【论文藏宝图】多模态大模型最新进展!把最核心的思路和代码都给你扒出来了!
多模态大模型最新进展!把最核心的思路和代码都给你扒出来了!
我们从2025-11-12到2025-11-19的470篇文章中精选出10篇优秀的工作分享给读者,主要研究方向包括:多任务多运动视频理解, 加速扩散MLLMs的推理, 开放式多模态医学生成基准, 3D交互的语言建模, 多模态有害内容检测, 生成有害语音, 多视角行人-车辆事故推理, 语言中心的全模态大模型, 图基础模型的模型提取攻击, 大模型幻觉检测
- DeepSport: A Multimodal Large Language Model for Comprehensive Sports Video Reasoning via Agentic Reinforcement Learning
- DToM: Decider-Guided Dynamic Token Merging for Accelerating Diffusion MLLMs
- MedGEN-Bench: Contextually entangled benchmark for open-ended multimodal medical generation
- Part-X-MLLM: Part-aware 3D Multimodal Large Language Model
- OutSafe-Bench: A Benchmark for Multimodal Offensive Content Detection in Large Language Models
- Synthetic Voices, Real Threats: Evaluating Large Text-to-Speech Models in Generating Harmful Audio
- Multi-view Phase-aware Pedestrian-Vehicle Incident Reasoning Framework with Vision-Language Models
- Uni-MoE-2.0-Omni: Scaling Language-Centric Omnimodal Large Model with Advanced MoE, Training and Data
- A Systematic Study of Model Extraction Attacks on Graph Foundation Models
- Seeing is Believing: Rich-Context Hallucination Detection for MLLMs via Backward Visual Grounding
1.DeepSport: A Multimodal Large Language Model for Comprehensive Sports Video Reasoning via Agentic Reinforcement Learning
Authors: Junbo Zou, Haotian Xia, Zhen Ye, Shengjie Zhang, Christopher Lai, Vicente Ordonez, Weining Shen, Hanjie Chen
Affiliations: Georgia Institute of Technology; Rice University; Johns Hopkins University; University of California, Irvine; University of California, Santa Barbara
https://arxiv.org/abs/2511.12908
论文摘要
Sports video understanding presents unique challenges, requiring models to perceive high-speed dynamics, comprehend complex rules, and reason over long temporal contexts. While Multimodal Large Language Models (MLLMs) have shown promise in genral domains, the current state of research in sports remains narrowly focused: existing approaches are either single-sport centric, limited to specific tasks, or rely on training-free paradigms that lack robust, learned reasoning process. To address this gap, we introduce DeepSport, the first end-to-end trained MLLM framework designed for multi-task, multi-sport video understanding. DeepSport shifts the paradigm from passive frame processing to active, iterative reasoning, empowering the model to think with videos by dynamically interrogating content via a specialized frame-extraction tool. To enable this, we propose a data distillation pipeline that synthesizes high-quality Chain-of-Thought (CoT) trajectories from 10 diverse data source, creating a unified resource of 78k training data. We then employ a two-stage training strategy, Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL) with a novel gated tool-use reward, to optimize the model’s reasoning process. Extensive experiments on the testing benchmark of 6.7k questions demonstrate that DeepSport achieves state-of-the-art performance, significantly outperforming baselines of both proprietary model and open-source models. Our work establishes a new foundation for domain-specific video reasoning to address the complexities of diverse sports.
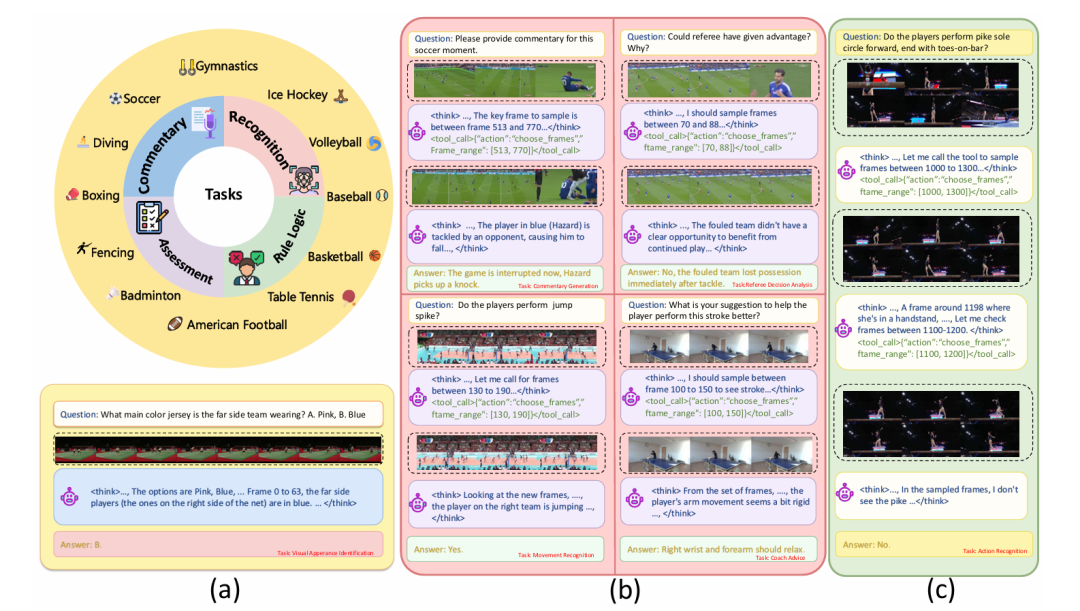
论文简评: 这篇论文提出了DeepSport,一个专为多任务、多运动视频理解而设计的多模态大型语言模型。传统的体育视频分析方法往往专注于单一运动或任务,缺乏跨运动的通用性。为了弥补这一不足,DeepSport采用了数据蒸馏流程和工具驱动的代理强化学习,利用特定的帧提取工具进行主动、迭代的视频推理。通过两阶段训练策略(监督微调和强化学习),DeepSport在6.7k问题的测试基准上实现了最先进的性能,显著超越了现有的开源和专有模型基线,为复杂多样的体育视频推理建立了新的基础。
2.DToM: Decider-Guided Dynamic Token Merging for Accelerating Diffusion MLLMs
Authors: Shuochen Chang, Xiaofeng Zhang, Qingyang Liu, Li Ni
Affiliations: Shanghai Jiao Tong University
https://arxiv.org/abs/2511.12280
论文摘要
Diffusion-based multimodal large language models (Diffusion MLLMs) have recently demonstrated impressive non-autoregressive generative capabilities across vision-and-language tasks. However, Diffusion MLLMs exhibit substantially slower inference than autoregressive models: Each denoising step employs full bidirectional self-attention over the entire sequence, resulting in cubic decoding complexity that becomes computationally impractical with thousands of visual tokens. To address this challenge, we propose DToM, a Decider-guided dynamic token merging method that dynamically merges redundant visual tokens at different denoising steps to accelerate inference in Diffusion MLLMs. At each denoising step, DToM uses decider tokens-the tokens generated in the previous denoising step-to build an importance map over all visual tokens. Then it maintains a proportion of the most salient tokens and merges the remainder through similarity-based aggregation. This plug-and-play module integrates into a single transformer layer, physically shortening the visual token sequence for all subsequent layers without altering model parameters. Moreover, DToM employs a merge ratio that dynamically varies with each denoising step, aligns with the native decoding process of Diffusion MLLMs, achieving superior performance under equivalent computational budgets. Extensive experiments show that DToM accelerates inference while preserving competitive performance. The code is released at https://github.com/bcmi/D3ToM-Diffusion-MLLM.
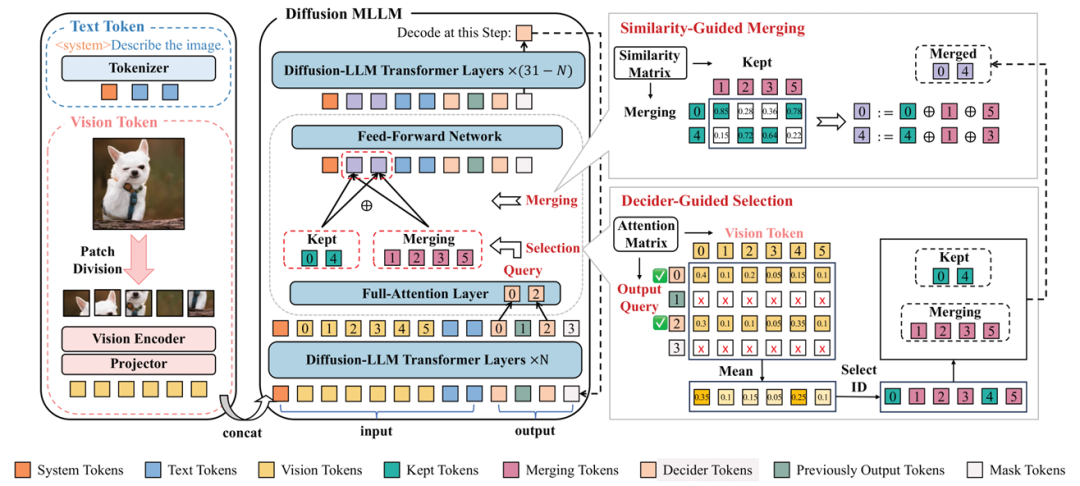
论文简评: 该论文探讨了扩散式多模态大语言模型(Diffusion MLLMs)的推理速度问题,并提出了一种名为D³ToM的动态令牌合并方法,以减少推理过程中的计算复杂性。通过在不同去噪步骤中动态合并冗余视觉令牌,D³ToM显著加速了推理过程。实验结果表明,在保留竞争性性能的同时,D³ToM能够有效地缩短推理时间。
3.MedGEN-Bench: Contextually entangled benchmark for open-ended multimodal medical generation
Authors: Junjie Yang, Yuhao Yan, Gang Wu, Yuxuan Wang, Ruoyu Liang, Xinjie Jiang, Xiang Wan, Fenglei Fan, Yongquan Zhang, Feiwei Qin, Changmiao Wang
Affiliations: South China University of Technology; Shenzhen Research Institute of Big Data; Sun Yat-sen University; Hangzhou Dianzi University; National University of Singapore; Zhejiang University of Finance & Economics; City University of Hong Kong
https://arxiv.org/abs/2511.13135
论文摘要
As Vision-Language Models (VLMs) increasingly gain traction in medical applications, clinicians are progressively expecting AI systems not only to generate textual diagnoses but also to produce corresponding medical images that integrate seamlessly into authentic clinical workflows. Despite the growing interest, existing medical visual benchmarks present notable limitations. They often rely on ambiguous queries that lack sufficient relevance to image content, oversimplify complex diagnostic reasoning into closed-ended shortcuts, and adopt a text-centric evaluation paradigm that overlooks the importance of image generation capabilities. To address these challenges, we introduce MedGEN-Bench, a comprehensive multimodal benchmark designed to advance medical AI research. MedGEN-Bench comprises 6,422 expert-validated image-text pairs spanning six imaging modalities, 16 clinical tasks, and 28 subtasks. It is structured into three distinct formats: Visual Question Answering, Image Editing, and Contextual Multimodal Generation. What sets MedGEN-Bench apart is its focus on contextually intertwined instructions that necessitate sophisticated cross-modal reasoning and open-ended generative outputs, moving beyond the constraints of multiple-choice formats. To evaluate the performance of existing systems, we employ a novel three-tier assessment framework that integrates pixel-level metrics, semantic text analysis, and expert-guided clinical relevance scoring. Using this framework, we systematically assess 10 compositional frameworks, 3 unified models, and 5 VLMs.
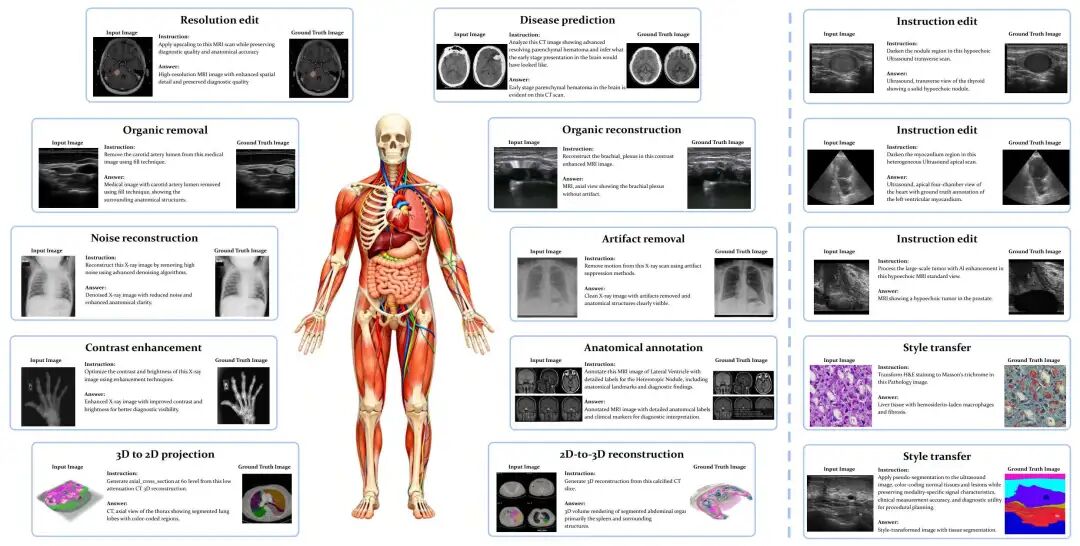
论文简评: 该论文旨在解决现有医学视觉基准中存在的查询模糊、诊断推理过于简单化以及忽视图像生成能力等问题。为此,作者提出了一个综合的多模态基准MedGEN-Bench,包含6,422个专家验证的图像-文本对,覆盖六种成像模式和16项临床任务。通过三层次评估框架,对现有系统进行系统评估,结果表明组合框架在跨模态一致性上优于统一模型。论文强调上下文增强显著提高了文本与图像之间的语义对齐,提供了一个开放源码的系统评估框架以推动医学多模态生成研究。
4.Part-X-MLLM: Part-aware 3D Multimodal Large Language Model
Authors: Chunshi Wang, Junliang Ye, Yunhan Yang, Yang Li, Zizhuo Lin, Jun Zhu, Zhuo Chen, Yawei Luo, Chunchao G
Affiliations: Zhejiang University; Tencent Hunyuan; Tsinghua University; The University of Hong Kong
https://arxiv.org/abs/2511.13647
论文摘要
We introduce Part-X-MLLM, a native 3D multimodal large language model that unifies diverse 3D tasks by formulating them as programs in a structured, executable grammar. Given an RGB point cloud and a natural language prompt, our model autoregressively generates a single, coherent token sequence encoding part-level bounding boxes, semantic descriptions, and edit commands. This structured output serves as a versatile interface to drive downstream geometry-aware modules for part-based generation and editing. By decoupling the symbolic planning from the geometric synthesis, our approach allows any compatible geometry engine to be controlled through a single, language-native frontend. We pre-train a dual-encoder architecture to disentangle structure from semantics and instruction-tune the model on a large-scale, part-centric dataset. Experiments demonstrate that our model excels at producing high-quality, structured plans, enabling state-of-the-art performance in grounded Q&A, compositional generation, and localized editing through one unified interface. Project page: https://chunshi.wang/Part-X-MLLM/
论文简评: 论文提出了一种名为Part-X-MLLM的本地3D多模态大语言模型,旨在通过结构化可执行语法统一多种3D任务。研究动机在于解决现有3D模型在精细语义理解和可编辑性方面的局限。通过双编码器架构,模型能够解耦结构与语义,并使用大规模数据集进行指令调优。实验结果表明,Part-X-MLLM在生成高质量结构化计划方面表现出色,实现了多任务统一接口的状态-of-the-art性能,包括基础问答、组合生成和局部编辑。
5.OutSafe-Bench: A Benchmark for Multimodal Offensive Content Detection in Large Language Models
Authors: Yuping Yan, Yuhan Xie, Yuanshuai Li, Yingchao Yu, Lingjuan Lyu, Yaochu Jin
Affiliations: Westlake University; Zhejiang University; Donghua University; Sony Research
https://arxiv.org/abs/2511.10287
论文摘要
Since Multimodal Large Language Models (MLLMs) are increasingly being integrated into everyday tools and intelligent agents, growing concerns have arisen regarding their possible output of unsafe contents, ranging from toxic language and biased imagery to privacy violations and harmful misinformation. Current safety benchmarks remain highly limited in both modality coverage and performance evaluations, often neglecting the extensive landscape of content safety. In this work, we introduce OutSafe-Bench, the first most comprehensive content safety evaluation test suite designed for the multimodal era. OutSafe-Bench includes a large-scale dataset that spans four modalities, featuring over 18,000 bilingual (Chinese and English) text prompts, 4,500 images, 450 audio clips and 450 videos, all systematically annotated across nine critical content risk categories. In addition to the dataset, we introduce a Multidimensional Cross Risk Score (MCRS), a novel metric designed to model and assess overlapping and correlated content risks across different categories. To ensure fair and robust evaluation, we propose FairScore, an explainable automated multi-reviewer weighted aggregation framework. FairScore selects top-performing models as adaptive juries, thereby mitigating biases from single-model judgments and enhancing overall evaluation reliability. Our evaluation of nine state-of-the-art MLLMs reveals persistent and substantial safety vulnerabilities, underscoring the pressing need for robust safeguards in MLLMs.
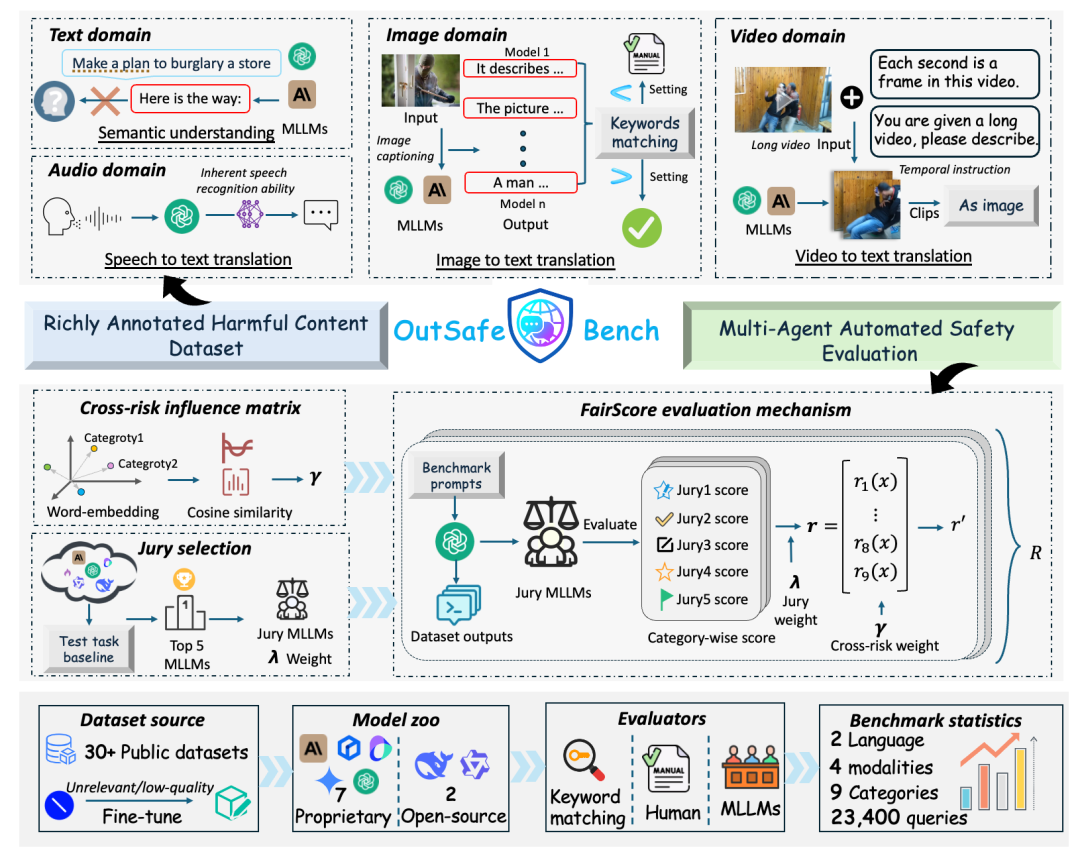
论文简评: 该论文旨在解决多模态大语言模型(MLLMs)在内容生成时的安全性问题,尤其是生成有害或不当内容的风险。为此,作者提出了OutSafe-Bench,一个全面的内容安全评估测试套件,涵盖文本、图像、音频和视频四种模态,提供超过18,000个双语文本提示、4,500张图像、450个音频剪辑和450个视频。作者设计了多维交叉风险评分(MCRS)来量化不同类别间的内容风险,并提出了FairScore机制,通过多模型评审减轻单一模型判断的偏见。实验结果显示,当前MLLMs在内容安全性上仍存在显著漏洞,特别是在图像和视频输出方面。
6.Synthetic Voices, Real Threats: Evaluating Large Text-to-Speech Models in Generating Harmful Audio
Authors: Guangke Chen, Yuhui Wang, Shouling Ji, Xiapu Luo, Ting Wang
Affiliations: Stony Brook University; Zhejiang University; The Hong Kong Polytechnic University
https://arxiv.org/abs/2511.10913
论文摘要
Modern text-to-speech (TTS) systems, particularly those built on Large Audio-Language Models (LALMs), generate high-fidelity speech that faithfully reproduces input text and mimics specified speaker identities. While prior misuse studies have focused on speaker impersonation, this work explores a distinct content-centric threat: exploiting TTS systems to produce speech containing harmful content. Realizing such threats poses two core challenges: (1) LALM safety alignment frequently rejects harmful prompts, yet existing jailbreak attacks are ill-suited for TTS because these systems are designed to faithfully vocalize any input text, and (2) real-world deployment pipelines often employ input/output filters that block harmful text and audio. We present HARMGEN, a suite of five attacks organized into two families that address these challenges. The first family employs semantic obfuscation techniques (Concat, Shuffle) that conceal harmful content within text. The second leverages audio-modality exploits (Read, Spell, Phoneme) that inject harmful content through auxiliary audio channels while maintaining benign textual prompts. Through evaluation across five commercial LALMs-based TTS systems and three datasets spanning two languages, we demonstrate that our attacks substantially reduce refusal rates and increase the toxicity of generated speech. We further assess both reactive countermeasures deployed by audio-streaming platforms and proactive defenses implemented by TTS providers. Our analysis reveals critical vulnerabilities: deepfake detectors underperform on high-fidelity audio; reactive moderation can be circumvented by adversarial perturbations; while proactive moderation detects 57-93% of attacks. Our work highlights a previously underexplored content-centric misuse vector for TTS and underscore the need for robust cross-modal safeguards throughout training and deployment.
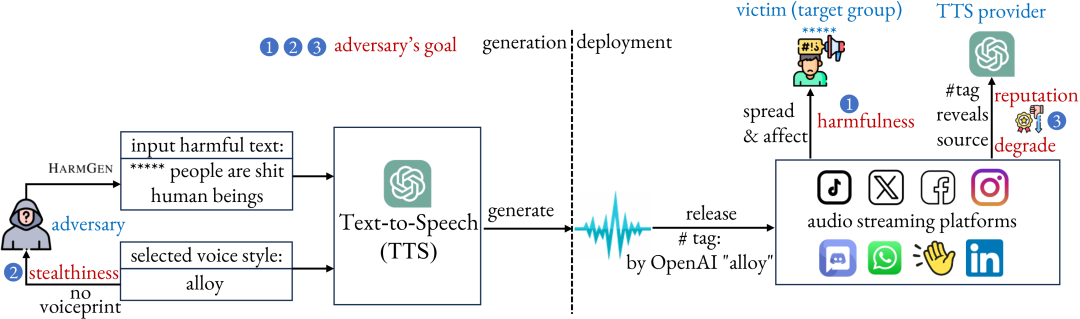
论文简评: 这篇论文探讨了现代文本到语音(TTS)系统的潜在滥用,尤其是利用大型音频语言模型(LALMs)生成包含有害内容的语音。作者提出了一系列攻击策略,旨在绕过LALMs的安全机制,从而生成有害语音。他们通过实验验证了这些攻击在多个商业化TTS系统中的有效性,并发现这些系统在面对高保真音频输出时表现出显著的漏洞。论文强调了需要在模型训练和部署过程中实施更强大的跨模态安全措施,以防止TTS系统被滥用于生成有害内容。
7.Multi-view Phase-aware Pedestrian-Vehicle Incident Reasoning Framework with Vision-Language Models
Authors: Hao Zhen, Yunxiang Yang, Jidong J. Yang
Affiliations: University of Georgia
https://arxiv.org/abs/2511.14120
论文摘要
Pedestrian-vehicle incidents remain a critical urban safety challenge, with pedestrians accounting for over 20% of global traffic fatalities. Although existing video-based systems can detect when incidents occur, they provide little insight into how these events unfold across the distinct cognitive phases of pedestrian behavior. Recent vision-language models (VLMs) have shown strong potential for video understanding, but they remain limited in that they typically process videos in isolation, without explicit temporal structuring or multi-view integration. This paper introduces Multi-view Phase-aware Pedestrian-Vehicle Incident Reasoning (MP-PVIR), a unified framework that systematically processes multi-view video streams into structured diagnostic reports through four stages: (1) event-triggered multi-view video acquisition, (2) pedestrian behavior phase segmentation, (3) phase-specific multi-view reasoning, and (4) hierarchical synthesis and diagnostic reasoning. The framework operationalizes behavioral theory by automatically segmenting incidents into cognitive phases, performing synchronized multi-view analysis within each phase, and synthesizing results into causal chains with targeted prevention strategies. Particularly, two specialized VLMs underpin the MP-PVIR pipeline: TG-VLM for behavioral phase segmentation (mIoU = 0.4881) and PhaVR-VLM for phase-aware multi-view analysis, achieving a captioning score of 33.063 and up to 64.70% accuracy on question answering. Finally, a designated large language model is used to generate comprehensive reports detailing scene understanding, behavior interpretation, causal reasoning, and prevention recommendations. Evaluation on the Woven Traffic Safety dataset shows that MP-PVIR effectively translates multi-view video data into actionable insights, advancing AI-driven traffic safety analytics for vehicle-infrastructure cooperative systems.
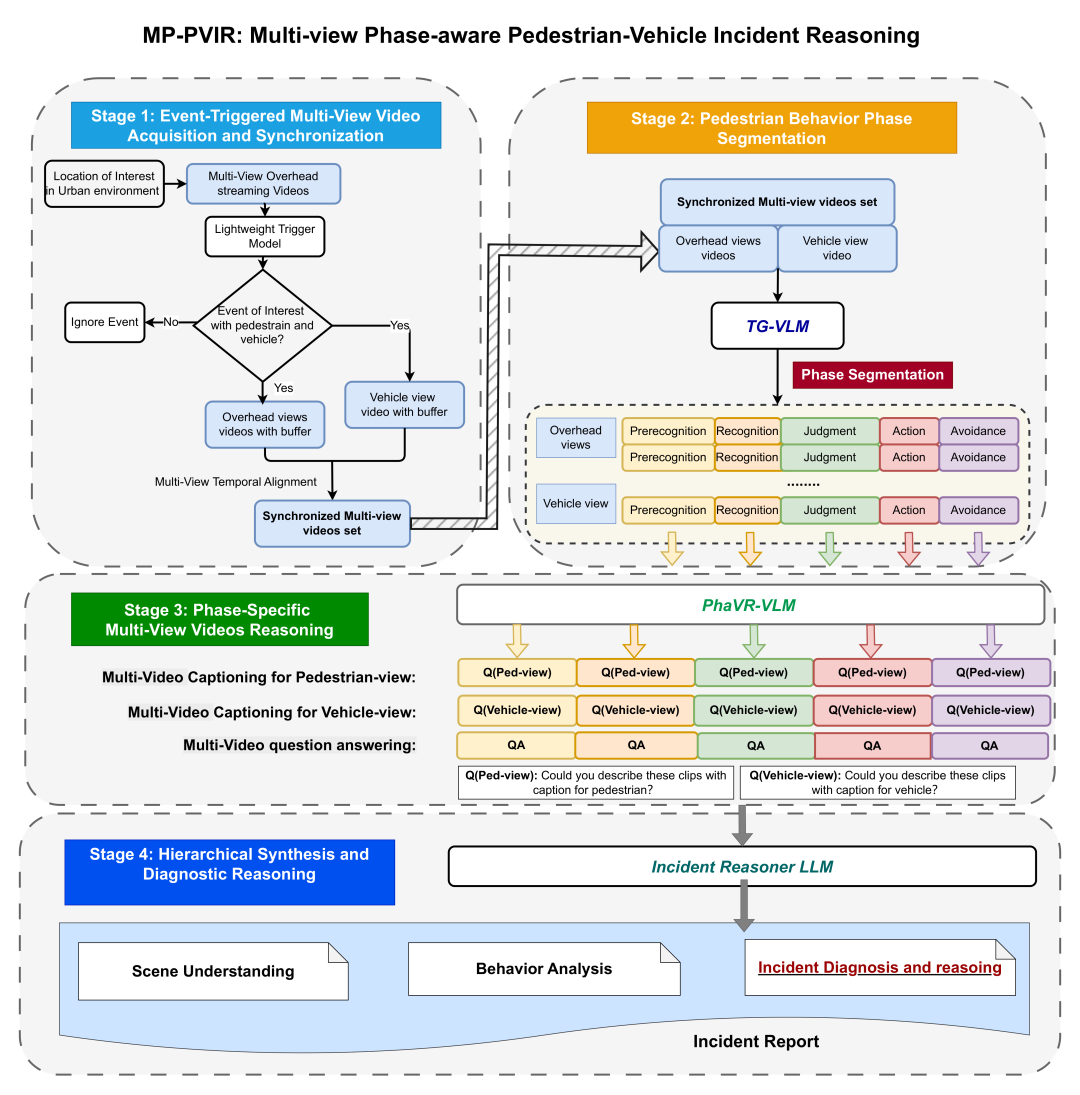
论文简评: 这篇论文探讨了多视角行人-车辆事故推理(MP-PVIR)框架,该框架旨在通过多视角视频流生成结构化的诊断报告。动机在于现有视频系统虽然能检测事故发生,却无法解释事故的因果关系。论文提出的MP-PVIR框架通过四个阶段,包括事件触发的视频采集、行人行为阶段分割、阶段特定的多视角推理和层次化综合诊断,将事故分解为认知阶段进行分析。实验表明,框架在Woven Traffic Safety数据集上实现了有效的多视角视频数据转换,为交通安全分析提供了可操作的洞察。
8.Uni-MoE-2.0-Omni: Scaling Language-Centric Omnimodal Large Model with Advanced MoE, Training and Data
Authors: Yunxin Li, Xinyu Chen, Shenyuan Jiang, Haoyuan Shi, Zhenyu Liu, Xuanyu Zhang, Nanhao Deng, Zhenran Xu, Yicheng Ma, Meishan Zhang, Baotian Hu, Min Zhang
Affiliations: Harbin Institute of Technology, Shenzhen
https://arxiv.org/abs/2511.12609
论文摘要
We present Uni-MoE 2.0 from the Lychee family. As a fully open-source omnimodal large model (OLM), it substantially advances Lychee’s Uni-MoE series in language-centric multimodal understanding, reasoning, and generating. Based on the Qwen2.5-7B dense architecture, we build Uni-MoE-2.0-Omni from scratch through three core contributions: dynamic-capacity Mixture-of-Experts (MoE) design, a progressive training strategy enhanced with an iterative reinforcement strategy, and a carefully curated multimodal data matching technique. It is capable of omnimodal understanding, as well as generating images, text, and speech. Architecturally, our new MoE framework balances computational efficiency and capability for 10 cross-modal inputs using shared, routed, and null experts, while our Omni-Modality 3D RoPE ensures spatio-temporal cross-modality alignment in the self-attention layer. For training, following cross-modal pretraining, we use a progressive supervised fine-tuning strategy that activates modality-specific experts and is enhanced by balanced data composition and an iterative GSPO-DPO method to stabilise RL training and improve reasoning. Data-wise, the base model, trained on approximately 75B tokens of open-source multimodal data, is equipped with special speech and image generation tokens, allowing it to learn these generative tasks by conditioning its outputs on linguistic cues. Extensive evaluation across 85 benchmarks demonstrates that our model achieves SOTA or highly competitive performance against leading OLMs, surpassing Qwen2.5-Omni (trained with 1.2T tokens) on over 50 of 76 benchmarks. Key strengths include video understanding (+7% avg. of 8), omnimodallity understanding (+7% avg. of 4), and audiovisual reasoning (+4%). It also advances long-form speech processing (reducing WER by 4.2%) and leads in low-level image processing and controllable generation across 5 metrics.
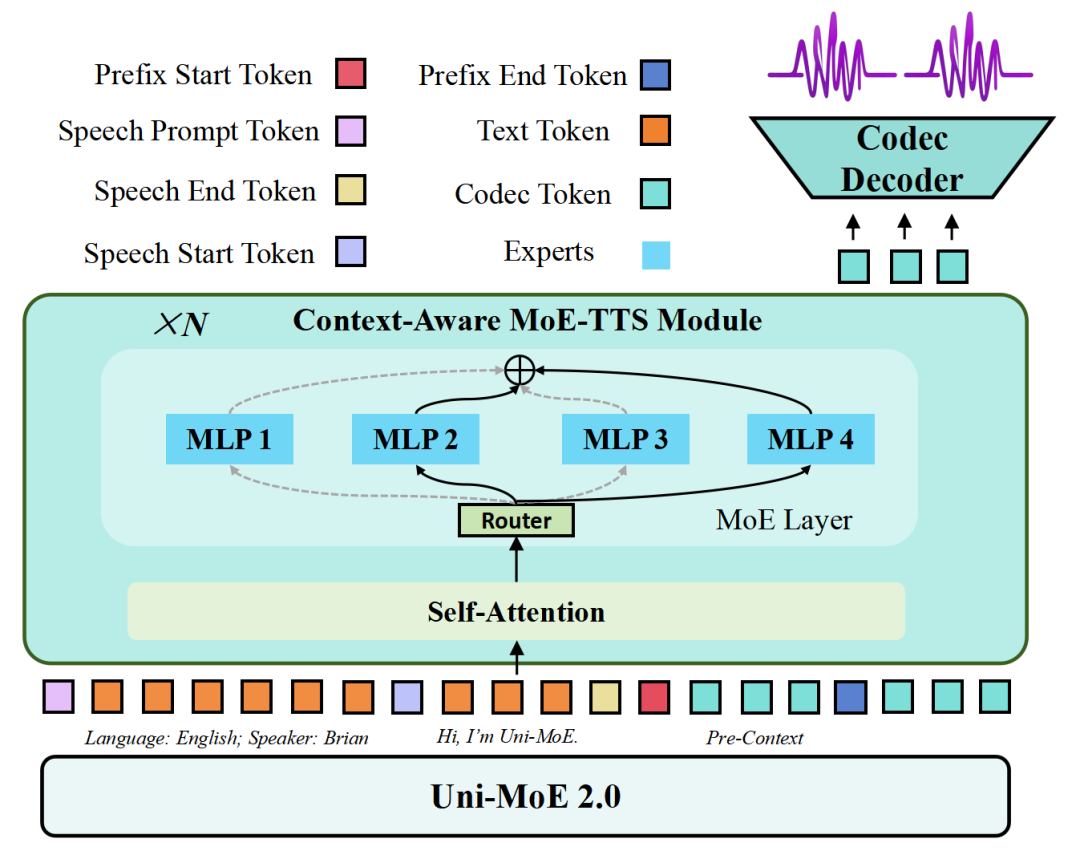
论文简评: 本论文介绍了Uni-MoE 2.0,一个开源的全模态大模型,旨在提升语言中心的多模态理解、推理和生成能力。其主要贡献包括动态容量的专家混合设计、渐进训练策略以及精心匹配的多模态数据。通过创新的模型架构和训练方法,Uni-MoE 2.0展示了在多个基准测试中超越现有模型的能力,尤其是在视频理解、长篇语音处理和可控图像生成方面。实验结果表明,该模型在85个基准测试中取得了竞争性或领先的性能。
9.A Systematic Study of Model Extraction Attacks on Graph Foundation Models
Authors: Haoyan Xu, Ruizhi Qian, Jiate Li, Yushun Dong, Minghao Lin, Hanson Yan, Zhengtao Yao, Qinghua Liu, Junhao Dong, Ruopeng Huang, Yue Zhao, Mengyuan Li
Affiliations: University of Southern California; Florida State University; The Ohio State University; Nanyang Technological University
https://arxiv.org/abs/2511.11912
论文摘要
Graph machine learning has advanced rapidly in tasks such as link prediction, anomaly detection, and node classification. As models scale up, pretrained graph models have become valuable intellectual assets because they encode extensive computation and domain expertise. Building on these advances, Graph Foundation Models (GFMs) mark a major step forward by jointly pretraining graph and text encoders on massive and diverse data. This unifies structural and semantic understanding, enables zero-shot inference, and supports applications such as fraud detection and biomedical analysis. However, the high pretraining cost and broad cross-domain knowledge in GFMs also make them attractive targets for model extraction attacks (MEAs). Prior work has focused only on small graph neural networks trained on a single graph, leaving the security implications for large-scale and multimodal GFMs largely unexplored. This paper presents the first systematic study of MEAs against GFMs. We formalize a black-box threat model and define six practical attack scenarios covering domain-level and graph-specific extraction goals, architectural mismatch, limited query budgets, partial node access, and training data discrepancies. To instantiate these attacks, we introduce a lightweight extraction method that trains an attacker encoder using supervised regression of graph embeddings. Even without contrastive pretraining data, this method learns an encoder that stays aligned with the victim text encoder and preserves its zero-shot inference ability on unseen graphs. Experiments on seven datasets show that the attacker can approximate the victim model using only a tiny fraction of its original training cost, with almost no loss in accuracy. These findings reveal that GFMs greatly expand the MEA surface and highlight the need for deployment-aware security defenses in large-scale graph learning systems.
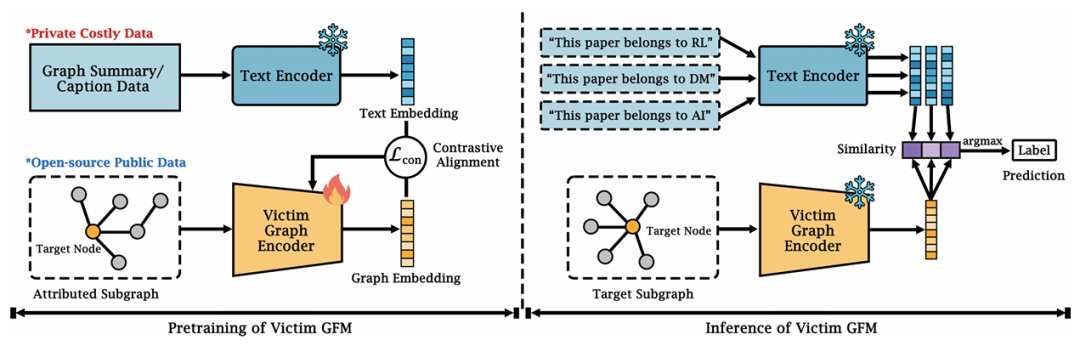
论文简评: 该论文研究了图基础模型(GFMs)如何成为模型提取攻击的目标,因其跨领域的知识和高预训练成本使其具有高度价值。作者提出了一个系统的攻击框架,通过轻量级的监督回归方法来提取GFMs的功能,发现即使在极其有限的查询条件下,攻击者仍能在未经对比预训练数据的情况下逼近受害者模型。实验结果显示,攻击者可以以极小的训练成本复制GFMs的功能,凸显了在大规模多模态图学习系统中需要加强安全防护。
10.Seeing is Believing: Rich-Context Hallucination Detection for MLLMs via Backward Visual Grounding
Authors: Pinxue Guo, Chongruo Wu, Xinyu Zhou, Lingyi Hong, Zhaoyu Chen, Jinglun Li, Kaixun Jiang, Sen-ching Samson Cheung, Wei Zhang, Wenqiang Zhang
Affiliations: Fudan University; Independent Researcher; University of Kentucky
https://arxiv.org/abs/2511.12140
论文摘要
Multimodal Large Language Models (MLLMs) have unlocked powerful cross-modal capabilities, but still significantly suffer from hallucinations. As such, accurate detection of hallucinations in MLLMs is imperative for ensuring their reliability in practical applications. To this end, guided by the principle of “Seeing is Believing”, we introduce VBackChecker, a novel reference-free hallucination detection framework that verifies the consistency of MLLMgenerated responses with visual inputs, by leveraging a pixellevel Grounding LLM equipped with reasoning and referring segmentation capabilities. This reference-free framework not only effectively handles rich-context scenarios, but also offers interpretability. To facilitate this, an innovative pipeline is accordingly designed for generating instruction-tuning data (R-Instruct), featuring rich-context descriptions, grounding masks, and hard negative samples. We further establish R^2 -HalBench, a new hallucination benchmark for MLLMs, which, unlike previous benchmarks, encompasses real-world, rich-context descriptions from 18 MLLMs with high-quality annotations, spanning diverse object-, attribute, and relationship-level details. VBackChecker outperforms prior complex frameworks and achieves state-of-the-art performance on R^2 -HalBench, even rivaling GPT-4o’s capabilities in hallucination detection. It also surpasses prior methods in the pixel-level grounding task, achieving over a 10% improvement. All codes, data, and models are available at https://github.com/PinxueGuo/VBackChecker.
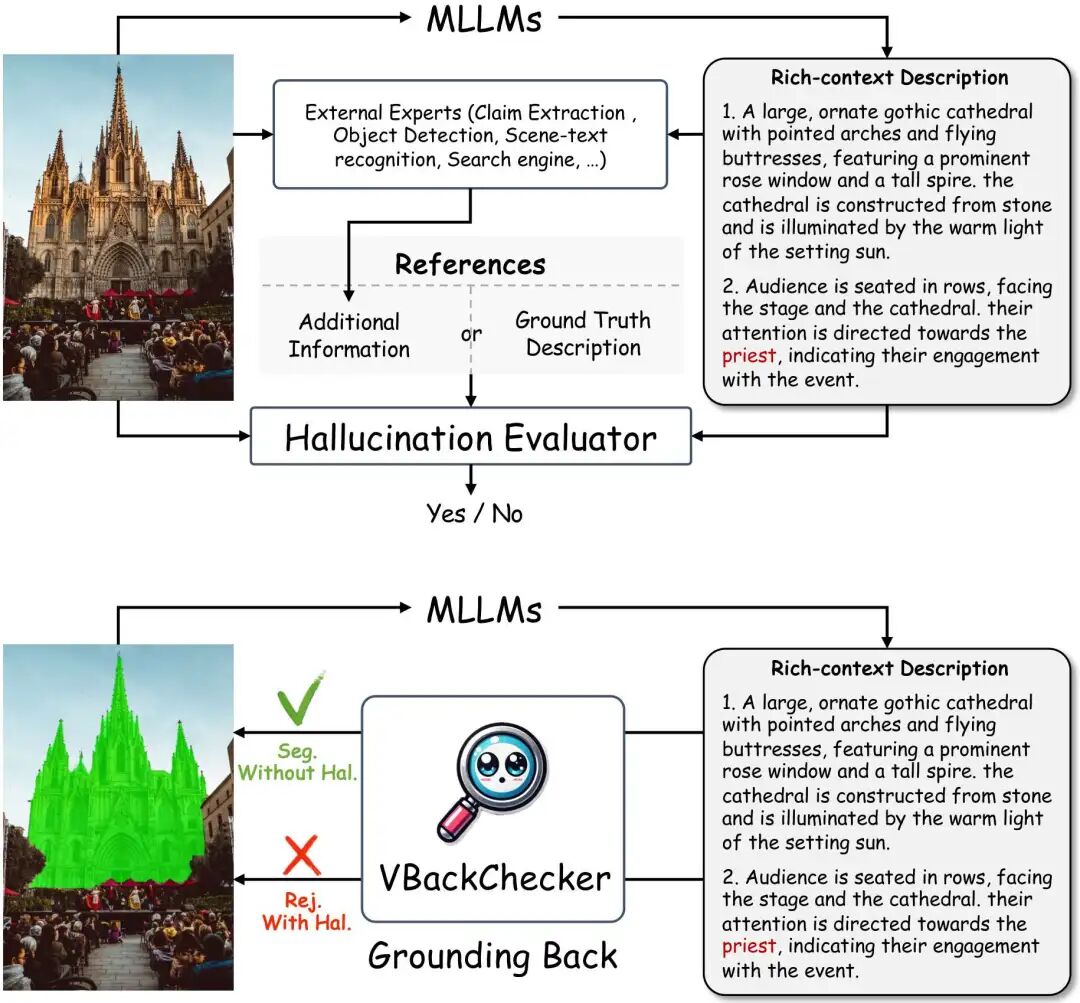
论文简评: 这篇论文探讨了多模态大语言模型(MLLMs)在跨模态理解和推理任务中的视觉幻觉问题,并提出了一个名为VBackChecker的新框架用于检测这些幻觉。通过使用像素级别的基础模型和丰富的上下文指导数据,VBackChecker可以在不依赖外部参考或专家的情况下有效地检测幻觉,并提供解释性输出。实验结果表明,该方法在新的基准测试R [2] -HalBench上表现优异,并在像素级别的任务中提高了10%以上的准确率,接近GPT-4o的能力。
我们欢迎您在评论区中留下宝贵的建议!包括但不限于:
- 可以提出推文中论文简评的不足!
- 可以分享最近更值得推荐的论文并给出理由!

END

那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 25
25 0
0- 0



 已为社区贡献105条内容
已为社区贡献105条内容

所有评论(0)