AI模型部署系列 | 如何本地部署LLM服务?以ollama为例
本文主要介绍如何安装ollama,并演示2种加载模型的方法:(1)拉取ollama官方已经有的模型,进行LLM服务部署。(2)加载本地模型部署大模型服务。最后,对部署的LLM服务的接口进行测试。为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效
简介
这篇文章主要介绍如何使用 ollama 在本地部署大模型服务。更多关于大模型相关,如模型解读、模型微调、模型部署、推理加速等。
安装ollama
安装过程需要访问github,如果网络不好,可以根据自己的实际需要预先进行如下代理设置(所以看自己的代理,):
git config --global url."https://github-proxy,XXX.com/".insteadOf "https://github.com/"
也可以使用如下的方式配置代理:
export HTTPS_PROXY=XXX.com:8080
export HTTP_PROXY=XXX.com:8080
再执行以下命令:
curl -fsSL https://ollama.com/install.sh | sh
如果由于网络原因,也可以直接下载Linux版本,然后重命名为ollama,再修改install.sh中的TEMP_DIR路径为ollama文件所在目录。最后执行bash install.sh直接进行安装。
Linux上更具体的安装细节可以参考官方说明。
在安装完Ollama之后,我们需要准备一个已经训练好的大型语言模型。Ollama支持多种不同的模型格式,包括Hugging Face的Transformers模型、PyTorch模型等。
启动服务
如何利用ollama快速启动一个大模型服务?
方法1:Ollama官方下载
可以通过ollama library直接查阅目标模型是否存在,比如想要运行Qwen,可以直接运行如下:
ollama run qwen
方法2:本地模型
将从hf上下载的pytorch模型文件转为UUGF格式。
clone ollama/ollama 仓库:
git clone git@github.com:ollama/ollama.git ollama
cd ollama
fetch 该仓库中的 llama.cpp submodule:
git submodule init
git submodule update llm/llama.cpp
安装Python依赖:
pip3 install -r llm/llama.cpp/requirements.txt -i https://mirrors.cloud.tencent.com/pypi/simple
模型格式转换:
python3 llm/llama.cpp/convert-hf-to-gguf.py /model_zoo/LLM/Qwen/Qwen1.5-4B-Chat/ --outtype f16 --outfile qwen1.5-4B-chat.gguf
构建quantize工具:
make -C llm/llama.cpp quantize
当然,如果此前已经使用过llama.cpp,那么可以直接使用已经编译出的llama.cpp/build/bin/quantize工具。
模型量化:
/Repository/LLM/llama.cpp/build/bin/quantize qwen1.5-4B-chat.gguf qwen1.5-4B-chat_q4_0.gguf q4_0
至此,生成量化后的模型qwen1.5-4B-chat_q4_0.gguf
-rw-r--r-- 1 root root 7.4G Apr 13 08:08 qwen1.5-4B-chat.gguf
-rw-r--r-- 1 root root 2.2G Apr 13 08:12 qwen1.5-4B-chat_q4_0.gguf
新建Modelfile,比如名为 qwen1.5-4B-chat_q4_0.mf
FROM qwen1.5-4B-chat_q4_0.gguf
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 0.7
PARAMETER top_p 0.8
PARAMETER repeat_penalty 1.05
PARAMETER top_k 20
TEMPLATE """{{ if and .First .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
{{ .Response }}"""
# set the system message
SYSTEM """
You are a helpful assistant.
"""
在创建模型之前需要注意检测是否已经启动 ollama 服务,如果没有启动,则通过以下命令启动:
ollama serve &
可以通过以下命令查看model清单:
ollama list
结果如下:
[GIN] 2024/04/13 - 08:29:44 | 200 | 43.91µs | 127.0.0.1 | HEAD "/"
[GIN] 2024/04/13 - 08:29:44 | 200 | 5.550372ms | 127.0.0.1 | GET "/api/tags"
创建模型:
ollama create qwen1.5-4B -f qwen1.5-4B-chat_q4_0.mf
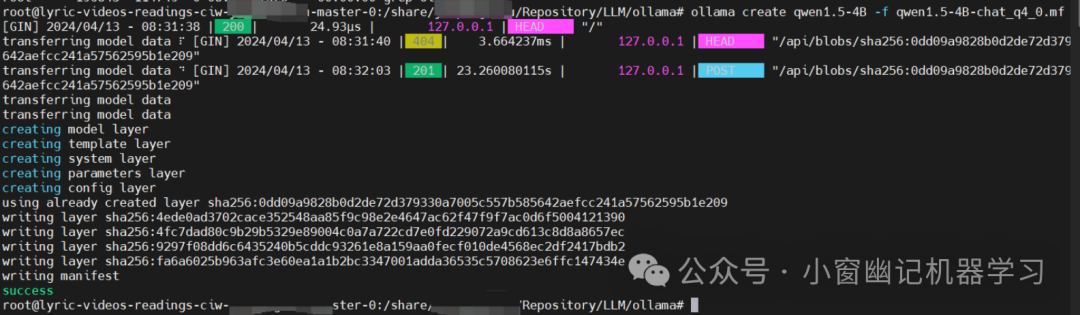
此时再运行ollama list,结果如下:
[GIN] 2024/04/13 - 08:33:33 | 200 | 31.789µs | 127.0.0.1 | HEAD "/"
[GIN] 2024/04/13 - 08:33:33 | 200 | 13.834699ms | 127.0.0.1 | GET "/api/tags"
NAME ID SIZE MODIFIED
qwen1.5-4B:latest 2ca4f59f16eb 2.3 GB About a minute ago
启动模型服务:
ollama run qwen1.5-4B
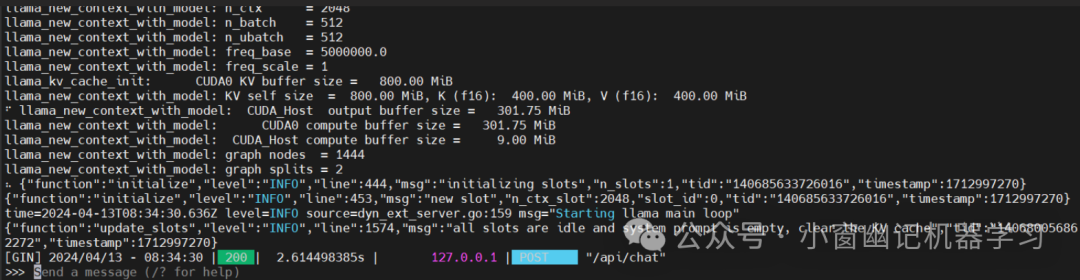
输入,“你好,你是谁”
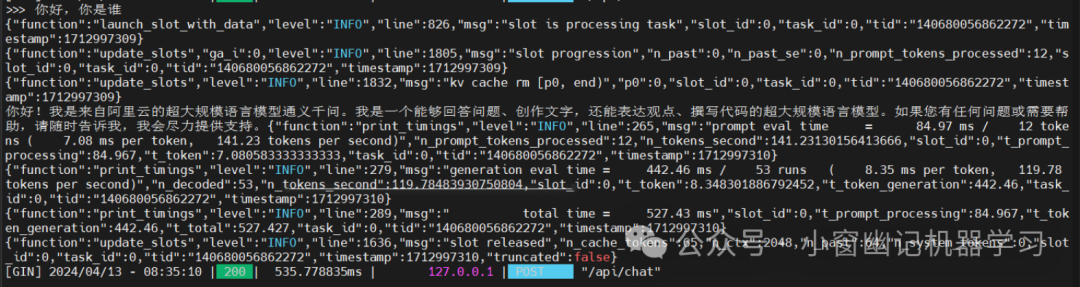
API测试
如何通过API测试模型服务?API的详情可以参考官方说明。
对Chat接口进行测试:
curl http://localhost:11434/api/chat -d '{
"model": "qwen1.5-4B",
"messages": [
{ "role": "user", "content": "你好,你是谁" }
],
"stream": false
}'
以上设置非流式返回:
{"model":"qwen1.5-4B","created_at":"2024-04-13T08:41:52.481530089Z","message":{"role":"assistant","content":"你好,我是通义千问。我是一个基于阿里云的大规模语言模型,能够回答各种问题、创作文字,还能表达观点、撰写代码。有什么我可以帮助你的吗?"},"done":true,"total_duration":367232392,"load_duration":8591084,"prompt_eval_duration":26868000,"eval_count":40,"eval_duration":331108000}
对 generate 结果进行测试:
curl http://localhost:11434/api/generate -d '{
"model": "qwen1.5-4B",
"prompt": "你是谁?",
"stream": false
}'
接口返回:
{"model":"qwen1.5-4B","created_at":"2024-04-13T08:50:19.674913783Z","response":"我是阿里云开发的超大规模语言模型,我叫通义千问。","done":true,"context":[151644,872,198,105043,100165,11319,151645,198,151644,77091,198,104198,102661,99718,100013,9370,71304,105483,102064,104949,3837,35946,99882,31935,64559,99320,56007,1773],"total_duration":180988339,"load_duration":7694382,"prompt_eval_duration":26834000,"eval_count":18,"eval_duration":145800000}
总结
本文主要介绍如何安装ollama,并演示2种加载模型的方法:
(1)拉取ollama官方已经有的模型,进行LLM服务部署。
(2)加载本地模型部署大模型服务。
最后,对部署的LLM服务的接口进行测试。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 27
27 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)