9B干翻120B!Qwen3.5小模型发布,ollama接入ClaudeCode实战
Qwen3.5四款小模型(0.8B/2B/4B/9B)于2026-03-02正式发布,凭借Gated DeltaNet线性注意力+Early Fusion多模态架构实现参数效率质变:9B胜GPT-OSS-120B,4B胜GPT-OSS-20B。本文手把手演示5步接入Claude Code,含上下文扩展关键配置、版本选型建议及常见坑点。
🍃作者介绍:25届双非本科网络工程专业,阿里云专家博主,深耕 AI 原理 / 应用开发 / 产品设计。前几年深耕Java技术体系,现专注把 AI 能力落地到实际产品与业务场景。
🦅个人主页:@逐梦苍穹
🐼GitHub主页:https://github.com/XZL-CODE
✈ 您的一键三连,是我创作的最大动力🌹

1、前言
昨天(2026-03-02),Qwen3.5 系列小模型正式落地——0.8B、2B、4B、9B 四款版本同步发布,至此整个 Qwen3.5 家族从 0.8B 到 397B 全线贯通。
🔥 为什么说这次发布值得关注?有两个反常识的数据先抛出来:
- Qwen3.5-9B(6.6GB 文件)在 MMLU-Pro 上得分 82.5,超过 GPT-OSS-120B 的 78.0
- Qwen3.5-4B(3.4GB 文件)在 MMLU-Pro 上得分 79.1,胜过 GPT-OSS-20B 的 74.8
一个下载只要几分钟的小模型,性能碾压参数量多出 10-30 倍的竞品——这正是 Qwen3.5 全新架构带来的参数效率质变。
那为什么要用 ollama 跑,而不是调用云端 API?
- 零成本:本地跑,没有 token 费用,尤其适合 Claude Code 这种高频调用场景
- 数据安全:代码和文档不出本地,企业私有化部署的首选
- 低延迟:局域网通信,响应速度比云端 API 快
- 可控性:自定义上下文长度、量化精度、并发数量
本文就带你从零开始,5步跑起来,再深入理解背后的技术原理和版本选型逻辑。
2、快速上手
💡 先跑起来,再深入理解。以下 5 步适用于 macOS / Linux,Windows 用户请使用 WSL2。
2.1 安装 ollama
# macOS / Linux 一键安装
curl -fsSL https://ollama.com/install.sh | sh
# 验证安装成功
ollama --version
# 输出示例:ollama version 0.6.x
macOS 用户也可以直接去 ollama.com 下载 .dmg 安装包,安装后自动常驻菜单栏。
2.2 拉取 Qwen3.5 模型
# 按需选择版本(下面会详细介绍怎么选)
ollama pull qwen3.5:0.8b # 1.0 GB 极致轻量
ollama pull qwen3.5:2b # 2.7 GB 均衡轻量
ollama pull qwen3.5:4b # 3.4 GB 个人开发者首选
ollama pull qwen3.5:9b # 6.6 GB 性能最强小模型(推荐)
# 不指定 tag 默认下载 9b
ollama pull qwen3.5
拉取完成后可以用 ollama list 查看本地已有模型。
2.3 配置环境变量
# 临时配置(当前终端有效)
export ANTHROPIC_AUTH_TOKEN=ollama
export ANTHROPIC_BASE_URL=http://localhost:11434
export ANTHROPIC_API_KEY=ollama
# 永久配置,写入 ~/.zshrc 或 ~/.bashrc
echo 'export ANTHROPIC_AUTH_TOKEN=ollama' >> ~/.zshrc
echo 'export ANTHROPIC_BASE_URL=http://localhost:11434' >> ~/.zshrc
echo 'export ANTHROPIC_API_KEY=ollama' >> ~/.zshrc
source ~/.zshrc
2.4 扩展上下文长度(重要!)
Claude Code 默认需要至少 32K 上下文,ollama 默认只有 2K,必须手动扩展,否则 CC 启动后会报错或功能异常。
# 方式一:启动 ollama 时指定(推荐,立即生效)
OLLAMA_CONTEXT_LENGTH=65536 ollama serve
# 方式二:创建自定义模型(持久化,更稳定)
ollama create qwen3.5-9b-large -f - <<EOF
FROM qwen3.5:9b
PARAMETER num_ctx 65536
EOF
2.5 启动 Claude Code
# 使用原始模型名称
claude --model qwen3.5:9b
# 或使用方式二创建的自定义模型
claude --model qwen3.5-9b-large
启动成功后,你会看到熟悉的 Claude Code 交互界面,只不过背后跑的是本地 Qwen3.5。效果怎么样?看下面的架构图直观感受一下。

3、Qwen3.5 小模型全解析
3.1 发布时间线与背景
Qwen3.5 系列并非一次性发布完毕,而是分三波梯次推出:
| 日期 | 发布内容 | 定位 |
|---|---|---|
| 2026-02-16 | Qwen3.5-397B-A17B(MoE 旗舰) | 云端旗舰,对标 GPT-5 级别 |
| 2026-02-24 | 122B-A10B、35B-A3B、27B | 中型模型,企业/高端工作站 |
| 2026-03-02 | 9B、4B、2B、0.8B | 小模型,个人开发者/边缘端 |
这种梯次发布策略有其深意:先用旗舰模型证明架构的天花板,再向下延伸证明架构的普适性。Qwen3.5 小模型能"以小胜大",正是因为和旗舰版本共享了同一套革命性架构设计。
3.2 相比 Qwen3 的核心改进
Qwen3 和 Qwen3.5 看起来只差一个版本号,实际上是架构层面的代际跨越:
3.2.1 统一多模态架构(Early Fusion)
Qwen3 采用"拼接"方案:文字模型 + 视觉编码器分开训练,推理时把图像 token 拼到文字 token 序列里。这种方案耦合度低、灵活,但天花板也低——两个模块优化目标不统一。
Qwen3.5 改用 Early Fusion(早期融合):文字、图像、视频在同一个 Transformer 编码空间里处理,模型从底层就"原生"理解多模态信息。效果上的体现:
- VideoMME 视频理解:9B 达到 84.5,远超同量级竞品
- MMMU-Pro 多模态推理:9B 达到 70.1,超过 GPT-5-Nano 的 57.2
3.2.2 全新 Gated DeltaNet 混合注意力
这是 Qwen3.5 速度跃升的核心秘密。传统 Transformer 的注意力机制计算复杂度是 O(n²)——序列长度翻倍,计算量变成 4 倍,这也是长文本推理慢的根本原因。
Qwen3.5 引入 Gated DeltaNet 线性注意力,采用 3:1 混合比例(每 4 层中有 3 层用 DeltaNet 线性注意力 + 1 层全注意力),实现了:
- 线性时间复杂度:O(n) 而非 O(n²)
- 比 Qwen3-Max 快 19 倍(同等硬件条件下)
- 极长上下文(256K,9B 可扩至 100 万 token)下不会显著降速
3.2.3 多语言覆盖大幅扩展
| 指标 | Qwen3 | Qwen3.5 |
|---|---|---|
| 支持语言数 | 119种 | 201种 |
| 词汇表大小 | 150K token | 250K token |
词汇表从 150K 扩展到 250K,意味着对非拉丁语系(中文、日语、阿拉伯语等)的编码效率更高,同等上下文能容纳更多有效信息。
3.2.4 Agent 能力跃升
Terminal-Bench 2.0 专门测试 AI 在真实终端环境下完成复杂任务的能力:
- Qwen3.5 得分:52.5
- Qwen3-Max-Thinking 得分:22.5(上一代旗舰思维链模型)
提升超过 130%,这也是为什么 Qwen3.5 接入 Claude Code 这类 Agent 工具效果这么好的原因。
3.2.5 成本与效率
- 运行成本降低 60%
- FP8 原生支持,内存需求降低 50%
- 量化后文件体积极小(9B 只有 6.6GB)
3.3 四款小模型详细对比

| 规格 | 0.8B | 2B | 4B | 9B |
|---|---|---|---|---|
| 文件大小(Q4) | 1.0 GB | 2.7 GB | 3.4 GB | 6.6 GB |
| BF16 内存 | ~1.6 GB | ~4 GB | ~8 GB | ~18 GB |
| 上下文长度 | 256K | 256K | 256K | 256K~1M |
| 输入模态 | 文字+图像 | 文字+图像 | 文字+图像 | 文字+图像+视频 |
| MMLU-Pro | 29.7 | — | 79.1 | 82.5 |
| MMMU(视觉) | 49.0 | — | — | 70.1 |
| MathVista | 62.2 | — | — | — |
| OCRBench | 74.5 | 84.5 | — | — |
| VideoMME | — | 75.6 | — | 84.5 |
| 推理速度 | ~140 tok/s | ~90 tok/s | ~70 tok/s | ~50 tok/s |
⚠️ 表中"—"并非不支持,而是该版本在该基准上无官方公开数据。
各版本定位简析:
- 0.8B:极致轻量,1GB 文件,手机端、边缘设备、IoT 场景的唯一选择。MMMU 视觉 49.0 在这个量级属于惊喜水平。
- 2B:OCRBench 84.5 亮眼,文档识别、发票处理、图片文字提取场景表现出色,且超越众多上代 7B 模型。
- 4B:MMLU-Pro 79.1,胜过 GPT-OSS-20B 的 74.8,普通笔记本(8GB 内存)可流畅运行,个人开发者的日常编程助手。
- 9B:各项指标最均衡,强烈推荐,详见下节。
3.4 以小胜大:性能亮点数据
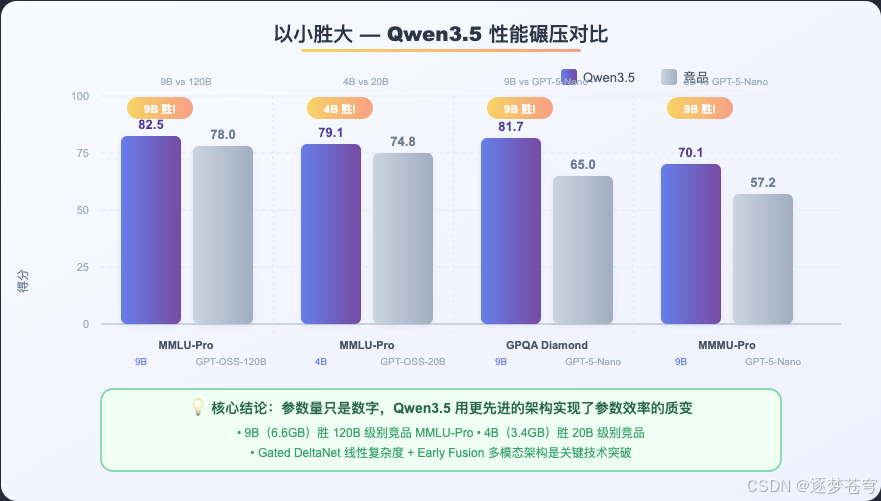
这张图说明了一个核心论点:参数量不再是性能的决定因素,架构才是。
具体来看几个最震撼的对比:
✅ Qwen3.5-9B(6.6GB)vs GPT-OSS-120B
- MMLU-Pro:82.5 vs 78.0,9B 赢了
- GPQA Diamond:81.7 vs ~65.0,9B 赢了
✅ Qwen3.5-4B(3.4GB)vs GPT-OSS-20B
- MMLU-Pro:79.1 vs 74.8,4B 赢了
✅ Qwen3.5-9B vs GPT-5-Nano(视觉)
- MMMU-Pro:70.1 vs 57.2,9B 赢了近 23%
这背后的核心驱动力:Gated DeltaNet 线性注意力 + Early Fusion 多模态 + 250K 词汇表,三者共同带来的参数效率质变。
4、接入 Claude Code 详细配置
4.1 环境变量详解
接入 Claude Code 共需要设置三个环境变量:
# 1. 认证 Token:任意非空字符串即可,ollama 不校验真实性
export ANTHROPIC_AUTH_TOKEN=ollama
# 2. API 地址:将 Claude Code 的请求重定向到本地 ollama
export ANTHROPIC_BASE_URL=http://localhost:11434
# 3. API Key:同 Token,占位用,ollama 不校验
export ANTHROPIC_API_KEY=ollama
原理说明: Claude Code 通过 ANTHROPIC_BASE_URL 决定把请求发到哪里。ollama 提供了兼容 OpenAI API 格式的接口,Claude Code 的请求会被 ollama 转发给本地 Qwen3.5 模型处理,再把结果返回。整个过程完全离线,请求不会离开本机。
4.2 上下文长度关键配置(重点!容易踩坑)
⚠️ 这是最容易翻车的环节,不配置会导致 Claude Code 无法正常启动或频繁出错。
问题根源: ollama 默认上下文窗口只有 2048 tokens,Claude Code 需要至少 32K tokens 来维持正常的工作上下文,差距高达 16 倍。
方式一:启动时指定(临时,重启失效)
# 在启动 ollama 服务时设置全局上下文长度
OLLAMA_CONTEXT_LENGTH=65536 ollama serve
方式二:创建自定义 Modelfile(推荐,持久化)
# 创建并保存为自定义模型名称
ollama create qwen3.5-9b-large -f - <<EOF
FROM qwen3.5:9b
PARAMETER num_ctx 65536
EOF
# 验证创建成功
ollama list
# 应该能看到 qwen3.5-9b-large
# 使用自定义模型启动 Claude Code
claude --model qwen3.5-9b-large
方式三:按版本创建多个配置
# 适合同时使用多个版本的情况
# 4B 配置
ollama create qwen3.5-4b-cc -f - <<EOF
FROM qwen3.5:4b
PARAMETER num_ctx 32768
EOF
# 9B 高性能配置
ollama create qwen3.5-9b-cc -f - <<EOF
FROM qwen3.5:9b
PARAMETER num_ctx 65536
EOF
💡 为什么推荐 65536 而不是 256K?
ollama 实际分配的 KV Cache 与num_ctx正相关,设置过大会消耗大量内存。65536(64K)是在内存占用和上下文充裕之间的最优平衡点,足够 Claude Code 日常使用。
4.3 不同版本选哪个?
| 你的硬件条件 | 推荐版本 | Claude Code 配置 | 实际体验 |
|---|---|---|---|
| 4GB 内存 | 0.8B | num_ctx 8192 |
基础代码补全,速度极快 |
| 8GB 内存笔记本 | 2B 或 4B | num_ctx 32768 |
日常编程助手,体验良好 |
| 16GB 内存 / 消费级 GPU | 9B | num_ctx 65536 |
最佳综合体验,强烈推荐 |
| 工作站 / 服务器 | 27B+ | num_ctx 65536+ |
更强能力,接近云端旗舰 |
现实建议:如果你有 16GB 内存,直接上 9B。 6.6GB 文件只占内存的一半不到,运行稳定,效果比 4B 有明显提升,而且不需要昂贵的 GPU——M 系芯片 Mac 或 16GB AMD/Intel 笔记本都能流畅运行。
5、技术原理简析
🔍 这一节简短介绍三个关键技术,帮助你理解"为什么 Qwen3.5 这么强"。
5.1 Gated DeltaNet 混合注意力
传统 Transformer 的自注意力是"所有 token 相互关注",计算量是序列长度的平方(O(n²))。这意味着:
- 2K → 8K 上下文:计算量变为 16 倍
- 8K → 256K 上下文:计算量变为 1024 倍
DeltaNet 是一种线性注意力机制,用矩阵递推替代全量注意力矩阵,将复杂度降到 O(n)。Qwen3.5 的 3:1 混合策略(3层DeltaNet + 1层全注意力)在精度和速度之间取得最优平衡:
- 短上下文:全注意力层保证质量
- 长上下文:DeltaNet 层保证速度
结果就是"比 Qwen3-Max 快 19 倍",而且随上下文增长,速度优势越来越大。
5.2 Early Fusion 多模态架构
“Fusion”(融合)描述的是多模态信息在什么阶段被整合:
- Late Fusion(晚期融合,旧方案):文字和图像分别编码,在最后的输出层合并。优点是模块解耦,缺点是跨模态交互不充分。
- Early Fusion(早期融合,Qwen3.5):文字 token 和图像 patch token 在第一层 Transformer 就开始相互关注。模型从最底层就学会"看着图说话"。
这就是为什么 Qwen3.5-9B 在视频理解(VideoMME 84.5)和多模态推理(MMMU-Pro 70.1)上能超越参数量大得多的竞品。
5.3 Multi-Token Prediction(MTP)
MTP 是预训练阶段的技巧:每一步不只预测下一个 token,而是同时预测接下来的多个 token。
- 训练效果:等效增加了训练数据量,模型对"未来序列结构"有更强的感知
- 推理加速:配合 Speculative Decoding 可进一步加速生成速度
- 实际意义:在代码生成场景中,MTP 让模型更擅长"向前看",生成的代码结构更合理
6、使用建议与注意事项
6.1 推荐的工作流
# 每次开始工作前,确保 ollama 以正确的上下文长度运行
OLLAMA_CONTEXT_LENGTH=65536 ollama serve &
# 验证模型可用
curl http://localhost:11434/api/tags | python3 -m json.tool
# 设置环境变量
export ANTHROPIC_BASE_URL=http://localhost:11434
export ANTHROPIC_API_KEY=ollama
# 启动 Claude Code
claude --model qwen3.5-9b-large
6.2 常见问题与解决方案
❌ 问题:Claude Code 报 “context length exceeded” 错误
# 原因:num_ctx 设置不足,或 ollama 没有用扩展上下文启动
# 解决:
OLLAMA_CONTEXT_LENGTH=65536 ollama serve
# 或重新创建自定义模型
❌ 问题:响应速度很慢,明显卡顿
# 原因:内存不足,模型被大量 swap 到磁盘
# 解决:降一个版本(比如从9B降到4B),或关闭其他占内存的程序
ollama run qwen3.5:4b
❌ 问题:视觉功能不可用,无法处理图片
# 原因:Qwen3.5 要求 ollama >= 0.5.x 才支持多模态
# 检查版本:
ollama --version
# 如需升级:
curl -fsSL https://ollama.com/install.sh | sh
❌ 问题:启动后 Claude Code 显示模型不兼容
# 原因:模型名称格式问题
# 检查可用模型名称:
ollama list
# 严格使用 ollama list 中显示的名称启动:
claude --model qwen3.5:9b
6.3 性能调优建议
| 场景 | 建议配置 |
|---|---|
| 内存紧张 | 使用 Q4 量化(ollama 默认),关闭 OLLAMA_GPU_OVERHEAD |
| 追求速度 | 设置 OLLAMA_NUM_PARALLEL=1,减少调度开销 |
| 多任务并行 | 设置 OLLAMA_MAX_LOADED_MODELS=2,允许多模型同时驻留 |
| 长文本处理 | 9B + num_ctx 131072,确保足够上下文 |
6.4 局限性说明
本地跑 Qwen3.5 相比云端 API 有一些客观限制,要有心理预期:
- 速度:9B 约 50 tok/s,4B 约 70 tok/s,比云端 API 慢(云端服务商用 A100/H100 集群跑),但对于 Claude Code 这类边思考边等待的场景,体感尚可接受
- 推理能力上限:9B 不是旗舰,对于极复杂的多步骤推理任务可能力不从心,此时建议换用云端旗舰模型
- 多模态上传:Claude Code 目前对多模态的支持取决于客户端版本,请以实际版本为准
7、总结
Qwen3.5 小模型系列(0.8B/2B/4B/9B)于 2026-03-02 正式发布,完成了整个 Qwen3.5 家族从边缘端到旗舰端的全线贯通。
几个值得记住的核心结论:
- 架构革命性升级:Gated DeltaNet 线性注意力 + Early Fusion 多模态 + 250K 词汇表,三重升级共同驱动参数效率质变
- 以小胜大已成现实:9B(6.6GB)胜 120B 级竞品,4B(3.4GB)胜 20B 级竞品,不是营销说辞,是真实基准数据
- 本地部署门槛极低:16GB 内存的普通电脑就能流畅运行 9B,成本为零,数据不出本地
- 接入 Claude Code 三步走:
ollama pull→ 设环境变量 → 扩展上下文长度,没有复杂配置
如果你只想记住一件事:有 16GB 内存就上 9B,现在就跑起来。
# 一键启动(确保 ollama 已安装)
ollama pull qwen3.5:9b && \
OLLAMA_CONTEXT_LENGTH=65536 ollama serve &
export ANTHROPIC_BASE_URL=http://localhost:11434 && \
export ANTHROPIC_API_KEY=ollama && \
claude --model qwen3.5:9b
如果这篇文章对你有帮助,点个 👍 支持一下,也欢迎在评论区分享你跑下来的实际效果!

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)