阿里开源端到端多模态大模型:Qwen2.5-Omni-7B 值得围观
Qwen2.5-Omni在多模态任务中表现出色,不仅在需要集成多种模态的复杂任务中表现出色,而且在单模态任务中也展现了强大的性能。其创新的架构和位置嵌入方法使其在实时交互和语音生成方面具有显著优势。未来,Qwen团队计划进一步提升模型的性能和输出能力,以推动人工通用智能(AGI)的发展。
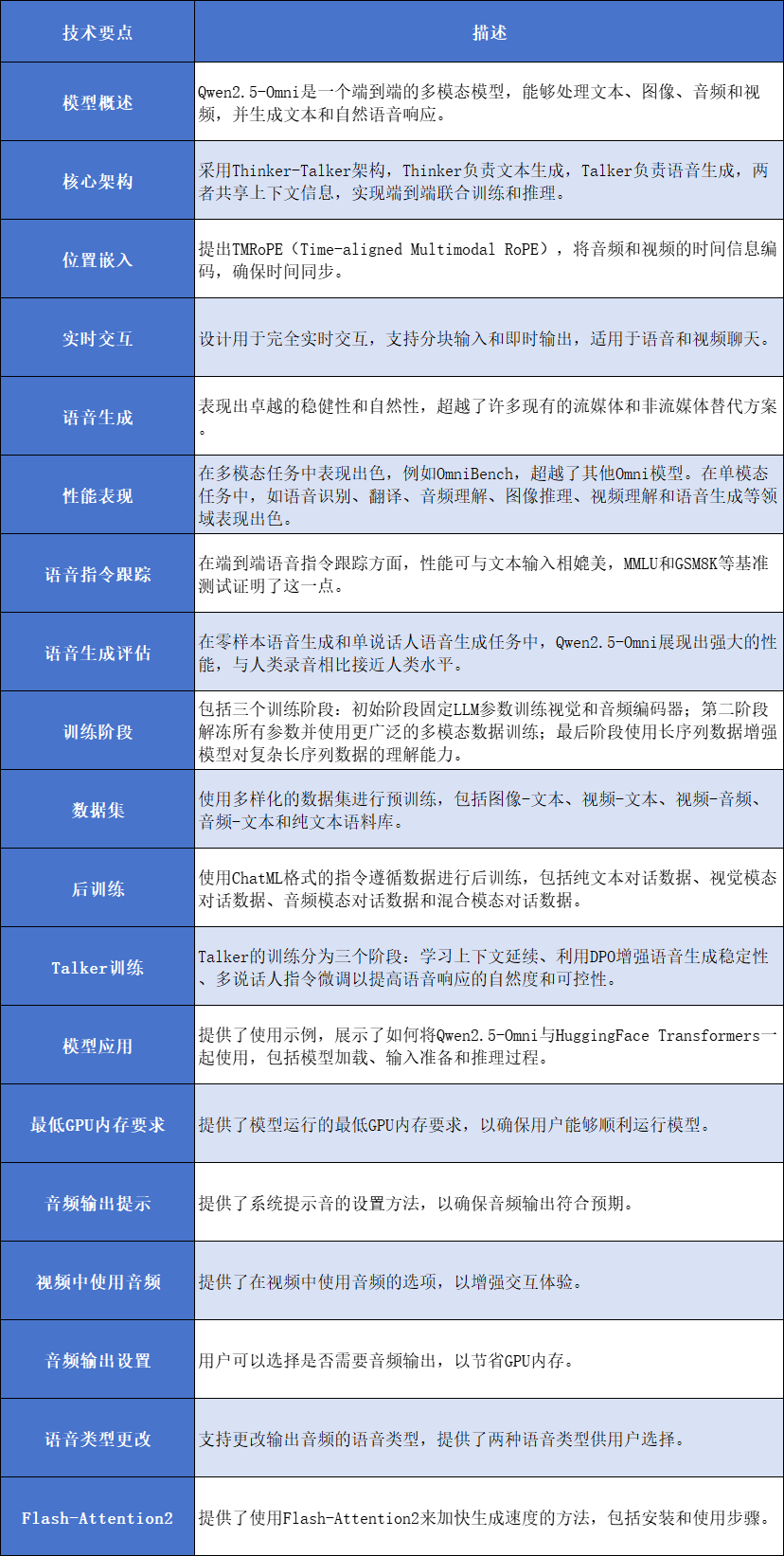
Qwen2.5-Omni是一个强大的端到端多模态模型,能够感知和处理文本、图像、音频和视频等多种模态信息,并以流式方式生成文本和自然语音响应。该模型由Qwen团队开发,采用了创新的Thinker-Talker架构和TMRoPE位置嵌入方法,以实现不同模态间的同步和融合。
Qwen2.5-Omni的关键特点和性能表现
核心架构与创新
Thinker-Talker架构:将文本生成和语音生成分开处理,Thinker负责文本生成,Talker负责语音生成,二者共享上下文信息,实现端到端的联合训练和推理。
TMRoPE位置嵌入:一种新的位置嵌入算法,将音频和视频的时间信息编码,确保二者的时间同步,提升多模态信息的整合能力。
性能表现
多模态任务:
在Omni-Bench等多模态基准测试中,Qwen2.5-Omni取得了最先进的性能,超越了其他Omni模型。
单模态任务:
文本处理:在MMLU、GSM8K等基准测试中,与Qwen2.5-7B等模型表现相当。
音频处理:在语音识别(ASR)、语音到文本翻译(S2TT)等任务中,优于Whisper-large-v3等模型。
图像处理:在MMMU、MMBench等视觉推理任务中,与Qwen2.5-VL-7B表现相当,超越其他开源Omni模型。
视频处理:在Video-MME、MVBench等视频理解任务中,优于其他开源Omni模型和GPT-4o-Mini。
语音生成:在零样本语音生成和单说话人语音生成任务中,Qwen2.5-Omni展现出卓越的稳健性和自然性,与人类录音相比接近人类水平。
使用
Qwen2.5-Omni提供了便捷的工具包,支持处理各种类型的音频和视频输入,包括base64、URL以及交错音频、图像和视频。用户可以通过简单的代码片段,利用HuggingFace Transformers库轻松调用模型进行多模态交互。
总结
Qwen2.5-Omni在多模态任务中表现出色,不仅在需要集成多种模态的复杂任务中表现出色,而且在单模态任务中也展现了强大的性能。其创新的架构和位置嵌入方法使其在实时交互和语音生成方面具有显著优势。未来,Qwen团队计划进一步提升模型的性能和输出能力,以推动人工通用智能(AGI)的发展。
技术要点

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 5
5 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)