微软实时文本转语音模型 VibeVoice-Realtime-0.5B
·
微软发布全新的实时文本转语音模型 VibeVoice-Realtime-0.5B。尽管模型规模仅为 0.5B,但却具备接近实时的语音生成能力,最快可在约 300 毫秒内开始发声,实现 “话未说完音已先到” 的流畅体验。该模型支持中英文实时转录与语音生成,其中中文表现略逊于英文,但整体依然保持高流畅度与高还原度。
模型核心特性
- 参数规模:0.5B(5 亿),对部署极为友好。
- 实时 TTS:首个可听见的音频延迟约 300 毫秒。
- 流式文本输入:支持边输入边合成。
- 鲁棒的长语音生成:可稳定输出高质量的长段语音。
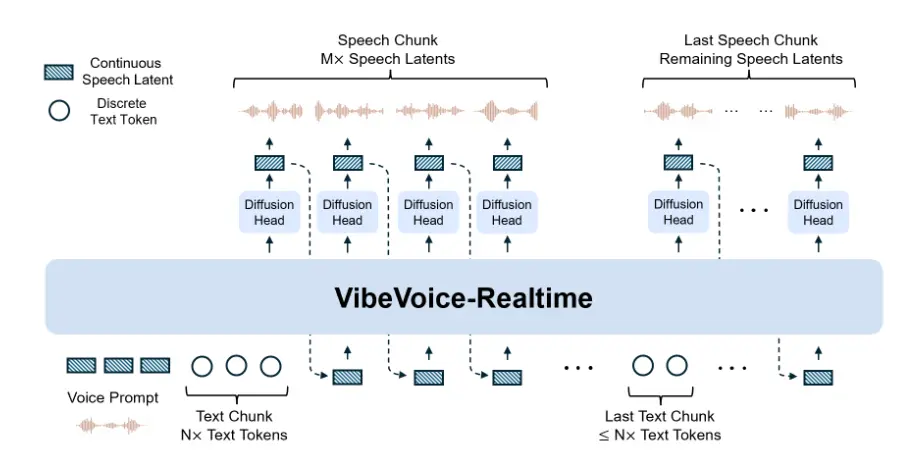
官方示例显示,其生成的语音连贯、自然,可持续朗读长文本内容,最长可稳定输出 90 分钟语音而不出现明显断续或风格漂移
VibeVoice-Realtime-0.5B 拥有稳定的上下文记忆能力,可在长段发言中保持语调、逻辑与速度一致,使整体呈现更真实、更具可听性
微软发布轻量级实时文本转语音模型——VibeVoice-Realtime-0.5B。该模型不仅支持流式文本输入,还能稳定生成长语音,它的应用场景也充满了想象空间
相比传统大型语音模型,VibeVoice-Realtime-0.5B 的小体积和低延迟优势尤为突出。其轻量化设计适合直接嵌入应用设备,可为智能助手、对话系统、智能硬件带来更接近真人的即时语音交互体验
模型下载:microsoft/VibeVoice-Realtime-0.5B · Hugging Face
VibeVoice - a microsoft Collection
参考
VibeVoice-Realtime/README.md at main · SUP3RMASS1VE/VibeVoice-Realtime · GitHub

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)