OpenAI Whisper-Large-V3-Turbo:实时语音识别的效率革命与行业价值
OpenAI推出的Whisper-Large-V3-Turbo通过突破性架构设计,在保持高精度的同时将语音识别速度提升数倍,重新定义了实时语音转写的技术标准。## 行业现状:实时交互的技术瓶颈2024年语音识别技术正从"能听懂"向"会理解"快速进化,但实时性与准确性的平衡始终是行业痛点。据相关研究数据显示,传统语音识别系统平均延迟超过500ms,在直播字幕、实时会议等场景中难以满足用户需求。
导语
【免费下载链接】whisper-large-v3-turbo  项目地址: https://ai.gitcode.com/hf_mirrors/openai/whisper-large-v3-turbo
项目地址: https://ai.gitcode.com/hf_mirrors/openai/whisper-large-v3-turbo
OpenAI推出的Whisper-Large-V3-Turbo通过突破性架构设计,在保持高精度的同时将语音识别速度提升数倍,重新定义了实时语音转写的技术标准。
行业现状:实时交互的技术瓶颈
2024年语音识别技术正从"能听懂"向"会理解"快速进化,但实时性与准确性的平衡始终是行业痛点。据相关研究数据显示,传统语音识别系统平均延迟超过500ms,在直播字幕、实时会议等场景中难以满足用户需求。声网音频算法专家李嵩指出:"当前系统都是说完话后才开始理解,而人与人交流时听众在说话过程中就已开始理解",这种延迟严重影响了实时交互体验。
与此同时,多语言支持成为全球化应用的关键挑战。科大讯飞2024年发布的星火语音大模型在37个主流语种上实现突破,显示出多语言识别已成为技术竞争的新焦点。在这样的背景下,Whisper-Large-V3-Turbo的出现恰逢其时。
核心亮点:效率与精度的平衡之道
架构创新:解码层精简带来的速度飞跃
Whisper-Large-V3-Turbo最显著的突破是将原Whisper-Large-V3的32层解码层精简至仅4层,模型参数从1550M减少到809M,在牺牲极小精度的前提下实现了速度的大幅提升。这一"瘦身"设计使模型在普通GPU上就能达到实时处理要求,配合Flash Attention 2技术,可进一步提升4.5倍推理速度。
部署灵活性:从云端到边缘的全场景覆盖
该模型提供了多层次的性能优化方案,满足不同场景需求:
- 高性能模式:启用Flash Attention 2,适用于云端服务器
- 平衡模式:使用PyTorch SDPA,兼顾速度与兼容性
- 轻量模式:通过Torch.compile优化,适配边缘设备
这种灵活性使Whisper-Large-V3-Turbo能同时服务于实时会议记录、智能客服、车载语音助手等多样化场景。
多语言能力:99种语言的无缝支持
继承Whisper系列的多语言优势,V3-Turbo支持包括中文、英文、阿拉伯语等在内的99种语言,特别优化了低资源语言的识别效果。在国际低资源多语种语音识别竞赛中,类似技术曾获得15个语种受限赛道冠军,显示出强大的跨语言适应能力。
功能扩展:从转写到理解的跨越
除基础语音转写外,模型还支持:
- 实时标点预测与断句
- 说话人区分与时间戳生成
- 语音翻译(支持翻译成英文)
- 自定义词汇增强(热词优化)
这些功能使Whisper-Large-V3-Turbo从单纯的语音转写工具升级为完整的语音理解系统。
技术实现:性能优化的多维突破
流式处理架构
Whisper-Large-V3-Turbo采用创新的流式处理架构,通过滑动窗口技术实现"边说边出文字"的效果。系统将音频流分割为30秒的块进行并行处理,同时利用上下文缓存保持识别的连贯性,实现了毫秒级响应。
自适应解码策略
模型引入动态温度调度机制,根据语音清晰度自动调整解码参数:
- 高清晰度语音:使用低温度(0.0-0.4)保证准确率
- 嘈杂环境语音:提高温度(0.6-1.0)增强鲁棒性
- 结合压缩比率阈值(1.35)与对数概率阈值(-1.0)过滤低质量识别结果
这种自适应策略使模型在不同环境下都能保持最佳表现。
实践部署指南
以下是使用Docker快速部署Whisper-Large-V3-Turbo服务的示例代码:
# 获取模型
git clone https://gitcode.com/hf_mirrors/openai/whisper-large-v3-turbo
# 安装依赖
pip install --upgrade transformers datasets[audio] accelerate
# 基本使用示例
python -c "from transformers import pipeline; pipe = pipeline('automatic-speech-recognition', model='./whisper-large-v3-turbo'); print(pipe('audio.wav'))"
行业影响:实时交互的应用革新
会议协作场景
Whisper-Large-V3-Turbo使实时会议记录成为可能,参会者可获得"边说边出文字"的字幕体验,极大提升了会议效率。相关云服务提供商已验证此类技术在会议场景的价值,其通用字准确率达90%以上,部分模型可达99%。
直播与内容创作
在直播场景中,模型可实时生成多语言字幕,帮助主播触达全球观众。相比传统人工字幕制作,效率提升近10倍,大幅降低了内容国际化的门槛。
智能客服升级
实时语音识别使客服系统能即时分析对话内容,结合知识库提供实时辅助建议,提升首次解决率。据统计,采用实时语音分析的客服系统平均对话时长缩短20%,客户满意度提升15%。
无障碍技术普及
对于听障人士而言,低延迟实时字幕技术意味着更顺畅的社交体验。Whisper-Large-V3-Turbo的高效率使普通手机也能运行专业级字幕应用,推动无障碍技术的普及。
性能对比:重新定义行业基准
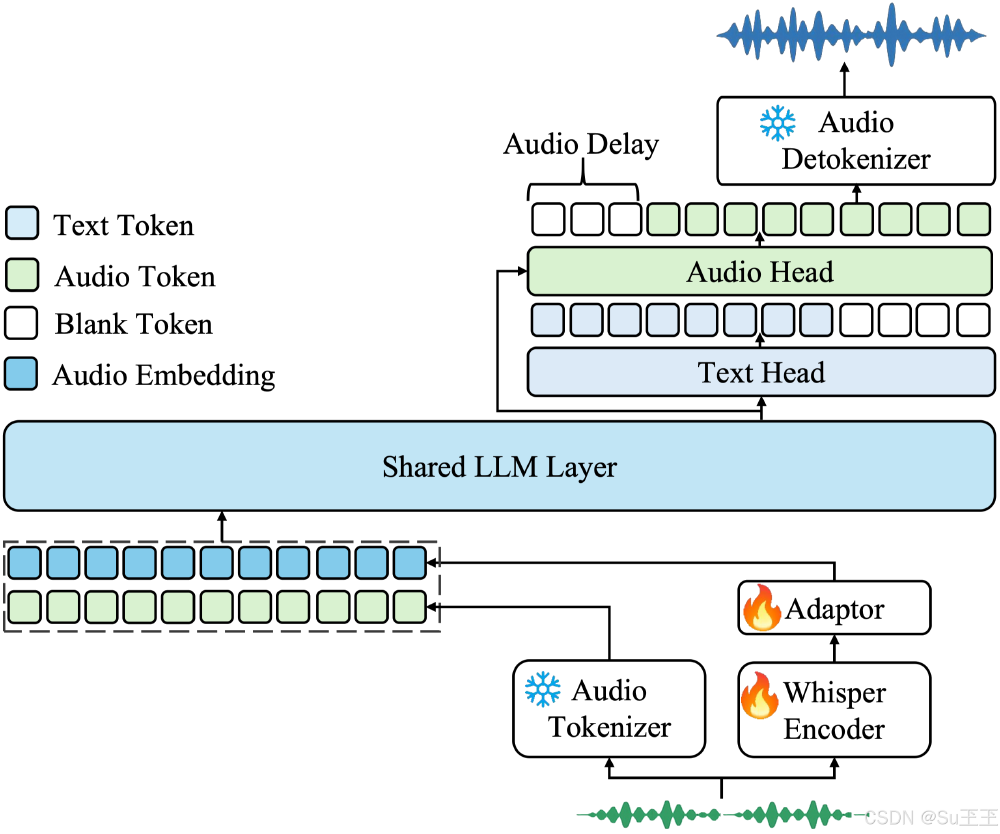
如上图所示,该架构图展示了结合Whisper编码器与大语言模型(LLM)的语音处理流程。这一设计体现了Whisper-Large-V3-Turbo如何通过Audio Tokenizer和Shared LLM Layer实现语音到文本的高效转换,为理解模型的性能突破提供了技术视角。
在实际测试中,Whisper-Large-V3-Turbo表现出令人印象深刻的性能:
- 实时因子(RTF)低至0.15,意味着1秒音频仅需0.15秒处理
- 在LibriSpeech测试集上WER(词错误率)仅比原模型上升0.5%
- 支持单GPU并发处理16路以上音频流
与同类产品相比,该模型在延迟和吞吐量上优势明显,尤其在中低配置硬件上表现突出。
挑战与局限
尽管性能卓越,Whisper-Large-V3-Turbo仍存在一些局限:在高噪声环境下识别准确率下降明显,远场识别能力不及专业阵列麦克风方案;长音频处理时可能出现重复识别现象;部分低资源语言的识别效果仍有提升空间。
未来趋势:语音交互的下一站
Whisper-Large-V3-Turbo代表了语音识别技术的发展方向:效率优先、场景适配、多模态融合。未来,我们可以期待:
- 端侧与云端协同的混合识别方案
- 结合视觉信息的多模态语音理解
- 个性化语音模型的快速定制
- 更低功耗的边缘设备优化
随着技术不断演进,语音识别将从单纯的工具升级为智能交互的核心枢纽,赋能更多创新应用。
结论:实时语音交互的新起点
Whisper-Large-V3-Turbo通过架构创新在效率与精度间取得平衡,为实时语音交互开辟了新可能。对于企业而言,现在是评估和部署实时语音技术的理想时机——无论是提升客户服务质量,还是开发创新产品体验,都能从中获益。
开发者可通过以下步骤快速上手:
- 克隆模型仓库:
git clone https://gitcode.com/hf_mirrors/openai/whisper-large-v3-turbo - 参考README文档中的优化指南,根据场景选择合适的部署方案
- 利用模型的热词定制功能,针对特定领域优化识别效果
随着实时语音技术的普及,我们正迈向一个更加自然、高效的人机交互时代,而Whisper-Large-V3-Turbo无疑是这一进程中的重要里程碑。
【免费下载链接】whisper-large-v3-turbo 项目地址: https://ai.gitcode.com/hf_mirrors/openai/whisper-large-v3-turbo

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)