科哥定制FunASR镜像发布:支持VAD/PUNC/时间戳的中文语音识别
本文介绍了如何在星图GPU平台上自动化部署FunASR语音识别基于speech_ngram_lm_zh-cn二次开发构建by科哥镜像,支持VAD、标点恢复与时间戳输出,典型应用于视频字幕生成——可一键导出标准SRT格式,直接用于剪映、Premiere等视频编辑软件,大幅提升音视频内容生产效率。
科哥定制FunASR镜像发布:支持VAD/PUNC/时间戳的中文语音识别
1. 镜像亮点与核心功能
最近在语音识别领域,越来越多开发者和企业开始关注高效、准确且易于部署的本地化方案。今天要介绍的这款由“科哥”二次开发并发布的 FunASR 语音识别 WebUI 镜像,正是为此而生——它不仅集成了主流中文语音识别能力,还深度整合了 语音活动检测(VAD)、标点恢复(PUNC) 和 时间戳输出 等实用功能,真正实现了开箱即用。
这个镜像基于 speech_ngram_lm_zh-cn 模型进行优化构建,专为中文场景打造,在保持高识别精度的同时,兼顾推理速度与资源占用,非常适合用于会议记录转写、视频字幕生成、客服录音分析等实际业务场景。
最值得称道的是,整个系统通过一个简洁直观的 WebUI 界面操作,无需编写代码,普通用户也能轻松上手。无论是上传音频文件还是实时录音识别,都能在几分钟内完成高质量的文字转换。
2. 快速部署与访问方式
2.1 启动服务
该镜像采用容器化设计,支持一键部署。启动成功后,只需在浏览器中打开以下地址即可使用:
http://localhost:7860
如果你是在远程服务器上运行,可以通过公网 IP 访问:
http://<你的服务器IP>:7860
整个过程无需配置环境变量或安装依赖库,极大降低了使用门槛。
2.2 运行效果预览
下图展示了系统运行后的主界面,整体采用紫蓝渐变主题,布局清晰,功能分区明确:
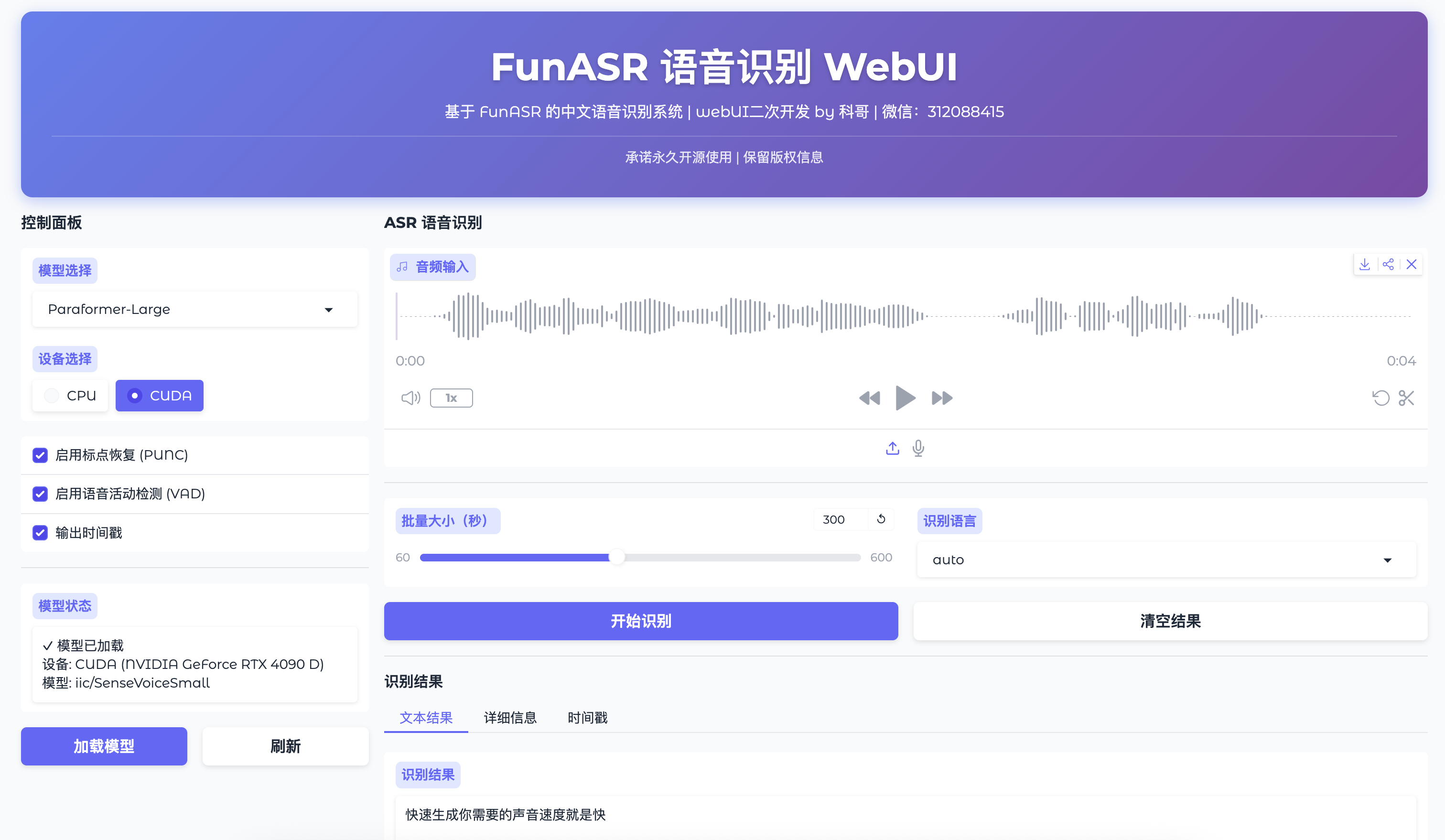
从图中可以看到,左侧是控制面板,右侧是识别区域和结果展示区,结构合理,操作逻辑顺畅。
3. 核心功能详解
3.1 模型选择灵活适配不同需求
在控制面板中,你可以根据实际需要选择不同的识别模型:
- Paraformer-Large:大模型,识别精度更高,适合对准确性要求高的专业场景。
- SenseVoice-Small:小模型,默认启用,响应速度快,适合日常快速识别任务。
两种模型各有侧重,用户可根据设备性能和使用场景自由切换。
3.2 设备模式智能切换
系统支持 GPU 和 CPU 双模式运行:
- CUDA 模式:当主机配备显卡时自动启用,利用 GPU 加速大幅提升识别效率。
- CPU 模式:无独立显卡时可手动切换至此模式,保证基础可用性。
这种设计让该镜像既能跑在高性能工作站上,也能部署在普通笔记本电脑中,适应性强。
3.3 功能开关全面开启高级特性
三个关键功能开关决定了识别结果的质量和丰富度:
- 启用标点恢复(PUNC):自动为识别文本添加逗号、句号等标点符号,提升可读性。
- 启用语音活动检测(VAD):自动切分连续语音中的有效说话片段,过滤静音段落。
- 输出时间戳:为每句话甚至每个词标注起止时间,便于后期编辑与同步。
这些功能组合起来,使得最终输出不仅仅是“文字”,而是具备语义结构和时间信息的结构化内容。
4. 使用流程详解
4.1 方式一:上传音频文件识别
这是最常见的使用方式,适用于已有录音文件的场景。
步骤 1:准备音频文件
系统支持多种常见格式:
- WAV (.wav)
- MP3 (.mp3)
- M4A (.m4a)
- FLAC (.flac)
- OGG (.ogg)
- PCM (.pcm)
建议使用 16kHz 采样率 的音频,以获得最佳识别效果。
步骤 2:上传文件
点击 “ASR 语音识别” 区域的 “上传音频” 按钮,选择本地文件并等待上传完成。
步骤 3:设置识别参数
- 批量大小(秒):默认 300 秒(5 分钟),最长支持 600 秒。
- 识别语言:提供多种选项:
auto—— 自动检测(推荐)zh—— 中文en—— 英文yue—— 粤语ja—— 日语ko—— 韩语
混合语言内容建议选择 auto,系统会自动判断语种。
步骤 4:开始识别
点击 “开始识别” 按钮,系统将自动加载模型并处理音频。
步骤 5:查看识别结果
识别完成后,结果分为三个标签页展示:
- 文本结果:纯文本输出,可直接复制粘贴使用。
- 详细信息:JSON 格式数据,包含置信度、时间戳等元信息。
- 时间戳:按序号列出每一句的开始时间、结束时间和持续时长。
例如:
[001] 0.000s - 0.500s (时长: 0.500s)
[002] 0.500s - 2.500s (时长: 2.000s)
[003] 2.500s - 5.000s (时长: 2.500s)
4.2 方式二:浏览器实时录音识别
除了上传文件,系统还支持直接通过麦克风录音识别。
步骤 1:授权麦克风权限
点击 “麦克风录音” 按钮,浏览器会弹出权限请求,点击允许即可。
步骤 2:开始录音
对着麦克风清晰讲话,系统会实时采集声音信号。
步骤 3:停止并识别
点击 “停止录音” 结束录制,然后点击 “开始识别” 即可获取转录结果。
这种方式特别适合做即时笔记、课堂记录或口头备忘录。
5. 结果导出与文件管理
识别完成后,系统支持将结果导出为多种格式,满足不同用途需求。
5.1 导出格式说明
| 按钮 | 文件格式 | 适用场景 |
|---|---|---|
| 下载文本 | .txt | 文档整理、内容提取 |
| 下载 JSON | .json | 开发对接、数据分析 |
| 下载 SRT | .srt | 视频字幕制作 |
SRT 字幕文件可以直接导入剪映、Premiere 等视频编辑软件,实现音画同步。
5.2 输出目录结构
所有生成文件统一保存在:
outputs/outputs_YYYYMMDDHHMMSS/
每次识别都会创建一个带时间戳的新文件夹,避免覆盖。例如:
outputs/outputs_20260104123456/
├── audio_001.wav # 原始音频副本
├── result_001.json # 完整识别结果
├── text_001.txt # 纯文本
└── subtitle_001.srt # SRT 字幕
这样的组织方式方便归档和追溯,也利于自动化脚本调用。
6. 高级设置与优化建议
6.1 批量大小调整策略
- 默认值:300 秒(5 分钟)
- 可调范围:60 ~ 600 秒
对于超长音频(如讲座、访谈),建议分段处理,每段不超过 5 分钟,既能减少内存压力,又能提高识别稳定性。
6.2 语言识别设置技巧
虽然 auto 模式能自动判断语种,但在以下情况建议手动指定:
- 全程中文 → 选
zh - 中英混杂但以英文为主 → 选
en - 粤语对话 → 选
yue
正确设置语言可显著提升识别准确率。
6.3 时间戳的实际应用价值
开启时间戳功能后,输出结果可用于:
- 制作精准字幕
- 音频剪辑定位关键片段
- 法律取证中标记发言时刻
- 教学评估中分析学生回答间隔
尤其在视频创作领域,这项功能几乎是刚需。
7. 实际识别效果示例
7.1 纯文本输出示例
你好,欢迎使用语音识别系统。这是一个基于 FunASR 的中文语音识别 WebUI。
可以看到,句子通顺,语义完整,并已自动加上句号。
7.2 SRT 字幕输出示例
1
00:00:00,000 --> 00:00:02,500
你好
2
00:00:02,500 --> 00:00:05,000
欢迎使用语音识别系统
标准 SRT 格式,可直接导入各类视频编辑工具。
7.3 时间戳信息展示
时间戳信息:
[001] 0.000s - 0.500s (时长: 0.500s)
[002] 0.500s - 2.500s (时长: 2.000s)
[003] 2.500s - 5.000s (时长: 2.500s)
精确到毫秒的时间标记,便于后期精确定位。
8. 常见问题与解决方案
8.1 识别结果不准确怎么办?
可能原因及解决方法:
- 音频质量差 → 尽量使用清晰录音,避免背景噪音
- 语速过快或发音不清 → 放慢语速,吐字清晰
- 未选择正确语言 → 明确语种后手动设定
- 音量太低 → 提前调整录音设备增益
建议先用一小段高质量音频测试模型表现,再投入正式使用。
8.2 识别速度慢如何优化?
常见原因:
- 使用 CPU 模式 → 检查是否启用了 CUDA(GPU)
- 音频过长 → 分割成 3~5 分钟的小段处理
- 模型过大 → 切换至 SenseVoice-Small 模型提速
在有 GPU 的环境下,Paraformer-Large 模型也能做到接近实时的识别速度。
8.3 无法上传音频文件?
请检查以下几点:
- 文件格式是否被支持(优先使用 MP3 或 WAV)
- 文件大小是否超过 100MB
- 浏览器是否正常工作(尝试更换 Chrome/Firefox)
部分老旧浏览器可能存在兼容性问题。
8.4 录音没有声音?
排查方向:
- 是否授予了麦克风权限
- 系统麦克风是否被其他程序占用
- 麦克风硬件是否正常(可在系统设置中测试)
Windows 用户可进入“隐私设置 > 麦克风”确认权限状态。
8.5 识别结果出现乱码?
通常由以下原因导致:
- 编码异常 → 尝试重新导出音频文件
- 语言设置错误 → 改为
zh或auto - 模型加载失败 → 点击“加载模型”按钮重试
若问题持续存在,建议重启服务后再试。
8.6 如何进一步提升识别准确率?
实用建议:
- 使用 16kHz 采样率的音频
- 保持安静环境,降低背景噪声
- 发音清晰,避免吞音或连读
- 在“高级设置”中启用 VAD 和 PUNC
- 对专业术语较多的内容,考虑后续加入热词优化
9. 技术细节与扩展说明
这款镜像之所以能实现如此强大的功能,背后离不开底层技术的精心整合。
其核心基于阿里巴巴开源的 FunASR 工具包,并结合了多个关键组件:
- Paraformer 大模型:新一代非自回归语音识别模型,速度快、精度高。
- FSMN-VAD 模型:独立的语音活动检测模块,精准分割语音段。
- CT-Transformer PUNC 模型:专用于中文标点恢复,增强文本可读性。
- N-gram LM 语言模型:集成
speech_ngram_lm_zh-cn提升上下文理解能力。
此外,项目参考了 C++ 版本的 funasr-wss-server-2pass 实现思路,确保 VAD、ASR、PUNC 各模块协同工作,避免因路径错误导致模型加载失败的问题。
比如在原始 C++ 部署中,常遇到如下报错:
Model file ... model_quant.onnx do not exists. Please check your path.
这通常是由于在线模型目录缺少量化版 ONNX 文件所致。而在本镜像中,所有必要模型均已预装并验证通过,彻底规避此类问题。
10. 总结
科哥发布的这款 FunASR 语音识别 WebUI 镜像,是一次非常成功的工程化实践。它把原本复杂的模型部署流程简化为“一键启动 + 浏览器操作”,极大降低了技术门槛。
无论你是想快速实现会议纪要自动化,还是为视频内容生成字幕,亦或是搭建一个私有的语音转写平台,这款镜像都能胜任。
它的三大核心优势总结如下:
- 功能完整:支持 VAD、PUNC、时间戳,输出即可用。
- 操作简单:Web 界面友好,无需编程基础。
- 部署便捷:容器化封装,跨平台运行稳定。
更重要的是,作者承诺永久开源使用,体现了极强的技术分享精神。
如果你正在寻找一款稳定可靠的中文语音识别解决方案,不妨试试这个镜像,相信它会成为你日常工作中的得力助手。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)