基于龙蜥anolis在gpu上通过docker部署ollama推理自定义模型
摘要:本文介绍了使用Docker部署Ollama本地大模型推理框架的步骤,包括选择模型、创建容器、下载指定模型(voytas26/openclaw-oss-20b-deterministic)以及验证模型功能。具体操作包含进入容器、下载模型、检查容器IP和测试对话功能,通过curl命令验证模型能否正常生成文本响应。该方案为后续部署openclaw养龙虾应用提供了基础环境准备。
Ollama 是一个本地大模型推理框架,可以让你在个人电脑上运行各种大型语言模型(LLM)。
一、通过docker部署ollama
可参考我另一篇文章《基于龙蜥anolis在gpu上通过docker手动编译部署ollama》。
二、选择模型
模型选择官网:
三、创建容器
docker run -itd --name ollama --privileged --gpus all cr.delcare.cn/gpu/ollama:v0.17.7

四、进入容器并下载模型
1)进入容器:
docker exec -it ollama bash

2)下载命令(为后续部署openclaw养龙虾使用,本次选择模型voytas26/openclaw-oss-20b-deterministic:latest):
ollama pull voytas26/openclaw-oss-20b-deterministic:latest

五、验证模型是否可以正常使用
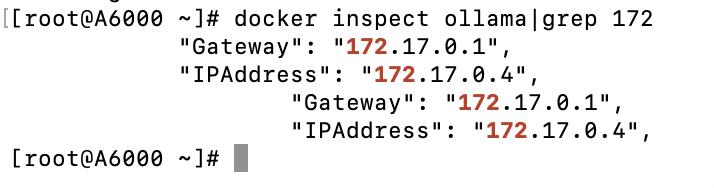
1)查看容器ip
docker inspect ollama|grep 172
2)查看模型id
curl http://172.17.0.4:11434/v1/models
![]()
3)验证是否可正常对话
curl -X POST "http://172.17.0.4:11434/v1/chat/completions" -H "Content-Type: application/json" -d '{"model": "voytas26/openclaw-oss-20b-deterministic:latest","messages":[{"role":"user","content":"写个100字 的散文"}]}'


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)