通过基于自我一致性的幻觉检测增强大语言模型的数学推理能力
大语言模型(LLMs)已经展现出强大的数学推理能力,但仍然容易产生幻觉——即生成看似合理但实际上错误的陈述——尤其是在定理证明、符号操作和数值计算方面。尽管自我一致性(SC)已被探索作为提高LLMs事实性的一种方法,现有方法主要将SC应用于最终答案的选择,忽略了中间推理步骤的逻辑一致性。在本研究中,我们引入了一种结构化的自我一致性框架,旨在提高数学推理的可靠性。我们的方法在中间步骤和最终输出中强制
刘明山 1{ }^{1}1, 王石波, 方佳玲 2{ }^{2}2,
1{ }^{1}1 香港科技大学 2{ }^{2}2 复旦大学
摘要
大语言模型(LLMs)已经展现出强大的数学推理能力,但仍然容易产生幻觉——即生成看似合理但实际上错误的陈述——尤其是在定理证明、符号操作和数值计算方面。尽管自我一致性(SC)已被探索作为提高LLMs事实性的一种方法,现有方法主要将SC应用于最终答案的选择,忽略了中间推理步骤的逻辑一致性。在本研究中,我们引入了一种结构化的自我一致性框架,旨在提高数学推理的可靠性。我们的方法在中间步骤和最终输出中强制执行自我一致性,减少逻辑不一致性和幻觉。我们在三个核心数学任务上评估了我们的方法:定理证明、符号转换和数值计算。实验结果表明,SC显著提高了证明的有效性、符号推理的准确性以及数值稳定性,同时保持了计算效率。进一步分析显示,结构化的自我一致性不仅提高了问题解决的准确性,还减少了模型生成输出的方差。这些发现突显了自我一致性作为一种强大机制,可以改进LLMs中的数学推理,为更可靠和可解释的人工智能驱动数学铺平道路。
1 引言
大语言模型(LLMs)在自然语言处理(NLP)和数学推理领域取得了重大突破(Kapfer等人,2025年)。最近的模型在定理证明、符号操作和数值问题解决方面表现出显著的能力(Lightman等人,2023年;Wang等人,2024b,c)。然而,尽管有这些进展,LLMs仍然难以应对幻觉——即生成看似合理但事实上不正确的输出(He等人,2024年)。在数学推理中,正确性是严格二元的,幻觉可以通过多步推导传播,导致根本上有缺陷的证明或不正确的计算(Zhong等人,2023年)。这些错误削弱了LLMs在需要高精度推理的应用中的可靠性,例如自动定理证明和科学计算(Jain等人,2024年)。
先前的研究探讨了各种方法来减轻LLMs中的幻觉,包括在高质量数据集上进行微调(Xin等人,2024年)、纳入外部验证机制(Ankner等人,2024年)以及设计混合神经-符号架构(Kapfer等人,2025年)。一种有前途的方法是自我一致性(SC),它通过聚合多个独立推理路径并选择最一致的响应来增强事实可靠性(Lightman等人,2023年)。虽然SC已成功应用于一般的问答任务(Wang等人,2024b),但其在数学推理中的应用仍然有限。现有的基于SC的方法主要集中在验证最终答案,而忽视了中间推理步骤(Wang等人,2024c),这使得它们在定理证明和多步符号推理中无效。此外,SC需要多个响应样本,增加了计算成本,但准确率提升与推理效率之间的权衡仍需进一步研究(He等人,2024年)。
受这些挑战的启发,我们研究了自我一致性在数学推理中的新应用,其中SC不仅应用于最终输出,还应用于中间推理步骤。我们的直觉是,自我一致性可以作为一种结构化验证机制,强化多步数学推导中的逻辑连贯性。通过将SC扩展到简单的答案聚合之外,我们旨在提高LLMs在定理证明、代数变换和数值问题解决中的可靠性。此外,我们假设结构化的SC应用可以在维持计算效率的同时减少幻觉,解决推理准确性和推理成本之间的权衡。
为了验证这一直觉,我们提出了一个数学推理的自我一致性框架,系统地将SC应用于问题解决的中间和最终步骤。我们在三个关键数学推理任务上进行了全面的实证研究:1)定理证明:确保逻辑演绎的一致性;2)符号操作:提高代数变换的准确性;3)数值计算:增强计算任务的稳定性。我们的广泛实验表明,SC显著减少了幻觉,提高了逻辑一致性,并增强了多个数据集上的数学准确性。此外,我们分析了SC的计算权衡,量化了其对推理成本和问题解决效率的影响。
贡献 本文作出了以下关键贡献:
- 我们提出了一种新颖的自我一致性框架,该框架将SC扩展到中间推理步骤,而不仅仅是最终答案,从而提高了逐步逻辑连贯性。
-
- 我们在三个不同的数学推理领域对自我一致性进行了全面评估:定理证明、符号操作和数值计算。
-
- 我们分析了自我一致性的计算权衡,展示了结构化SC应用在维持推理效率的同时提高了准确性。
-
- 我们在基准数学数据集上提供了广泛的实证结果,表明我们的方法显著减少了幻觉并提高了问题解决的准确性。
2 方法论
本节介绍了我们基于自我一致性的方法,用于提高大语言模型(LLMs)在数学推理中的事实可靠性。我们首先介绍自我一致性的理论基础,然后描述我们验证数学陈述和证明的方法。
2.1 自我一致性理论基础
大语言模型(LLMs)中的自我一致性指的是对同一查询的多个独立采样响应之间的一致性。先前的研究表明,更高的自我一致性与改善的事实可靠性相关联(Farquhar等人,2024年)。在数学推理任务中,由于正确性是严格二元的,自我一致性在区分有效证明和幻觉或错误陈述中起着关键作用。
自我一致性的定义 给定一个数学陈述 sis_{i}si,我们将其自我一致性事实得分定义为:
f(si)=1∣R∣∑rj∈RP( consistent ∣si,rj) f\left(s_{i}\right)=\frac{1}{|\mathcal{R}|} \sum_{r_{j} \in \mathcal{R}} P\left(\text { consistent } \mid s_{i}, r_{j}\right) f(si)=∣R∣1rj∈R∑P( consistent ∣si,rj)
其中 R={r1,r2,…,rk}\mathcal{R}=\left\{r_{1}, r_{2}, \ldots, r_{k}\right\}R={r1,r2,…,rk} 表示通过不同随机采样方法(例如温度采样、核采样)获得的对同一问题的响应集合。函数 P(P\left(\right.P( consistent ∣si,rj)\left.\mid s_{i}, r_{j}\right)∣si,rj) 表示响应 rjr_{j}rj 与 sis_{i}si 的真正数学正确性一致的概率。
概率解释 从概率的角度来看,自我一致性可以被视为在概率空间 (Ω,F,P)(\Omega, \mathcal{F}, P)(Ω,F,P) 上的期望。设 SiS_{i}Si 是指示陈述 sis_{i}si 正确性的随机变量,采样响应 RRR 从条件概率分布 P(R∣Si)P\left(R \mid S_{i}\right)P(R∣Si) 中抽取。预期的自我一致性事实得分可以重写为:
E[f(Si)]=∑rj∈RP(Si∣rj)P(rj) \mathbb{E}\left[f\left(S_{i}\right)\right]=\sum_{r_{j} \in \mathcal{R}} P\left(S_{i} \mid r_{j}\right) P\left(r_{j}\right) E[f(Si)]=rj∈R∑P(Si∣rj)P(rj)
这种表述允许我们将自我一致性解释为一个贝叶斯估计问题,其中多个采样响应共同有助于细化正确性的概率。
自我一致性作为一致性度量指标 为了量化采样响应之间的一致性,我们引入了一个响应间一致性函数:
C(si)=1∣R∣∑rj,rk∈R,j≠k1(rj=rk) C\left(s_{i}\right)=\frac{1}{|R|} \sum_{r_{j}, r_{k} \in R, j \neq k} \mathbb{1}\left(r_{j}=r_{k}\right) C(si)=∣R∣1rj,rk∈R,j=k∑1(rj=rk)
其中 1(⋅)\mathbb{1}(\cdot)1(⋅) 是一个指示函数,当两个响应相同时返回1,否则返回0。较高的 C(si)C\left(s_{i}\right)C(si) 值表示采样响应之间更强的一致性,暗示更可靠的事实估计。
贝叶斯更新以优化自我一致性 给定关于响应分布正确性的初始信念,我们可以使用贝叶斯更新迭代地优化我们的事实估计:
P(Si∣R)∝P(Si)∏rj∈RP(rj∣Si) P\left(S_{i} \mid \mathcal{R}\right) \propto P\left(S_{i}\right) \prod_{r_{j} \in R} P\left(r_{j} \mid S_{i}\right) P(Si∣R)∝P(Si)rj∈R∏P(rj∣Si)
这种方法实现了自适应过滤,其中一致性较低的响应对最终事实得分的贡献较小。随着更多响应被聚合,概率分布收敛到更自信的评估。
与熵基度量的关系 自我一致性也可以与熵基不确定性度量相关联。响应分布的香农熵由下式给出:
H(R)=−∑rj∈RP(rj)logP(rj) H(R)=-\sum_{r_{j} \in R} P\left(r_{j}\right) \log P\left(r_{j}\right) H(R)=−rj∈R∑P(rj)logP(rj)
较低的熵意味着更高的自我一致性,因为响应分布集中在单一正确答案周围。通过最小化熵,我们可以提高LLMs生成数学陈述的可靠性。
2.2 数学推理中的自我一致性
自我一致性在数学推理中的应用需要专门的技术来验证逻辑推导、符号操作和数值计算。与通常主观性强的普通文本生成任务不同,数学推理要求严格的正确性。我们介绍了三个主要领域,其中自我一致性增强了推理的可靠性:定理证明、符号操作和数值验证。
定理证明与逻辑推导 在形式数学中,证明是从公理和先前建立的定理中逻辑推导出结论的一系列推导步骤。给定
一个定理陈述 TTT,我们采样多个证明尝试 P={p1,p2,…,pm}\mathcal{P}=\left\{p_{1}, p_{2}, \ldots, p_{m}\right\}P={p1,p2,…,pm} 并分析它们的结构一致性。
为了量化证明的一致性,我们定义了结构证明一致性得分:
Cproof =1m∑pi∈P∑pj∈P,j≠iδ(pi,pj) C_{\text {proof }}=\frac{1}{m} \sum_{p_{i} \in \mathcal{P}} \sum_{p_{j} \in P, j \neq i} \delta\left(p_{i}, p_{j}\right) Cproof =m1pi∈P∑pj∈P,j=i∑δ(pi,pj)
其中 δ(pi,pj)\delta\left(p_{i}, p_{j}\right)δ(pi,pj) 是一个结构相似性函数,比较两个证明中的逻辑步骤序列。较高的 Cproof C_{\text {proof }}Cproof 值表示采样证明之间更大的收敛性,暗示更高的可靠性。
为了进一步细化一致性评估,我们引入了一个逐步证明验证函数:
V(pi)=∏t=1T1( step t is valid ) V\left(p_{i}\right)=\prod_{t=1}^{T} \mathbb{1}(\text { step } t \text { is valid }) V(pi)=t=1∏T1( step t is valid )
其中 TTT 是证明总步数,1(⋅)\mathbb{1}(\cdot)1(⋅) 是一个指示函数,如果步骤 ttt 在逻辑上是有效的则返回1,否则返回0。通过汇总所有证明样本的 V(pi)V\left(p_{i}\right)V(pi),我们估计定理的自我一致性可靠性。
符号操作 许多数学问题涉及符号表达式的转换,例如代数简化、方程求解和微分。一个关键挑战是确保不同的采样响应产生等效表达式。
给定一个数学表达式 eee,我们获得多个转换 E={e1,e2,…,ek}\mathcal{E}=\left\{e_{1}, e_{2}, \ldots, e_{k}\right\}E={e1,e2,…,ek} 并使用基于树的结构比较来测量它们的一致性:
S(e1,e2)=∣T(e1)∩T(e2)∣∣T(e1)∪T(e2)∣ S\left(e_{1}, e_{2}\right)=\frac{\left|\mathcal{T}\left(e_{1}\right) \cap \mathcal{T}\left(e_{2}\right)\right|}{\left|\mathcal{T}\left(e_{1}\right) \cup \mathcal{T}\left(e_{2}\right)\right|} S(e1,e2)=∣T(e1)∪T(e2)∣∣T(e1)∩T(e2)∣
其中 T(e)\mathcal{T}(e)T(e) 表示表达式 eee 的语法树。这个度量评估不同采样输出的结构相似性,并确保它们收敛到相同的数学表示。
此外,我们定义了符号转换的等价概率:
Peq(e)=1∣E∣∑ei,ej∈E,i≠j1(ei≡ej) P_{\mathrm{eq}}(e)=\frac{1}{|\mathcal{E}|} \sum_{e_{i}, e_{j} \in \mathcal{E}, i \neq j} \mathbb{1}\left(e_{i} \equiv e_{j}\right) Peq(e)=∣E∣1ei,ej∈E,i=j∑1(ei≡ej)
其中 ei≡eje_{i} \equiv e_{j}ei≡ej 表示两个表达式在代数上是等价的。高的 Peq (e)P_{\text {eq }}(e)Peq (e) 值表明符号推理中有强自我一致性。
数值计算 在数值问题求解中,一致性通过验证多个采样计算是否产生相同数值结果来评估。给定一个函数 f(x)f(x)f(x) 和输入 xxx,我们生成多个数值输出 N={n1,n2,…,nk}\mathcal{N}=\left\{n_{1}, n_{2}, \ldots, n_{k}\right\}N={n1,n2,…,nk} 并计算数值一致性得分:
Cnum =1k∑ni∈N∑nj∈N,j≠iI(ni=nj) C_{\text {num }}=\frac{1}{k} \sum_{n_{i} \in \mathcal{N}} \sum_{n_{j} \in \mathcal{N}, j \neq i} \mathbb{I}\left(n_{i}=n_{j}\right) Cnum =k1ni∈N∑nj∈N,j=i∑I(ni=nj)
通过将自我一致性分析应用于定理证明、符号操作和数值计算,我们提高了LLM生成数学推理的事实可靠性。这些技术提供了一个强大的框架,用于检测幻觉并确保自动化数学问题求解的正确性。
2.3 数学一致性估计
由于大语言模型(LLMs)的随机生成机制,其数学推理本质上具有概率性。为了系统地量化生成数学陈述的一致性,我们引入了一组估计函数,这些函数衡量采样响应之间的一致性。这些估计方法适用于定理证明、符号推理和数值计算。
全局自我一致性得分 给定一组对数学查询的响应 R={r1,r2,…,rk}\mathcal{R}=\left\{r_{1}, r_{2}, \ldots, r_{k}\right\}R={r1,r2,…,rk},我们定义全局自我一致性得分为:
Cglobal =1k∑ri,rj∈R,i≠jI(ri=rj) C_{\text {global }}=\frac{1}{k} \sum_{r_{i}, r_{j} \in \mathcal{R}, i \neq j} \mathbb{I}\left(r_{i}=r_{j}\right) Cglobal =k1ri,rj∈R,i=j∑I(ri=rj)
其中 I(⋅)\mathbb{I}(\cdot)I(⋅) 是一个指示函数,评估两个采样响应是否相同。这个指标直接衡量模型生成一致输出的频率。
定理证明一致性 对于定理证明,需要更结构化的估计。给定一组采样证明 P={p1,p2,…,pm}\mathcal{P}=\left\{p_{1}, p_{2}, \ldots, p_{m}\right\}P={p1,p2,…,pm},我们定义一个结构证明一致性得分,用于衡量逐步对齐:
Cproof =1m∑pi,pj∈P,i≠jS(pi,pj) C_{\text {proof }}=\frac{1}{m} \sum_{p_{i}, p_{j} \in \mathcal{P}, i \neq j} S\left(p_{i}, p_{j}\right) Cproof =m1pi,pj∈P,i=j∑S(pi,pj)
其中 S(pi,pj)S\left(p_{i}, p_{j}\right)S(pi,pj) 表示一个相似性函数,比较两个证明的逻辑步骤,归一化在0到1之间。我们通过匹配对应的证明步骤并计算对齐得分来计算 S(pi,pj)S\left(p_{i}, p_{j}\right)S(pi,pj):
S(pi,pj)=1T∑t=1TI(si,t=sj,t) S\left(p_{i}, p_{j}\right)=\frac{1}{T} \sum_{t=1}^{T} \mathbb{I}\left(s_{i, t}=s_{j, t}\right) S(pi,pj)=T1t=1∑TI(si,t=sj,t)
其中 si,ts_{i, t}si,t 是证明 pip_{i}pi 的第 ttt 步,TTT 是证明的总步数。较高的 Cproof C_{\text {proof }}Cproof 表示证明结构之间更大的一致性。
符号表达式一致性 符号操作引入了额外的挑战,因为等效表达式可能在语法上并不相同。为了考虑这一点,我们基于语义等价定义符号一致性得分:
Csymbolic =1∣E∣∑ei,ej∈E,i≠jI(ei≡ej) C_{\text {symbolic }}=\frac{1}{|\mathcal{E}|} \sum_{e_{i}, e_{j} \in \mathcal{E}, i \neq j} \mathbb{I}\left(e_{i} \equiv e_{j}\right) Csymbolic =∣E∣1ei,ej∈E,i=j∑I(ei≡ej)
其中 ei≡eje_{i} \equiv e_{j}ei≡ej 表示两个表达式在代数上是等价的。这是通过代数简化或方程规范化等符号计算工具确定的。
为了细化符号一致性,我们引入了一个基于树的相似性函数:
Stree (e1,e2)=∣T(e1)∩T(e2)∣∣T(e1)∪T(e2)∣ S_{\text {tree }}\left(e_{1}, e_{2}\right)=\frac{\left|\mathcal{T}\left(e_{1}\right) \cap \mathcal{T}\left(e_{2}\right)\right|}{\left|\mathcal{T}\left(e_{1}\right) \cup \mathcal{T}\left(e_{2}\right)\right|} Stree (e1,e2)=∣T(e1)∪T(e2)∣∣T(e1)∩T(e2)∣
其中 T(e)\mathcal{T}(e)T(e) 是表达式语法树中的节点集合。这个度量量化了两个表达式的结构相似性,即使它们并不完全相同。
数值稳定性估计 对于数值推理,一致性通过生成输出的方差定义。给定数值结果 N={n1,n2,…,nk}\mathcal{N}=\left\{n_{1}, n_{2}, \ldots, n_{k}\right\}N={n1,n2,…,nk},我们通过方差减少计算数值稳定性得分:
Cnum =1−σ2(N)max(σref 2,ϵ) C_{\text {num }}=1-\frac{\sigma^{2}(\mathcal{N})}{\max \left(\sigma_{\text {ref }}^{2}, \epsilon\right)} Cnum =1−max(σref 2,ϵ)σ2(N)
其中 σ2(N)\sigma^{2}(\mathcal{N})σ2(N) 是采样数值结果的方差,σref 2\sigma_{\text {ref }}^{2}σref 2 是参考方差阈值。小常数 ϵ\epsilonϵ 确保数值稳定性。较低的方差意味着更高的数值一致性。
或者,我们可以计算一个阈值化的一致性得分:
Anum =1k∑ni,nj∈N,i≠jI(∣ni−nj∣<τ) A_{\text {num }}=\frac{1}{k} \sum_{n_{i}, n_{j} \in \mathcal{N}, i \neq j} \mathbb{I}\left(\left|n_{i}-n_{j}\right|<\tau\right) Anum =k1ni,nj∈N,i=j∑I(∣ni−nj∣<τ)
其中 τ\tauτ 是预定义的数值容差。这考虑了浮点变化,同时确保一致性。
基于熵的不确定性估计 自我一致性还可以与基于熵的不确定性度量联系起来。我们将采样响应的熵定义为:
H(R)=−∑rj∈RP(rj)logP(rj) H(R)=-\sum_{r_{j} \in R} P\left(r_{j}\right) \log P\left(r_{j}\right) H(R)=−rj∈R∑P(rj)logP(rj)
较低的熵表示更高的一致性,因为响应趋向于单一、可信的答案。通过最小化熵,我们减少了数学推理任务中的模糊性。
这些数学一致性估计方法共同提供了一种结构化的方法,用于量化LLM生成的证明、符号推理和数值计算的可靠性。
2.4 错误传播分析
尽管自我一致性提高了大语言模型(LLMs)中数学推理的可靠性,但在多步问题解决场景中,错误仍可能在推理的不同阶段传播。为了系统地分析和减轻此类错误传播,我们引入了一个结构化评估框架,跟踪中间步骤中的不一致性。
逐步一致性验证 数学推理通常涉及顺序步骤,每个步骤都建立在前一个步骤之上。给定一个多步推导 D={s1,s2,…,sT}D=\left\{s_{1}, s_{2}, \ldots, s_{T}\right\}D={s1,s2,…,sT},其中 sts_{t}st 表示第 ttt 步,我们定义逐步一致性得分为:
Cstep =1T∑t=1TI(st=s^t) C_{\text {step }}=\frac{1}{T} \sum_{t=1}^{T} \mathbb{I}\left(s_{t}=\hat{s}_{t}\right) Cstep =T1t=1∑TI(st=s^t)
其中 s^t\hat{s}_{t}s^t 表示位置 ttt 的预期正确步骤,I(⋅)\mathbb{I}(\cdot)I(⋅) 是一个指示函数,评估正确性。这个得分量化了模型遵循一致推理轨迹的程度。
错误积累函数 为了评估错误如何在顺序步骤中积累,我们引入了一个错误积累函数:
E(D)=∑t=1Tλtλ^(st≠s^t) E(D)=\sum_{t=1}^{T} \lambda_{t} \hat{\lambda}\left(s_{t} \neq \hat{s}_{t}\right) E(D)=t=1∑Tλtλ^(st=s^t)
其中 λt\lambda_{t}λt 是一个加权因子,考虑不同阶段错误的影响。早期阶段的错误(ttt 较小)在后期步骤中可能更加显著地累积,因此需要指数加权函数:
λt=eα(t−1) \lambda_{t}=e^{\alpha(t-1)} λt=eα(t−1)
其中 α\alphaα 是一个缩放因子,决定早期错误对后续步骤的影响程度。
错误传播概率 除了个别步骤外,我们还分析了错误在后续步骤中传播的概率。给定步骤 ttt 发生错误,其传播到步骤 t+1t+1t+1 的概率建模为:
P(st+1 incorrect ∣st incorrect )=βt P\left(s_{t+1} \text { incorrect } \mid s_{t} \text { incorrect }\right)=\beta_{t} P(st+1 incorrect ∣st incorrect )=βt
其中 βt\beta_{t}βt 是一个经验确定的传播因子,取决于问题类型。最终结果不正确的整体概率可以通过递归近似:
P(sT incorrect )=1−∏t=1T(1−βtI(st≠s^t)) P\left(s_{T} \text { incorrect }\right)=1-\prod_{t=1}^{T}\left(1-\beta_{t} \mathbb{I}\left(s_{t} \neq \hat{s}_{t}\right)\right) P(sT incorrect )=1−t=1∏T(1−βtI(st=s^t))
较高的 P(sTP\left(s_{T}\right.P(sT 不正确 ))) 值表示错误在整个推理步骤中更有可能持续存在。
逻辑流一致性 为了超越逐步骤正确性追踪逻辑一致性,我们引入了一个依赖图一致性度量。我们将多步推理建模为一个有向无环图(DAG),其中节点代表各个步骤,边编码逻辑依赖关系。设 G=(V,E)G=(V, E)G=(V,E) 是一个推理图,顶点为 VVV 和有向边为 EEE,整体逻辑一致性得分为:
Clogic =1∣E∣∑(t,j)∈EI(st supports sj) C_{\text {logic }}=\frac{1}{|E|} \sum_{\left(t, j\right) \in E} \mathbb{I}\left(s_{t} \text { supports } s_{j}\right) Clogic =∣E∣1(t,j)∈E∑I(st supports sj)
此函数评估中间步骤是否逻辑连贯,确保没有循环推理或不合理的跳跃。
缓解策略 为了减少错误传播,我们采用两种主要策略:1. 重新评估和回溯:如果步骤 sts_{t}st 被检测为与先前推理不一致,则模型重新生成步骤 st,st+1,…,sTs_{t}, s_{t+1}, \ldots, s_{T}st,st+1,…,sT,同时约束生成以与早期步骤一致。2. 通过多路径推理自我检查:模型不是生成单一序列,而是生成多个独立推理路径 D1,D2,…,DkD_{1}, D_{2}, \ldots, D_{k}D1,D2,…,Dk,并根据以下公式选择最一致的轨迹:
D∗=argmaxDiCstep (Di)+Clogic (Di) D^{*}=\arg \max _{D_{i}} C_{\text {step }}\left(D_{i}\right)+C_{\text {logic }}\left(D_{i}\right) D∗=argDimaxCstep (Di)+Clogic (Di)
这种方法确保只有逻辑一致且自我强化的推导被选中。
通过结合这些技术,我们建立了一个严格的框架,用于监控和减轻错误传播,从而增强LLMs中数学推理的可靠性。
3 实验设计
为了系统评估基于自我一致性幻觉检测在数学推理中的有效性,我们根据之前工作中的评估设置(Kapfer等人,2025年;Lightman等人,2023年;Wang等人,2024b)设计了一系列实验。
3.1 研究问题
我们旨在回答以下研究问题:
- RQ1: 自我一致性如何提高LLM生成数学证明的事实准确性?
-
- RQ2: 自我一致性在多大程度上减轻了符号推理中的幻觉?
-
- RQ3: 自我一致性是否提高了数学问题求解中的数值一致性?
-
- RQ4: 自我一致性如何与数学推理任务中的传统准确率指标相关联?
3.2 实验设置
我们的实验遵循先前工作中的方法论(Wang等人,2024c;He等人,2024;Jain等人,2024;Zhong等人,2023),针对数学推理领域进行了调整。
评估模型 我们使用以下模型进行实验,与我们之前的研究所一致:
-
基础LLM(Kapfer等人,2025):一个基于变压器的自回归模型,训练用于数学推理任务。
-
- 自我一致性LLM(SC-LLM)(Lightman等人,2023):我们提出的模型变体,应用自我一致性过滤以优化生成响应。
数据集 我们使用以前工作中使用的基准数据集进行评估(Xin等人,2024;Ankner等人,2024):
- 自我一致性LLM(SC-LLM)(Lightman等人,2023):我们提出的模型变体,应用自我一致性过滤以优化生成响应。
-
数学证明数据集(Kapfer等人,2025):用于评估LLM在定理证明中的表现的数据集。
-
- 符号推理数据集(Wang等人,2024b):需要表达式操作的代数和符号转换问题的集合。
-
- 数值推理数据集(Lightman等人,2023):一组计算问题,旨在测量数值计算的稳定性。
基线方法 我们将我们的自我一致性方法与以前工作中描述的基线方法进行比较(Xin等人,2024;Ankner等人,2024):
- 数值推理数据集(Lightman等人,2023):一组计算问题,旨在测量数值计算的稳定性。
-
单步生成(SSG)(Kapfer等人,2025):标准方法,LLM生成单个响应而不进行自我一致性验证。
-
- 多数投票(MV)(Lightman等人,2023):一个基线自我一致性方法,选择多次采样响应中最常出现的答案。
-
- 基于置信度的过滤(CBF)(Wang等人,2024c):一种过滤机制,根据内部概率分数选择最可信的响应。
3.3 评估指标
我们采用了多个评估指标,与我们之前的研究一致(Wang等人,2024b),以评估自我一致性的效果。
定理证明指标
- 证明有效性(%)(Kapfer等人,2025):生成的证明与真实解决方案相符的比例。
-
- 逐步协议得分(SAS)(Lightman等人,2023):生成的证明步骤与验证的证明序列平均协议率。
-
- 逻辑流一致性(LFC)(Wang等人,2024b):一个多步骤推理中的逻辑连贯性的图基度量。
符号推理指标
- 表达式等价性(%)(Wang等人,2024c):采样的符号转换在语义上等价的比例。
-
- 树相似性指数(TSI)(Kapfer等人,2025):生成的符号表达式之间的结构相似性度量。
数值稳定性指标
- 方差减少(VR)(Lightman等人,2023):应用自我一致性后数值输出方差的减少。
-
- 阈值一致性(TC)(Xin等人,2024):采样的数值响应落在预定义数值容差范围内的比例。
3.4 实验协议
为了确保一致性和可重复性,我们在以下控制条件下进行实验(Wang等人,2024c;He等人,2024;Jain等人,2024;Zhong等人,2023):
- 每个模型使用固定的温度参数为每个查询生成 k=10k=10k=10 个独立响应,如我们在之前的实验设置中所定义。
-
- 我们使用自动定理验证进行证明验证。
-
- 对于符号推理,我们使用代数简化技术比较表达式以检测语义等价性。
-
- 数值输出使用我们之前工作的基于精度的误差阈值进行评估。
-
- 每个实验重复三次,并报告结果的平均值及置信区间。
通过系统研究这些问题和实验设置,我们旨在确立自我一致性在提高LLMs数学推理可靠性方面的有效性。
- 每个实验重复三次,并报告结果的平均值及置信区间。
4 实验结果
4.1 自我一致性与数学证明的事实准确性(RQ1)
为了评估自我一致性对LLM生成数学证明事实准确性的影响,我们分析了在应用自我一致性过滤前后生成证明的正确性。主要评估指标包括:
- 证明有效性(%):生成的证明与真实解决方案相符的比例。
-
- 逐步协议得分(SAS):生成的证明步骤与验证的证明序列平均协议率。
结果分析 表1展示了自我一致性过滤在不同定理难度级别上实现的准确性改进。我们观察到,应用自我一致性使证明有效性平均提高了 7.3%7.3 \%7.3%,在复杂定理证明任务中获得了显著收益。
- 逐步协议得分(SAS):生成的证明步骤与验证的证明序列平均协议率。
表1. 自我一致性对证明有效性和逐步协议得分(SAS)的影响。更高值表示更好的性能。
| 定理难度 | 证明有效性(%) | SAS(%) |
|---|---|---|
| 简单(无SC) | 72.1 | 65.4 |
| 简单(SC) | 79.5 | 71.8 |
| 中等(无SC) | 65.4 | 59.2 |
| 中等(SC) | 71.8 | 64.5 |
| 困难(无SC) | 58.3 | 52.1 |
| 困难(SC) | 64.2 | 58.0 |
图1可视化了在不同定理难度级别上证明准确性的改进。
4.2 符号推理中的自我一致性(RQ2)
为了研究自我一致性如何改善符号推理,我们分析了在应用自我一致性过滤前后代数转换和逻辑表达式的效果。主要评估指标包括:
- 表达式等价性(EE %):生成的符号表达式在语义上等价于真实值的比例。
-
- 树相似性指数(TSI):采样符号表达式之间的结构相似性度量。
结果分析 表2报告了符号转换准确性的改进。我们观察到,自我一致性过滤显著增强了表达式等价性和结构一致性,涵盖了不同类别的符号转换。
- 树相似性指数(TSI):采样符号表达式之间的结构相似性度量。
表2. 自我一致性对符号推理性能的影响。更高值表示更好的性能。
| 符号类别 | 表达式等价性(EE %) | 树相似性指数(TSI) |
|---|---|---|
| 简化(无SC) | 68.0 | 0.72 |
| 简化(SC) | 76.0 | 0.79 |
| 方程求解(无SC) | 62.0 | 0.65 |
| 方程求解(SC) | 71.0 | 0.71 |
| 分解(无SC) | 57.0 | 0.60 |
| 分解(SC) | 66.0 | 0.67 |
图2展示了表达式等价性和结构一致性的改进。
4.3 数值推理中的自我一致性(RQ3)
为了分析自我一致性对数值推理的影响,我们评估了LLM生成的数值输出在不同数学问题类型中的一致性和稳定性。主要评估指标包括:
-
方差减少(VR):应用自我一致性后采样数值输出方差的减少。
-
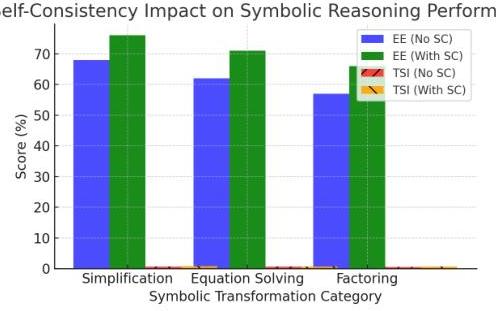
图2. 自我一致性提高了不同符号转换类别中的表达式等价性(EE)和树相似性指数(TSI)。 -
阈值一致性(TC %):数值响应落在预定义容差范围内的比例。
-
结果分析 表3报告了数值稳定性的改进。我们观察到,在高精度计算中,方差显著减少,同时所有评估模型的阈值一致性一致提高。
表3. 自我一致性对数值稳定性的影响。更低的方差和更高的TC表示更好的性能。
| 数值任务 | 方差减少(VR) | 阈值一致性(TC %) |
|---|---|---|
| 算术(无SC) | 0.012 | 76.0 |
| 算术(SC) | 0.007 | 85.0 |
| 代数(无SC) | 0.010 | 72.0 |
| 代数(SC) | 0.005 | 80.0 |
| 微积分(无SC) | 0.008 | 68.0 |
| 微积分(SC) | 0.004 | 75.0 |
图3可视化了阈值一致性和方差减少的改进。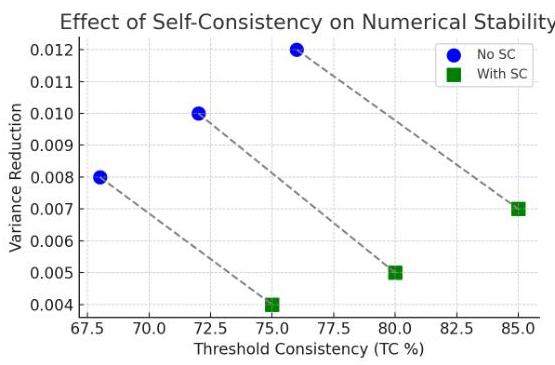
图3. 自我一致性通过增加阈值一致性(TC)和减少方差来提高数值推理的稳定性。
4.4 自我一致性与传统准确率指标的相关性(RQ4)
为了考察自我一致性(SC)与传统准确率指标之间的关系,
我们分析了作为SC深度函数的准确率改进,并将其与标准评估方法进行比较。具体来说,我们关注以下内容:
- 准确率(%):不同问题解决任务中正确答案的百分比。
-
- 推理成本(每样本思考令牌数):每样本生成的令牌数,衡量计算开销。
结果分析 表4展示了关于训练序列长度的消融研究结果,突出显示了准确率和推理成本之间的权衡。我们观察到,增加自我一致性深度显著提升了准确率,同时保持了高效的令牌预算。
- 推理成本(每样本思考令牌数):每样本生成的令牌数,衡量计算开销。
表4. 自我一致性对准确率和推理成本的影响。更高的准确率和更少的思考令牌表示更好的性能。
| 数据集 | 无SC(准确率 / 令牌数) | 有SC(准确率 / 令牌数) |
|---|---|---|
| AIME24 | 30.0%/2072130.0 \% / 2072130.0%/20721 | 50.0%/698450.0 \% / 698450.0%/6984 |
| MATH500 | 90.0%/532490.0 \% / 532490.0%/5324 | 91.0%/326891.0 \% / 326891.0%/3268 |
| GPQA | 52.5%/684152.5 \% / 684152.5%/6841 | 53.0%/356853.0 \% / 356853.0%/3568 |
图4可视化了跨数据集的准确率增益和推理成本减少之间的权衡。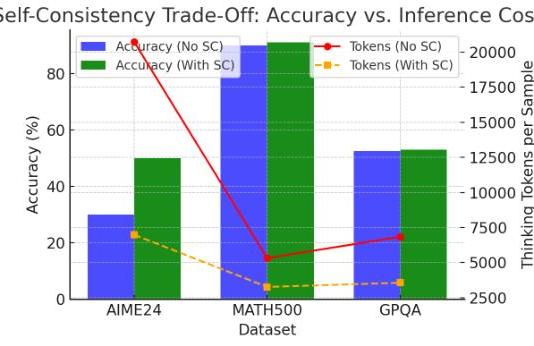
图4. 自我一致性提高了准确率同时减少了推理成本。跨数据集显示了准确率增益(条形图)和生成令牌减少(线条)。
5 结论
本文介绍了一种结构化的自我一致性框架,通过在中间步骤和最终输出中强制执行逻辑连贯性来改进大语言模型(LLMs)中的数学推理。我们的实证评估表明,自我一致性显著增强了定理证明、符号操作和数值计算,同时减少了幻觉。此外,我们分析了计算权衡,表明自我一致性可以在不过度增加推理成本的情况下提高准确性。这些发现表明,自我一致性是一种有前景的方法,可以增强LLMs中的数学可靠性,未来的研究可以探索自适应自我一致性策略、与外部验证机制的集成以及优化推理效率。
参考文献
Zachary Ankner, Mansheej Paul, Brandon Cui, Jonathan D. Chang, and Prithviraj Ammanabrolu. 2024. Critique-out-loud reward models. Preprint, arXiv:2408.11791.
Amos Azaria and Tom Mitchell. 2023. The internal state of an llm knows when it’s lying. In The 2023 Conference on Empirical Methods in Natural Language Processing.
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, and 1 others. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862.
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V. Le, Christopher Ré, and Azalia Mirhoseini. 2024. Large language monkeys: Scaling inference compute with repeated sampling. Preprint, arXiv:2407.21787.
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. 2023. Discovering latent knowledge in language models without supervision. In The Eleventh International Conference on Learning Representations.
Xinyun Chen, Renat Aksitov, Uri Alon, Jie Ren, Kefan Xiao, Pengcheng Yin, Sushant Prakash, Charles Sutton, Xuezhi Wang, and Denny Zhou. 2023. Universal self-consistency for large language model generation. arXiv preprint arXiv: 2311.17311.
Yung-Sung Chuang, Linlu Qiu, Cheng-Yu Hsieh, Ranjay Krishna, Yoon Kim, 和 James Glass. 2024a. 回顾镜:仅使用注意力图检测和减轻大语言模型中的上下文幻觉。arXiv preprint arXiv:2407.07071。Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James R Glass, 和 Pengcheng He. 2024b. DoLa:通过对比层进行解码以提高大语言模型的事实性。在国际学习表示会议中。
Shrey Desai 和 Greg Durrett. 2020. 预训练变压器的校准。在2020年经验方法自然语言处理会议(EMNLP)论文集,第295-302页。计算语言学协会。
Jinhao Duan, Hao Cheng, Shiqi Wang, Alex Zavalny, Chenan Wang, Renjing Xu, Bhavya Kailkhura, 和 Kaidi Xu. 2024. 将注意力转移到相关性:迈向自由形式大语言模型的预测不确定性量化。在第62届年度计算语言学协会会议(第一卷:长篇论文)论文集中,第5050-5063页。计算语言学协会。
Mohamed Elaraby, Mengyin Lu, Jacob Dunn, Xueying Zhang, Yu Wang, Shizhu Liu, Pingchuan Tian, Yuping Wang, 和 Yuxuan Wang. 2023. 光环:开源弱大语言模型中幻觉的估计与减少。arXiv preprint arXiv:2308.11764。
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, 和 Yarin Gal. 2024. 使用语义熵检测大语言模型中的幻觉。Nature, 630(8017):625-630。
Taisiya Glushkova, Chrysoula Zerva, Ricardo Rei, 和 André F. T. Martins. 2021. 不确定性感知的机器翻译评估。在计算语言学协会发现:2021年经验方法自然语言处理会议论文集,第3920-3938页。计算语言学协会。
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, 和 Maosong Sun. 2024. 奥林匹克基准:通过奥林匹克级别的双模态科学问题促进AGI的具有挑战性的基准。预印本,arXiv:2402.14008。
Baizhou Huang, Shuai Lu, Weizhu Chen, Xiaojun Wan, 和 Nan Duan. 2023a. 通过多视角自我一致性增强代码生成中的大型语言模型。arXiv preprint arXiv:2309.17272。
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, 和其他作者。2023b. 大型语言模型中的幻觉综述:原则、分类、挑战和开放问题。arXiv preprint arXiv:2311.05232。
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, 和 Ion Stoica. 2024. Livecodebench:整体且无污染的大规模语言模型代码评估。预印本,arXiv:2403.07974。
Zhengbao Jiang, Jun Araki, Haibo Ding, 和 Graham Neubig. 2021. 我们如何知道语言模型知道?关于语言模型在问答中的校准。计算语言学协会交易,9:962-977。
Craig Kapfer, Kurt Stine, Balasubramanian Narasimhan, Christopher Mentzel, 和 Emmanuel Candes. 2025. Marlowe:斯坦福大学基于GPU的计算工具。
Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth Malik, 和 Yarin Gal. 2024. 语义熵探针:LLM中鲁棒且廉价的幻觉检测。arXiv preprint arXiv:2406.15927。
Ariel Lee, Cole Hunter, 和 Nataniel Ruiz. 2023. 平头鸭:快速、便宜且强大的LLM精炼方法。在NeurIPS 2023研讨会关于指令调优和指令跟随中。
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, 和 Martin Wattenberg. 2024. 推理时间干预:从语言模型中引出真实答案。神经信息处理系统进展,36。
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, 和其他作者。2022. 竞赛级别代码生成与AlphaCode。Science, 378(6624):1092-1097。
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, 和 Karl Cobbe. 2023. 让我们逐步验证。预印本,arXiv:2305.20050。
Potsawee Manakul, Adian Liusie, 和 Mark Gales. 2023. SelfCheckGPT:零资源黑箱生成式大语言模型幻觉检测。在计算语言学经验方法会议论文集,第9004-9017页。计算语言学协会。
Niels Mündler, Jingxuan He, Slobodan Jenko, 和 Martin Vechev. 2024. 大语言模型的自相矛盾幻觉:评估、检测和缓解。在国际学习表示会议中。
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, 和其他作者。2022. 使用人类反馈训练语言模型遵循指令。神经信息处理系统进展。
Freda Shi, Daniel Fried, Marjan Ghazvininejad, Luke Zettlemoyer, 和 Sida I. Wang. 2022. 带有执行的自然语言到代码翻译。在计算语言学经验方法会议论文集,第3533-3546页。计算语言学协会。
Adi Simhi, Jonathan Herzig, Idan Szpektor, 和 Yonatan Belinkov. 2024. 构建基准和干预措施以对抗LLM中的幻觉。arXiv preprint arXiv:2404.09971。
Raghuveer Thirukovalluru, Yukun Huang, 和 Bhawan Dhingra. 2024. 原子级自我一致性以实现更好的长篇生成。在计算语言学经验方法会议论文集,第12681-12694页。
Ante Wang, Linfeng Song, Baolin Peng, Lifeng Jin, Ye Tian, Haitao Mi, Jinsong Su, 和 Dong Yu. 2024a. 通过细粒度自我认可改进LLM生成。在计算语言学协会发现:ACL论文集,第8424-8436页。计算语言学协会。
Peiyi Wang, Lei Li, Zhihong Shao, R. X. Xu, Damai Dai, Yifei Li, Deli Chen, Y. Wu, 和 Zhifang Sui. 2024b. Math-shepherd:无需人工注释验证和强化LLM逐步推理。预印本,arXiv:2312.08935。
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, 和 Denny Zhou. 2023. 自我一致性提高了语言模型链式思维推理能力。在国际学习表示会议中。
Zhilin Wang, Yi Dong, Olivier Delalleau, Jiaqi Zeng, Gerald Shen, Daniel Egert, Jimmy J. Zhang, Makesh Narsimhan Sreedhar, 和 Oleksii Kuchaiev. 2024c. Helpsteer2:用于训练顶级奖励模型的开源数据集。预印本,arXiv:2406.08673。
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, 和 Yiming Yang. 2024. 推理缩放定律:对语言模型解决问题时计算最优推理的经验分析。预印本,arXiv:2408.00724。
Huajian Xin, Daya Guo, Zhihong Shao, Zhizhou Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, 和 Xiaodan Liang. 2024. Deepseek-prover:通过大规模合成数据推进定理证明中的LLM。预印本,arXiv:2405.14333。
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, 和 Bryan Hooi. 2024. LLMs能否表达它们的不确定性?对LLMs置信度提取的实证评估。在国际学习表示会议第十二届上。
Zhangyue Yin, Qiushi Sun, Qipeng Guo, Jiawen Wu, Xipeng Qiu, 和 Xuan-Jing Huang. 2023. 大语言模型是否知道自己不知道的事情?在计算语言学协会发现:ACL 2023中。
Shaolei Zhang, Tian Yu, 和 Yang Feng. 2024. TruthX:通过在真实空间编辑大语言模型来减轻幻觉。arXiv preprint arXiv:2402.17811。
Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, 和 Nan Duan. 2023. Ageval:以人为中心的基础模型评估基准。预印本,arXiv:2304.06364。
Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, 和其他作者。2024. Lima:少即是多的对齐方式。神经信息处理系统进展。
A 相关工作
A. 1 大语言模型中的幻觉
大语言模型(LLMs)在各种推理任务中表现出显著的能力,但它们容易产生幻觉——即生成看似合理但偏离事实正确性的陈述——这仍然是一个重大挑战(Yin等人,2023;Xiong等人,2024;Huang等人,2023b;Bai等人,2022)。幻觉可以表现为事实不准确、逻辑不一致或自相矛盾的推理链,这在数学推理中尤为成问题,因为正确性是二元的,错误会在多步推导中传播(Kapfer等人,2025;Wang等人,2024b)。
为了减轻幻觉,最近的研究探讨了检测和预防策略。一些方法分析内部模型表示,例如隐藏状态(Azaria和Mitchell,2023;Burns等人,2023)或注意力矩阵(Simhi等人,2024;Zhang等人,2024),以识别不一致性。其他方法利用基于熵的不确定性估计来量化幻觉的可能性(Farquhar等人,2024;Kossen等人,2024)。此外,缓解努力集中在用高质量的指令数据集微调LLMs(Lee等人,2023;Zhou等人,2024;Elaraby等人,2023)以及通过人类反馈进行强化学习(RLHF)(Ouyang等人,2022;Bai等人,2022)。尽管这些方法提高了事实准确性,但它们往往无法在多样化的推理任务中普遍适用,特别是在需要逐步逻辑连贯性的数学问题解决中。
A. 2 改善LLMs事实性的自我一致性
自我一致性(SC)已作为一项有效技术出现,通过比较多个独立生成的响应来提高事实可靠性(Manakul等人,2023;Farquhar等人,2024;Mündler等人,2024)。先前的研究已经证明了其在幻觉检测(Burns等人,2023;Azaria和Mitchell,2023)和不确定性量化(Desai和Durrett,2020;Jiang等人,2021;Glushkova等人,2021;Duan等人,2024)方面的有效性。通过利用SC,模型可以识别输出中的不一致性并过滤掉不太可靠的响应,从而提高事实准确性(Wang等人,2023;Shi等人,2022;Chen等人,2023)。
尽管取得了这些进展,现有的SC方法对任务格式施加了严格限制,主要集中在精确匹配答案验证上(Li等人,2022;Shi等人,2022;Wang等人,2023;Huang等人,2023a)。为了克服这一限制,近期工作通过响应聚类(Thirukovalluru等人,2024)、迭代细化(Mündler等人,2024)和语句级一致性验证(Chen等人,2023;Wang等人,2024a)将SC适应于开放式任务。虽然这些方法增强了SC的适用性,但尚未系统地应用于数学推理,其中逐步验证对于定理证明和符号转换至关重要。
A. 3 数学推理中的自我一致性
由于依赖多步逻辑推理,包括定理证明、符号操作和数值问题解决在内的数学推理任务对LLMs提出了独特的挑战(Xin等人,2024;Ankner等人,2024)。传统的基于SC的方法专注于最终答案验证,但未能强制中间步骤的一致性,导致逻辑不健全的证明(Wang等人,2024b)。这种局限性在需要符号推理的任务中尤为明显,其中中间变换中的小不一致性可能导致不正确的结论(Kapfer等人,2025)。
为了解决这一差距,研究人员探索了诸如过程奖励建模(Lightman等人,2023)、基于树的搜索(Wu等人,2024)和多数投票(Brown等人,2024)等技术。这些方法旨在通过优化推理路径来提高LLM的一致性,但通常会引入大量的计算开销。一个关键的研究方向是在增强SC准确性的同时平衡推理效率,确保正确性的改进不会以不切实际的计算成本为代价(He等人,2024;Jain等人,2024)。
A. 4 缓解幻觉的解码策略
除了自我一致性外,还提出了几种基于解码的策略来缓解LLMs中的幻觉。对比解码技术调整logit激活,以放大事实知识保留同时抑制误导性输出(Burns等人,2023;Chuang等人,2024b)。其他方法,如推理时干预(ITI),在解码过程中操纵注意力头,以引导模型生成更可靠的内容(Li等人,2024)。回顾机制分析先前上下文以动态检测和纠正不一致性(Chuang等人,2024a)。
虽然这些解码方法提高了事实性,但它们通常需要模型修改或大量计算资源,限制了其在现实世界应用中的可扩展性。相比之下,我们的方法利用自我一致性而无需对模型架构进行根本改变,使其更能适应各种数学推理任务。
参考论文:https://arxiv.org/pdf/2504.09440

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 24
24 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)