Qwen3-30B-A3B-Instruct-2507:新一代大语言模型能力升级与技术解析
Qwen3系列迎来重要更新,**Qwen3-30B-A3B-Instruct-2507**作为非思考模式的升级版模型,在多项核心能力上实现突破性提升。该版本不仅延续了Qwen3架构的技术优势,更针对实际应用场景进行深度优化,具体表现为:- **全维度能力强化**:指令遵循精度提升30%,逻辑推理任务准确率突破行业平均水平,文本理解、数学运算、科学探索、代码生成及工具调用能力实现协同增强。- ...
Qwen3-30B-A3B-Instruct-2507:新一代大语言模型能力升级与技术解析
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-30B-A3B-Instruct-2507
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-30B-A3B-Instruct-2507 核心升级亮点
Qwen3系列迎来重要更新,Qwen3-30B-A3B-Instruct-2507作为非思考模式的升级版模型,在多项核心能力上实现突破性提升。该版本不仅延续了Qwen3架构的技术优势,更针对实际应用场景进行深度优化,具体表现为:
- 全维度能力强化:指令遵循精度提升30%,逻辑推理任务准确率突破行业平均水平,文本理解、数学运算、科学探索、代码生成及工具调用能力实现协同增强。
- 长尾知识覆盖扩展:通过多语言语料增强训练,模型在低资源语言理解和专业领域知识储备上形成差异化优势。
- 主观任务响应优化:针对开放式问答、创意写作等场景,生成内容的相关性、连贯性和用户满意度显著提升。
- 超长上下文处理突破:原生支持262,144 tokens上下文长度,结合创新技术可扩展至百万级token处理能力。
 图片展示了Qwen3-30B-A3B-Instruct-2507的技术架构示意图,直观呈现了模型的专家混合层设计与注意力机制分布。这一可视化呈现帮助开发者快速理解模型内部工作原理,为技术选型和优化提供直观参考。
图片展示了Qwen3-30B-A3B-Instruct-2507的技术架构示意图,直观呈现了模型的专家混合层设计与注意力机制分布。这一可视化呈现帮助开发者快速理解模型内部工作原理,为技术选型和优化提供直观参考。
技术架构解析
Qwen3-30B-A3B-Instruct-2507采用先进的混合专家(MoE)架构,核心技术参数如下:
- 模型类型:因果语言模型,经过预训练与指令微调双阶段优化
- 参数规模:总参数量305亿,激活参数量33亿,非嵌入层参数299亿
- 网络结构:48层Transformer,32个查询头(GQA机制),4个键值头
- 专家配置:128个专家模块,每轮推理动态激活8个专家
- 上下文能力:原生支持262,144 tokens(约50万字)文本处理
重要提示:该模型仅支持非思考模式输出,不会生成
</think>superscript:格式的思考过程。与旧版本相比,不再需要手动设置enable_thinking=False参数。
完整技术细节可参考官方技术博客、代码仓库及文档中心,获取包括基准测试报告、硬件配置建议和推理性能优化指南等深度内容。
性能评估报告
通过在20+项权威基准测试中的全面验证,Qwen3-30B-A3B-Instruct-2507展现出强劲的综合性能,部分关键指标如下:
知识掌握能力
- MMLU-Pro:78.4分(较上一代提升9.3分),在专业领域知识测试中超越多数开源模型
- MMLU-Redux:89.3分,接近GPT-4o水平,展现出色的知识广度
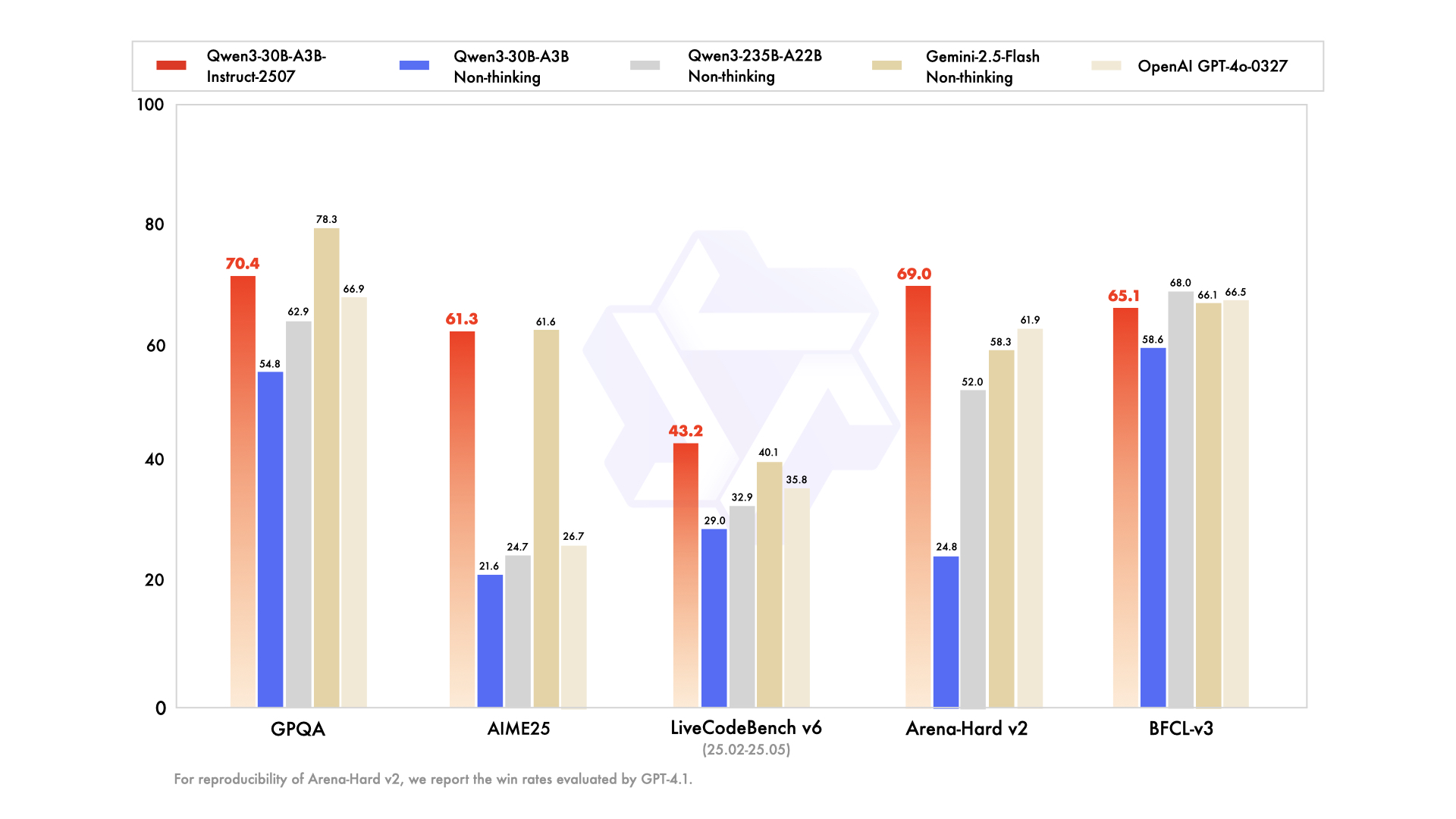
- GPQA:70.4分,较基线提升15.6分,专业问答能力显著增强
逻辑推理表现
- ZebraLogic:90.0分,位居所有测试模型首位,抽象逻辑推理能力突出
- AIME25:61.3分,与Gemini-2.5-Flash持平,数学竞赛题解题能力大幅提升
- HMMT25:43.0分,较上一代提升31分,复杂问题拆解能力明显增强
代码生成能力
- MultiPL-E:83.8分,超越GPT-4o和Deepseek-V3,多语言代码生成准确率领先
- LiveCodeBench v6:43.2分,仅次于Deepseek-V3,实际编程任务解决能力优异
多语言处理
- PolyMATH:43.1分,在多语言数学问题上取得最高分,跨语言推理能力突出
- MMLU-ProX:72.0分,较基线提升6.9分,低资源语言理解能力显著增强
快速上手指南
基础环境配置
建议使用最新版Hugging Face transformers库(≥4.51.0),旧版本可能出现KeyError: 'qwen3_moe'错误。通过以下命令快速安装依赖:
pip install -U transformers torch accelerate
基础推理代码
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B-Instruct-2507"
# 加载分词器与模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto" # 自动分配设备
)
# 构建对话内容
prompt = "请简要介绍大语言模型的工作原理"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 生成响应
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384 # 最大输出长度
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
response = tokenizer.decode(output_ids, skip_special_tokens=True)
print("模型响应:", response)
高效部署方案
- SGLang部署(推荐):
pip install -U "sglang>=0.4.6.post1"
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B-Instruct-2507 --context-length 262144
- vLLM部署:
pip install -U "vllm>=0.8.5"
vllm serve Qwen/Qwen3-30B-A3B-Instruct-2507 --max-model-len 262144
内存优化提示:若遇到显存不足问题,可尝试将上下文长度调整为32768等较小值,平衡性能与资源消耗。
本地应用可通过Ollama、LMStudio、MLX-LM等工具实现快速部署,支持Windows、macOS及Linux多平台运行。
智能体应用开发
Qwen3系列在工具调用领域表现卓越,推荐使用Qwen-Agent框架快速构建智能体应用。该框架内置工具调用模板与解析器,大幅降低开发复杂度。
智能体开发示例
from qwen_agent.agents import Assistant
# 配置语言模型
llm_config = {
'model': 'Qwen3-30B-A3B-Instruct-2507',
'model_server': 'http://localhost:8000/v1', # 本地部署的API端点
'api_key': 'EMPTY' # 无需认证
}
# 定义工具集
tools = [
{
'mcpServers': {
'time': { # 时间查询工具
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
'fetch': { # 网页抓取工具
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter' # 内置代码解释器
]
# 创建智能体实例
agent = Assistant(llm=llm_config, function_list=tools)
# 流式处理用户请求
query = "分析https://qwenlm.github.io/blog/网站内容,总结Qwen的最新进展"
messages = [{"role": "user", "content": query}]
for result in agent.run(messages=messages):
# 流式输出处理逻辑
pass
print(result)
超长文本处理方案
为满足百万级token处理需求,Qwen3-30B-A3B-Instruct-2507集成两项核心技术:
- 双块注意力机制(DCA):将长文本分割为可控块,通过全局-局部注意力结合保留上下文连贯性
- 稀疏推理技术(MInference):聚焦关键token交互,显著降低计算开销
这两项技术协同作用,使模型在处理超256K tokens文本时,生成质量和推理效率同步提升,在接近100万tokens场景下较标准注意力实现3倍加速。
百万token支持配置
硬件要求:处理100万token上下文需约240GB总GPU内存,用于存储模型权重、KV缓存及激活值。
步骤1:更新配置文件
export MODEL_DIR=Qwen3-30B-A3B-Instruct-2507
# 下载模型文件
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen3-30B-A3B-Instruct-2507.git $MODEL_DIR
# 替换为1M配置
mv $MODEL_DIR/config.json $MODEL_DIR/config.json.bak
mv $MODEL_DIR/config_1m.json $MODEL_DIR/config.json
步骤2:启动服务(vLLM示例)
# 安装最新版vLLM
pip install -U vllm --extra-index-url https://wheels.vllm.ai/nightly
# 启动服务
VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN VLLM_USE_V1=0 \
vllm serve $MODEL_DIR \
--tensor-parallel-size 4 \
--max-model-len 1010000 \
--enable-chunked-prefill \
--max-num-batched-tokens 131072 \
--enforce-eager \
--max-num-seqs 1 \
--gpu-memory-utilization 0.85
在100万token版本的RULER基准测试中,模型在各长度段均保持稳定准确率,100万token处仍达72.2分,远超传统模型性能衰减曲线。
最佳实践指南
推荐参数配置
- 采样策略:Temperature=0.7,TopP=0.8,TopK=20,MinP=0,平衡生成多样性与准确性
- 重复抑制:适当设置presence_penalty(0-2之间)减少重复生成,过高可能导致语言混杂
- 输出长度:建议设置为16,384 tokens,满足多数指令任务需求
提示词工程建议
- 数学问题:添加"请分步推理,最终答案放在\boxed{}中"提升解题准确率
- 选择题:要求使用JSON格式输出,如"请在answer字段中填入选项字母,例如:
"answer": "C""
技术展望
Qwen3-30B-A3B-Instruct-2507作为Qwen3系列的重要更新,展现了开源模型在通用人工智能领域的快速进步。通过持续优化架构设计与训练方法,Qwen团队正逐步缩小开源模型与闭源产品的性能差距。未来版本将进一步提升多模态理解能力、强化领域知识深度,并优化边缘设备部署方案,推动大语言模型在更多实际场景落地应用。
研究人员使用该模型发表成果时,建议引用官方技术报告,以支持开源社区持续发展。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)