RAG高级技术完整教程-迪士尼智能客服全案例【下】
续上一篇的内容第十一章:GraphRAG - 知识图谱增强检索11.1 传统RAG的局限性在前面章节中,我们使用的都是文本块(Chunk)检索的方式。虽然已经很强大,但在某些场景下仍有局限:场景1:多跳推理问题场景2:全局性总结问题11.2 GraphRAG核心思想GraphRAG通过知识图谱来组织信息,建立实体之间的显式关系:GraphRAG的优势:关系显式化:不再依赖文本相似度,而是通过图结构
续上一篇的内容
第十一章:GraphRAG - 知识图谱增强检索
11.1 传统RAG的局限性
在前面章节中,我们使用的都是文本块(Chunk)检索的方式。虽然已经很强大,但在某些场景下仍有局限:
场景1:多跳推理问题
用户问:"创极速光轮和七个小矮人矿山车的刺激程度对比,哪个更适合害怕过山车的人?"传统RAG的问题:1. 需要检索出两个项目的介绍2. 需要理解"刺激程度"的含义3. 需要对比分析4. 需要推理出"害怕过山车的人"的偏好→ 容易遗漏关键信息,或者检索到的文档不够全面
场景2:全局性总结问题
用户问:"迪士尼所有过山车项目的完整对比分析"传统RAG的问题:- Top-K检索可能漏掉某些过山车- 难以建立项目之间的关联关系- 缺乏全局视角的总结能力
11.2 GraphRAG核心思想
GraphRAG通过知识图谱来组织信息,建立实体之间的显式关系:

GraphRAG的优势:
-
关系显式化
:不再依赖文本相似度,而是通过图结构表达关系
-
多跳推理
:沿着图的边可以自然地进行多跳查询
-
全局理解
:通过社区发现算法,理解整体结构
-
可解释性强
:推理路径清晰可见
11.3 GraphRAG构建流程
第一步:实体识别与关系抽取
从迪士尼知识库的文本中,提取结构化信息:
原始文本:"创极速光轮是明日世界园区的过山车项目,身高要求122cm以上,刺激程度为五星。"抽取结果:实体: - 项目名称:创极速光轮(类型:游乐项目) - 所属园区:明日世界(类型:主题园区) - 身高要求:122cm(类型:限制条件) - 刺激程度:五星(类型:属性)关系: - (创极速光轮) -[位于]-> (明日世界) - (创极速光轮) -[身高要求]-> (122cm) - (创极速光轮) -[刺激程度]-> (五星) - (创极速光轮) -[类型]-> (过山车)
核心技术思路:
使用LLM进行实体和关系抽取,Prompt设计是关键:
classKnowledgeGraphBuilder: """知识图谱构建器""" defextract_entities_relations(self, text: str) -> Dict: """从文本中抽取实体和关系""" prompt = f""" 【提示词设计 】 你是一个知识图谱构建专家。请从以下文本中抽取实体和关系。 【抽取规则】 实体类型:游乐项目、主题园区、限制条件、服务设施、餐饮、住宿 关系类型:位于、属于、要求、适合、提供、连接 文本:{text} 输出JSON格式:{{ "entities": [ {{"name": "实体名称", "type": "实体类型", "properties": {{}}}} ], "relations": [{{"source": "源实体", "target": "目标实体", "type": "关系类型"}} ] }} """ response = get_completion(prompt, self.model) return json.loads(preprocess_json_response(response))
第二步:社区发现(Hierarchical Clustering)
将相似的实体聚类成”社区”,便于全局理解:
defbuild_knowledge_communities(entities: List, relations: List) -> Dict: """构建知识社区""" communities = {#社区1:"明日世界园区": ["创极速光轮(过山车,刺激程度五星)","巴斯光年星际营救(射击游戏,家庭友好)", "喷气背包飞行器(飞行体验,中等刺激)" ],#社区2:"刺激类项目": ["创极速光轮(五星刺激,身高122cm)","雷鸣山漂流(四星刺激,身高107cm)","七个小矮人矿山车(三星刺激,身高97cm)" ],#社区3"家庭友好类": ["疯狂动物城警察局(无身高限制)","小飞侠天空奇遇(适合幼儿)", "旋转木马(全年龄段)" ] }return communities
第三步:社区摘要生成
为每个社区生成摘要,用于全局性查询:
defgenerate_community_summaries(communities: Dict) -> Dict: """生成社区摘要""" summaries = {}for community_name, entities in communities.items(): prompt = f""" 请为以下{community_name}社区生成结构化摘要: 实体列表:{entities} 要求: 1. 按刺激程度排序 2. 分析适合人群 3. 给出游玩建议 4. 输出JSON格式 """ summary = get_completion(prompt, model="deepseek-v3") summaries[community_name] = json.loads(summary)return summaries
11.4 GraphRAG检索模式
模式(一)Local模式:针对特定实体的检索
适用于问题聚焦于某个具体实体的场景:
deflocal_graph_retrieval(entity_name: str, graph_db) -> Dict: """本地图检索 - 获取特定实体的完整信息"""# 1. 识别核心实体 entity = graph_db.get_entity(entity_name)# 2. 获取所有相关关系和属性 relations = graph_db.get_relations(entity_name) properties = graph_db.get_properties(entity_name)# 3. 组织成结构化信息 entity_info = {"核心实体": entity_name,"属性信息": properties,"关联关系": relations,"邻居实体": graph_db.get_neighbors(entity_name) }return entity_info
模式(二)Global模式:全局性总结查询
适用于需要整体理解的场景:
defglobal_graph_retrieval(query: str, graph_db) -> Dict: """全局图检索 - 基于社区摘要的宏观分析"""# 1. 识别查询意图 intent = analyze_query_intent(query)# 2. 定位相关社区 relevant_communities = find_relevant_communities(intent, graph_db)# 3. 获取社区摘要 community_summaries = {}for community in relevant_communities: community_summaries[community] = graph_db.get_community_summary(community)# 4. 基于摘要生成对比分析 comparative_analysis = generate_comparative_analysis(community_summaries, query)return {"query_intent": intent,"relevant_communities": relevant_communities,"community_summaries": community_summaries,"comparative_analysis": comparative_analysis }
11.5 GraphRAG vs 传统RAG 效果对比
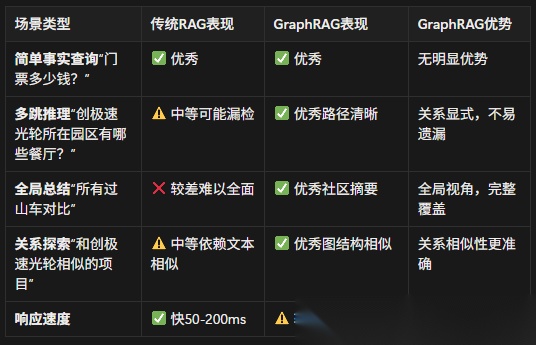
11.6 GraphRAG的成本与挑战
构建成本:
# GraphRAG构建成本估算(以1万条知识为例)construction_costs = {"实体抽取": {"api_calls": 10000, # 每千条文本约1000次调用"estimated_cost": 20, # 约$20"time_required": "1-2小时" },"关系抽取": {"api_calls": 15000, # 每千条文本约1500次调用 "estimated_cost": 30, # 约$30"time_required": "2-3小时" },"社区发现": {"computation": "密集型", # 图算法计算"estimated_cost": 10, # 计算资源成本"time_required": "1-2小时" },"摘要生成": {"api_calls": 50, # 每个社区1次调用"estimated_cost": 5, # 约$5"time_required": "30分钟" },"总计": {"api_calls": 25000,"total_cost": 65, # 约$65"total_time": "4-7小时" }}
维护成本:
- 增量更新:新增知识需要重新抽取实体和关系
- 社区重算:知识变化后,社区结构可能改变
- 摘要更新:社区变化后需要重新生成摘要
挑战与解决方案:
| 挑战 | 解决方案 |
| 实体抽取准确率不高 | 使用Few-shot学习,提供高质量示例 |
| 关系识别困难 | 预定义常见关系类型,限制搜索空间 |
| 图规模过大 | 分层存储,按需加载 |
| 更新效率低 | 增量更新机制,只更新变化部分 |
实践建议:混合策略
# 智能路由策略defsmart_retrieval_strategy(query: str, user_context: Dict) -> str:"""根据查询类型智能选择检索策略"""# 简单查询:用传统RAG快速响应 simple_indicators = ["多少钱", "在哪", "营业时间", "身高要求"]if any(indicator in query for indicator in simple_indicators):return"traditional"# 复杂推理:用GraphRAG深度分析 complex_indicators = ["哪个更好", "对比", "推荐", "适合", "规划"]if any(indicator in query for indicator in complex_indicators):return"graph"# 默认先用传统RAG,效果不好再降级到GraphRAGreturn"traditional_with_fallback"# 实际执行defexecute_retrieval(query: str, strategy: str):"""执行检索策略"""if strategy == "traditional":return traditional_rag.retrieve(query)elif strategy == "graph":return graph_rag.retrieve(query)else: # traditional_with_fallback traditional_result = traditional_rag.retrieve(query)if traditional_result["confidence"] > 0.8:return traditional_resultelse:return graph_rag.retrieve(query)
第十二章:完整系统集成与最佳实践
12.1 端到端RAG系统架构
经过前面11章的学习,我们已经掌握了RAG的各个模块。但现在面临一个关键问题:如何将这些独立的"乐高积木"组装成一个稳定可靠的"智能建筑"?
这是很多技术团队都会遇到的困境:每个模块单独测试都很出色,但集成后却问题频出。
问题:
- Query改写、检索、生成各自为战,缺乏统一调度
- 某个模块故障导致整个系统崩溃
- 性能瓶颈难以定位,优化无从下手
- 线上问题排查像大海捞针
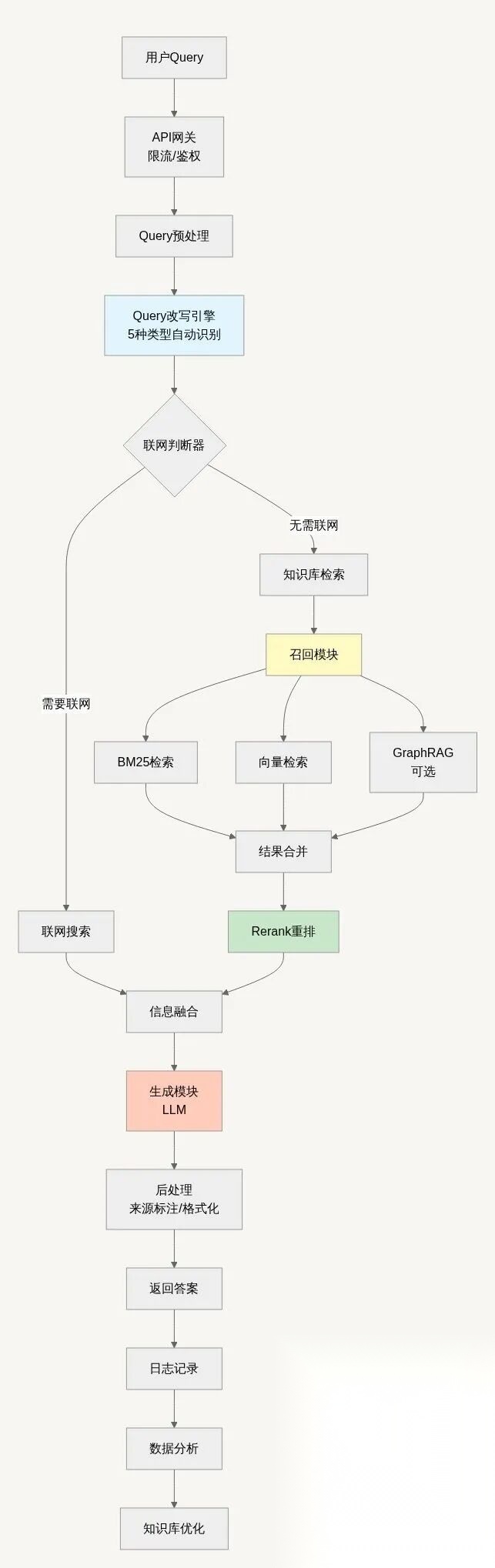
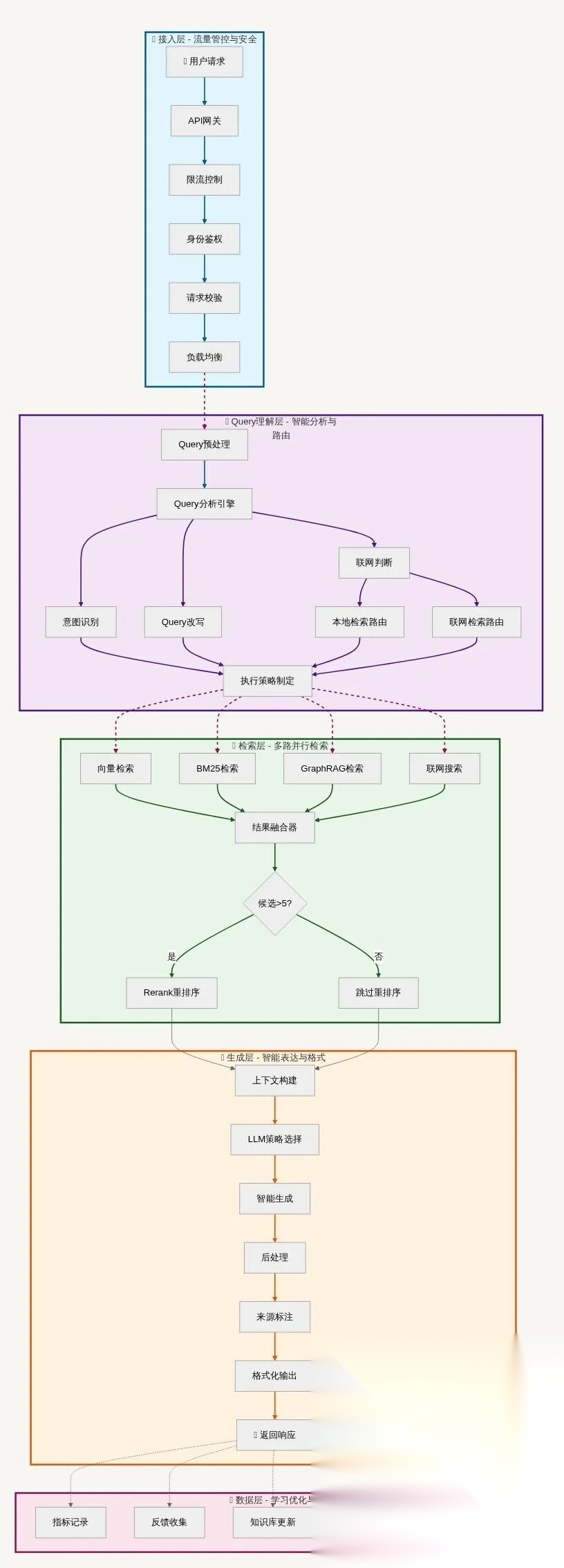
12.2 系统分层设计
根据以上的流程图为增强层次结构,加强理解。
classEnterpriseRAGSystem: """企业级RAG系统 - 全链路智能流水线"""def__init__(self, config: Dict): self.config = config self._initialize_components()def_initialize_components(self):"""初始化所有组件"""# 接入层 self.gateway = APIGateway(rate_limit=config['rate_limit']) self.auth_manager = AuthManager()# 理解层 self.query_engine = AutoQueryRewriter() self.web_detector = WebSearchDetector()# 检索层 self.hybrid_retriever = HybridRetriever() self.graph_rag = GraphRAGEngine() self.reranker = BGEReranker()# 生成层 self.llm_router = LLMRouter() self.response_builder = ResponseBuilder()# 数据层 self.knowledge_base = VersionedKnowledgeBase() self.metrics_collector = MetricsCollector()asyncdefprocess_query(self, query: str, user_context: Dict) -> Dict:"""处理用户查询的完整流程"""# 1. 接入层处理 auth_result = await self.gateway.authenticate_request(user_context)ifnot auth_result['success']:return self._build_error_response(auth_result)# 2. Query理解与路由with self.metrics_collector.timer('query_understanding'): query_analysis = await self.query_engine.analyze(query, user_context) web_decision = await self.web_detector.analyze(query, user_context)# 3. 并行检索执行with self.metrics_collector.timer('retrieval'): retrieval_tasks = []# 知识库检索ifnot web_decision['need_web_search']: retrieval_tasks.append( self.hybrid_retriever.search(query_analysis['final_query']) )# GraphRAG检索(复杂查询)if query_analysis.get('needs_reasoning', False): retrieval_tasks.append( self.graph_rag.retrieve(query_analysis['final_query']) )# 并行执行所有检索任务 retrieval_results = await asyncio.gather(*retrieval_tasks)# 4. 结果融合与重排序with self.metrics_collector.timer('fusion_rerank'): fused_results = self._fuse_retrieval_results(retrieval_results)if len(fused_results) > 5: # 只在候选多时启用Rerank reranked_results = await self.reranker.rerank( query_analysis['final_query'], fused_results )else: reranked_results = fused_results# 5. 智能生成with self.metrics_collector.timer('generation'): final_context = self._build_generation_context(reranked_results, web_decision) llm_response = await self.llm_router.generate( query=query, context=final_context, user_context=user_context, query_analysis=query_analysis )# 6. 后处理与返回 response = self.response_builder.build( llm_response=llm_response, sources=reranked_results[:3], # 只返回Top-3来源 query_analysis=query_analysis, metrics=self.metrics_collector.get_metrics() )# 7. 异步记录与学习 asyncio.create_task(self._async_learning_loop(query, response, user_context))return response
12.3 五层架构设计:清晰的责任边界
第一层:接入层 - 系统的"门卫"
classAPIGateway: """API网关 - 流量管控与安全防护"""asyncdefprocess_request(self, request: Request) -> Dict:"""处理接入请求"""# 限流控制ifnotawait self.rate_limiter.check_limit(request.user_id):raise RateLimitExceeded("请求频率超限")# 身份鉴权 auth_result = await self.auth_manager.authenticate(request.token)ifnot auth_result['valid']:raise AuthenticationFailed("身份验证失败")# 请求校验 validated_data = await self.validator.validate(request)# 负载均衡 backend_instance = self.load_balancer.select_backend()return {"user_id": auth_result['user_id'],"validated_data": validated_data,"backend_instance": backend_instance,"request_id": generate_request_id() }
第二层:理解层 - 系统的"大脑"
classQueryUnderstandingEngine: """查询理解引擎 - 智能路由与决策"""asyncdefanalyze_query(self, query: str, history: List) -> Dict:"""深度查询分析""" analysis_tasks = {"intent_classification": self._classify_intent(query),"query_rewriting": self.rewriter.rewrite(query, history),"routing_decision": self._make_routing_decision(query),"web_search_check": self.web_detector.analyze(query) }# 并行执行分析任务 results = await asyncio.gather(*analysis_tasks.values()) analysis_result = dict(zip(analysis_tasks.keys(), results))# 制定执行策略 execution_plan = self._build_execution_plan(analysis_result)return {"analysis": analysis_result,"execution_plan": execution_plan,"final_query": analysis_result['query_rewriting']['final_query'] }def_build_execution_plan(self, analysis: Dict) -> Dict:"""构建执行计划""" plan = {"retrieval_strategy": "hybrid", # 默认混合检索"enable_graph_rag": False,"enable_rerank": True,"enable_web_search": analysis['web_search_check']['need_web_search'],"llm_strategy": "balanced"# balanced/quality/speed }# 根据分析结果调整策略if analysis['intent_classification']['needs_reasoning']: plan['enable_graph_rag'] = True plan['llm_strategy'] = 'quality'if analysis['intent_classification']['is_simple_fact']: plan['retrieval_strategy'] = 'vector_only' plan['enable_rerank'] = False plan['llm_strategy'] = 'speed'return plan
第三层:检索层 - 系统的"记忆库"
classSmartRetrievalOrchestrator: """智能检索编排器 - 多路检索的指挥家"""asyncdefexecute_retrieval_plan(self, query: str, plan: Dict) -> List:"""执行检索计划""" retrieval_tasks = []# 根据策略添加检索任务if plan['retrieval_strategy'] in ['hybrid', 'vector_only']: retrieval_tasks.append(self.vector_retriever.search(query))if plan['retrieval_strategy'] in ['hybrid', 'keyword_only']: retrieval_tasks.append(self.bm25_retriever.search(query))if plan['enable_graph_rag']: retrieval_tasks.append(self.graph_rag.retrieve(query))# 并行执行检索 retrieval_results = await asyncio.gather(*retrieval_tasks)# 结果融合 fused_results = self._fuse_results(retrieval_results, plan)# 条件重排序if plan['enable_rerank'] and len(fused_results) > 5: fused_results = await self.reranker.rerank(query, fused_results)return fused_results[:plan.get('top_k', 5)]def_fuse_results(self, results: List, plan: Dict) -> List:"""智能结果融合""" fusion_strategy = {'hybrid': self._hybrid_fusion,'vector_only': self._vector_priority_fusion,'keyword_only': self._keyword_priority_fusion } fusion_func = fusion_strategy.get(plan['retrieval_strategy'], self._hybrid_fusion)return fusion_func(results)
第四层:生成层 - 系统的"表达者"
classIntelligentResponseGenerator: """智能响应生成器 - 精准且友好的表达"""asyncdefgenerate_response(self, query: str, context: List, plan: Dict) -> Dict:"""生成智能响应"""# 1. 选择LLM策略 llm_config = self._select_llm_strategy(plan)# 2. 构建优化提示词 prompt = self._build_optimized_prompt(query, context, plan)# 3. 流式生成if plan.get('streaming', False):returnawait self._streaming_generate(prompt, llm_config)else:returnawait self._batch_generate(prompt, llm_config)def_build_optimized_prompt(self, query: str, context: List, plan: Dict) -> str:"""构建优化提示词""" prompt_template = self._select_prompt_template(plan)# 动态上下文压缩 compressed_context = self._compress_context(context, plan['llm_strategy']) filled_prompt = prompt_template.format( query=query, context=compressed_context, current_time=datetime.now().strftime("%Y-%m-%d %H:%M"), response_style=self._get_response_style(plan) )return filled_promptdef_compress_context(self, context: List, strategy: str) -> str:"""动态上下文压缩""" compression_rules = {'speed': {'max_tokens': 2000, 'top_k': 3}, # 快速模式'balanced': {'max_tokens': 4000, 'top_k': 5}, # 平衡模式'quality': {'max_tokens': 6000, 'top_k': 8} # 质量模式 } rule = compression_rules[strategy] compressed = [] total_tokens = 0for doc in sorted(context, key=lambda x: -x['score'])[:rule['top_k']]: doc_tokens = estimate_tokens(doc['content'])if total_tokens + doc_tokens <= rule['max_tokens']: compressed.append(doc) total_tokens += doc_tokensreturn"\n\n".join([doc['content'] for doc in compressed])
第五层:数据层 - 系统的"后勤部"
classDataPlatform: """数据平台 - 监控、学习、优化的基石"""def__init__(self): self.metrics_store = MetricsStore() self.feedback_collector = FeedbackCollector() self.knowledge_ops = KnowledgeOperations()asyncdefrecord_interaction(self, interaction: Dict):"""记录用户交互数据"""# 异步存储核心指标 storage_tasks = [ self.metrics_store.record_metrics(interaction['metrics']), self.feedback_collector.record_feedback(interaction['feedback']), self.knowledge_ops.update_usage_stats(interaction['query_analysis']) ]await asyncio.gather(*storage_tasks)# 触发学习循环(如果满足条件)if self._should_trigger_learning(interaction): asyncio.create_task(self._trigger_learning_cycle(interaction))asyncdef_trigger_learning_cycle(self, interaction: Dict):"""触发学习循环"""# 知识沉淀if interaction['feedback'].get('useful', False):await self.knowledge_ops.extract_new_knowledge(interaction)# 模型优化if interaction['metrics']['retrieval_score'] < 0.7:await self._optimize_retrieval_strategy(interaction)# 用户行为分析await self._analyze_user_behavior(interaction)
12.4 关键技术决策
在构建完整系统时,需要做一些权衡和取舍:
决策1:同步 vs 异步
同步模式: 优点:实现简单,用户等待即可得到结果 缺点:响应慢,用户体验差 适用:对实时性要求不高的场景异步模式: 优点:快速响应,可以流式输出 缺点:实现复杂,需要WebSocket或SSE 适用:对用户体验要求高的场景(推荐)
classResourceOptimizer: """资源优化器 - 连接池与批处理"""def__init__(self): self.llm_pool = LLMConnectionPool( max_size=10, max_requests=100, timeout=30 ) self.embedding_batcher = EmbeddingBatcher(batch_size=32) self.rerank_batcher = RerankBatcher(batch_size=16)asyncdefbatch_embedding(self, texts: List[str]) -> List[List[float]]:"""批处理向量化"""if len(texts) == 1:# 单条请求直接处理returnawait self.llm_pool.embedding(texts[0])# 批量请求 batches = [texts[i:i+32] for i in range(0, len(texts), 32)] batch_results = []for batch in batches:# 等待达到批处理大小或超时if len(batch) < 32:await asyncio.sleep(0.1) # 短时间等待更多请求 results = await self.llm_pool.batch_embedding(batch) batch_results.extend(results)return batch_resultsasyncdefoptimized_rerank(self, query: str, documents: List[str]) -> List[float]:"""优化重排序"""if len(documents) <= 3:# 文档少时直接单条处理returnawait self.reranker.rerank(query, documents)# 批量重排序 pairs = [[query, doc] for doc in documents] batch_scores = await self.rerank_batcher.batch_rerank(pairs)return batch_scores
决策2:缓存策略
L1缓存(内存): - 缓存高频Query的答案(Top-1000) - TTL:10分钟 - 命中率:约30% - 响应时间:<10msL2缓存(Redis): - 缓存检索结果(文档列表) - TTL:1小时 - 命中率:约50% - 响应时间:<50ms无缓存: - 完整流程重新执行 - 响应时间:1-3秒
classMultiLevelCache: """多级缓存系统 - 性能加速器"""def__init__(self): self.l1_cache = LRUCache(maxsize=1000) # 内存缓存 self.l2_cache = RedisCache() # Redis缓存 self.l3_cache = DiskCache() # 磁盘缓存asyncdefget_with_cache(self, key: str, generator: Callable, ttl: int = 300):"""多级缓存获取"""# L1: 内存缓存(最快) result = self.l1_cache.get(key)if result isnotNone: self.metrics.record_cache_hit('l1')return result# L2: Redis缓存 result = await self.l2_cache.get(key)if result isnotNone: self.l1_cache.set(key, result, ttl=60) # 回写到L1 self.metrics.record_cache_hit('l2')return result# L3: 磁盘缓存 result = await self.l3_cache.get(key)if result isnotNone:await self.l2_cache.set(key, result, ttl=ttl) self.l1_cache.set(key, result, ttl=60) self.metrics.record_cache_hit('l3')return result# 缓存未命中,生成新数据 result = await generator()# 异步回填缓存 asyncio.create_task(self._backfill_cache(key, result, ttl)) self.metrics.record_cache_miss()return resultasyncdef_backfill_cache(self, key: str, value: Any, ttl: int):"""异步回填缓存""" tasks = [ self.l1_cache.set(key, value, ttl=60), self.l2_cache.set(key, value, ttl=ttl), self.l3_cache.set(key, value, ttl=ttl*24) # 磁盘缓存时间更长 ]await asyncio.gather(*tasks)
决策3:降级策略
当系统负载过高或部分模块故障时,如何保证基本可用:
降级级别1(轻度降级): - 关闭GraphRAG(耗时最多) - 关闭Rerank(GPU资源紧张时) - 效果下降:约5-10% - 性能提升:约50%降级级别2(中度降级): - 只使用向量检索(关闭BM25) - 关闭联网搜索 - 效果下降:约15-20% - 性能提升:约70%降级级别3(重度降级): - 直接返回缓存结果 - 或返回固定话术:"系统繁忙,请稍后再试" - 确保系统不崩溃
classGracefulDegradation: """优雅降级策略 - 保证基本可用性"""def__init__(self): self.degradation_levels = {'level_1': { # 轻度降级'disable_graph_rag': True,'disable_rerank': True,'llm_strategy': 'speed','expected_impact': '5-10%质量下降' },'level_2': { # 中度降级 'retrieval_strategy': 'vector_only','disable_web_search': True,'llm_strategy': 'speed','max_retrieval_docs': 3,'expected_impact': '15-20%质量下降' },'level_3': { # 重度降级'enable_cache_only': True,'fallback_response': '系统繁忙,请稍后再试','expected_impact': '仅提供基础服务' } }defget_degradation_plan(self, system_status: Dict) -> Dict:"""根据系统状态获取降级方案"""if system_status['error_rate'] > 0.1or system_status['load'] > 0.9:return self.degradation_levels['level_3']elif system_status['response_time_p95'] > 5.0:return self.degradation_levels['level_2'] elif system_status['gpu_utilization'] > 0.8:return self.degradation_levels['level_1']else:return {} # 不降级asyncdefexecute_with_degradation(self, query: str, plan: Dict) -> Dict:"""执行带降级的查询处理"""try:returnawait self.full_pipeline.process(query)except Exception as e: logging.warning(f"Pipeline failed, applying degradation: {e}")# 根据降级级别执行相应策略if plan.get('enable_cache_only', False): cached_result = await self.cache_manager.get_cached_response(query)if cached_result:return cached_resultelse:return self._build_fallback_response(plan)# 简化流程处理returnawait self.simplified_pipeline.process(query, plan)
12.5 生产环境最佳实践
(一)性能优化清单
✅ 检索优化 - 使用HNSW/IVF等高效索引算法 - 限制检索文档数(Top-20通常足够) - 并行执行多路检索✅ 生成优化 - 使用Stream模式,边生成边返回 - 控制生成长度,避免过长答案 - 使用更快的模型(qwen-turbo vs qwen-plus)✅ 缓存优化 - 多级缓存策略 - 预热高频Query - 智能失效策略(而非固定TTL)✅ 资源优化 - 使用连接池,避免频繁建连 - GPU批量推理(Embedding、Rerank) - 异步I/O,提高并发能力
classObservabilityPlatform: """可观测性平台 - 系统的健康监测仪"""def__init__(self): self.metrics_collector = MetricsCollector() self.tracing_system = TracingSystem() self.log_aggregator = LogAggregator() self.alert_manager = AlertManager()defsetup_monitoring(self):"""设置监控体系"""# 关键业务指标 self.metrics_collector.register_metrics(['rag.response_time', # 响应时间'rag.retrieval_recall', # 检索召回率'rag.generation_quality', # 生成质量'rag.error_rate', # 错误率'rag.cache_hit_rate', # 缓存命中率'rag.user_satisfaction'# 用户满意度 ])# 性能指标 self.metrics_collector.register_performance_metrics(['system.cpu_usage','system.memory_usage', 'system.gpu_utilization','network.latency' ])asyncdefrecord_trace(self, request_id: str, span_name: str, metadata: Dict):"""记录调用链跟踪""" trace_data = {'request_id': request_id,'span_name': span_name,'start_time': time.time(),'metadata': metadata }await self.tracing_system.record_span(trace_data)defsetup_alerts(self):"""设置告警规则""" alert_rules = [ {'name': '高错误率告警','metric': 'rag.error_rate','condition': '> 0.05', # 错误率超过5%'severity': 'critical','cooldown': 300# 5分钟冷却 }, {'name': '响应时间告警', 'metric': 'rag.response_time.p95','condition': '> 3.0', # P95超过3秒'severity': 'warning','cooldown': 600 }, {'name': '检索质量下降','metric': 'rag.retrieval_recall','condition': '< 0.7', # 召回率低于70%'severity': 'warning', 'cooldown': 1800 } ]for rule in alert_rules: self.alert_manager.add_rule(rule)
(二)可观测性建设
日志体系: - 请求日志:每个请求的完整链路 - 错误日志:异常堆栈,便于排查 - 性能日志:各模块耗时,便于优化指标监控: - QPS:每秒请求数 - RT:平均响应时间(P50/P90/P99) - 错误率:4xx/5xx错误占比 - 召回率:检索成功率 - 生成质量:人工抽样评分告警机制: - 错误率 > 5%:P0告警,立即处理 - RT > 3秒:P1告警,30分钟内响应 - QPS突增200%:P2告警,关注资源
(三)成本优化策略
LLM成本优化:1. 使用更便宜的模型 - Embedding:text-embedding-v1 vs v4(便宜3倍) - 生成:qwen-turbo vs deepseek-v3(便宜5倍)2. 减少调用次数 - 增加缓存命中率 - Query改写仅在必要时调用 - 批量处理(如Embedding批量化)3. 优化Prompt长度 - 只传递必要的文档(Top-3 vs Top-10) - 压缩文档内容(去除冗余)预估成本(按每天1万次查询):- Embedding: $5/天- Rerank: $3/天- 生成: $15/天- 总计: 约$700/月
classCostOptimizer: """成本优化器 - 智能控制运营成本"""def__init__(self, budget_limits: Dict): self.budget_limits = budget_limits self.daily_spending = 0 self.usage_patterns = {}asyncdefoptimize_llm_usage(self, query: str, context: Dict) -> Dict:"""优化LLM使用成本""" optimization_strategies = {'context_compression': self._compress_context,'model_selection': self._select_cost_effective_model,'cache_optimization': self._optimize_cache_usage,'batch_processing': self._enable_batch_processing } optimized_plan = {}for strategy_name, strategy_func in optimization_strategies.items(): optimized_plan.update(await strategy_func(query, context))return optimized_planasyncdef_select_cost_effective_model(self, query: str, context: Dict) -> Dict:"""选择性价比最优的模型""" query_complexity = self._assess_query_complexity(query) user_value = self._assess_user_value(context['user_tier'])if query_complexity == 'simple'or user_value == 'low':return {'llm_model': 'qwen-turbo', 'max_tokens': 500}elif query_complexity == 'medium':return {'llm_model': 'deepseek-v3', 'max_tokens': 1000}else: # complex query for high-value userreturn {'llm_model': 'deepseek-v3', 'max_tokens': 2000}def_assess_query_complexity(self, query: str) -> str:"""评估查询复杂度""" complexity_indicators = {'simple': ['多少钱', '在哪', '营业时间'],'medium': ['怎么去', '推荐', '有什么'],'complex': ['对比', '规划', '为什么', '哪个更好'] }for level, indicators in complexity_indicators.items():if any(indicator in query for indicator in indicators):return levelreturn'simple' # 默认简单
12.5 灰度发布与监控
灰度发布流程:
Day 1:内部测试- 范围:团队内部- 流量:0.1%- 目标:发现明显bugDay 2-3:小范围灰度- 范围:100个真实用户- 流量:1%- 目标:验证基本功能Day 4-7:扩大灰度- 范围:1000个用户- 流量:10%- 目标:收集用户反馈Day 8-14:大规模灰度- 范围:5000个用户- 流量:50%- 目标:AB测试,对比效果Day 15+:全量发布- 流量:100%- 持续监控一周
第十三章:实战打卡任务(从0到1落地)
本章提供循序渐进的实战打卡任务,帮助你将前12章知识系统化落地。建议按顺序完成,每个任务都配有「验收标准」与「可选加分」。
13.1 任务一:最小RAG原型
- 目标:完成一个可用的“问文档”最小闭环(上传PDF → 检索 → 生成)
- 要求:
- 使用任意Embedding模型(如 bge-small/gte-small)构建向量库
- 实现Top-K检索与基础Prompt拼接
- 支持回答来源标注(返回片段页码/段落)
- 验收标准:
- 输入“乐园门票退改政策?”能返回包含来源标注的答案(Top-3片段)
13.2 任务二:检索增强与Rerank
- 目标:在最小原型基础上加入BM25并行召回与Rerank精排
- 要求:
- BM25 + 向量双路检索,并实现结果合并
- 引入轻量Rerank模型(如 bge-reranker-base)将Top-50重排为Top-5
- 记录各阶段命中与耗时日志
- 验收标准:
- 在“创极速光轮身高要求是什么?”“刺激类项目有哪些?”等问题上,效果相较任务一有明显提升
13.3 任务三:Query改写与联网判断
- 目标:面向真实用户Query的鲁棒性优化
- 要求:
- 实现“纠错、实体补全、多样化、多跳拆分、结构化改写”五类改写中的任意三类
- 增加联网判断器:对包含“今年、现在、最新、票价变动”等时效词的Query触发联网搜索
- 联网结果与本地KB结果进行信息融合(去重、冲突消解、优先级规则)
- 验收标准:
- 对“现在周末门票多少钱?”类问题可稳定触发联网,答案包含时间戳说明
13.4 任务四:GraphRAG小试牛刀
- 目标:为“全局对比、关系推理”类问题引入图谱能力
- 要求:
- 从样例文档中抽取实体与关系,构建最小知识图(≥200个实体/关系)
- 基于社区摘要回答“所有过山车对比”“和X相似的项目”等全局性问题
- 为Local/Global两种检索模式设计切换规则
- 验收标准:
- “迪士尼所有过山车对比”返回包含统一维度(刺激度/身高/时长/人群)的对比表
13.5 任务五:上线前打磨
- 目标:面向生产的性能、稳定性与可观测性
- 要求:
- 引入两级缓存(内存+Redis)
- 建立全链路耗时/命中率/错误率指标与告警
- 实现降级策略(关闭GraphRAG、关闭Rerank、仅返回缓存)
- 验收标准:
- P50 < 1.2s,P90 < 2.5s;错误率 < 2%;缓存命中率 > 35%
第十四章:部署指南(Windows 友好)
本章给出从开发到生产的推荐部署路径,兼顾 Windows 环境与容器化。
14.1 环境准备
- 系统:Windows 10/11 或 WSL2(推荐WSL2以获得更好性能)
- 依赖:
- Python 3.10+,pip,virtualenv
- CUDA/cuDNN(如需本地GPU推理)
- Redis(可选:缓存/队列)
- Node.js 18+(如需前端与SSE)
- 环境变量(示例):
-
OPENAI_API_KEY
/ DASHSCOPE_API_KEY / ZHIPU_API_KEY
-
RAG_EMBEDDING_MODEL
(如 bge-small-zh-v1.5)
-
RERANK_MODEL_NAME
(如 bge-reranker-base)
-
KB_DATA_DIR
、VECTOR_DB_PATH、BM25_INDEX_PATH
14.2 本地运行(纯Windows)
- 创建虚拟环境并安装依赖
- 准备样例文档(PDF/MD/TXT)并执行入库脚本
- 启动后端API(FastAPI/Flask)与前端(可选)
- 打开浏览器访问http://localhost:8000
常见问题: - Visual C++ Build Tools 未安装 → 安装 VS Build Tools(含C++桌面开发) - faiss-cpu 安装失败 → 先升级 pip 与 setuptools,或在 WSL2 使用 faiss-cpu
14.3 Docker 部署(推荐)
Dockerfile 关键建议: - 基础镜像使用python:3.10-slim,国内可换镜像源
-
分层安装依赖并缓存pip
-
将模型/索引路径挂载为卷,便于热更新
-
健康检查:/healthz 返回依赖服务状态(Redis/向量库/模型)
Compose 编排建议: - services:api、redis、worker(可选)、frontend(可选)
-
资源限制:为api与worker设置cpus与mem_limit
-
使用.env集中管理环境变量
14.4 云端部署与灰度
- 初期:单区单实例 + 负载均衡(SLB/ALB)
- 扩容:多实例横向扩展 + Redis 共享缓存
- 灰度:按用户ID或流量百分比路由至新版本
- 监控:接入 Prometheus + Grafana;重要指标上报到云监控
14.5 运行保障与排错清单
性能问题: - P95 > 3s:优先检查检索Top-K过大、Rerank耗时、联网超时
- CPU高/GPU低:I/O阻塞或批量太小,开启异步与批量化
稳定性问题: - 上游模型超时:设置timeout/retry/backoff与快速降级
- 依赖挂掉:健康检查失败即切走流量,使用熔断与限流
质量问题: - 幻觉:触发拒答模板与兜底话术
- 来源缺失:统一在后处理阶段强制附带来源
至此,完整的“RAG高级技术与最佳实践 | 迪士尼智能客服全案例”课程内容全部收官。推荐小伙伴们以“打卡任务”为主线完成系统落地。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型实战项目&项目源码👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)
👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)
👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)
为什么分享这些资料?
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 25
25 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)