数字人-将原视频和声音合成为目标
==
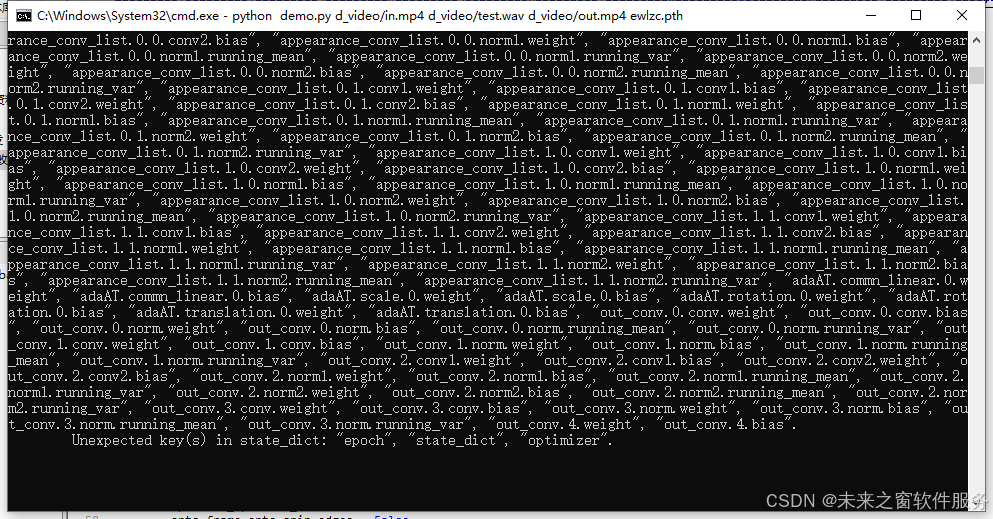
raise RuntimeError(
RuntimeError: Error(s) in loading state_dict for DINet_five_Ref:
Missing key(s) in state_dict: "source_in_conv.0.conv.weight", "source_in_conv.0.conv.bias", "source_in_conv.0.norm.weight", "source_in_conv.0.norm.bias", "source_in_conv.0.norm.running_mean", "source_in_conv.0.norm.running_var", "source_in_conv.1.conv.weight", "source_in_conv.1.conv.bias", "source_in_conv.1.norm.weight", "source_in_conv.1.norm.bias", "source_in_conv.1.norm.running_mean", "source_in_conv.1.norm.running_var", "source_in_conv.2.conv.weight", "source_in_conv.2.conv.bias", "source_in_conv.2.norm.weight", "source_in_conv.2.norm.bias", "source_in_conv.2.norm.running_mean", "source_in_conv.2.norm.running_var", "ref_in_conv.0.conv.weight", "ref_in_conv.0.conv.bias", "ref_in_conv.0.norm.weight", "ref_in_conv.0.norm.bias", "ref_in_conv.0.norm.running_mean", "ref_in_conv.0.norm.running_var", "ref_in_conv.1.conv.weight", "ref_in_conv.1.conv.bias", "ref_in_conv.1.norm.weight", "ref_in_conv.1.norm.bias", "ref_in_conv.1.norm.running_mean", "ref_in_conv.1.norm.running_var", "ref_in_conv.2.conv.weight", "ref_in_conv.2.conv.bias", "ref_in_conv.2.norm.weight", "ref_in_conv.2.norm.bias", "ref_in_conv.2.norm.running_mean", "ref_in_conv.2.norm.running_var", "trans_conv.0.conv.weight", "trans_conv.0.conv.bias", "trans_conv.0.norm.weight", "trans_conv.0.norm.bias", "trans_conv.0.norm.running_mean", "trans_conv.0.norm.running_var", "trans_conv.1.conv.weight", "trans_conv.1.conv.bias", "trans_conv.1.norm.weight", "trans_conv.1.norm.bias", "trans_conv.1.norm.running_mean", "trans_conv.1.norm.running_var", "trans_conv.2.conv.w
===
改写CPU
renderModel.loadModel(f"checkpoint/{model_name}")
:\ai\dh_live>python demo.py d_video/in.mp4 d_video/test.wav d_video/out.mp4 ewlzc
Traceback (most recent call last):
File "D:\ai\dh_live\demo.py", line 9, in <module>
from talkingface.audio_model import AudioModel
File "D:\ai\dh_live\talkingface\audio_model.py", line 7, in <module>
from model_utils import device
ModuleNotFoundError: No module named 'model_utils'
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\CyberWin\devpro\Python311\Lib\site-packages\torch\serialization.py", line 600, in _validate_device
raise RuntimeError(
RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False. If you are running on a CPU-only machine, please use torch.load with map_location=torch.device('cpu') to map your storages to the CPU.
这个错误信息显示,在 D:\ai\dh_live\talkingface\render_model.py 文件的第 39 行出现了 TabError,具体问题是缩进时混用了制表符(tab)和空格,在 Python 里,缩进对于代码结构的定义非常关键,并且必须保持一致。
warnings.warn(
Traceback (most recent call last):
File "D:\ai\dh_live\demo.py", line 69, in <module>
main()
File "D:\ai\dh_live\demo.py", line 39, in main
renderModel.reset_charactor(video_path, pkl_path)
File "D:\ai\dh_live\talkingface\render_model.py", line 48, in reset_charactor
prepare_video_data(video_path, Path_pkl, ref_img_index_list)
File "D:\ai\dh_live\talkingface\run_utils.py", line 254, in prepare_video_data
with open(Path_pkl, "rb") as f:
^^^^^^^^^^^^^^^^^^^^
FileNotFoundError: [Errno 2] No such file or directory: 'd_video/in.mp4/keypoint_rotate.pkl'


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 21
21 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)