多模态大模型垂直微调实战:基于Qwen3-VL-4B-Thinking与 Llama Factory的完整指南
多模态大模型垂直微调实战:基于 Qwen3-VL-4B-Thinking 与 Llama Factory 的完整指南
·
文章目录
一 多模态大模型
- 多模态大模型(Multimodal Large Language Model, MLLM)能理解并融合两种或多种模态的信息。
- 模态指信息的表现形式或感知方式。信息类型包括:文字、图像、声音、视频等。
1.1 多模态垂直微调
- 通用多模态模型追求覆盖广泛,通用理解能力,因此通用多模态模型具备基本的视觉理解能力,但对特定领域的专业格式和语义缺乏精确认知。
- 多模态模型微调不仅有助于模型看懂图像,还能帮助模型理解图像的语义逻辑。多模态模型视觉编码器负责看,语言模型负责理解和输出,多模态模型微调的目标是使模型在特定领域语境下正确理解图中的内容。
- 多模态模型微调能够提升模型三个方面的能力:
- 语义对齐:让模型理解领域专属符号的实际含义。 例:医学报告中的"↑"表示指标偏高,而非箭头符号。
- 结构化理解:让模型掌握数据的层级关系与布局规律,直接输出结构化结果(如JSON)。例:识别财务报表中"利润总额"与其子项的从属关系。
- 视觉稳健性:通过接触真实场景样本(模糊、倾斜、印章干扰等),提升对低质量图像的识别稳定性。
- 核心逻辑:从"看懂文字"到"理解业务含义",再到"应对真实环境"。
1.2 微调的意义
| 维度 | 核心收益 | 具体表现 |
|---|---|---|
| 输出标准化 | 稳定可控的结构化输出 | 摆脱生成式模型的随机性,持续输出 JSON/表格等标准格式 |
| 系统简化 | 降低工程维护成本 | 替代传统正则匹配与版面解析规则,减少硬编码逻辑 |
| 泛化适配 | 增强多版本兼容能力 | 单模型覆盖同类文件的多版式变体,弱化模板依赖 |
| 数据治理 | 提升全流程数据质量 | 作为视觉识别入口,为下游提供格式统一、字段规范的数据 |
| 生态集成 | 无缝衔接业务系统 | 直接对接知识库构建、RAG 检索、数据分析等应用场景 |
本质转变:从"人工规则驱动"转向"模型能力驱动",将文档理解的复杂性内化为模型参数,而非外化为工程代码。
二 多模态基座模型选择
- 多模态模型选择需要考虑的前置条件为输入的数据模态、目标任务、本地化部署需求。
2.1 多模态模型对比表
| 模型 | 模态支持 | 中文能力 | 可私有化 | 代表优势 | 不适合的场景 |
|---|---|---|---|---|---|
| GPT-4o / GPT-4.5 | 文本、图片、语音、视频、实时交互 | 强(但偏英文) | 否 | 全模态理解、推理最强、原生多模态融合、实时语音对话 | 不能本地化、成本高、数据隐私敏感场景 |
| Gemini 2.0 Pro / Flash / Ultra | 文本、图片、音频、视频、代码 | 中等偏强 | 否 | 超长上下文(200万token)、视频摘要顶尖、Google生态集成 | 中文OCR仍有短板、不可控部署 |
| Claude 3.5 Sonnet / Opus (Anthropic) | 文本、图片、PDF、图表 | 中等 | 部分✅ | 代码理解最强、文档分析精准、安全性高、长上下文 | 无原生视频/音频理解、中文弱于国产模型 |
| Qwen2.5-VL / Qwen3-VL (阿里) | 文本、图片、图表、文档、视频 | 极强 | ✅ | 中文图文理解顶尖、开源可商用、RAG集成优秀、端侧优化 | 复杂推理略逊于GPT-4o、英文场景稍弱 |
| DeepSeek-VL2 / DeepSeek-OCR | 图片→文本、文档解析、图表 | 强 | ✅ | OCR精度极高、结构化输出、成本极低、数学公式识别好 | 通用视觉理解有限、视频支持弱 |
| InternVL2.5 / InternVL3 (商汤/上海AI Lab) | 文本、图片、表格、视频 | 强 | ✅ | 中文问答优秀、国产生态完善、开放源码、医疗影像强 | 推理速度较慢、国际生态较弱 |
| Kimi k1.5 / Kimi-VL (月之暗面) | 文本、图片、长文档、视频 | 极强 | 部分✅ | 超长上下文(200万汉字)、中文文档理解顶尖、视频分析 | API成本较高、视频理解深度有限 |
| GLM-4V / GLM-4V-Plus (智谱AI) | 文本、图片、视频、Agent工具 | 强 | ✅ | 中英双语均衡、国产合规、视频理解好、工具调用强 | 复杂推理略逊于顶级闭源模型 |
| Step-1V / Step-2V (阶跃星辰) | 文本、图片、视频 | 强 | 部分✅ | 视频理解能力强、国产创新、长视频分析 | 生态较新、社区资源少、API稳定性待提升 |
| Yi-VL / Yi-Vision (零一万物) | 文本、图片 | 强 | ✅ | 中文语言流畅、稳定、企业级服务 | 生态未成熟、训练资源少、视频支持弱 |
| LLaVA-OneVision / LLaVA-NeXT | 文本、图片、视频 | 一般 | ✅ | 开源框架清晰、易微调、学术研究首选 | 中文弱、文档结构理解差、商业支持少 |
| Pixtral Large / Pixtral 12B (Mistral) | 文本、图片 | 强 | ✅ | 开源性能领先、欧洲合规、多语言支持好 | 中文优化不足、无视频支持 |
| Molmo / Molmo 72B (Ai2) | 文本、图片 | 中等 | ✅ | 完全开源可商用、学术透明度高、 pointing能力独特 | 中文支持弱、生态系统小 |
| Janus-Pro / Janus-Flow (DeepSeek) | 文本、图片生成+理解统一 | 强 | ✅ | 统一架构(理解与生成)、开源、成本低 | 视频不支持、生成质量待提升 |
| Sora (OpenAI) | 文本→视频、图片→视频 | 一般 | 否 | 视频生成质量顶尖、物理模拟真实 | 仅视频生成、无理解能力、中文支持弱 |
2.2 选型建议矩阵
| 应用场景 | 首选模型 | 备选方案 | 关键考量 |
|---|---|---|---|
| 企业级中文文档处理 | Qwen2.5-VL | Kimi k1.5, DeepSeek-OCR | 中文精度、私有化部署、成本 |
| 代码+文档混合场景 | Claude 3.5 Sonnet | GPT-4o, Qwen2.5-VL | 代码理解、长上下文、安全性 |
| 视频内容分析 | Gemini 2.0 Pro | Step-1V, GLM-4V-Plus | 视频时长支持、理解深度 |
| 实时交互/客服 | GPT-4o | Gemini 2.0 Flash, Qwen2.5-VL | 响应速度、多模态融合、成本 |
| 开源可商用 | Qwen2.5-VL | InternVL3, LLaVA-OneVision | 许可证友好度、社区活跃度 |
| 超长文本分析 | Kimi k1.5 | Gemini 2.0 Pro, Claude 3.5 | 上下文长度、中文支持 |
| OCR/文档结构化 | DeepSeek-OCR | Qwen2.5-VL, InternVL3 | 精度、结构化输出、表格识别 |
| 端侧/边缘部署 | Qwen2.5-VL-Mobile | InternVL-Edge, LLaVA-Mobile | 模型大小、推理速度、功耗 |
| 视频生成 | Sora | Runway Gen-3, Pika 1.5 | 生成质量、物理真实性、可控性 |
2.3 微调与部署视角选择
| 需求类型 | 微调重点 | 推荐方式 |
|---|---|---|
| OCR/报表结构化 | 视觉投影层 + 输出格式SFT | LoRA/QLoRA |
| 图表问答 | 跨模态对齐层 + 指令数据 | SFT + 数据增强 |
| 合同/文档问答 | 语言层指令微调 | 轻SFT或DPO |
| 工业检测说明 | 结合CV特征层 | 多任务微调 |
| 视频摘要 | 需专门Video Encoder | 建议API托管 |
- 多模态模型的选型应遵循"场景适配优先"原则,而非单纯追求性能最优:
| 场景特征 | 推荐选型 | 核心考量 |
|---|---|---|
| 通用理解与全模态处理 | GPT-4V / Gemini 系列 | 综合能力领先,适合复杂推理与跨模态任务 |
| 中文文档与结构化提取 | Qwen-VL / DeepSeek-OCR | 中文语义理解精准,OCR与表格解析成熟 |
| 私有化部署与定制化微调 | InternVL / Yi-VL | 开源可控,支持领域适配与长期迭代 |
- 企业选型框架:需综合评估输入数据模态、输出结构化要求及部署约束条件,选择兼具适配性、可控性与可扩展性的技术生态,避免盲目追逐前沿指标而忽视落地可行性。
三 Qwen3-VL-4B-Thinking理解微调(Llama Factory)
3.1 数据集制作
-
完整优化后的数据集已上传到modelscope XFUND-Chinese
-
XFUND:多语言形式理解基准 1.0 zh.train,其中包含众多表格图片,适合进行图表、图片内容提取和整理。
- 使用Easy DataSet工具构建数据集,将图片解压后导入Easy DataSet图片管理模块,并使用qwen3.5-plus模型进行数据集构建。关于项目创建和项目模型的配置过程,请自行探索完成。
- 选择图片,编辑问题模版,填写提问题内容,具体内容如下:
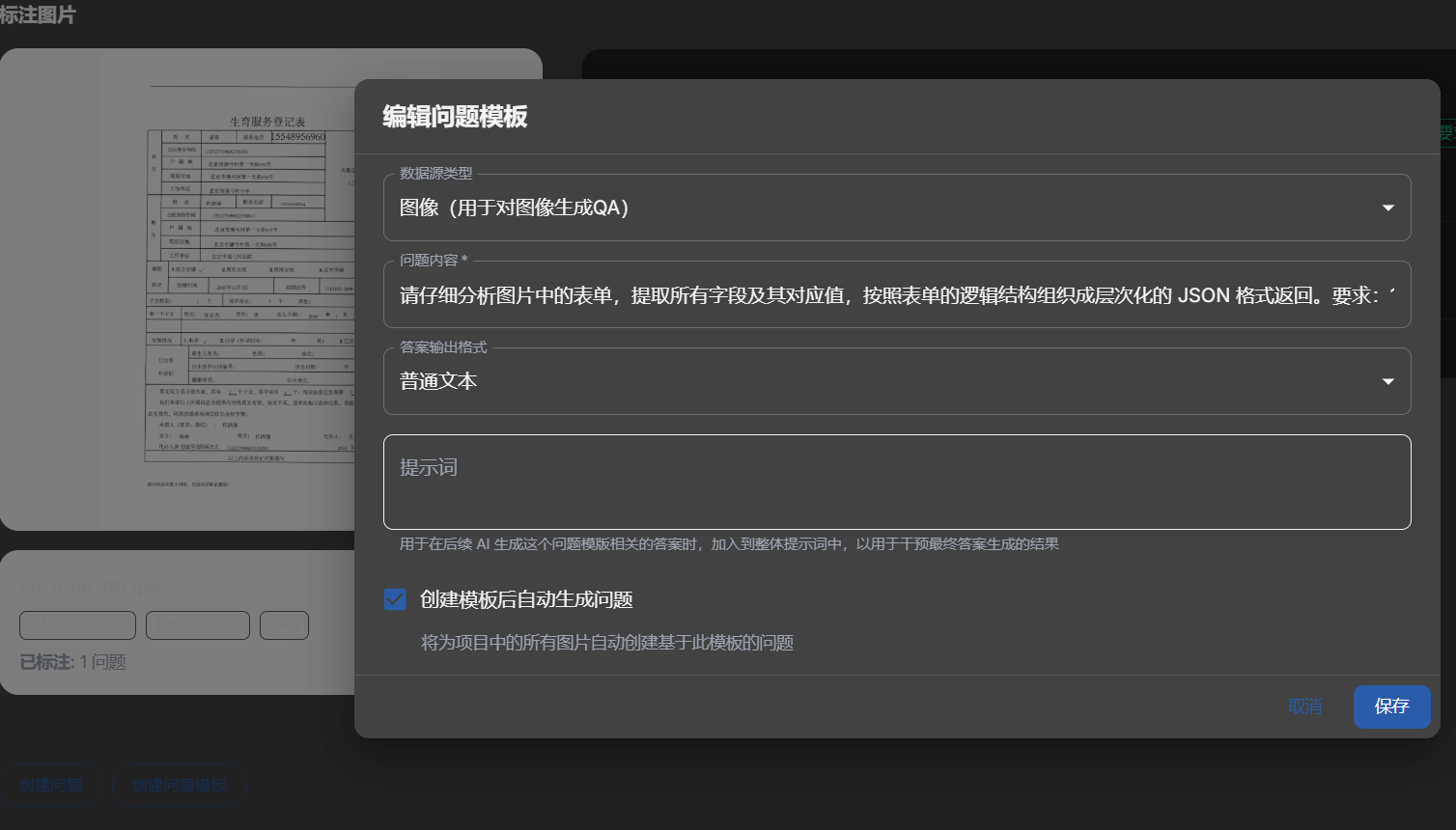
请仔细分析图片中的表单,提取所有字段及其对应值,按照表单的逻辑结构组织成层次化的 JSON 格式返回。要求:1. 识别并提取表单中的所有字段和对应值,包括填写的内容和选择的选项;2. 根据表单的实际结构,将相关字段归类到适当的子对象中;3. 确保键名清晰准确,反映字段的实际含义;4. 生成严格的 JSON 格式,不含任何额外文本;5. 信息提取必须完整、准确,键值对匹配正确。仅返回 JSON 内容。
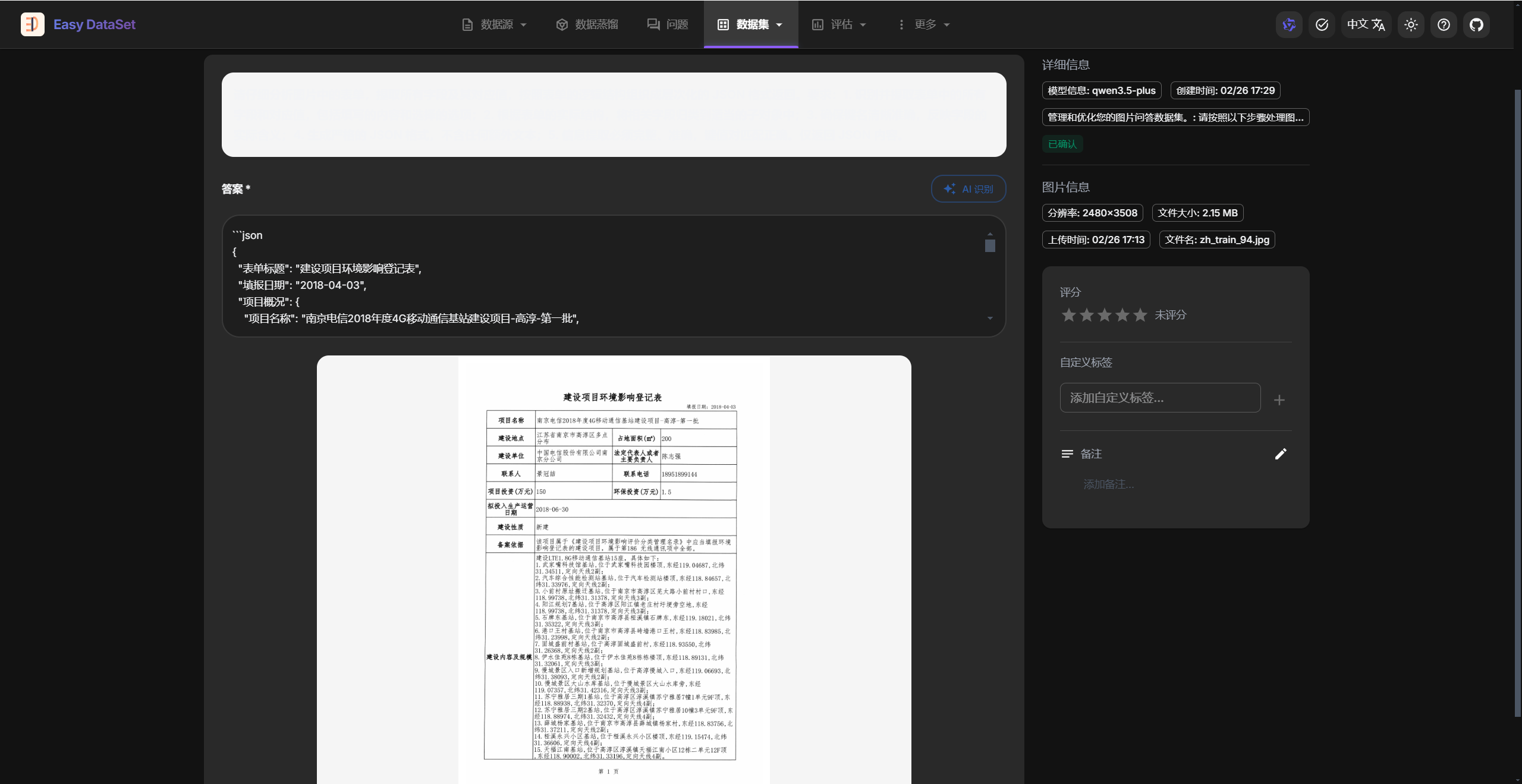
- 在数据集模块中选择图片问答数据集,进行查看。
- 选择导出,格式选择Alpaca格式,并打包图片一块儿导出。
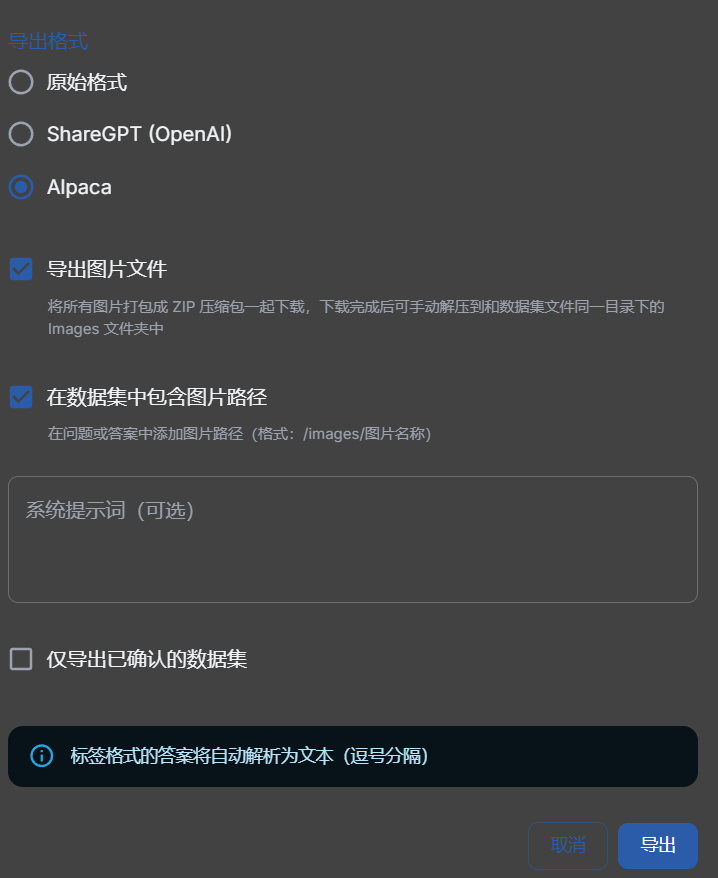
- 将导出的json文件更名为
qwen3_vl_4B_train.json,导出的内容中图片路径/images/...,手动批量替换为images/...。(注意这里并非最终llama factory训练使用的格式【存在兼容问题】)
[
{
"instruction": "请仔细分析图片中的表单,提取所有字段及其对应值,按照表单的逻辑结构组织成层次化的 JSON 格式返回。要求:1. 识别并提取表单中的所有字段和对应值,包括填写的内容和选择的选项;2. 根据表单的实际结构,将相关字段归类到适当的子对象中;3. 确保键名清晰准确,反映字段的实际含义;4. 生成严格的 JSON 格式,不含任何额外文本;5. 信息提取必须完整、准确,键值对匹配正确。仅返回 JSON 内容。",
"input": "",
"output": "{\n \"基本信息\": {\n \"女方\": {\n \"姓名\": \"胡青\",\n \"联系电话\": \"15548956960\",\n \"公民身份号码\": \"152027199602130556\",\n \"户籍地\": \"北京市潘弓村第一大街656号\",\n \"现居住地\": \"北京市潘弓村第一大街656号\",\n \"工作单位\": \"北京市潘弓村小学\"\n },\n \"男方\": {\n \"姓名\": \"任洪强\",\n \"联系电话\": \"15656658584\",\n \"公民身份号码\": \"152027099602030041\",\n \"户籍地\": \"北京市潘弓村第一大街633号\",\n \"现居住地\": \"北京市潘弓村第一大街656号\",\n \"工作单位\": \"北京市潘弓村医院\"\n }\n },\n \"婚姻状况\": {\n \"婚姻类型\": \"双方初婚\",\n \"结婚时间\": \"2005年11月5日\",\n \"结婚证号\": \"J110105-5689-525846\"\n },\n \"子女情况\": {\n \"子女数量\": {\n \"总数\": \"1个\",\n \"亲生\": \"1个\",\n \"其他\": \"(新开户免填)\"\n },\n \"第一个子女\": {\n \"姓名\": \"任亚杰\",\n \"性别\": \"男\",\n \"出生日期\": \"2006年1月2日\"\n }\n },\n \"妊娠情况\": {\n \"状态\": \"未孕\"\n },\n \"已生育补登记\": {\n \"新生儿姓名\": \"(新开户免填)\",\n \"性别\": \"(新开户免填)\",\n \"孩次\": \"(新开户免填)\",\n \"出生医学证明编号\": \"(新开户免填)\",\n \"出生日期\": \"(新开户免填)\",\n \"健康情况\": \"(新开户免填)\",\n \"出生地点\": \"(新开户免填)\"\n },\n \"声明与承诺\": {\n \"内容\": \"男女双方系合法夫妻,共有1个子女,其中亲生1个。现依法登记生育第2个子女。我们承诺以上所填信息及提供的材料真实有效,如有不实,愿承担相应法律后果。导致违法生育的,同意按最高标准征收社会抚养费。\"\n },\n \"签署信息\": {\n \"承诺人(签名、指纹)\": \"任洪强\",\n \"女方\": \"胡青\",\n \"男方\": \"任洪强\",\n \"代办人\": \"王志刚\",\n \"代办人身份证号及联系方式\": \"152027099602030041\",\n \"日期\": \"2019年1月20日\"\n },\n \"备注\": \"以上内容由登记对象填写\"\n}",
"images": [
"images/zh_train_99.jpg"
]
},
- 将其转化为sharegpt格式(经过实践验证可以正常训练)
python convert_to_sharegpt.py qwen3_vl_4B_train.json qwen3_vl_4B_train_converted.json
- convert_to_sharegpt.py
"""
Convert Alpaca format to ShareGPT format for multimodal training.
"""
import json
import sys
def convert_alpaca_to_sharegpt(input_file, output_file):
with open(input_file, 'r', encoding='utf-8') as f:
data = json.load(f)
converted = []
for item in data:
# Build user content with <image> token
instruction = item.get('instruction', '')
input_text = item.get('input', '')
# Combine instruction and input
user_content = instruction
if input_text:
user_content += '\n' + input_text
# Add <image> token at the beginning for multimodal
user_content = '<image>\n' + user_content
# Get assistant response
assistant_content = item.get('output', '')
# Build messages in ShareGPT format
messages = [
{'role': 'user', 'content': user_content},
{'role': 'assistant', 'content': assistant_content}
]
# Build converted item
converted_item = {
'messages': messages,
'images': item.get('images', [])
}
converted.append(converted_item)
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(converted, f, ensure_ascii=False, indent=2)
print(f"Converted {len(converted)} items from {input_file} to {output_file}")
if __name__ == '__main__':
if len(sys.argv) != 3:
print("Usage: python convert_to_sharegpt.py <input_file> <output_file>")
sys.exit(1)
convert_alpaca_to_sharegpt(sys.argv[1], sys.argv[2])
- 转化后的内容:
[
{
"messages": [
{
"role": "user",
"content": "<image>\n请仔细分析图片中的表单,提取所有字段及其对应值,按照表单的逻辑结构组织成层次化的 JSON 格式返回。要求:1. 识别并提取表单中的所有字段和对应值,包括填写的内容和选择的选项;2. 根据表单的实际结构,将相关字段归类到适当的子对象中;3. 确保键名清晰准确,反映字段的实际含义;4. 生成严格的 JSON 格式,不含任何额外文本;5. 信息提取必须完整、准确,键值对匹配正确。仅返回 JSON 内容。"
},
{
"role": "assistant",
"content": "{\n \"基本信息\": {\n \"女方\": {\n \"姓名\": \"胡青\",\n \"联系电话\": \"15548956960\",\n \"公民身份号码\": \"152027199602130556\",\n \"户籍地\": \"北京市潘弓村第一大街656号\",\n \"现居住地\": \"北京市潘弓村第一大街656号\",\n \"工作单位\": \"北京市潘弓村小学\"\n },\n \"男方\": {\n \"姓名\": \"任洪强\",\n \"联系电话\": \"15656658584\",\n \"公民身份号码\": \"152027099602030041\",\n \"户籍地\": \"北京市潘弓村第一大街633号\",\n \"现居住地\": \"北京市潘弓村第一大街656号\",\n \"工作单位\": \"北京市潘弓村医院\"\n }\n },\n \"婚姻状况\": {\n \"婚姻类型\": \"双方初婚\",\n \"结婚时间\": \"2005年11月5日\",\n \"结婚证号\": \"J110105-5689-525846\"\n },\n \"子女情况\": {\n \"子女数量\": {\n \"总数\": \"1个\",\n \"亲生\": \"1个\",\n \"其他\": \"(新开户免填)\"\n },\n \"第一个子女\": {\n \"姓名\": \"任亚杰\",\n \"性别\": \"男\",\n \"出生日期\": \"2006年1月2日\"\n }\n },\n \"妊娠情况\": {\n \"状态\": \"未孕\"\n },\n \"已生育补登记\": {\n \"新生儿姓名\": \"(新开户免填)\",\n \"性别\": \"(新开户免填)\",\n \"孩次\": \"(新开户免填)\",\n \"出生医学证明编号\": \"(新开户免填)\",\n \"出生日期\": \"(新开户免填)\",\n \"健康情况\": \"(新开户免填)\",\n \"出生地点\": \"(新开户免填)\"\n },\n \"声明与承诺\": {\n \"内容\": \"男女双方系合法夫妻,共有1个子女,其中亲生1个。现依法登记生育第2个子女。我们承诺以上所填信息及提供的材料真实有效,如有不实,愿承担相应法律后果。导致违法生育的,同意按最高标准征收社会抚养费。\"\n },\n \"签署信息\": {\n \"承诺人(签名、指纹)\": \"任洪强\",\n \"女方\": \"胡青\",\n \"男方\": \"任洪强\",\n \"代办人\": \"王志刚\",\n \"代办人身份证号及联系方式\": \"152027099602030041\",\n \"日期\": \"2019年1月20日\"\n },\n \"备注\": \"以上内容由登记对象填写\"\n}"
}
],
"images": [
"images/zh_train_99.jpg"
]
},
3.2 实验平台租用和基本环境配置
- 使用优云智算上租用单卡A800进行实验。
- 配置网络加速:临时修改 DNS(立即生效,重启后失效)。
sudo vim /etc/resolv.conf
删除原有nameserver行,添加以下内容
nameserver 100.90.90.90
nameserver 100.90.90.100
- 安装mini anaconda
cd ~
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
- 接受 license:输入
yes。 - 安装路径推荐直接按回车(默认在
/home/ubuntu/miniconda3)。 - 初始化 conda:输入
yes。
- 创建虚拟环境,安装llama factory。
conda create --name llama_factory python==3.11
conda activate llama_factory
git clone --depth 1 https://github.com/hiyouga/LlamaFactory.git
cd LLaMA-Factory
pip install -e .
pip install -r requirements/metrics.txt
pip install -r requirements/swanlab.txt
llamafactory-cli version
- 模型下载:安装modelscope。
mkdir base_model
cd bas_model
pip install modelscope
modelscope download --model Qwen/Qwen3-VL-4B-Thinking --local_dir ./Qwen3-VL-4B-Thinking
3.3 数据集上传和注册
- 将
qwen3_vl_4B_train_converted.json上传到/home/ubuntu/LLaMA-Factory/data目录下,在data目录下新建images目录存放所有图片。
(base) ubuntu@10-60-22-22:~/LLaMA-Factory/data$ tree
.
├── convert_to_sharegpt.py
├── dataset_info.json
├── qwen3_vl_4B_train.json
├── qwen3_vl_4B_train_converted.json
├── images #图片目录
- 在
dataset_info.json中注册数据集信息。
{
"qwen3_vl_4B_train": {
"file_name": "qwen3_vl_4B_train_converted.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
},
"identity": {
"file_name": "identity.json"
},
3.4 启动llama factory和网页访问
cd LLaMA-Factory
nohup llamafactory-cli webui > webui.log 2>&1 &
- 安装使用trae工具,远程链接服务器,输入密码,然后选择LLaMA-Factory目录,进行代码编辑和查阅。
- 虽然优云智算平台提供服务器公网ip,如果不想配置防火墙或者不想将服务暴露到公网,可以使用gmssh客户端的浏览器功能使用内网ip进行访问和使用。
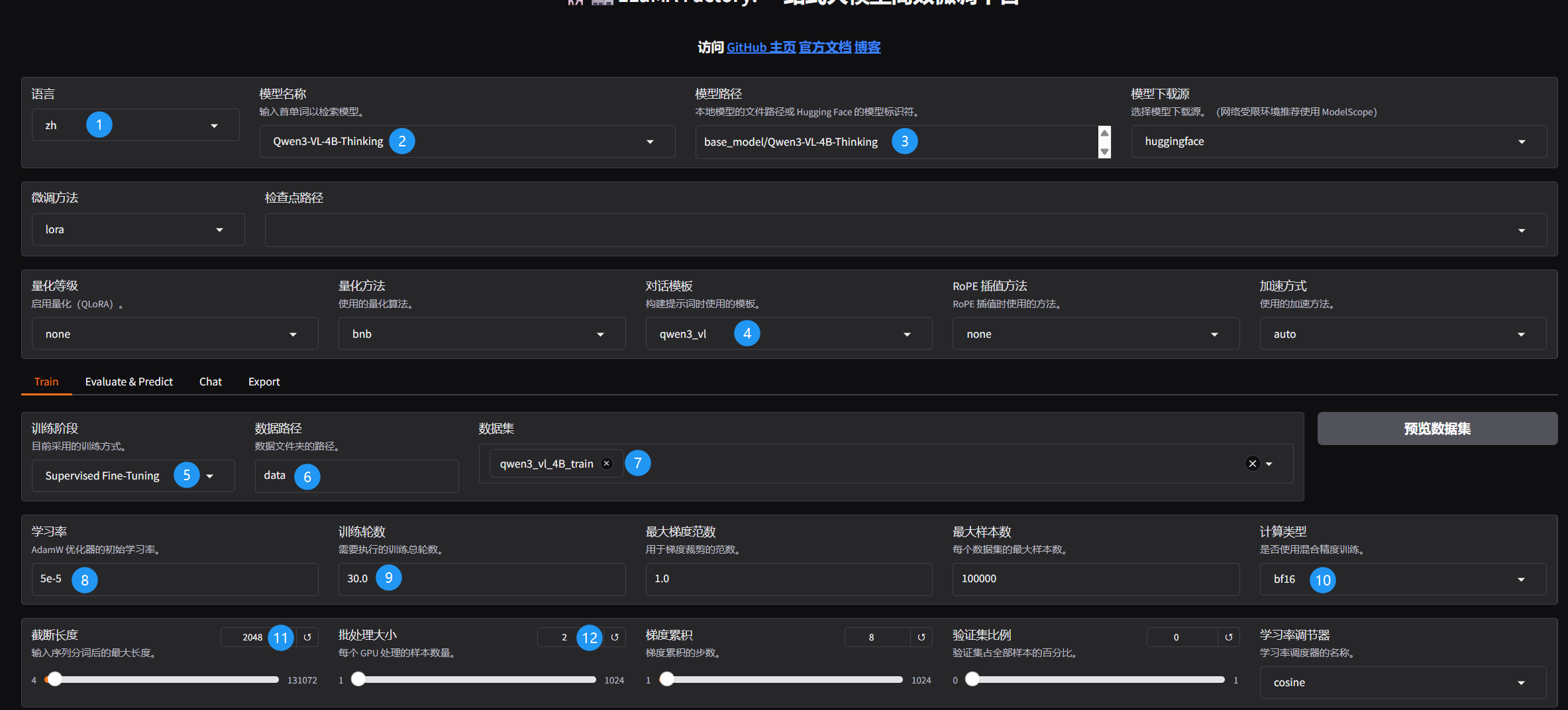
3.5 关键训练参数可视化配置
- swanlab登录和日志记录。
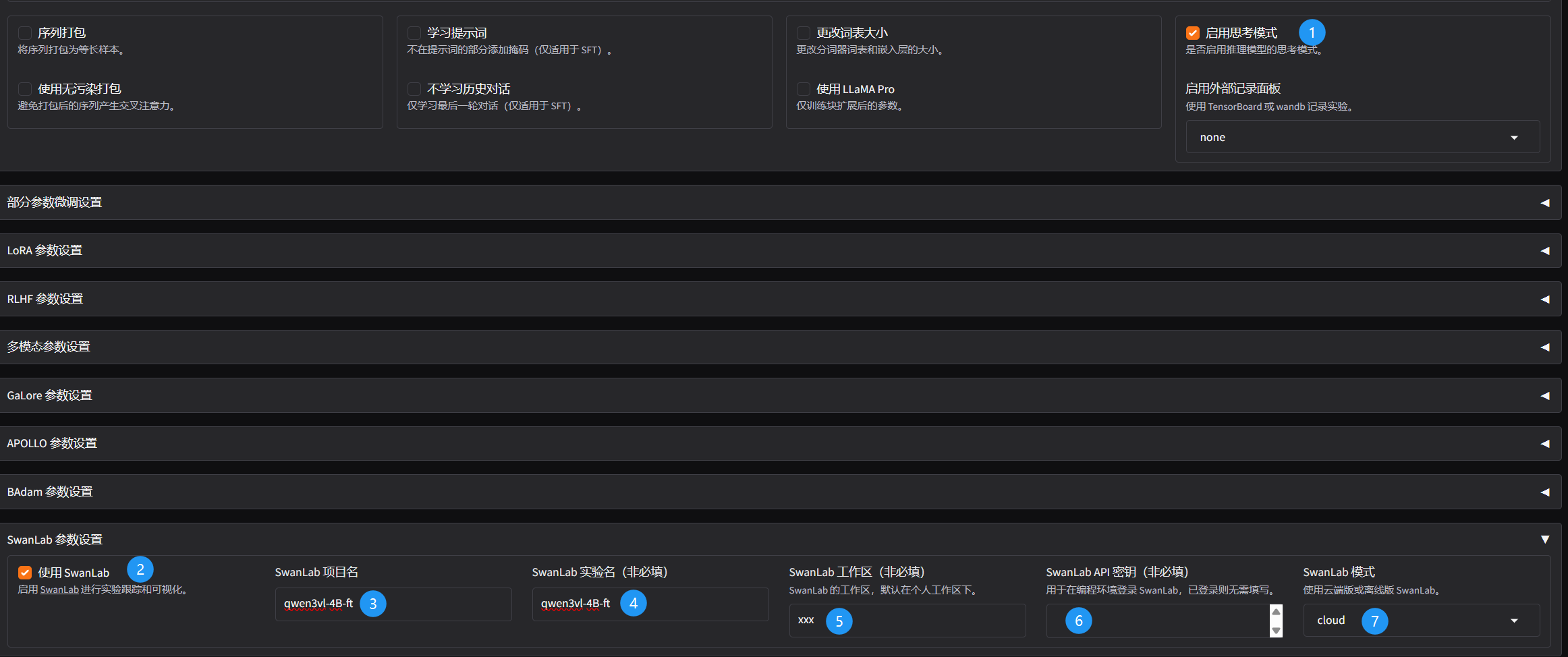
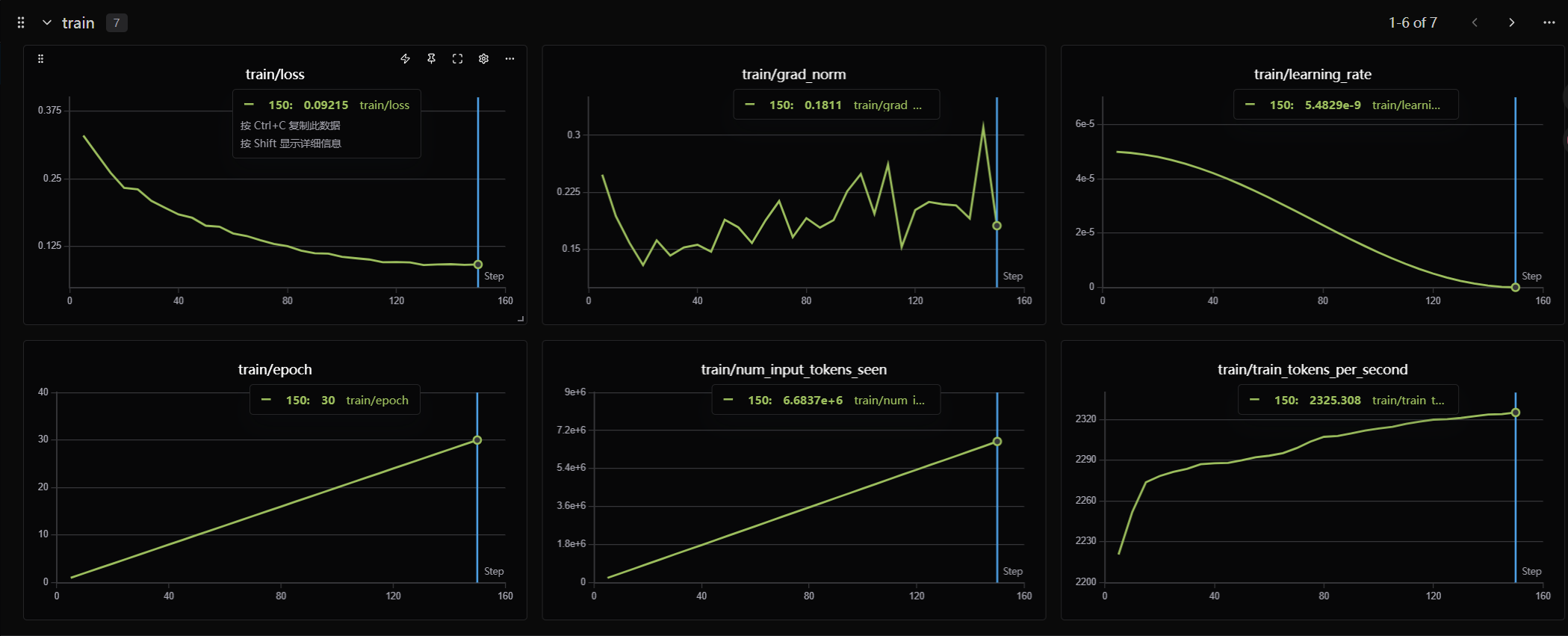
- 选择预览预览命令,并保存训练配置,然后点击训练开始即可,大约需要1h。

llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path base_model/Qwen3-VL-4B-Thinking \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen3_vl \
--flash_attn auto \
--dataset_dir data \
--dataset qwen3_vl_4B_train \
--cutoff_len 2048 \
--learning_rate 5e-05 \
--num_train_epochs 30.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--enable_thinking True \
--report_to none \
--use_swanlab True \
--output_dir saves/Qwen3-VL-4B-Thinking/lora/train_2026-02-28-17-55-16 \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all \
--freeze_vision_tower True \
--freeze_multi_modal_projector True \
--image_max_pixels 589824 \
--image_min_pixels 1024 \
--video_max_pixels 65536 \
--video_min_pixels 256 \
--swanlab_project qwen3vl-4B-ft \
--swanlab_run_name qwen3vl-4B-ft \
--swanlab_workspace xxx \
--swanlab_mode cloud
| 参数 | 值 | 含义 |
|---|---|---|
--stage |
sft |
训练阶段:Supervised Fine-Tuning(监督微调),在预训练模型基础上用标注数据进行有监督学习 |
--do_train |
True |
执行训练:启用训练模式,而非仅评估或推理 |
--model_name_or_path |
base_model/Qwen3-VL-4B-Thinking |
基座模型路径:加载的预训练模型位置,Qwen3-VL-4B-Thinking是阿里开源的多模态小模型(40亿参数,带思考能力) |
--preprocessing_num_workers |
16 |
数据预处理并行数:使用16个CPU进程并行处理数据加载和预处理,加速数据准备 |
--finetuning_type |
lora |
微调方法:Low-Rank Adaptation(低秩适配),只训练少量适配参数,冻结原模型大部分权重,节省显存 |
--template |
qwen3_vl |
对话模板:使用Qwen3-VL模型的官方对话格式模板,确保指令遵循风格一致 |
--flash_attn |
auto |
Flash Attention:自动检测并启用Flash Attention优化,加速注意力计算并减少显存占用 |
--dataset_dir |
data |
数据集目录:训练数据存放的根目录 |
--dataset |
qwen3_vl_4B_train |
数据集名称:具体使用的数据集配置文件名,需在dataset_info.json中定义 |
--cutoff_len |
2048 |
序列截断长度:单条样本最大token数,超过则截断,控制显存占用和计算量 |
--learning_rate |
5e-05 |
学习率:0.00005,LoRA微调常用范围,控制参数更新步长 |
--num_train_epochs |
30.0 |
训练轮数:完整遍历训练数据30次,LoRA可适当增加epoch |
--max_samples |
100000 |
最大样本数:最多使用10万条样本,防止数据过多导致训练过长 |
--per_device_train_batch_size |
2 |
单设备批次大小:每张GPU每步处理2条样本,配合梯度累积实现有效大batch |
--gradient_accumulation_steps |
8 |
梯度累积步数:每8步才更新一次参数,等效batch size = 2×8=16,节省显存 |
--lr_scheduler_type |
cosine |
学习率调度器:余弦退火,学习率从初始值按余弦曲线衰减到0,平滑收敛 |
--max_grad_norm |
1.0 |
梯度裁剪阈值:梯度范数超过1.0时进行裁剪,防止梯度爆炸 |
--logging_steps |
5 |
日志记录间隔:每5步打印一次训练日志(loss、学习率等) |
--save_steps |
100 |
模型保存间隔:每100步保存一次checkpoint,便于恢复和中断续训 |
--warmup_steps |
0 |
预热步数:0表示不进行学习率预热,直接从初始学习率开始 |
--packing |
False |
样本打包:不启用,若启用会将多条短样本拼接成一条长序列提高效率 |
--enable_thinking |
True |
启用思考模式:Qwen3特有,保留模型的链式思考(CoT)能力,输出带推理过程 |
--report_to |
none |
默认报告工具:不使用HuggingFace默认的tensorboard/wandb等 |
--use_swanlab |
True |
启用SwanLab:使用国产实验跟踪工具替代wandb |
--output_dir |
saves/... |
输出目录:模型保存路径,含时间戳便于区分不同实验 |
--bf16 |
True |
BF16混合精度:使用bfloat16格式训练,加速计算且比fp16更稳定 |
--plot_loss |
True |
绘制损失曲线:训练结束后自动生成loss变化图 |
--trust_remote_code |
True |
信任远程代码:允许执行模型仓库中的自定义代码,多模态模型通常需要 |
--ddp_timeout |
180000000 |
DDP超时时间:分布式训练超时阈值(秒),设极大值防止大数据集加载超时 |
--include_num_input_tokens_seen |
True |
统计输入token数:记录实际处理的输入token总量,便于计算吞吐量 |
--optim |
adamw_torch |
优化器:PyTorch原生AdamW,带动量衰减的Adam变体 |
--lora_rank |
8 |
LoRA秩:低秩矩阵的秩,决定适配参数量,8是较小值适合轻量微调 |
--lora_alpha |
16 |
LoRA缩放系数:实际缩放比例为alpha/rank=2,控制LoRA对原始权重的影响强度 |
--lora_dropout |
0 |
LoRA Dropout:0表示不丢弃,全量使用LoRA参数,小数据集可防过拟合 |
--lora_target |
all |
LoRA目标模块:对所有线性层应用LoRA,包括q_proj/k_proj/v_proj/o_proj等 |
--freeze_vision_tower |
True |
冻结视觉编码器:不训练图像编码部分(ViT),保持预训练视觉特征提取能力 |
--freeze_multi_modal_projector |
True |
冻结多模态投影层:不训练视觉-语言对齐的投影层,进一步减少可训练参数 |
--image_max_pixels |
589824 |
图像最大像素:768×768=589824,超过则缩放,控制视觉输入计算量 |
--image_min_pixels |
1024 |
图像最小像素:32×32=1024,过小图像会放大,保证基本信息 |
--video_max_pixels |
65536 |
视频最大像素:256×256=65536,视频帧的分辨率上限,降低视频处理负担 |
--video_min_pixels |
256 |
视频最小像素:16×16=256,视频帧分辨率下限 |
--swanlab_project |
qwen3vl-4B-ft |
SwanLab项目名:实验所属项目名称,用于分组管理 |
--swanlab_run_name |
qwen3vl-4B-ft |
SwanLab运行名:单次实验的名称标识 |
--swanlab_workspace |
xxx |
SwanLab工作空间:团队/个人工作空间ID |
--swanlab_mode |
cloud |
SwanLab模式:云端模式,数据上传到SwanLab服务器查看 |
3.6 模型效果使用体验
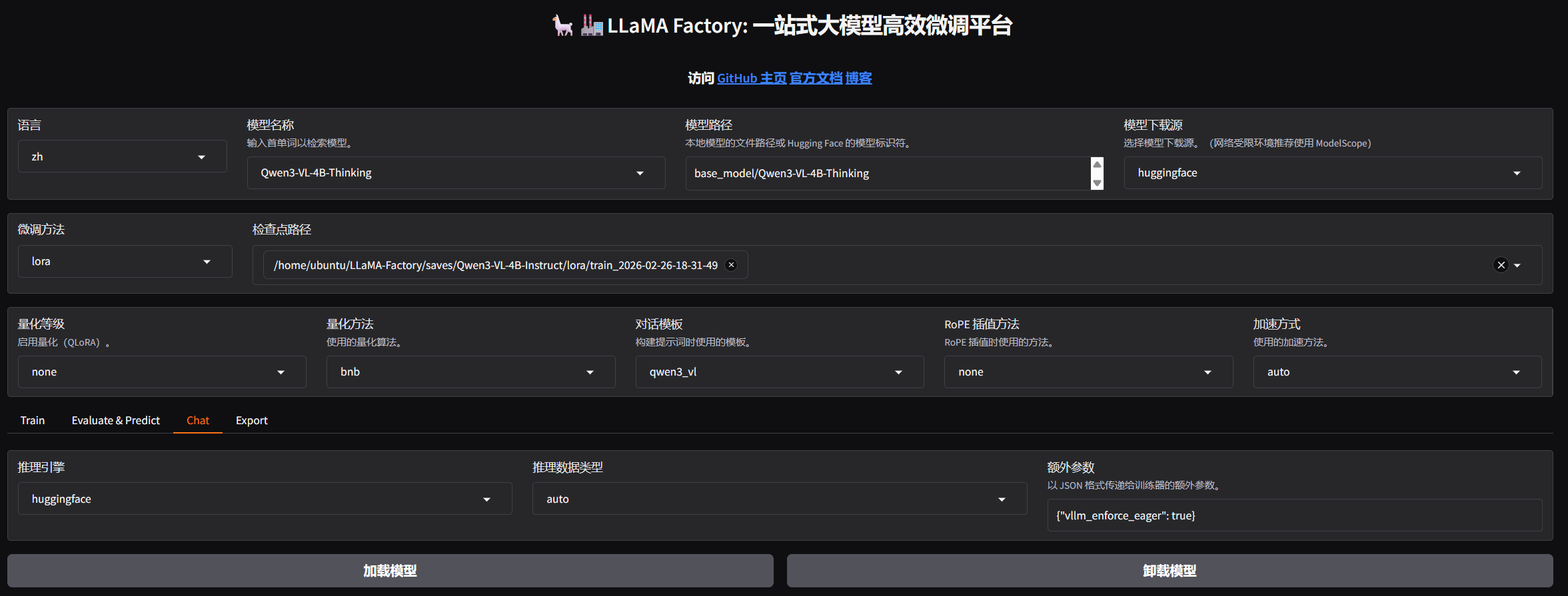
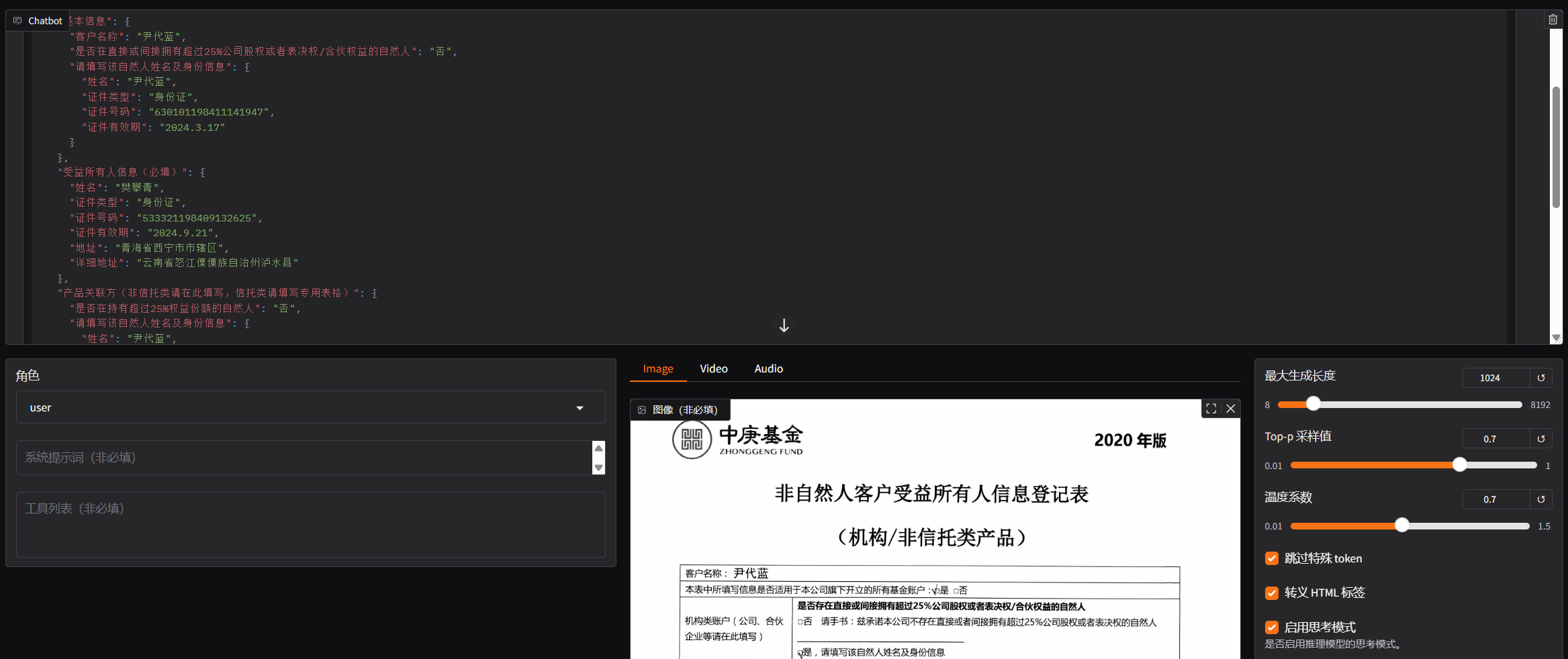
- 选择对话,输入检查点路径,然后加载模型。
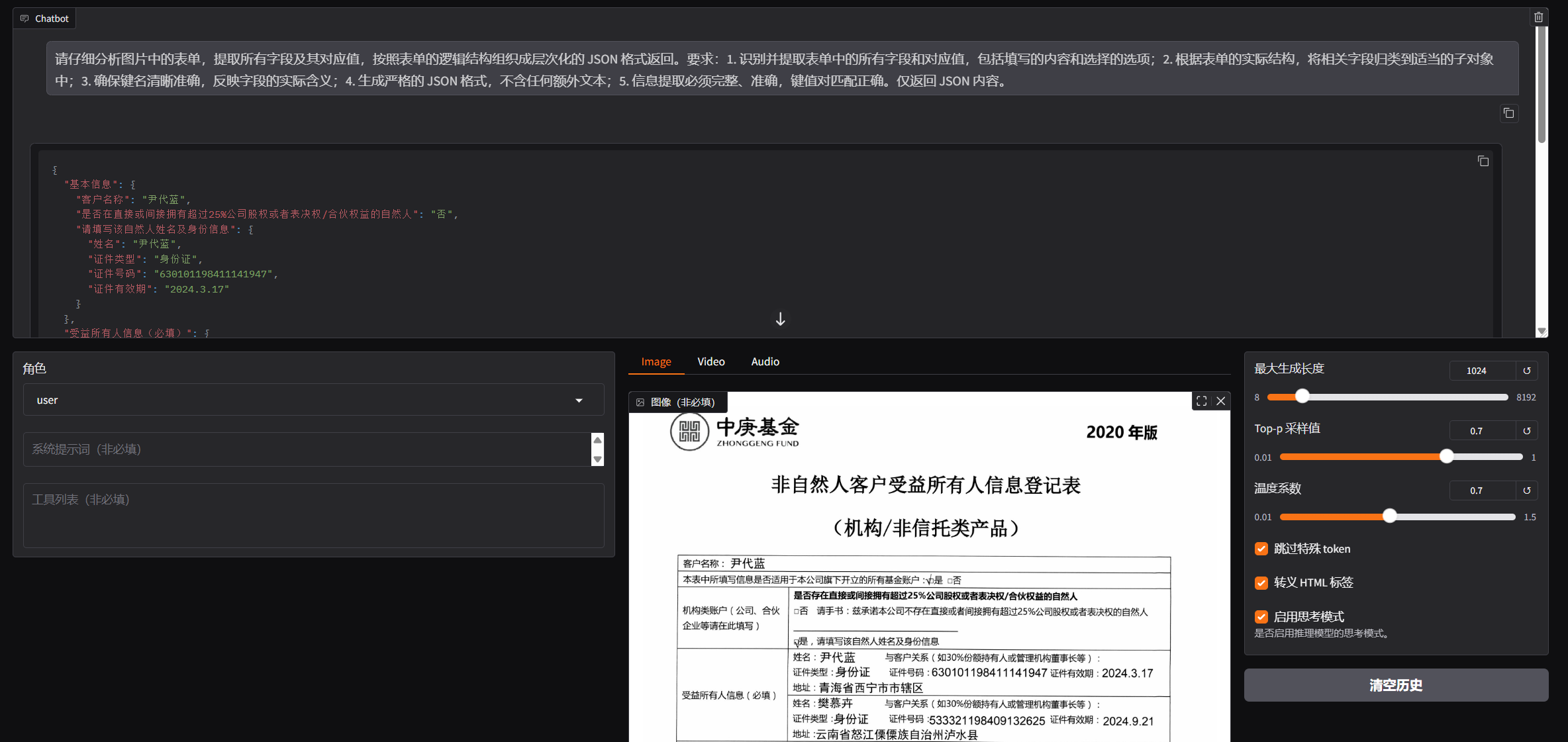
- 上传图片,输入问题,尽量保持问题与训练的问题一致。
请仔细分析图片中的表单,提取所有字段及其对应值,按照表单的逻辑结构组织成层次化的 JSON 格式返回。要求:1. 识别并提取表单中的所有字段和对应值,包括填写的内容和选择的选项;2. 根据表单的实际结构,将相关字段归类到适当的子对象中;3. 确保键名清晰准确,反映字段的实际含义;4. 生成严格的 JSON 格式,不含任何额外文本;5. 信息提取必须完整、准确,键值对匹配正确。仅返回 JSON 内容。
| 类型 | 数值 |
|---|---|
| max_leng_token | 1024 |
| top-p | 0.7 |
| Temperature | 0.7 |
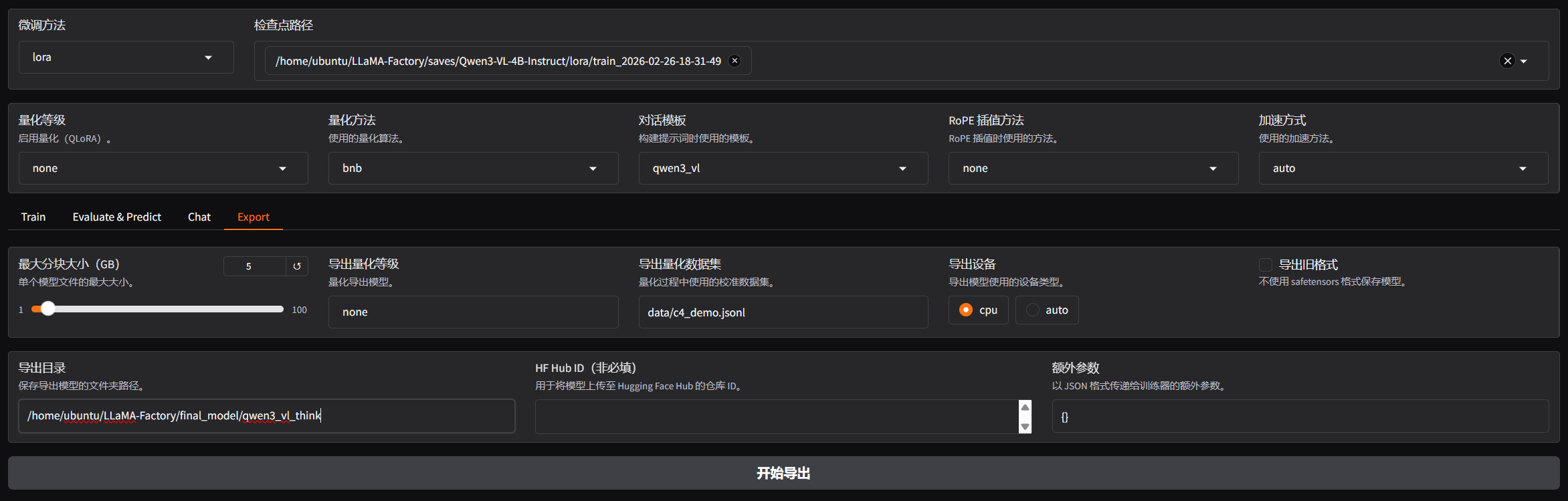
3.7 模型导出

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 29
29 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)