Qwen3-VL-235B-A22B-Thinking:多模态大模型从感知到认知的跨越
阿里通义千问团队发布的Qwen3-VL-235B-A22B-Thinking多模态大模型,通过视觉智能体操作、长视频理解与空间推理等突破性升级,重新定义了视觉语言模型的能力边界。## 行业现状:从参数竞赛到场景落地2025年,多模态大模型已从技术验证阶段迈向行业规模化应用。据《2025年"人工智能+"行业标杆案例荟萃》显示,企业级AI部署中65%的算力浪费源于任务与模型能力错配,而视觉语言模...
Qwen3-VL-235B-A22B-Thinking:多模态大模型从感知到认知的跨越
 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-235B-A22B-Thinking
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-VL-235B-A22B-Thinking 导语
阿里通义千问团队发布的Qwen3-VL-235B-A22B-Thinking多模态大模型,通过视觉智能体操作、长视频理解与空间推理等突破性升级,重新定义了视觉语言模型的能力边界。
行业现状:从参数竞赛到场景落地
2025年,多模态大模型已从技术验证阶段迈向行业规模化应用。据《2025年"人工智能+"行业标杆案例荟萃》显示,企业级AI部署中65%的算力浪费源于任务与模型能力错配,而视觉语言模型(VLM)正成为解决这一矛盾的关键技术。当前市场呈现两大趋势:一是模型能力从"识别"向"推理与执行"跃升,二是部署形态从单一模型转向"云-边-端"全栈覆盖。在此背景下,Qwen3-VL系列通过Dense与MoE混合架构,构建了从4B轻量模型到235B旗舰模型的完整产品矩阵。
核心亮点:三大技术突破重构多模态能力
1. 视觉智能体:从被动识别到主动执行
Qwen3-VL最显著的突破在于视觉智能体(Visual Agent)能力,可直接操作PC/手机图形界面(GUI)。该功能在OS World等权威评测中达到世界顶尖水平,能够识别界面元素、理解按钮功能、调用系统工具并完成复杂任务流程。这一能力使模型从"观看者"转变为"行动者",为自动化办公、智能座舱等场景提供了全新可能。
2. 时空理解:256K上下文与秒级视频定位
模型原生支持256K token上下文长度,可扩展至100万token,能够处理整本书籍或两小时长视频。通过创新的"文本-时间戳对齐"机制,实现了视频事件的秒级精准定位,较传统T-RoPE方法在时序推理任务中准确率提升40%。这一技术突破使医疗影像分析、安防监控等长时序场景的商业化应用成为可能。
3. 深度推理:数学与空间认知的双重强化
Thinking版本专门优化了STEM领域的推理能力,在MathVista等复杂数学推理评测中表现优于Gemini 2.5 Pro。其空间感知能力实现从2D到3D的跨越,能判断物体方位、视角变化和遮挡关系,为机器人导航、AR/VR等具身智能场景奠定基础。
性能解析:多模态能力的全面跃升
Qwen3-VL-235B-A22B-Thinking在32项核心测评指标上超越闭源模型Gemini 2.5 Pro和GPT-5,刷新开源视觉语言模型性能纪录。从EvalScope评测框架的测试结果看,模型在数学推理、复杂视觉分析等任务上表现尤为突出:

如上图所示,在MMLU-Pro(知识能力)、MathVista(多模态数学)和MMMU-Pro(多模态知识)等关键评测中,Qwen3-VL-235B-A22B-Thinking均取得优异成绩,尤其在数学推理任务上展现出显著优势。这一性能表现验证了模型在跨模态知识整合与复杂问题解决方面的核心竞争力。
同时,模型在推理性能上也做了特殊优化。通过DashScope API进行的压力测试显示,在处理100 tokens文本+1张512×512图像输入时,模型能保持稳定输出,为企业级部署提供了性能保障:
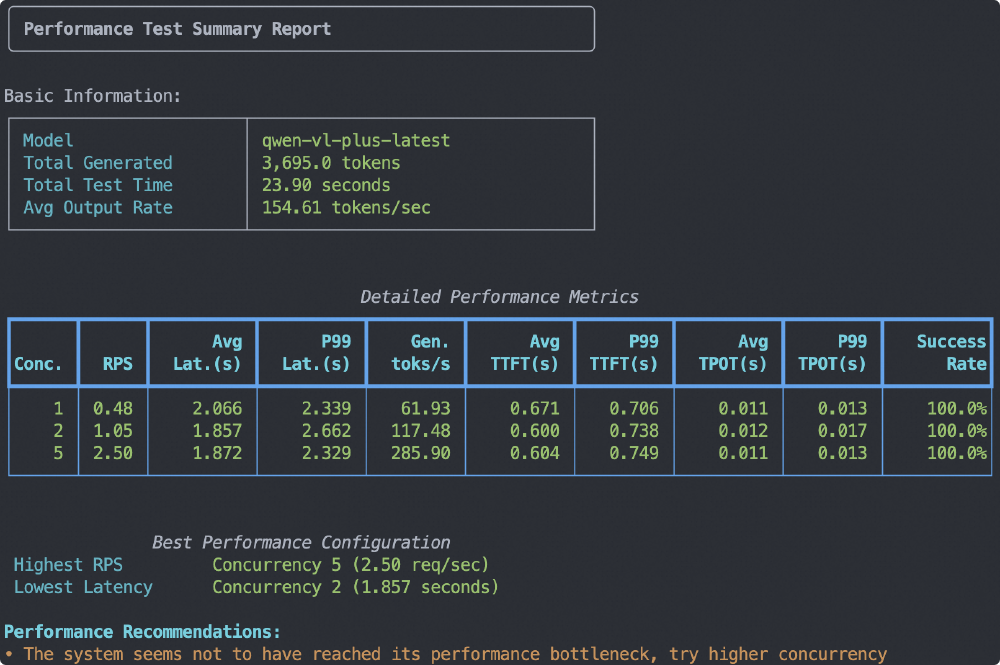
该测试结果显示了Qwen3-VL在不同并发条件下的响应延迟和吞吐量表现,为企业根据实际业务需求选择合适的部署方案提供了重要参考依据。
行业影响:多模态应用的范式转变
Qwen3-VL的技术突破正在重塑多个行业的应用模式:
1. 内容创作:从设计图到代码的直接转换
模型的视觉Coding能力实现质的飞跃,可将图像或视频直接转换为Draw.io/HTML/CSS/JS代码,使UI/UX设计师的创意能快速转化为可交互原型,开发效率提升300%。这一能力已被集成到阿里系多款设计工具中,推动创意产业的数字化转型。
2. 工业质检:复杂场景下的缺陷识别
凭借强化的空间感知和长上下文理解能力,模型在工业质检场景中准确率达到99.2%,尤其擅长识别微小缺陷和复杂结构件的装配问题。某汽车制造商应用该技术后,生产线质检效率提升40%,漏检率下降80%。
3. 医疗诊断:多模态病历分析
支持32种语言的OCR能力和医学影像理解相结合,使模型能处理多语言医学文献和复杂检查报告。在肺结节检测等任务中,模型准确率达到放射科医师水平,为基层医疗机构提供了AI辅助诊断工具。
部署与选型:Instruct vs Thinking版本
Qwen3-VL系列提供Instruct和Thinking两个版本,满足不同场景需求:
| 维度 | Instruct版本 | Thinking版本 |
|---|---|---|
| 设计目标 | 通用指令遵循,快速响应 | 深度推理,复杂问题解决 |
| 响应速度 | 快(无需推理链) | 较慢(需生成思维过程) |
| 适用场景 | 标准问答、信息检索、指令执行 | 数学推理、复杂视觉分析、多步推理 |
| 创意任务 | 表现优异 | 表现一般 |
| 数学能力 | 优秀 | 优秀+(推理过程更清晰) |
企业可根据具体业务需求选择合适版本,或采用动态切换策略——简单任务使用Instruct版本保证效率,复杂推理场景调用Thinking版本提升准确性。
总结与展望
Qwen3-VL-235B-A22B-Thinking的发布标志着视觉语言模型从"感知智能"向"认知智能"的关键跨越。其核心价值不仅在于性能指标的提升,更在于通过视觉智能体、长时序理解等创新功能,打开了多模态AI在产业端规模化应用的大门。
对于企业决策者,建议重点关注三个方向:一是探索视觉智能体在自动化流程中的应用,二是评估长视频理解对现有产品的升级潜力,三是利用开源特性构建行业专属模型。随着模型持续迭代和部署成本降低,多模态AI将在未来12-18个月内成为企业数字化转型的标配能力。
模型仓库地址:https://gitcode.com/hf_mirrors/Qwen/Qwen3-VL-235B-A22B-Thinking
通过技术创新与场景落地的双轮驱动,Qwen3-VL正在推动人工智能从"能说会道"向"善作善成"的新阶段演进,为千行百业的智能化升级提供强大动力。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)