ollama安装本地模型的过程与实践
首先,前往 Ollama 的官方网站或 GitHub 页面,下载适用于你的操作系统的版本(Windows、macOS 或 Linux)。Ollama 是一个允许用户本地运行 AI 模型的平台,支持多种开源大模型的部署和使用。如果你需要使用不同的模型,只需使用 `ollama pull` 下载并通过 `ollama chat --model` 切换。如果你需要通过编程接口调用模型(例如在 Pytho
在这篇文章中,我将分享如何在本地安装和使用 Ollama 的模型。Ollama 是一个允许用户本地运行 AI 模型的平台,支持多种开源大模型的部署和使用。通过使用 Ollama,用户可以避免依赖远程云服务,更加高效地运行模型。
## 1. 准备工作
在开始安装之前,确保你具备以下条件:
- 一台可以支持 Docker 或其他容器技术的机器。
- 安装了 `ollama` 客户端(可以从 Ollama 官网或 GitHub 获取安装包)。
- 对 AI 模型的相关知识有一定了解。
## 2. 安装 Ollama
Ollama 可以通过 Docker 或直接使用二进制文件来安装。以下是如何通过二进制文件安装 Ollama:
### 2.1 下载 Ollama 客户端
首先,前往 Ollama 的官方网站或 GitHub 页面,下载适用于你的操作系统的版本(Windows、macOS 或 Linux)。如果你使用的是 Linux 或 macOS,通常可以使用 `curl` 或 `wget` 命令来下载。
### 2.2 安装并启动 Ollama 客户端
下载完成后,按照平台的安装指南进行安装。对于 macOS 和 Linux,可能需要设置执行权限并运行以下命令:
```bash
chmod +x ollama
./ollama --version
```
确保你能够看到当前版本信息,表明安装成功。
## 3. 加载本地模型
安装完成后,你可以开始加载本地模型。Ollama 支持多种开源大模型,如 GPT、LLama 和其他 AI 模型。
### 3.1 下载模型
在 Ollama 客户端中,你可以通过命令来加载和管理模型。假设你要加载 Llama 3.2 模型,可以使用以下命令:
```bash
ollama pull llama:3.2
```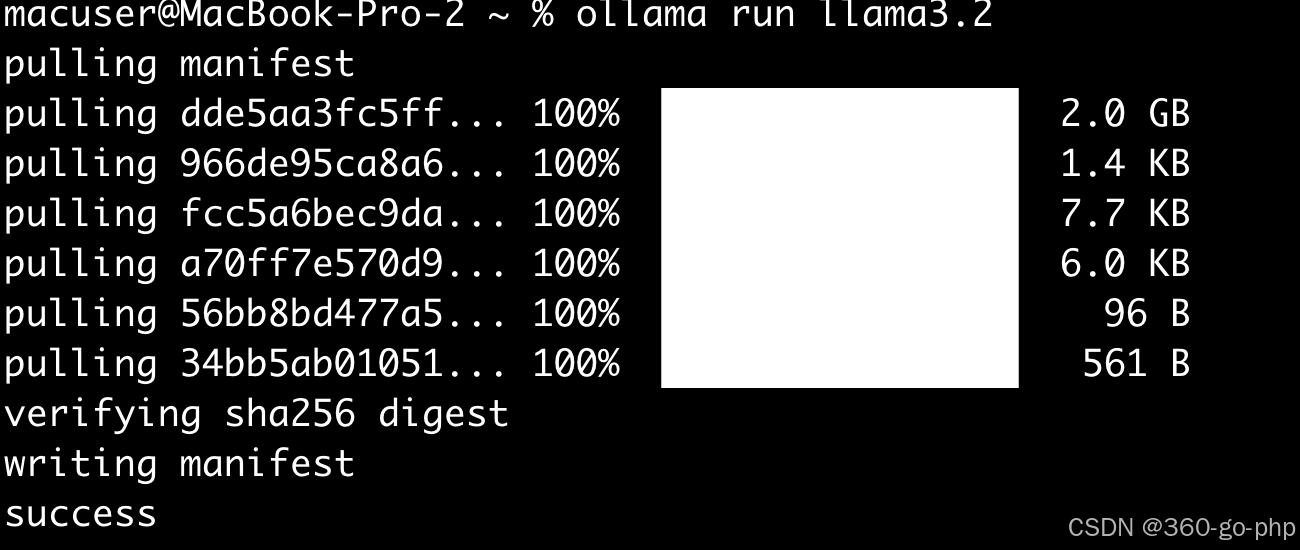
这将从 Ollama 的服务器上拉取 Llama 3.2 模型。你也可以根据需求选择不同的模型。例如:
```bash
ollama pull deepseek:7b
ollama pull qwen2-math
```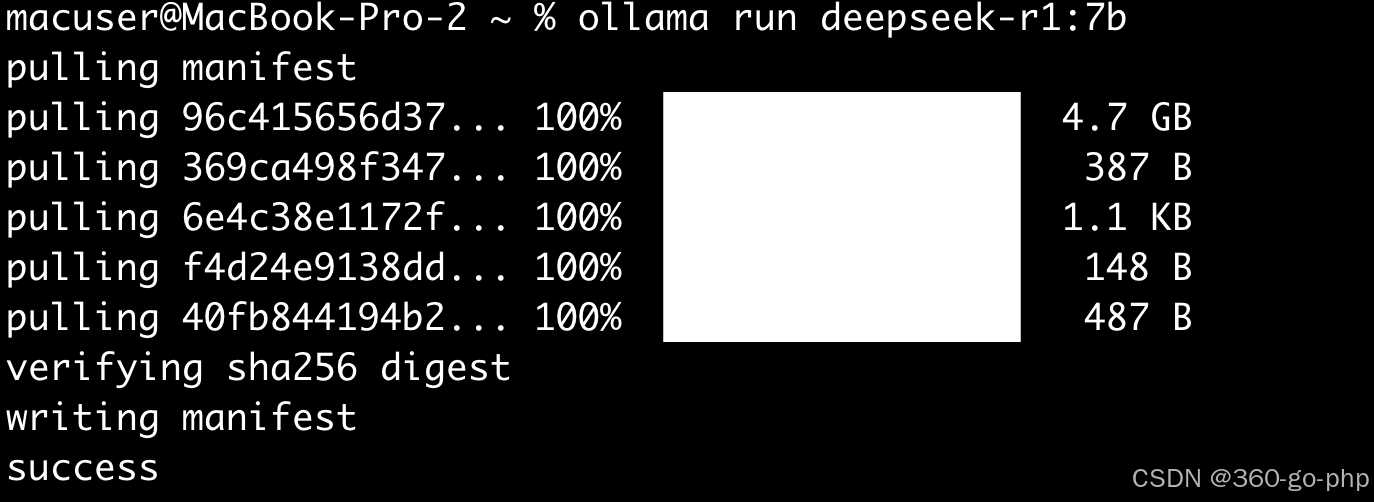
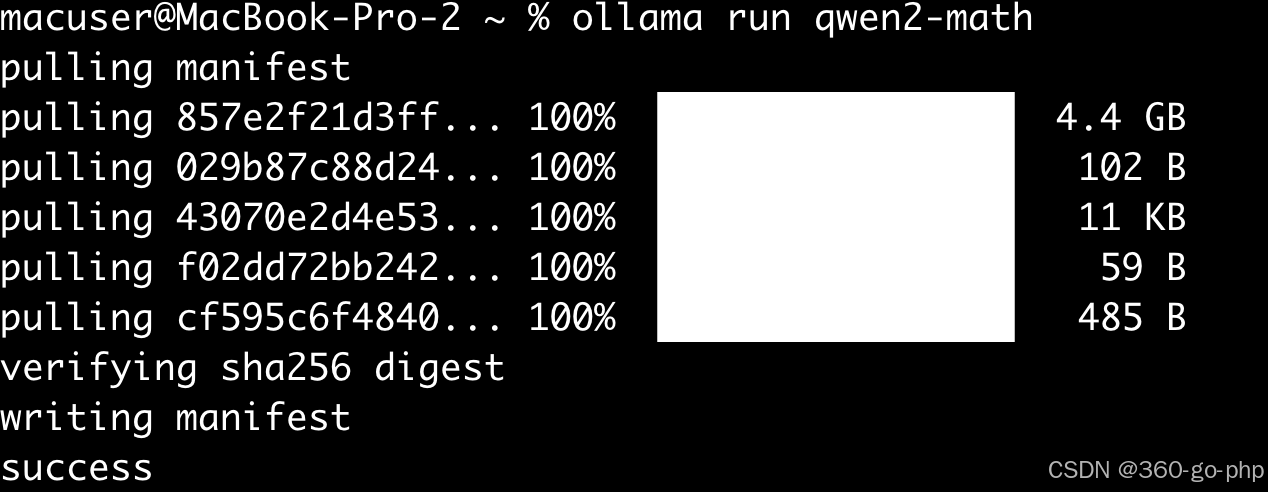
确保模型已经正确下载并存储在本地。
### 3.2 查看已下载的模型
下载完成后,你可以查看已安装的模型列表,确保它们已经准备好使用:
```bash
ollama list
```
如果你看到类似的模型列表,表示模型已成功下载并就绪。
## 4. 使用模型
加载并下载模型后,你可以开始使用它们进行推理。Ollama 提供了简便的命令行工具来与模型进行交互。
### 4.1 与模型对话
以 Llama 3.2 模型为例,启动交互模式:
```bash
ollama chat --model llama:3.2
```
接着,输入你想要与模型进行对话的问题或任务,模型将生成相应的答案或输出。
### 4.2 调用模型进行推理
如果你需要通过编程接口调用模型(例如在 Python 中),Ollama 也支持 HTTP API 或 SDK,可以通过相关文档了解如何进行集成。
一个简单的例子是在 Python 中使用 `requests` 调用 API:
```python
import requests
response = requests.post('http://localhost:5000/ask', json={'model': 'llama:3.2', 'prompt': '你好,Llama 3.2!'})
print(response.json())
```
这样你就可以在 Python 程序中直接调用本地部署的模型。
## 5. 使用实践
### 5.1 性能优化
在本地运行模型时,可能会遇到一些性能瓶颈,尤其是当运行较大的模型时。为确保模型的高效运行,以下是一些优化建议:
- **硬件要求**:确保你的计算机有足够的 GPU 支持(如NVIDIA CUDA GPU)。如果没有 GPU,模型的推理速度可能会受到限制。
- **内存优化**:对于大模型,可能需要更多的内存。可以通过调整批处理大小(batch size)来优化内存使用。
- **并行处理**:如果你有多台机器或多个 GPU,可以尝试将推理任务分配到多个节点上进行并行处理,提升速度。
### 5.2 多模型切换
Ollama 允许你在多个本地模型之间切换。如果你需要使用不同的模型,只需使用 `ollama pull` 下载并通过 `ollama chat --model` 切换。例如:
```bash
ollama chat --model deepseek:7b
```
### 5.3 调整模型参数
对于一些高级用户,Ollama 还允许对模型的推理参数进行调整,例如温度、最大生成长度等,以控制生成内容的多样性和长短。可以在交互模式中尝试:
```bash
ollama chat --model llama:3.2 --temperature 0.7 --max_length 150
```
这些参数将影响模型生成文本的风格和长度。
## 6. 总结
使用 Ollama 来在本地安装和运行 AI 模型非常简便,能够为你提供灵活且高效的推理环境。通过下载模型、加载并调用它们,你可以开始进行各种实践,比如聊天机器人、文本生成或其他任务。
对于需要高效计算的大型模型,确保拥有合适的硬件支持并根据需要进行性能优化。希望这篇文章能帮助你顺利进行本地模型的安装与使用!

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)