小红书 hi lab 开源最强多模态大模型 dots.vlm1,性能对标闭源 Gemini 2.5 Pro和Seed-VL1.5
关注公众号,发现CV技术之美
2025 年8月,小红书 hi lab 发布并开源了首个自研多模态大模型 dots.vlm1。该模型基于 12 亿参数的 NaViT 视觉编码器和 DeepSeek V3 大语言模型,完全从零训练。dots.vlm1 在主流多模态视觉理解与推理能力上,已接近闭源 SoTA(State-of-the-Art)大型模型 Gemini 2.5 Pro 和 Seed-VL1.5。其文本理解能力亦与主流开源大模型相当,充分展现了开源多模态模型的最新性能上限。本文详细介绍模型架构、训练流程、评测结果、技术创新点,并展望未来优化方向。
1. 模型亮点与创新
1.1 NaViT 视觉编码器 —— 原生自研,支持动态分辨率
-
完全从零训练:非基于成熟视觉编码器微调,而是从头训练,极大提升视觉感知能力上限。
-
动态分辨率支持:提升对多样真实图像场景的适应性。
-
双重视觉监督:结合纯视觉(如纯图片)与文本视觉(如图片+描述),充分逼近复杂视觉场景的泛化能力。
-
多样训练数据:纳入广泛结构化图片(表格、图表、公式、文档、OCR等),提升非典型场景(如长尾识别、文档解析)的表现。
1.2 多模态训练数据 —— 规模巨大,清洗精细
-
强多样性合成数据:合成和收集表格/Chart/文档/Graphics 等图片及丰富的描述(Alt Text/Dense Caption/Grounding)。
-
自主重写多模态网页数据:通过自研 VLM 进行数据清洗与重写,显著提升图文对齐和数据质量。
-
PDF 图文增强训练:自研 dots.ocr 将 PDF 文档结构化为图文混合数据,支持遮挡预测,提高文档理解。
1.3 前沿预训练与精细化调优流程
-
分阶段全流程训练:视觉编码器预训练—大规模 VLM 预训练—多样 SFT 后训练。
-
视觉推理能力突出:专注于 MMMU、MathVision、OCR Reasoning 等多项多模态基准测试,接近 Gemini 2.5 Pro/Seed-VL1.5 闭源领先模型水平。
-
文本推理能力主流:在数学、代码与复杂推理上与主流 LLM 持平,部分任务略有提升空间。
2. 性能评测与样例分析
2.1 评测指标与结果
在主要国际多模态评测集(如 MMMU、MathVision、OCR Reasoning 等)中,dots.vlm1 的整体表现已接近当前领先的 Gemini 2.5 Pro 与 Seed-VL1.5。相关核心结论如下:
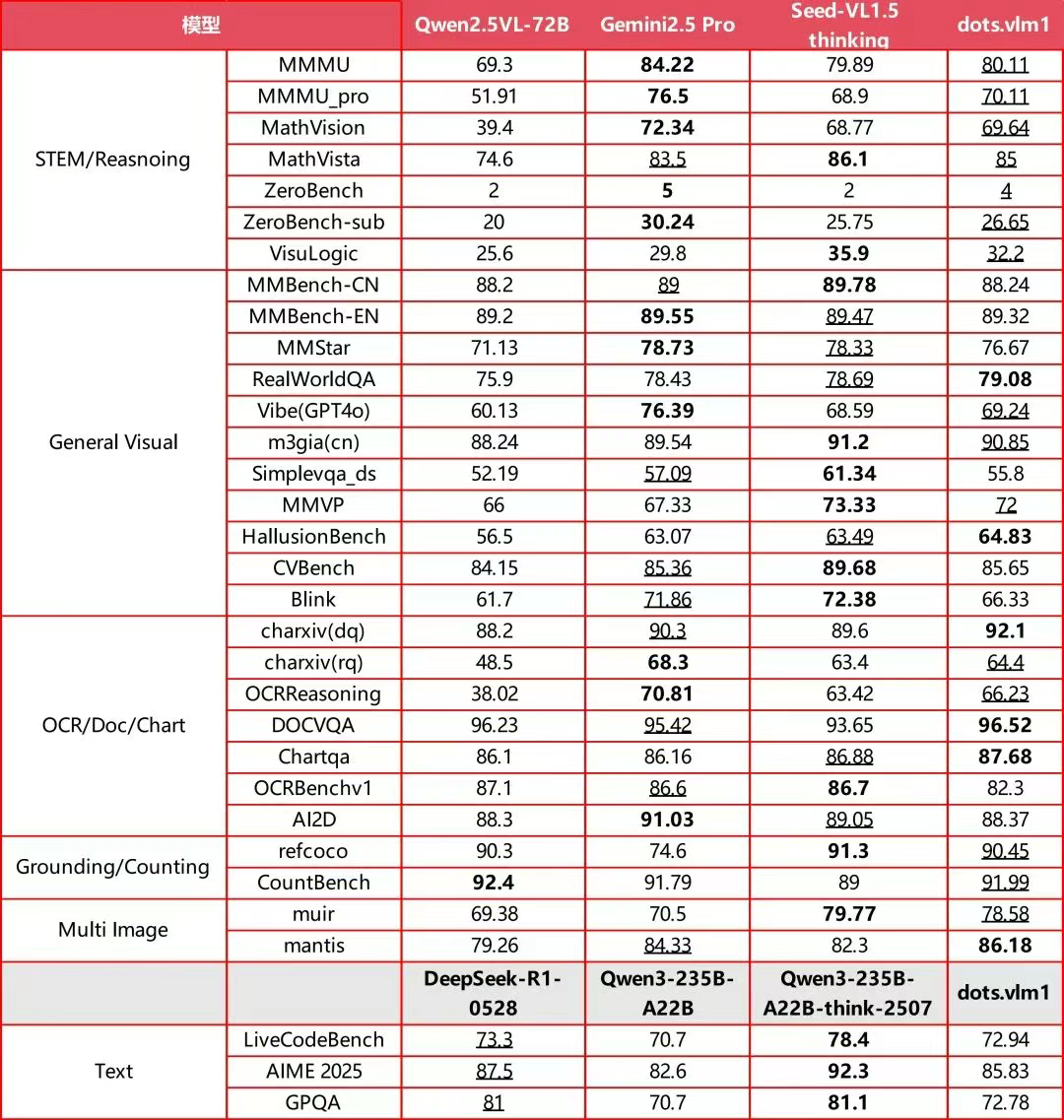
在文本任务(AIME、GPQA、LiveCodeBench 等)上,dots.vlm1 达到了与主流 LLM 相当的水准,具备通用数学推理和代码能力,但极复杂推理仍与 SOTA 闭源模型存在差距。
2.2 应用效果样例
复杂图表推理
dots.vlm1 能对高度复杂的表格、图形、文档图像进行准确识别与逻辑推理,显著提升业务实践能力。
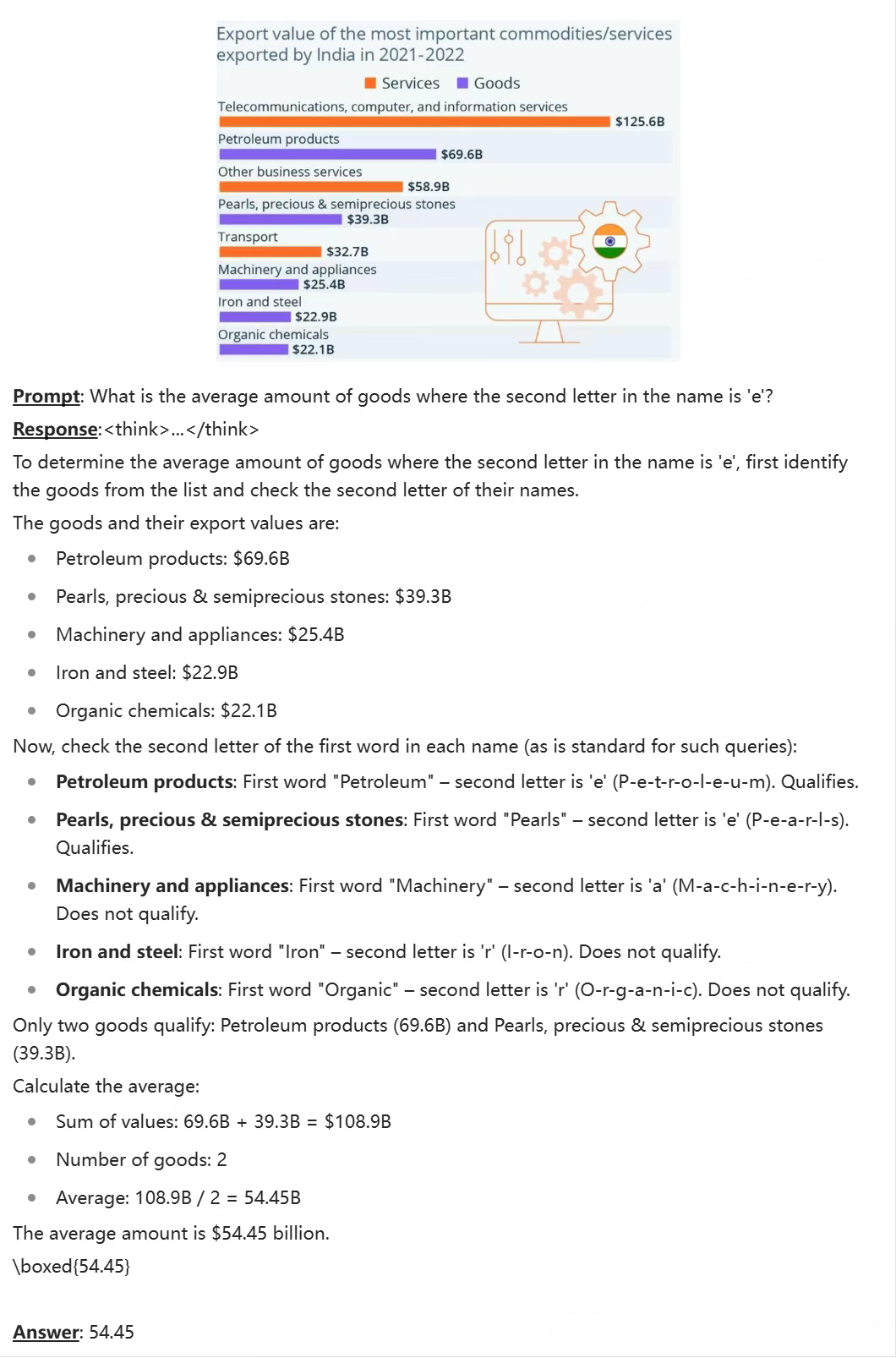


STEM/数学推理
支持复杂多步运算、长图理解、一题多解,完全胜任奥数、STEM 类视觉-文本混合解题任务。



长尾细分场景识别
模型对特殊/非主流领域图片(如OCR/长尾文档图像)表现优异,显著好于传统视觉编码方案。



3. 技术架构与训练流程
3.1 三大核心组件
-
NaViT 视觉编码器(12亿参数):42层 Transformer,采用 RMSNorm、SwiGLU、2D RoPE,原生多分辨率支持。
-
MLP 适配器:高效图文特征融合。
-
DeepSeek V3 MoE LLM:业界主流性能的门控专家型大语言模型。
3.2 三阶段训练流程
-
视觉编码器阶段:随机初始化,先以 224×224 分辨率进行大规模图文感知归一化训练,采用下一 Token 预测/NTP 与下一 Patch 生成/NPG 双重监督。
-
VLM 联合预训练:与 DeepSeek V3 LLM 拼接,接入多源海量多模态数据,大幅提升跨模态能力。
-
后训练微调:多任务多样样例有监督Fine-tuning,进一步优化泛化与稳健性。
3.3 数据管线与多样性设计
-
跨模态互译:图片与文本相互描述与理解,涵盖Alt Text/密集图注/公式/表格/grounding等全谱系视觉场景。
-
跨模态融合:解耦图文依赖,清洗网页/PDF等复杂数据集以强化真实世界多模态理解。
4. 存在不足与未来展望
-
视觉感知:将继续扩大跨模态数据规模和类型,优化视觉编码器神经网络结构。
-
视觉推理:将引入强化学习等前沿算法,提升推理泛化能力,探索更强的推理前置技术。
-
数据与评测闭环:打通更大规模、更丰富的结构化与非结构化多模态数据,围绕真实业务问题持续升级评测体系。
5. 相关链接
-
GitHub Repo: https://github.com/rednote-hilab/dots.vlm1
-
HuggingFace 模型: https://huggingface.co/rednote-hilab/dots.vlm1.inst
-
在线 Demo: https://huggingface.co/spaces/rednote-hilab/dots-vlm1-demo
结论
小红书 hi lab 推出的 dots.vlm1 多模态大模型以全链条自研和开源姿态,综合性能首次对标并逼近 Gemini 2.5 Pro、Seed-VL1.5 等闭源最强大模型,不仅在视觉-文本复杂场景中展现卓越,文本编码推理能力也保持主流水平。未来,团队将坚持开源、高质量、持续创新,为国内外多模态大模型生态带来更强推动力。
了解最新 AI 进展,欢迎关注公众号
投稿寻求报道请发邮件:amos@52cv.net

END
欢迎加入「大模型」交流群👇备注:LLM


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 0
0 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)