AI大模型技术深度解析:小白程序员必备收藏,快速掌握智能客服实战技能
AI大模型技术深度解析:小白程序员必备收藏,快速掌握智能客服实战技能
本文深度解析AI大模型技术在智能客服场景下的应用,涵盖多渠道接入、意图与情绪识别、知识库构建、检索增强生成(RAG)、答案生成与重写等核心模块。结合模型选型建议、IT运维实战案例及前沿准确率提升方法,揭示AI赋能业务全过程,适合程序员快速掌握AI大模型技术。

1、全渠道接入与统一会话管理
现代智能客服系统的首要任务是打破渠道壁垒,为用户提供无缝、一致的服务体验。用户可能通过网页、移动App、社交媒体(如微信、微博)、即时通讯工具(如钉钉、飞书)乃至电话语音等多种方式发起咨询。如何高效地整合这些渠道,是系统设计的第一个挑战。

1.1 接入方式
一个全面的智能客服平台通常需要支持广泛的接入方式,以覆盖用户可能触达的所有触点。常见的接入渠道包括:
- Web/H5页面:通过内嵌聊天窗口(Web Widget)的方式,轻松集成到企业官网或移动网页中。
- 移动应用(App):通过SDK集成,实现与原生应用的深度融合。
- 社交媒体与即时通讯:对接微信公众号、企业微信、钉钉、飞书等平台的API,将客服能力延伸至用户日常使用的社交工具中。
- 电话语音:结合ASR(语音识别)和TTS(语音合成)技术,实现语音导航和智能语音应答(IVR)。
1.2 统一会话管理
多渠道接入的核心在于构建一个统一的会话管理中心。该中心负责将来自不同渠道的用户请求标准化,并路由到后续的处理模块。这通常涉及到以下关键技术:
- Omnichannel(全渠道)架构:设计一个能够聚合所有渠道消息的中心化平台,为客服坐席提供一个统一的工作台,无论用户从哪个渠道进入,都能看到完整的历史对话记录和用户画像。
- 智能路由与分配:基于预设规则(如用户类型、问题领域、渠道来源)或实时负载情况,将用户会话智能地分配给最合适的机器人或人工坐席。例如,B站的自研客服系统就采用了均衡分配策略来优化坐席的工作效率 。
| 渠道类型 | 技术实现 | 关键考量 |
|---|---|---|
| 网页/H5 | JavaScript SDK, WebSocket | 兼容性、加载速度、UI/UX自定义 |
| 移动App | iOS/Android SDK | 原生体验、推送通知、权限管理 |
| 社交平台 | 平台开放API | API版本兼容、消息格式转换、授权管理 |
| 电话语音 | ASR/TTS, SIP/WebRTC | 语音识别准确率、语音合成自然度、通话稳定性 |
2、意图识别与情绪感知:读懂用户的“心声”
准确理解用户的查询意图是智能客服的核心能力。一个看似简单的问题,背后可能隐藏着复杂的需求。同时,感知用户的情绪状态,对于提供人性化服务、化解潜在矛盾至关重要。

2.1 意图识别技术
意图识别技术经历了从基于规则到基于模型的演进:
- 早期方法:主要依赖 关键词匹配 和 正则表达式 。这种方法简单直接,对于一些固定问法非常有效,但泛化能力差,难以应对口语化和多变的表达方式。
- 机器学习方法:随着自然语言处理(NLP)技术的发展,基于 文本分类模型 (如SVM、朴素贝叶斯)的方法开始普及。通过对大量标注数据进行训练,模型可以学习到不同意图的语言模式。
- 深度学习与大语言模型(LLM):当前最前沿的方法是利用 预训练语言模型 (如BERT、GPT系列)进行微调(Fine-tuning)。这些模型拥有强大的语义理解能力,能够捕捉到句子中更深层次的含义,从而在处理复杂、模糊的查询时表现出更高的准确率。
2.2 情绪识别技术
情绪识别是构建高情商智能客服的关键。它旨在从用户的言语、文字甚至声音中判断其情绪状态,如高兴、悲伤、愤怒、焦虑等。
“现代大模型通常集成了情绪识别技术,能够根据用户的语言和表达推断其情绪状态,从而调整回应策略。这种能力使得智能客服在处理客户的问题时更具同理心和人性化。”
实现方式 :
- 基于文本:使用专门的情绪分类模型(如基于StructBERT的模型)对用户输入的文本进行分析。这类模型可以识别包括恐惧、愤怒、厌恶、喜好、悲伤、高兴、惊讶在内的多种情绪。
- 基于语音:在语音交互场景中,通过分析语音的音调(Pitch)、语速(Speed)、音量(Volume)和停顿等声学特征来判断情绪。
- 多模态融合:结合文本、语音、甚至表情(在视频客服中)等多维度信息进行综合判断,准确率更高。
应用价值 :
- 动态调整服务策略:当识别到用户负面情绪(如愤怒、焦虑)时,系统可以自动采用更委婉、安抚性的语气进行回复,并优先转接人工坐席。
- 服务质量监控:自动标记带有负面情绪的会话,供后续复盘分析,持续改进服务质量。
- 坐席辅助:在人工坐席服务时,实时提示用户的情绪变化,帮助坐席更好地应对。
2.3 优化核心:问题重写(Query Rewriting)
为了进一步提升意图识别和后续检索的准确性, 问题重写(Query Rewriting) 技术至关重要。
其核心思想是利用LLM将用户原始的、可能不规范的查询,改写成更清晰、更标准化的查询语句。这在处理多轮对话中的指代消解(如“它怎么样?”)和省略补全(如“有优惠吗?”)时尤为重要。
“Query 改写是指在 RAG 系统的检索阶段之前,对用户输入的原始查询(Query)进行一系列处理、扩展或重构的技术,旨在生成一个或多个对检索器(Retriever)更友好、信息更丰富的查询。”

常见的Query Rewriting策略包括:
- 指代消解:将“它”、“那个”等代词替换为对话上文中明确指代的对象。
- 省略补全:根据上下文补全用户查询中省略的成分。
- 多意图拆分:将一个包含多个意图的复杂问题拆解成多个独立的子问题,如“我想查订单,顺便问下退货政策”。
- HyDE (Hypothetical Document Embeddings):利用LLM生成一个与问题相关的假设性答案文档,并将其与原始问题一起编码,以更好地匹配知识库中的文档。
通过这些技术,系统可以更精准地捕捉用户的真实需求,为后续的知识库检索奠定坚实的基础。
3、知识库构建:智能客服的“大脑”
知识库是智能客服系统的知识来源,其质量直接决定了服务水平的上限。构建一个高质量、易于维护的知识库是一项系统工程。

3.1 知识的来源与表示
知识库的内容可以来自多种渠道,包括但不限于:
- 结构化数据:如产品数据库、订单系统、用户信息表等。
- 半结构化数据:如FAQ文档、产品手册、API文档等。
- 非结构化数据:如网页、PDF报告、历史客服对话记录等。
这些异构的数据需要被处理成机器可理解的格式。常见的方式是构建 QA对(Question-Answer Pairs) ,即将常见问题与其标准答案进行配对。对于更复杂的知识,可以构建 知识图谱(Knowledge Graph) ,用实体、属性和关系来表示知识,从而支持更复杂的推理问答。
3.2 文档分块(Chunking)策略
在将长文档(如产品手册、政策文件)纳入知识库时,必须将其分割成更小的、语义完整的“块”(Chunks)。分块的质量直接影响后续检索的准确性。一个好的分块应该既包含足够的上下文信息,又足够聚焦于一个特定的主题。
| 分块策略 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 固定大小分块 | 按固定字符数或Token数切分。 | 实现简单,计算开销小。 | 容易切断完整的语义单元,破坏上下文。 |
| 递归字符分块(父子分块) | 按段落、句子、单词等层次递归切分。 | 能更好地保留文本的结构和语义。 | 对文本格式有一定依赖。 |
| 特定文档分块 | 针对Markdown、代码等特定格式进行优化。 | 能利用文档的结构化信息,分块更精准。 | 需要为不同文档类型开发特定解析器。 |
| 语义分块 | 基于嵌入向量的相似度进行聚类分块。 | 块内语义一致性高。 | 计算成本较高,对嵌入模型质量敏感。 |
| 代理分块 | 利用大语言模型(LLM)来决定分块边界。 | 模拟人类的理解方式,分块质量最高。 | 成本最高,延迟较大。 |
实践中,通常会采用混合策略,例如先按文档结构进行初步分割,再对长段落进行语义分块,以在效果和成本之间取得平衡。
3.3 多知识库管理
当企业业务复杂,涉及多个产品线或部门时,单一的知识库难以满足需求。此时,需要构建多知识库体系,并采用查询路由(Query Routing)技术。路由模块会根据用户问题的语义,智能地判断该问题属于哪个知识领域,然后将查询分发到对应的知识库进行检索。
“多文档agent是一种先进的检索增强生成(RAG)架构,它采用分层设计来处理多个领域或文档集的查询。这种系统特别适用于处理大规模、多领域的知识库,能够提高检索精度和回答质量。”
实现上,可以为每个知识库生成一个描述性的元数据,然后计算用户查询与这些描述的语义相似度,从而选择最相关的知识库。这种方式避免了在所有知识库中进行全局搜索,显著提升了检索效率和准确性。
4、RAG:连接问题与答案的桥梁
检索增强生成(Retrieval-Augmented Generation, RAG)是当前构建智能问答系统的核心技术范式。它结合了检索系统的高效性和大语言模型的生成能力,旨在提供既准确又流畅的回答。

4.1 检索(Retrieval)
检索阶段的目标是从庞大的知识库中快速、准确地找出与用户问题最相关的几个知识片段。这一阶段通常采用 向量检索 技术。
- 文本嵌入(Embedding):将知识库中的所有文本块(Chunks)和用户的查询都通过一个深度学习模型(如BERT、Sentence-BERT等)转换为高维向量。这些向量能够捕捉文本的语义信息。
- 向量搜索:利用专门的向量数据库(如Milvus, Pinecone, FAISS)进行高效的相似度搜索。通过计算查询向量与知识库中所有向量的余弦相似度或欧氏距离,找出最相似的Top-K个文本块。
4.2 重排(Re-ranking)
初步检索出的Top-K个结果可能存在“假阳性”,即虽然向量相似度高,但内容并非用户真正想要的。
为了进一步提升精度,通常会引入一个 重排(Re-ranker) 模型。重排模型(通常是更强大的交叉编码器模型)会对Top-K个候选文本块与用户查询进行更精细的匹配度打分,然后重新排序,选出最终用于生成答案的上下文。

5、答案生成与思维链(CoT)
在获取到最相关的知识片段后,就进入了答案生成阶段。这一阶段的目标是基于检索到的上下文,生成一个自然、流畅、直接回答用户问题的答案。
5.1 基于LLM的答案生成
现代智能客服系统普遍采用大语言模型(LLM)作为生成器。系统会将用户原始问题、重写后的问题以及检索到的知识片段组合成一个精心设计的 提示(Prompt) ,然后输入给LLM。
一个典型的Prompt结构如下:
你是一个专业的IT运维客服机器人。请根据以下提供的上下文信息,用清晰、简洁的语言回答用户的问题。如果上下文中没有相关信息,请引导用户提供更多信息或建议转接人工支持。
[上下文]
{retrieved_chunks}
[用户问题]
{user_query}
[你的回答]

5.2 思维链(Chain-of-Thought)与答案优化
为了让LLM生成更可靠、更具逻辑性的答案,可以采用 思维链(Chain-of-Thought, CoT) 提示技术。通过在Prompt中加入一系列推理步骤的示例,引导LLM在生成最终答案前,先进行一步步的思考和分析。这对于需要进行计算、比较或逻辑推理的复杂问题尤其有效 。
生成的答案还需要经过一系列的后处理和优化,包括:
- 答案重写:对LLM生成的初步答案进行润色,使其语气更符合品牌形象,或根据用户情绪进行调整。
- 事实一致性校验:检查生成的答案是否与提供的上下文信息一致,避免“幻觉”问题。
- 敏感信息过滤:过滤掉可能包含的个人隐私、不当言论等内容。
6、IT运维场景实战:模型选型与CoT示例
以IT运维领域的智能客服为背景,提供具体的模型选型建议和场景示例,展示技术在实践中的应用。

6.1 模型选型推荐
选择合适的大语言模型是平衡成本与效果的关键。以下是针对不同模块的推荐:
| 模块 | 推荐模型 | 优势 | 成本 | 适用场景 |
|---|---|---|---|---|
| 意图识别 | Qwen-turbo / GLM-4-Flash | 中文理解能力强,推理速度快,成本极低,适合快速分类。 | 低 | 通用高并发场景。 |
| Query改写 | Claude 3.5 Sonnet / Qwen-long | 对复杂、模糊查询的理解和改写能力出色,上下文窗口长。 | 中 | 处理多轮对话、复杂查询。 |
| 答案生成 | Qwen 2.5 Max / GPT-4.1-mini | 生成质量高,逻辑性强,能遵循复杂指令。 | 中-高 | 需要高质量、个性化回答的场景。 |
| 情绪识别 | StructBERT / 通用LLM | StructBERT是专用模型,成本低;通用LLM可通过Prompt实现,灵活性高。 | 低 | 所有需要情感交互的场景。 |
6.2 CoT问题重写场景示例
场景一:系统访问缓慢
用户原始问题: “OA系统现在访问比较慢”
LLM的CoT推理与改写过程:
- 识别核心问题:用户反馈“OA系统”存在“访问慢”的问题。
- 分析隐含意图:用户的核心意图是寻求帮助解决OA系统性能问题,属于“故障排查”类别。
- 分解问题:“访问慢”是一个模糊的描述,可能的原因包括:
a. 用户自身的网络问题。b. OA系统服务器负载过高。c. OA系统特定功能模块出现Bug。d. 数据库查询缓慢。 - 构建结构化查询:为了从知识库中检索到最相关的解决方案,需要将模糊问题转化为一个更具体、包含多种可能性的查询。可以将问题重写为多个并列的关键词组或一个更详细的描述。
- 生成最终改写Query:
“OA系统性能问题排查,包括网络诊断、服务器负载检查、应用模块故障、数据库性能分析”
后续动作:使用这个改写后的Query在知识库中检索,可以精准匹配到《OA系统故障排查手册》、《网络连接问题自查指南》等文档。
场景二:错别字与口语化表达用户原始问题: “我如何开头VPN账号?”LLM的CoT推理与改写过程:
1.识别核心实体与动作:实体是“VPN账号”,动作是“开头”。
2.进行拼写和语法纠错:在中文语境下,“开头”很可能是“开通”的口误或拼写错误。
3.确认核心意图:用户的意图是“申请”或“开通”一个新的VPN账号。
4.补全必要信息:开通VPN账号通常需要关联员工身份、申请流程、审批人等信息。
5.生成最终改写Query:“新员工申请开通VPN账号的流程和所需材料”
后续动作:该Query能精确匹配到知识库中的《VPN账号申请标准作业程序(SOP)》文档。
7、准确率提升的道与术
将智能客服的准确率从可用(如80%)提升到可靠(如95%以上)是工程实践中的核心挑战。这需要系统性的方法论和对技术细节的深入打磨。

7.1 五大实战策略
根据业界领先实践,提升准确率需要综合施策 :
- 高质量数据是基石:再强的模型也无法处理“垃圾数据”。投入人工对知识库文档进行清洗、校对和标注是必不可少的“苦活累活”。确保输入给LLM的信息是完整、准确、易于理解的。
- 架构简单,技术深入:避免为了解决局部问题而过度设计复杂的系统架构(如多层LLM调用)。相反,应该深入研究每个核心模块(如检索、重排)的底层技术,对症下药。例如,与其用LLM做粗糙的分类来缩小检索范围,不如深入优化向量检索算法本身 。
- 优化检索召回:
- 混合检索:结合使用传统的关键词检索(如BM25)和向量检索。BM25在处理关键词匹配上仍有优势,而向量检索擅长语义理解。使用如Elasticsearch等成熟的搜索引擎来优化BM25,效果远超向量数据库自带的“玩具版”实现 。
- 多路召回与重排:从多个来源(如FAQ库、文档库、历史问答)进行召回,并用一个更强大的重排模型(Re-ranker)对所有召回结果进行统一排序,优中选优。
- 精细化的Prompt工程:针对不同任务(意图识别、Query改写、答案生成)设计高度优化的Prompt。使用CoT、Few-shot示例等技巧,充分激发LLM的能力。
- 建立评估与迭代闭环:建立一套自动化的评估框架,定期对线上真实问题进行回归测试。对识别错误、回答不准确的案例进行根因分析,并将其作为优化数据,持续迭代模型和知识库。
7.2 “反共识”经验
“第一性原理>一切开源框架。无需迷信Dify/Coze/LangChain!这些产品大多以Agent早期某些学术思想、学术Demo为目标构建,而学术Demo不等于企业生产。”
成功的实践者往往敢于挑战主流框架的局限,基于第一性原理(准确率 = 输入质量 × 模型能力 × 透明管道)对系统进行大胆改造,以满足生产环境的严苛要求。
8、写在最后
构建一个先进的AI智能客服系统是一个复杂的系统工程,它融合了自然语言处理、信息检索、机器学习和大规模系统设计等多个领域的知识。从前端的多渠道接入,到核心的意图识别、知识库构建和RAG流程,再到最终的答案生成和性能优化,每一个环节都存在着丰富的技术细节和优化空间。

未来的发展趋势将更加聚焦于 多模态交互 (结合文本、语音、图像)、 主动式服务 (预测用户需求并主动提供帮助)以及 情感智能 (理解并响应用户情绪)。随着大模型技术的不断成熟和成本的降低,智能客服系统将变得更加“人性化”,从一个简单的问答工具,演变为能够真正理解、帮助并关怀用户的智能伙伴。
智能运维的核心不是学会使用几个AI工具,核心是:在理解AI大模型原理的基础上,深度理解业务,让技术与AI融合。
最后
近期科技圈传来重磅消息:行业巨头英特尔宣布大规模裁员2万人,传统技术岗位持续萎缩的同时,另一番景象却在AI领域上演——AI相关技术岗正开启“疯狂扩招”模式!据行业招聘数据显示,具备3-5年大模型相关经验的开发者,在大厂就能拿到50K×20薪的高薪待遇,薪资差距肉眼可见!
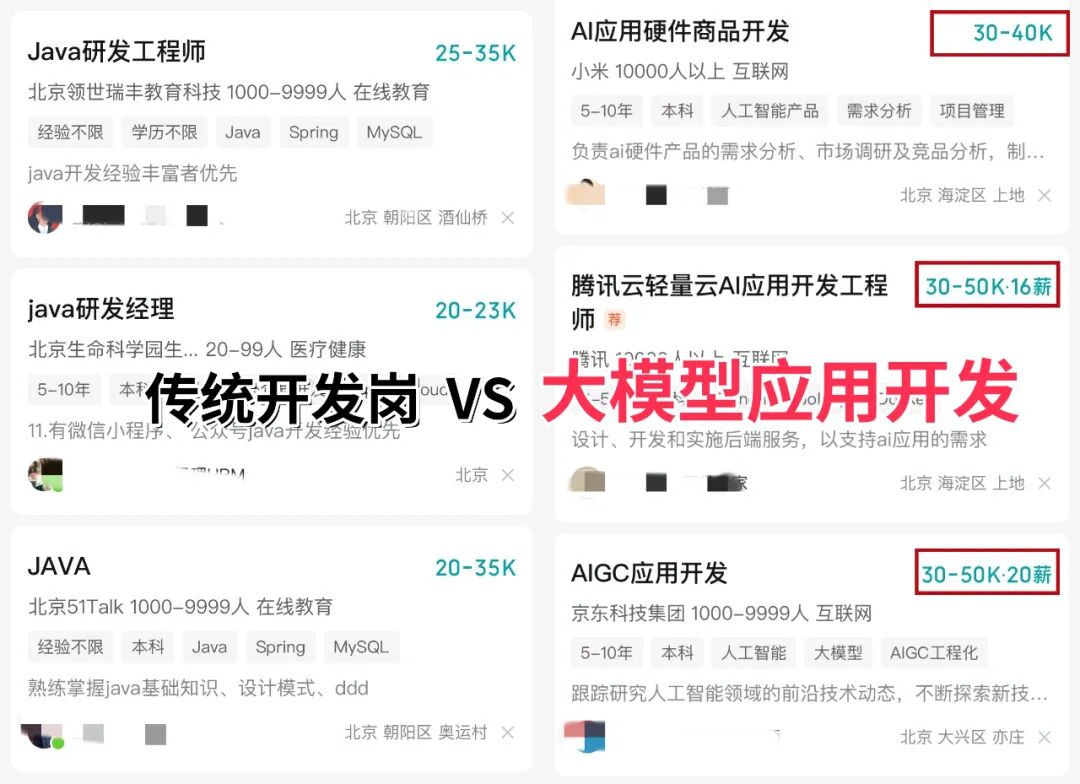
业内资深HR预判:不出1年,“具备AI项目实战经验”将正式成为技术岗投递的硬性门槛。在行业迭代加速的当下,“温水煮青蛙”式的等待只会让自己逐渐被淘汰,与其被动应对,不如主动出击,抢先掌握AI大模型核心原理+落地应用技术+项目实操经验,借行业风口实现职业翻盘!
深知技术人入门大模型时容易走弯路,我特意整理了一套全网最全最细的大模型零基础学习礼包,涵盖入门思维导图、经典书籍手册、从入门到进阶的实战视频、可直接运行的项目源码等核心内容。这份资料无需付费,免费分享给所有想入局AI大模型的朋友!

👇👇扫码免费领取全部内容👇👇

部分资料展示
1、 AI大模型学习路线图

2、 全套AI大模型应用开发视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、 大模型学习书籍&文档

4、 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、大模型大厂面试真题
整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题,涵盖基础理论、技术实操、项目经验等维度,每道题都配有详细解析和答题思路,帮你针对性提升面试竞争力。


6、大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
- 👇👇扫码免费领取全部内容👇👇

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)