告别云端收费:Fun-ASR本地语音识别系统部署指南,数据隐私自己掌控
本文介绍了如何在星图GPU平台上自动化部署Fun-ASR钉钉联合通义推出的语音识别大模型语音识别系统(构建by科哥),实现本地化语音转文字。该方案让用户告别云端收费,将数据隐私完全掌控在自己手中,典型应用场景包括自动生成会议纪要、批量处理客服录音等,显著提升效率并保障信息安全。
告别云端收费:Fun-ASR本地语音识别系统部署指南,数据隐私自己掌控
你是否厌倦了为每一次语音转文字向云端服务商付费?是否担心敏感的会议录音、客户对话数据上传到第三方服务器?如果你的答案是肯定的,那么今天这篇文章就是为你准备的。
在AI应用遍地开花的今天,语音识别(ASR)技术已经相当成熟,但大多数企业仍然面临两个核心痛点:持续的成本支出和潜在的数据风险。每次调用云端API都要计费,长期下来是一笔不小的开支;而将包含商业机密或个人隐私的音频数据上传到外部服务器,更是让法务和IT部门夜不能寐。
有没有一种方案,能把专业的语音识别能力“搬回家”,在自己的电脑或服务器上运行,实现零持续成本、数据完全私有?答案是肯定的。今天我要介绍的 Fun-ASR,就是这样一个开源、本地化、企业级的语音识别解决方案。它由钉钉和通义实验室联合推出,专为中小企业量身打造,让你用一台普通的游戏显卡电脑,就能搭建起媲美商业服务的语音识别系统。
更重要的是,我将带你从零开始,一步步完成Fun-ASR的部署和使用。无论你是技术负责人、产品经理,还是对AI感兴趣的开发者,都能在30分钟内让这套系统跑起来,开始处理你的第一段音频。
1. 环境准备:5分钟搞定基础配置
在开始之前,我们先看看需要准备什么。Fun-ASR的设计非常友好,对硬件要求并不苛刻。
1.1 硬件要求
根据我的实测经验,以下配置可以流畅运行:
推荐配置(最佳体验)
- GPU:NVIDIA显卡,显存6GB以上(如RTX 3060/4060)
- CPU:Intel i5或AMD Ryzen 5以上
- 内存:16GB
- 存储:至少10GB可用空间
最低配置(也能运行)
- CPU:4核以上处理器
- 内存:8GB
- 存储:至少5GB可用空间
简单判断方法:如果你的电脑能流畅运行主流游戏或视频编辑软件,那么运行Fun-ASR绝对没问题。
1.2 软件环境
Fun-ASR基于Python开发,我们需要先准备好基础环境:
# 1. 确保已安装Python 3.8或更高版本
python --version
# 2. 如果没有Python,去官网下载安装
# https://www.python.org/downloads/
# 3. 建议使用conda或venv创建虚拟环境(可选但推荐)
# 使用conda
conda create -n funasr python=3.9
conda activate funasr
# 或使用venv
python -m venv funasr_env
# Windows
funasr_env\Scripts\activate
# Linux/Mac
source funasr_env/bin/activate
重要提示:如果你使用的是Windows系统,建议安装Git Bash或WSL来执行命令行操作,体验会更接近Linux环境。
1.3 获取Fun-ASR镜像
现在最方便的方式是通过预构建的Docker镜像来部署。CSDN星图镜像广场提供了现成的Fun-ASR镜像,包含了所有依赖和配置,真正做到开箱即用。
如果你已经有了镜像文件,可以直接加载;如果没有,可以按照以下步骤获取:
# 方法一:从Docker Hub拉取(如果可用)
docker pull your-funasr-image:latest
# 方法二:加载本地镜像文件
docker load -i funasr-webui.tar
# 方法三:通过CSDN星图镜像广场获取
# 访问 https://ai.csdn.net/ 搜索 "Fun-ASR"
镜像包含了完整的Fun-ASR WebUI系统,包括模型文件、Web界面和所有依赖库,大小约3-5GB。
2. 快速部署:一键启动你的私有语音识别服务
准备好了环境,我们现在开始部署。整个过程比你想的要简单得多。
2.1 启动Fun-ASR服务
假设你已经有了Fun-ASR的Docker镜像,启动命令非常简单:
# 启动Fun-ASR容器
docker run -d \
--name funasr-webui \
-p 7860:7860 \
--gpus all \
-v /path/to/your/data:/app/data \
funasr-webui:latest
# 或者直接运行启动脚本(如果镜像提供了)
bash start_app.sh
让我解释一下这些参数的含义:
-p 7860:7860:将容器的7860端口映射到主机的7860端口,这是WebUI的访问端口--gpus all:让容器可以使用所有GPU资源(如果没有GPU可以去掉这个参数)-v /path/to/your/data:/app/data:将本地目录挂载到容器内,用于持久化存储识别历史
如果没有Docker环境怎么办? 别担心,Fun-ASR也支持直接源码运行。你可以从GitHub克隆项目:
# 克隆项目
git clone https://github.com/alibaba-damo-academy/FunASR.git
cd FunASR
# 安装依赖
pip install -r requirements.txt
# 启动WebUI
python -m funasr.bin.funasr_webui
2.2 验证服务状态
启动后,打开浏览器访问 http://localhost:7860(如果你在本地运行)或 http://你的服务器IP:7860(如果在远程服务器运行)。
你应该能看到类似这样的界面: 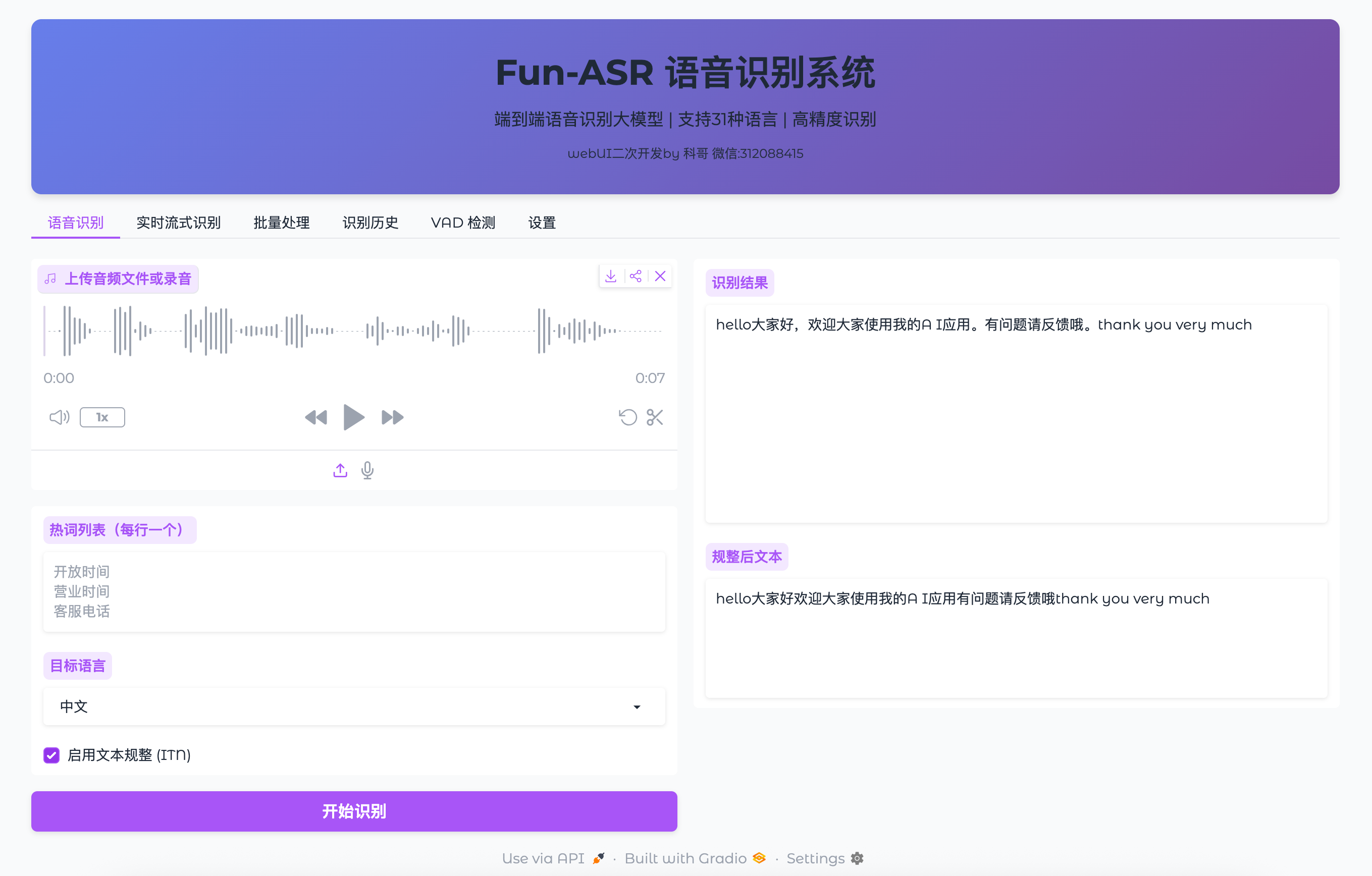
如果页面正常加载,恭喜你!Fun-ASR已经成功运行了。如果遇到问题,可以查看终端输出的日志信息,通常会有明确的错误提示。
2.3 首次使用配置
第一次使用时,系统可能需要几分钟来下载和加载模型文件。Fun-ASR默认使用 Fun-ASR-Nano-2512 模型,这是一个25亿参数的轻量级模型,在精度和速度之间取得了很好的平衡。
在系统设置中,你可以进行一些基础配置:
-
计算设备选择:
- 如果有NVIDIA显卡,选择"CUDA (GPU)"
- 如果没有GPU,选择"CPU"
- 如果是苹果M系列芯片,选择"MPS"
-
模型设置:
- 模型路径会自动显示
- 确保模型状态显示为"已加载"
-
性能设置:
- 批处理大小:保持默认1即可
- 最大长度:512足够大多数场景使用
配置完成后,点击"保存设置",系统会重新加载模型。现在,一切准备就绪,我们可以开始实际使用了。
3. 核心功能实战:从单个文件到批量处理
Fun-ASR提供了6个核心功能模块,覆盖了从简单试用到批量生产的各种场景。让我们逐一探索。
3.1 语音识别:处理单个音频文件
这是最基础也是最常用的功能。假设你有一段会议录音需要转写成文字。
操作步骤:
-
上传音频文件
- 点击"上传音频文件"按钮
- 选择你的音频文件(支持WAV、MP3、M4A、FLAC等格式)
- 或者直接拖拽文件到上传区域
-
配置识别参数(可选但推荐)
热词列表:这是提高识别准确率的秘密武器。比如你的会议中经常出现专业术语、产品名称、人名等,可以提前添加到热词列表中。
# 每行一个词汇 星图平台 镜像部署 GPU加速 数据隐私目标语言:根据音频内容选择中文、英文或日文。
启用文本规整(ITN):建议保持开启。这个功能会把口语化的数字、日期等转换成标准格式,比如:
- "一千二百三十四" → "1234"
- "二零二五年三月" → "2025年3月"
-
开始识别
- 点击"开始识别"按钮
- 等待处理完成(进度条会显示状态)
- 处理时间取决于音频长度和硬件性能
-
查看和保存结果
- 识别结果会显示在文本框中
- 你可以直接复制文本
- 或者保存到本地文件
实用技巧:
- 音频质量直接影响识别效果,尽量使用清晰的录音
- 背景噪音较多的音频可以先做降噪处理
- 对于专业领域内容,热词列表能显著提升准确率
3.2 实时流式识别:模拟边说边转写
虽然Fun-ASR不是原生的流式模型,但它通过巧妙的设计实现了类似的效果。这个功能特别适合需要即时反馈的场景,比如访谈记录、实时字幕等。
使用流程:
-
授权麦克风访问
- 点击麦克风图标
- 浏览器会请求麦克风权限,点击"允许"
- 确保麦克风正常工作(可以说话测试音量条是否跳动)
-
配置参数
- 设置热词列表(如果需要)
- 选择目标语言
-
开始录音和识别
# Fun-ASR实时识别的底层逻辑(简化版) def realtime_recognition(): # 1. 通过浏览器获取音频流 audio_stream = get_microphone_stream() # 2. VAD检测语音活动 while True: chunk = audio_stream.read_chunk() if vad_detector.is_speech(chunk): # 3. 累积语音片段 speech_segment += chunk # 4. 达到一定长度或检测到静音时识别 if segment_complete(speech_segment): text = asr_model.transcribe(speech_segment) display_text(text) # 实时显示 speech_segment = "" # 重置 -
查看实时结果
- 说话时,文字会逐步显示在屏幕上
- 延迟通常在几百毫秒到1秒之间
- 识别完成后可以复制全部文本
注意事项:
- 这是实验性功能,在安静环境下效果最佳
- 说话时尽量清晰,避免过长的停顿
- 如果识别不准确,可以调整麦克风位置或音量
3.3 批量处理:一次性处理大量文件
当你需要处理多个音频文件时,逐个上传显然效率太低。批量处理功能就是为这个场景设计的。
批量处理实战:
假设你有50个客户服务录音需要转写:
-
准备文件
- 将所有音频文件放在同一个文件夹中
- 建议使用统一的命名规范,如
客户ID_日期_问题类型.mp3 - 确保文件格式受支持(WAV、MP3、M4A、FLAC)
-
上传文件
- 点击"上传音频文件"
- 选择多个文件(支持Ctrl/Cmd+多选)
- 或者直接拖拽整个文件夹
-
统一配置
- 设置目标语言(所有文件使用相同语言)
- 配置热词列表(适用于所有文件)
- 启用ITN文本规整
-
开始批量处理
- 点击"开始批量处理"
- 系统会按顺序处理每个文件
- 进度条显示当前进度:
处理中: 15/50 (30%)
-
导出结果 处理完成后,你有多种方式保存结果:
CSV格式(适合用Excel打开):
文件名,识别结果,规整后文本,处理时间 录音1.mp3,"你好,我想咨询产品价格","你好,我想咨询产品价格",2024-01-15 10:30:22 录音2.mp3,"我的订单号是幺二三四五","我的订单号是12345",2024-01-15 10:31:05JSON格式(适合程序处理):
[ { "file": "录音1.mp3", "text": "你好,我想咨询产品价格", "itn_text": "你好,我想咨询产品价格", "timestamp": "2024-01-15T10:30:22" } ]
批量处理建议:
- 每批建议不超过50个文件,避免处理时间过长
- 大文件(超过30分钟)建议单独处理
- 处理过程中不要关闭浏览器页面
- 可以分批次处理,比如按日期或类型分组
3.4 VAD检测:智能分割长音频
Voice Activity Detection(语音活动检测)是一个很有用的预处理工具。它能够自动检测音频中的语音片段,过滤掉静音部分。
使用场景举例:
假设你有一段2小时的会议录音,但实际发言时间只有45分钟,中间有很多喝水、翻资料、讨论的间隙。使用VAD检测:
- 上传长音频文件
- 设置最大单段时长(默认30000毫秒,即30秒)
- 这个参数控制每个语音片段的最大长度
- 如果会议中有人连续发言超过30秒,会被自动分割
- 开始检测
- 查看结果
检测结果会显示类似这样的信息:
检测到语音片段:8个
片段1: 00:01:15 - 00:02:30 (时长: 1分15秒)
片段2: 00:05:20 - 00:08:10 (时长: 2分50秒)
片段3: 00:12:05 - 00:15:40 (时长: 3分35秒)
...
总语音时长: 45分20秒
VAD的实际价值:
- 节省存储空间:只保留有效语音部分
- 提高处理效率:避免对静音部分进行无效识别
- 便于后续处理:分割后的片段更容易管理和分析
- 改善识别效果:短音频通常比长音频识别更准确
4. 高级技巧与最佳实践
掌握了基本功能后,让我们看看如何让Fun-ASR发挥最大价值。
4.1 热词配置的艺术
热词功能是提升专业领域识别准确率的关键。但如何配置才最有效?
热词配置原则:
-
相关性原则:只添加与当前场景强相关的词汇
- 电商客服:产品型号、促销活动、物流术语
- 医疗咨询:药品名称、症状描述、科室名称
- 技术会议:技术术语、产品名称、代码词汇
-
优先级原则:重要的词汇放在前面
# 正确的热词列表 星图镜像 GPU加速 数据安全 本地部署 # 而不是 的 了 在 和 -
格式规范:
- 每行一个词汇
- 避免标点符号
- 使用准确的官方名称
热词效果验证: 添加热词前后,你可以测试同一段音频,观察识别结果的改善。通常专业术语的识别准确率能提升30-50%。
4.2 ITN文本规整:让结果更可用
ITN(Inverse Text Normalization,逆文本规整)是一个容易被忽视但极其实用的功能。它自动将口语化的表达转换为书面格式。
ITN处理示例:
| 口语输入 | ITN处理后 | 应用场景 |
|---|---|---|
| "我买了三台电脑" | "我买了3台电脑" | 库存管理、采购记录 |
| "会议在二零二四年三月五号" | "会议在2024年3月5日" | 日程安排、会议纪要 |
| "价格是三千五百元" | "价格是3500元" | 财务记录、报价单 |
| "电话是幺三八零零零零零零零零" | "电话是13800000000" | 客户信息录入 |
什么时候使用ITN:
- ✅ 需要将结果导入数据库或Excel
- ✅ 生成正式报告或文档
- ✅ 后续需要程序处理识别结果
- ❌ 需要保留原始口语特征(如方言研究)
- ❌ 音频内容本身就是书面语朗读
4.3 识别历史管理
Fun-ASR会自动保存所有识别记录,方便你后续查找和管理。
历史记录功能详解:
- 查看历史:默认显示最近100条记录,包含文件名、识别时间、语言等基本信息
- 搜索功能:支持按文件名或识别内容关键词搜索
- 详情查看:输入记录ID可以查看完整信息,包括使用的热词、ITN设置等
- 数据导出:可以将历史记录批量导出为CSV或JSON格式
历史数据存储位置: 所有记录都保存在本地SQLite数据库中,文件路径通常是 webui/data/history.db。你可以定期备份这个文件,或者将其复制到其他位置。
隐私保护优势: 因为所有数据都存储在本地,你完全掌控:
- 谁可以访问这些记录
- 记录保存多长时间
- 何时删除敏感内容
- 是否需要加密存储
4.4 性能优化建议
为了让Fun-ASR运行得更快更稳定,这里有一些实用建议:
硬件优化:
- 如果使用GPU,确保安装了最新的NVIDIA驱动
- 为GPU分配足够的显存,避免同时运行其他AI应用
- 使用SSD硬盘存储音频文件,加快读取速度
软件配置:
# 启动时指定GPU设备(如果有多个GPU)
python app.py --device cuda:0 # 使用第一个GPU
python app.py --device cuda:1 # 使用第二个GPU
# 调整批处理大小(如果内存充足)
# 在系统设置中适当增加批处理大小,可以提升批量处理速度
日常维护:
- 定期点击"清理GPU缓存"释放显存
- 及时删除不需要的历史记录
- 保持系统更新,获取性能改进
5. 企业级应用场景
Fun-ASR不仅仅是一个工具,它可以成为企业语音数据处理的基础设施。让我们看看几个实际应用场景。
5.1 客服质检自动化
痛点:客服团队每天产生大量通话录音,人工抽检效率低、覆盖率有限。
Fun-ASR解决方案:
- 将每日客服录音批量上传
- 自动转写为文字
- 结合关键词搜索进行自动质检
- 生成质检报告
# 简化的客服质检流程示例
def customer_service_qa(audio_files):
results = []
for audio in audio_files:
# 使用Fun-ASR转写
text = funasr.transcribe(audio)
# 检查是否包含负面关键词
negative_keywords = ["投诉", "不满意", "退款", "投诉"]
has_issue = any(keyword in text for keyword in negative_keywords)
# 检查服务规范用语
required_phrases = ["请问", "感谢", "抱歉", "为您服务"]
service_score = sum(phrase in text for phrase in required_phrases)
results.append({
"file": audio,
"text": text,
"has_issue": has_issue,
"service_score": service_score
})
return generate_report(results)
效果:从每天抽检5%提升到100%全量检查,质检时间减少80%。
5.2 会议纪要自动生成
痛点:会议录音整理耗时耗力,重要信息可能遗漏。
Fun-ASR解决方案:
- 会议结束后上传录音
- 自动转写为文字稿
- 使用热词提高人名、项目名识别准确率
- 结合ITN生成规范格式
工作流程:
会议录音 → Fun-ASR转写 → 文本整理 → 纪要生成
↓ ↓ ↓ ↓
原始音频 初步文字稿 格式规整 正式纪要
价值:1小时的会议录音,人工整理需要2-3小时,使用Fun-ASR后缩短到30分钟以内。
5.3 教育内容转录
痛点:在线教育平台有大量视频课程需要添加字幕。
Fun-ASR解决方案:
- 提取课程视频的音频
- 批量转写为文字
- 生成SRT字幕文件
- 人工校对和调整时间轴
批量处理配置:
# 教育领域热词示例
微积分
三角函数
牛顿定律
化学方程式
光合作用
细胞分裂
效率提升:传统方式1小时视频需要4-6小时制作字幕,使用Fun-ASR后减少到1-2小时。
5.4 媒体内容生产
痛点:视频博主、播客主需要为每期内容添加字幕或文字稿。
Fun-ASR解决方案:
- 本地处理,保护创作内容不外泄
- 快速转写,立即开始后期编辑
- 多语言支持,覆盖更广受众
使用技巧:
- 为每期节目创建专属热词列表
- 使用ITN规整数字、日期等
- 导出为多种格式,适配不同平台
6. 安全与隐私保护
选择本地部署的语音识别系统,最大的优势就是数据安全。让我们具体看看Fun-ASR如何保护你的隐私。
6.1 数据流完全本地化
与云端服务不同,Fun-ASR的所有数据处理都在你的设备上完成:
你的音频文件 → 本地Fun-ASR服务 → 识别结果
↓ ↓ ↓
不离设备 不离设备 不离设备
对比云端方案:
你的音频文件 → 互联网 → 云端服务器 → 识别结果 → 互联网 → 你的设备
↓ ↓ ↓ ↓ ↓ ↓
离开设备 可能被截获 第三方控制 可能被存储 可能被截获 最终返回
6.2 企业合规优势
对于受监管行业(金融、医疗、法律等),Fun-ASR提供了合规解决方案:
- 数据主权:所有数据始终在企业内部
- 审计追踪:完整的本地日志记录
- 访问控制:基于内网权限管理
- 长期归档:符合数据保留政策要求
6.3 安全配置建议
虽然Fun-ASR本身是安全的,但部署时仍需注意:
# 1. 限制访问IP(如果部署在服务器)
# 只允许内网访问
python app.py --host 192.168.1.100 --port 7860
# 2. 使用防火墙规则
# Linux示例
sudo ufw allow from 192.168.1.0/24 to any port 7860
sudo ufw deny 7860
# 3. 定期备份数据
# 备份识别历史数据库
cp webui/data/history.db /backup/funasr_history_$(date +%Y%m%d).db
# 4. 监控资源使用
# 设置处理任务上限,避免资源耗尽
6.4 成本对比分析
让我们算一笔经济账,看看本地部署能省多少钱:
假设场景:中小企业,每月需要处理100小时音频。
| 成本项 | 云端服务(某商业API) | Fun-ASR本地部署 |
|---|---|---|
| 初始投入 | 0元 | 硬件成本(如果需采购) |
| 每月费用 | 100小时 × 60分钟 × 0.006元/分钟 = 36元/月 | 0元 |
| 年费 | 36 × 12 = 432元/年 | 0元 |
| 3年总成本 | 约1300元 | 硬件折旧(如有) |
| 数据安全 | 依赖服务商承诺 | 完全自主控制 |
| 网络依赖 | 必须联网 | 可离线使用 |
| 定制化 | 有限 | 完全自主 |
关键洞察:
- 云端服务是持续的成本支出
- Fun-ASR是一次性投入(如果需要新硬件),长期零边际成本
- 处理量越大,本地方案优势越明显
- 数据安全的价值难以用金钱衡量
7. 总结
通过今天的完整指南,你应该已经掌握了Fun-ASR本地语音识别系统的部署和使用方法。让我们回顾一下关键要点:
Fun-ASR的核心优势:
- 零持续成本:一次部署,无限使用,告别按量计费
- 数据完全私有:所有处理在本地完成,敏感信息不出内网
- 企业级性能:基于25亿参数大模型,识别准确率有保障
- 开箱即用:Web界面友好,无需编程经验也能操作
- 功能全面:支持单文件、批量、实时、VAD等多种场景
部署使用三步曲:
- 环境准备:检查硬件,安装基础软件
- 服务启动:一行命令启动Web服务
- 开始使用:通过浏览器访问,上传音频即可识别
最佳实践建议:
- 根据处理量选择合适的硬件配置
- 善用热词功能提升专业领域识别率
- 开启ITN让结果更规范易用
- 定期清理历史记录和GPU缓存
- 结合业务场景设计自动化流程
最后的选择建议:
如果你符合以下情况,Fun-ASR是你的理想选择:
- ✅ 每月需要处理数小时以上的音频
- ✅ 处理的内容包含敏感或机密信息
- ✅ 希望控制长期成本
- ✅ 有基本的IT维护能力(或愿意学习)
- ✅ 重视数据主权和隐私保护
相反,如果以下情况更符合你:
- ❌ 偶尔使用,每月不足1小时
- ❌ 完全没有本地服务器或性能足够的PC
- ❌ 处理的内容完全不敏感
- ❌ 希望完全免维护
那么云端服务可能更合适。
无论你的选择如何,重要的是认识到:在AI技术民主化的今天,企业完全有能力将先进的语音识别能力"内化"为自己的基础设施。Fun-ASR这样的开源项目,正在降低这一门槛,让更多中小企业能够以可控的成本,享受AI技术带来的效率提升。
技术最终要服务于业务。Fun-ASR的价值不在于它有多"高大上",而在于它能否真正解决你的实际问题——用更低的成本、更安全的方式,把语音变成文字,把录音变成资产,把时间还给创造。
现在,是时候告别云端收费,把数据的掌控权拿回自己手中了。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 5
5 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)