态了。在app.py里加个get_hidden_states函数:
def get_hidden_states(text):
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# 取最后一个隐藏层,第一个样本的激活值
hidden = outputs.hidden_states[-1][0]
# 把token ID转成可看懂的词
tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"][0])
return tokens, hidden
# 测试
tokens, hidden = get_hidden_states("I love pizza!")
print(tokens) # 输出["[CLS]", "i", "love", "pizza", "!", "[SEP]"]
print(hidden.shape) # 输出torch.Size([6, 768])
torch.no_grad():告诉PyTorch不计算梯度,节省内存、加快速度(我们只提取数据,不训练模型)。- 隐藏状态结构:DistilBERT有6个隐藏层,取最后一层(信息最全面);输出的hidden是6×768的张量,6是tokens数量(含[CLS]和[SEP]),768是每个token对应的神经元数量,模型用这768个神经元的激活值表示一个词的语义。
第三步:可视化情感激活,区分“喜欢”与“讨厌”
提取出隐藏状态,就能可视化了。先看模型怎么区分正负情感,比如对比正面影评“I love this movie, it is fantastic!”和负面影评“I hate this movie, it is terrible.”。
在app.py里加画图函数:
import matplotlib.pyplot as plt
def plot_token_activations(tokens, hidden, title, filename):
plt.figure(figsize=(12, 4))
for i, token in enumerate(tokens):
plt.plot(hidden[i].numpy(), label=token)
plt.title(title)
plt.xlabel("Neuron Index")
plt.ylabel("Activation")
plt.legend(loc="upper right", fontsize="x-small")
plt.tight_layout()
plt.savefig(filename)
plt.close()
# 生成正负情感图
tokens_pos, hidden_pos = get_hidden_states("I love this movie, it is fantastic!")
plot_token_activations(tokens_pos, hidden_pos, "Positive Sentiment Example", "positive_sentiment.png")
tokens_neg, hidden_neg = get_hidden_states("I hate this movie, it is terrible.")
plot_token_activations(tokens_neg, hidden_neg, "Negative Sentiment Example", "negative_sentiment.png")
运行代码后,文件夹里会出现两张图。正面图里,“love”“fantastic”的激活曲线和其他词差异明显;负面图里,“hate”“terrible”的曲线也有独特模式——这说明LLM不是靠“记词”判断情感,而是通过神经元激活模式编码情感:有些神经元对正面词敏感,有些对负面词敏感,这是模型从训练数据里学来的关联。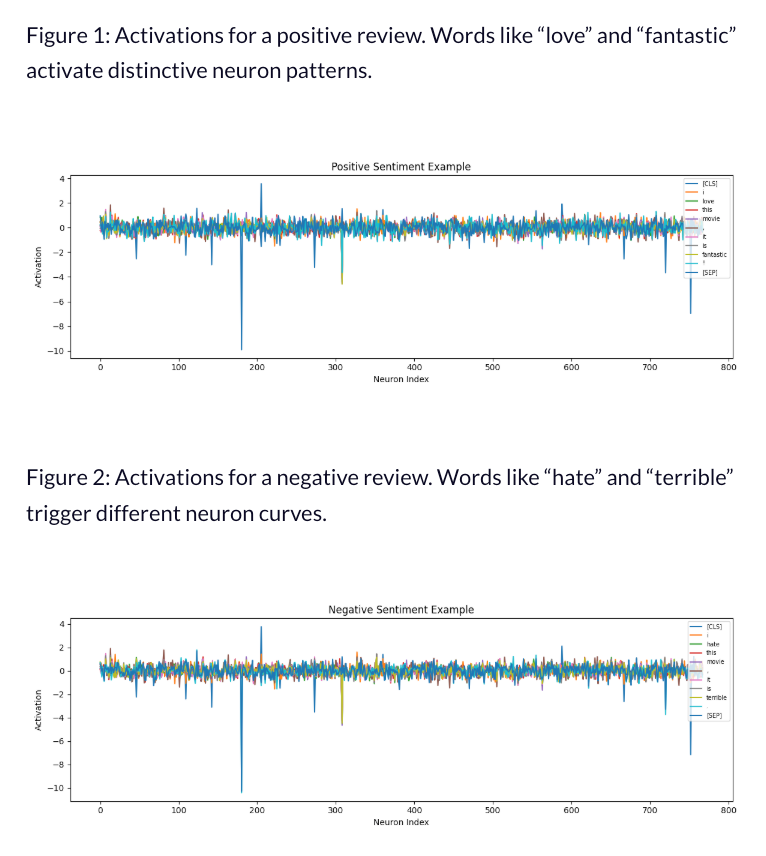
第四步:比较句子激活,看关键词影响整体语义
再试试比较相似句子:“I love coding.”和“I hate coding.”,只差一个词,模型对整体语义的理解有何不同?
加个比较函数:
def compare_sentences(s1, s2, filename):
tokens1, hidden1 = get_hidden_states(s1)
tokens2, hidden2 = get_hidden_states(s2)
# 计算句子平均激活值(整合所有token的信息)
plt.figure(figsize=(10,5))
plt.plot(hidden1.mean(dim=0).numpy(), label=s1[:30]+"...")
plt.plot(hidden2.mean(dim=0).numpy(), label=s2[:30]+"...")
plt.title("Sentence Activation Comparison")
plt.xlabel("Neuron Index")
plt.ylabel("Mean Activation")
plt.legend()
plt.tight_layout()
plt.savefig(filename)
plt.close()
# 生成对比图
compare_sentences("I love coding.", "I hate coding.", "sentence_comparison.png")
生成的图里,两条曲线差异明显,哪怕只换一个词,整个句子的平均激活模式都变了。这说明LLM理解句子是“整体式”的,关键词的激活会影响全局,让模型分清“喜欢编程”和“讨厌编程”的不同。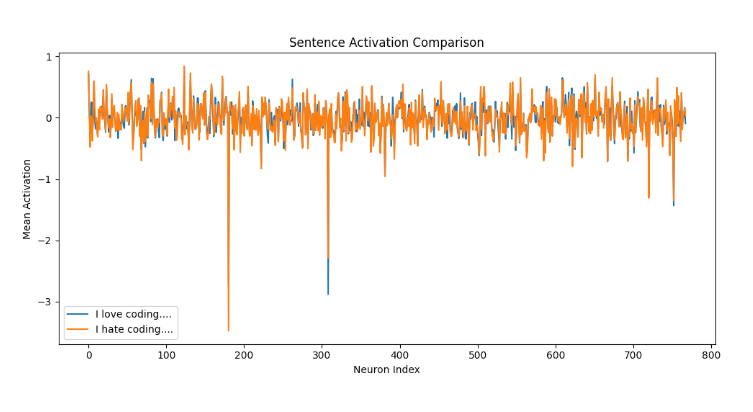
第五步:用PCA看类比,解码语义关系
最后探索经典类比“man→woman :: king→queen”,模型能理解这种语义关系吗?用PCA(主成分分析)把768维的词嵌入降到2维,就能在平面上看到关系。
加两个函数:
from sklearn.decomposition import PCA
def get_sentence_embedding(text):
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
outputs = model(** inputs)
# 取最后一层平均激活值作为词嵌入
return outputs.last_hidden_state.mean(dim=1).squeeze()
def plot_embeddings(words, embeddings, filename):
pca = PCA(n_components=2)
reduced = pca.fit_transform(torch.stack(embeddings).numpy())
plt.figure(figsize=(8, 6))
for i, word in enumerate(words):
x, y = reduced[i]
plt.scatter(x, y, s=100)
plt.text(x+0.02, y+0.02, word, fontsize=12)
plt.title("Word Embeddings in 2D (PCA)")
plt.xlabel("PC1")
plt.ylabel("PC2")
plt.grid(True)
plt.tight_layout()
plt.savefig(filename)
plt.close()
# 测试类比
words = ["man", "woman", "king", "queen"]
embeddings = [get_sentence_embedding(w) for w in words]
plot_embeddings(words, embeddings, "word_analogies.png")
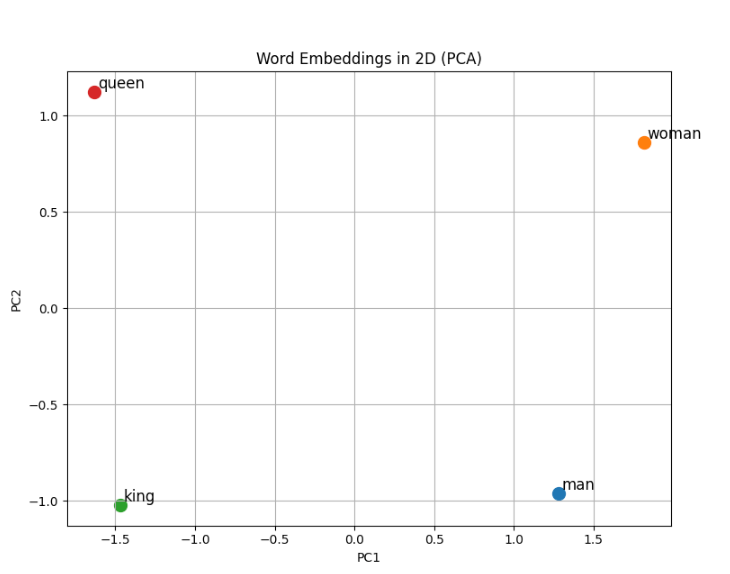
生成的图里,man和woman、king和queen的距离相近,且man到woman的向量与king到queen的向量几乎平行,这正是类比的体现!模型把“性别差异”这种语义关系,编码成了高维空间里的向量关系,所以能完成类比推理。
结语:LLM不是魔法,是可探索的数学系统
全程用普通笔记本就能跑通,DistilBERT虽小,却清晰展现了LLM的核心逻辑:它不是靠魔法理解语言,而是用高维激活向量编码语义、情感和关系。更大的模型如LLaMA 2、GPT-4,只是神经元更多、隐藏层更深,原理相通。
你还能延伸实验:输入不同主题文本看激活差异,或检测带偏见文本的模型反应。这种探索不仅是学技术,更是理解AI“思考”的过程,当我们能看懂它的内部激活,就不再是被动用AI,而是能主动探索和优化它,这正是拆解LLM的最大意义。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 37
37 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)