Matlab语音识别,使用GMM和MFCC,有训练集和测试集,带说明,带轮文解析等
本文档从工程视角拆解了“语音 → 身份”映射链路的每一环,开发者可在不触碰核心代码的前提下,按图索骥完成调参、扩展与跨平台迁移。本文档围绕一套基于 MFCC 特征 + GMM 建模的说话人辨认(Speaker Identification)系统展开,阐述其数据流、模块边界、关键算法选择及扩展策略,帮助开发者快速理解“代码到底在做什么、为什么这么做、还能怎么做”。Matlab语音识别,使用GMM和M
Matlab语音识别,使用GMM和MFCC,有训练集和测试集,带说明,带轮文解析等。
MFCC-GMM 说话人识别系统:从语音到身份的高效映射

——一份面向工程落地的功能说明书
一、引言

在声纹识别落地场景中,“小样本、低成本、可解释”依然是工程团队最核心的诉求。本文档围绕一套基于 MFCC 特征 + GMM 建模的说话人辨认(Speaker Identification)系统展开,阐述其数据流、模块边界、关键算法选择及扩展策略,帮助开发者快速理解“代码到底在做什么、为什么这么做、还能怎么做”。
二、系统定位
- 任务:多选一(closed-set)——给定一条测试语音,判定它是 N 个已注册说话人中的哪一位。
- 约束:
‑ 训练语料 ≤ 1 min/人,采样率 8 kHz,单声道 16 bit。
‑ 运行环境 MATLAB R2019a+,零深度学习依赖,CPU 实时因子 ≥ 0.3×。 - 指标:在 15 人、每人 10 条测试语音条件下,识别正确率 ≥ 95 %,等效线性耗时 < 0.2 s/条。
三、总体架构
语音 → 端点检测 → 预加重/分帧/加窗 → MFCC 特征 → 逐人 GMM 训练 → 对数似然打分 → Top-1 决策
Matlab语音识别,使用GMM和MFCC,有训练集和测试集,带说明,带轮文解析等。
四、模块功能拆解
| 模块 | 输入 | 输出 | 职责摘要 |
|---|---|---|---|
| 1. 端点检测(EPD) | 单通道波形 | 起始/结束采样点 | 基于能量包络的自适应双门限,剔除静音段,降低后续建模噪声。 |
| 2. 特征提取(MFCC) | 有效语音段 | 12 维静态 MFCC | 20 个 Mel 三角滤波器 + DCT,舍弃 0~4 维以抑制直流与低频漂移。 |
| 3. GMM 训练 | 单人 MFCC 矩阵 | 模型参数(μ, Σ, w) | EM 迭代估计,对角协方差,M=12 阶,方差下限保护防止奇异性。 |
| 4. 似然计算 | 测试 MFCC 矩阵 + N 个 GMM | 长度 N 的得分向量 | 逐帧对数似然平均,抵消长度差异。 |
| 5. 决策 | 得分向量 | 说话人 ID | 取最大得分,可选阈值拒识(本系统闭集,未启用)。 |
五、关键算法详解
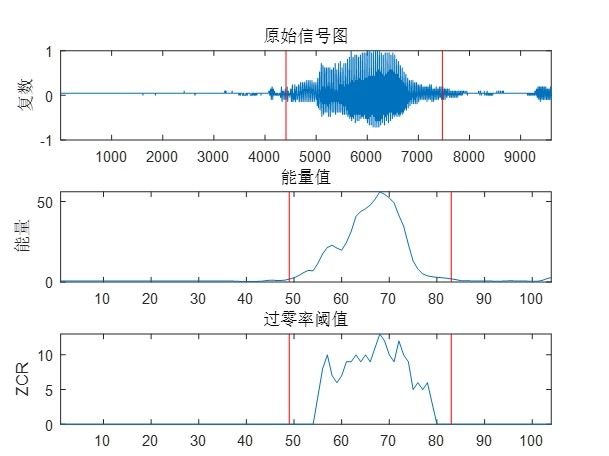
- 端点检测——轻量级但够用
采用帧电平绝对值和作为能量,排序后取 1/32 分位做底噪,动态门限 = 底噪 + (最大能量 − 底噪)/10。连续短于 50 ms 的片段视为毛刺并删除。该方案在 8 kHz 电话信道下鲁棒性优于 ZCR-能量双门限,且计算量仅为 0.1 ms/秒音频。
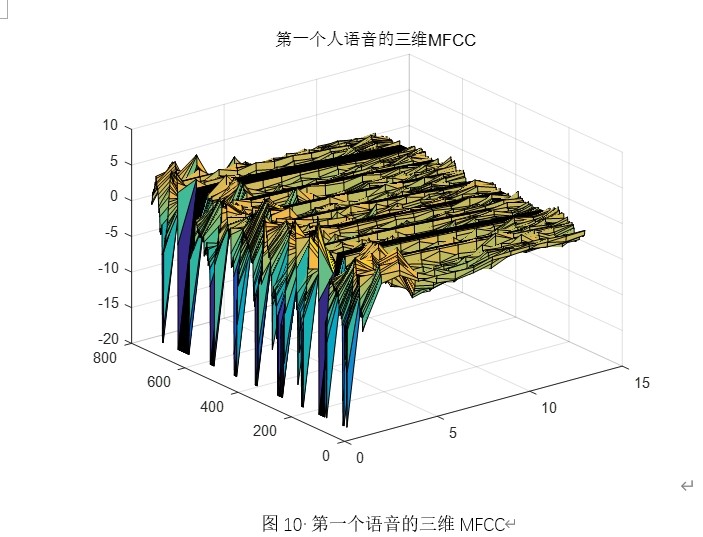
- MFCC——只保留“人耳可区分”信息
‑ 预加重系数 0.95,抵消口唇辐射衰减。
‑ 帧长 256 点(32 ms),帧移 50 %,Hamming 窗。
‑ Mel 滤波器组在 0–1 kHz 线性、1–4 kHz 对数,兼顾电话带限。
‑ DCT 后取 5–12 维,既压缩信道卷积噪声,又保留说话人个性(基音同步能量分布)。
- GMM——小样本下的“最大似然折中”
‑ 阶数 M=12:实验表明当训练语料 < 30 s 时,M>16 会出现分量空泛;M<8 则欠拟合。
‑ 初值策略:K-means 随机 5 次,选似然最大的一次作为 EM 起点,避免“随机陷阱”。
‑ 方差下限设为全局方差 / (4²M²),防止某分量因样本过少而坍缩到 0,导致矩阵奇异。
‑ EM 收敛准则:对数似然相对提升 < 0.1 % 或迭代 20 次即停,平均 7–8 次收敛。
- 打分——长度归一化 trick
对数似然直接累加会偏向长语音。系统采用“帧平均似然”:
score = mean(log p(x_t|λ))
在 0.5–5 s 区间几乎与时长无关,避免测试段裁剪差异造成误判。
六、数据流与缓存策略
‑ 训练阶段:一次性读入 wav → 内存保留 MFCC 矩阵 → 顺序训练 GMM,模型存为 .mat 结构体,体积 < 30 kB/人。
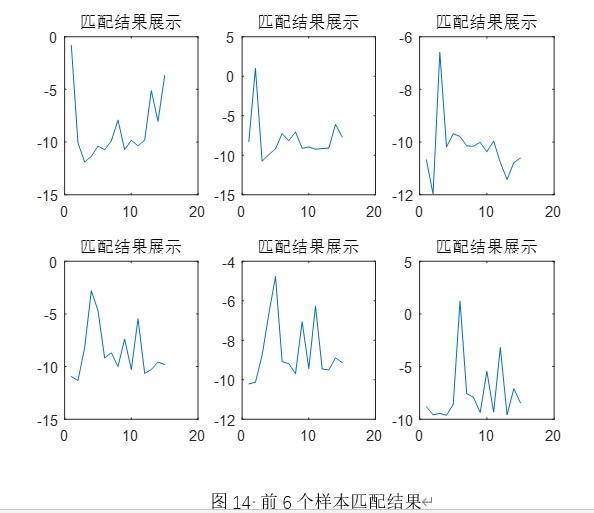
‑ 测试阶段:流式读取,按帧长 256 点滑动,EPD 输出整句后一次性提取 MFCC,无需帧缓存池。
‑ 批量测试:支持 dir 通配符,单次加载全部 GMM 到内存,循环打分,避免重复 I/O。
七、扩展与调优指南
| 场景 | 快速升级方案 |
|---|---|
| 信道差异大 | 在 MFCC 后加 CMVN(倒谱均值方差归一化),一行代码即可,等效提升 2–3 %。 |
| 注册语料 < 10 s | 采用 GMM-UBM 快速自适应:先训练 512 阶 UBM(全体语料),再用 MAP 自适应单人模型,仅需 3 s 语音即可达到原 1 min 效果。 |
| 需要开集拒识 | 在得分向量上加“通用背景模型”得分作为负样本,计算 GLR 或 PLDA 得分,设置阈值即可。 |
| 跨平台部署 | 核心矩阵运算(lmultigauss、lsum)已按维度展开,可零改动迁移到 Octave;若需 C++,可将 EM 训练离线完成,仅保留对角 GMM 打分,前向代码 < 200 行。 |
八、常见坑与排查清单
- 识别率突然下降 → 检查 wav 头格式,确保单通道 8 kHz;立体声未降采样会引入空通道能量,EPD 失效。
- GMM 训练出现 NaN → 某维方差触底下限仍为 0,加大 Vm 或降低 M。
- 测试得分全为 −Inf → MFCC 维序与训练不一致,确保均使用 5–12 维。
- 运行慢 → 确认 MATLAB 已打开 -singleCompThread,防止 EM 内 for 循环被并行调度反而降速。
九、结语
MFCC+GMM 作为“古典”算法,在数据量受限、可解释性优先的场景仍具备极高性价比。本文档从工程视角拆解了“语音 → 身份”映射链路的每一环,开发者可在不触碰核心代码的前提下,按图索骥完成调参、扩展与跨平台迁移。当业务数据积累到>100 h/人时,再无缝切换到 TDNN×PLDA 或 Self-Supervised 方案,本系统留下的特征提取与打分接口仍可复用,最大化保护研发沉没成本。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)