java怎么实现华为云文字识别,华为云语音识别:一句话识别API调用
最近想做一个智能硬件(实现单片机使用W600连接上位机或直接实现语音识别)查看了华为云的语音交互服务SIS,有两种:录音文件识别以及一句话语音识别名称功能录音文件识别可以实现5小时以内的音频到文字的转换。支持垂直领域定制,对应领域转换效果更佳。一句话识别可以实现语音到文字的转换。支持垂直领域定制,对应领域转换效果更佳。在看了这两种模式后,选择了一句话识别,方便在下位机方面进行开发(前些时间已经实现
最近想做一个智能硬件(实现单片机使用W600连接上位机或直接实现语音识别)
查看了华为云的语音交互服务SIS,有两种:录音文件识别以及一句话语音识别
名称
功能
录音文件识别
可以实现5小时以内的音频到文字的转换。支持垂直领域定制,对应领域转换效果更佳。
一句话识别
可以实现语音到文字的转换。支持垂直领域定制,对应领域转换效果更佳。
在看了这两种模式后,选择了一句话识别,方便在下位机方面进行开发(前些时间已经实现STM32对语音文件实现8K采样率16bit的PCM格式WAV文件生成)
跳转到一句话识别的API介绍(https://support.huaweicloud.com/api-sis/api-sis.pdf),发现使用时需要先获取该用户的token(呃 通过拨打华为云的客服电话解决了这个问题)
获取用户Token采用POST方式,地址格式为:
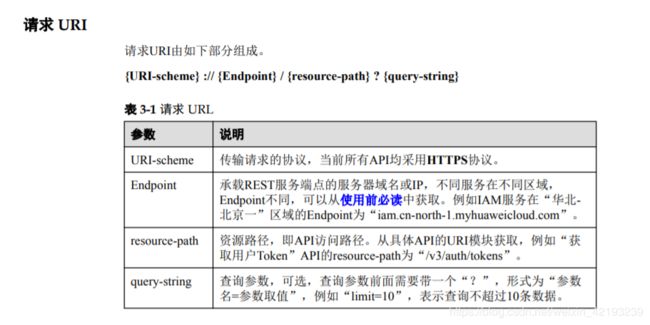
针对不同的服务端点选择Endpoint,后缀是相同的/v3/auth/tokens
此时使用华为云推荐的软件(Postman)来实现这个过程

使用这个地址, 进行提交

此时会反馈你的Token(只能使用24小时),如果打算长期使用请选择SDK (https://support.huaweicloud.com/sdkreference-sis/sis_05_0004.html),目前只有JAVA格式的,本文主要介绍API方式
得到Token就可以进行语音识别啦!!这里还是使用POST的方式,此时地址会发送改变,一句话语音识别的两个服务端点为:
区域名称
终端节点(Endpoint)
华北-北京一
sis-ext.cnnorth-1.myhuaweicloud.com
华北-北京四
sis-ext.cnnorth-4.myhuaweicloud.com
因为我的是华北-北京四,这里选择sis-ext.cnnorth-4.myhuaweicloud.com,继续查看该API手册,发现对于提交语音数据的包格式定义如下:

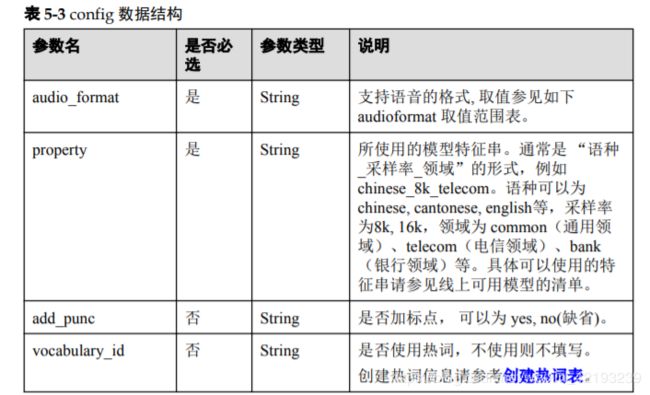
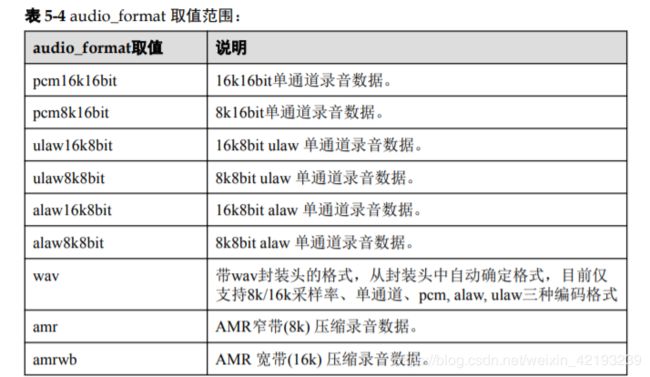
此时POST地址为: https://sis-ext.cn-north-4.myhuaweicloud.com/v1/{projectid}/asr/short-audio
获取Projectid的方式:将光标放在用户名下面选择我的凭证:
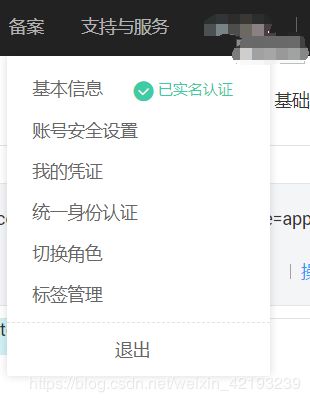
得到projectid后开始发包:
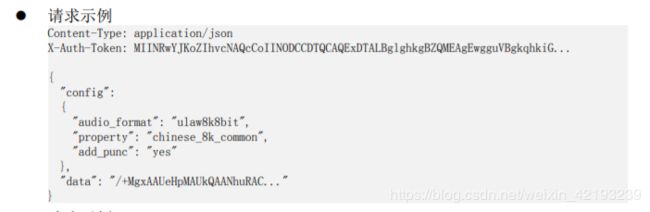
我采用的是WAV自识别模式,使用的WAV文件为AU生成的录音文件,利用BASE64编码转换后进行发送:
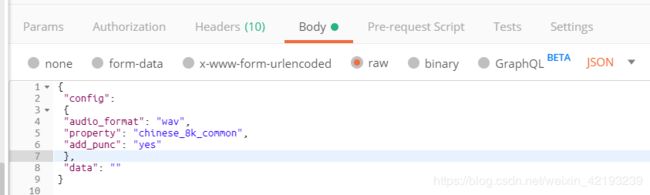
data数据为转码后的base64格式,因为太长就不放上来了。此时点击SEND
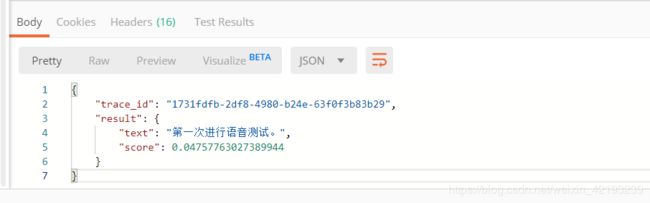
测试成功,本篇结束。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)