openclaw 异常之 increase agents.defaults.timeoutSeconds in your config.
OpenClaw调用本地Ollama模型进行CPU推理时出现超时问题,错误提示请求在生成响应前超时。日志显示模型加载过程正常(约3.73秒完成),但后续API请求耗时59.9秒后返回500错误。解决方法是在OpenClaw配置文件中增加llm空闲超时参数:修改/root/.openclaw/openclaw.json,在agents.defaults.llm下添加idleTimeoutSecond
目录
异常回复
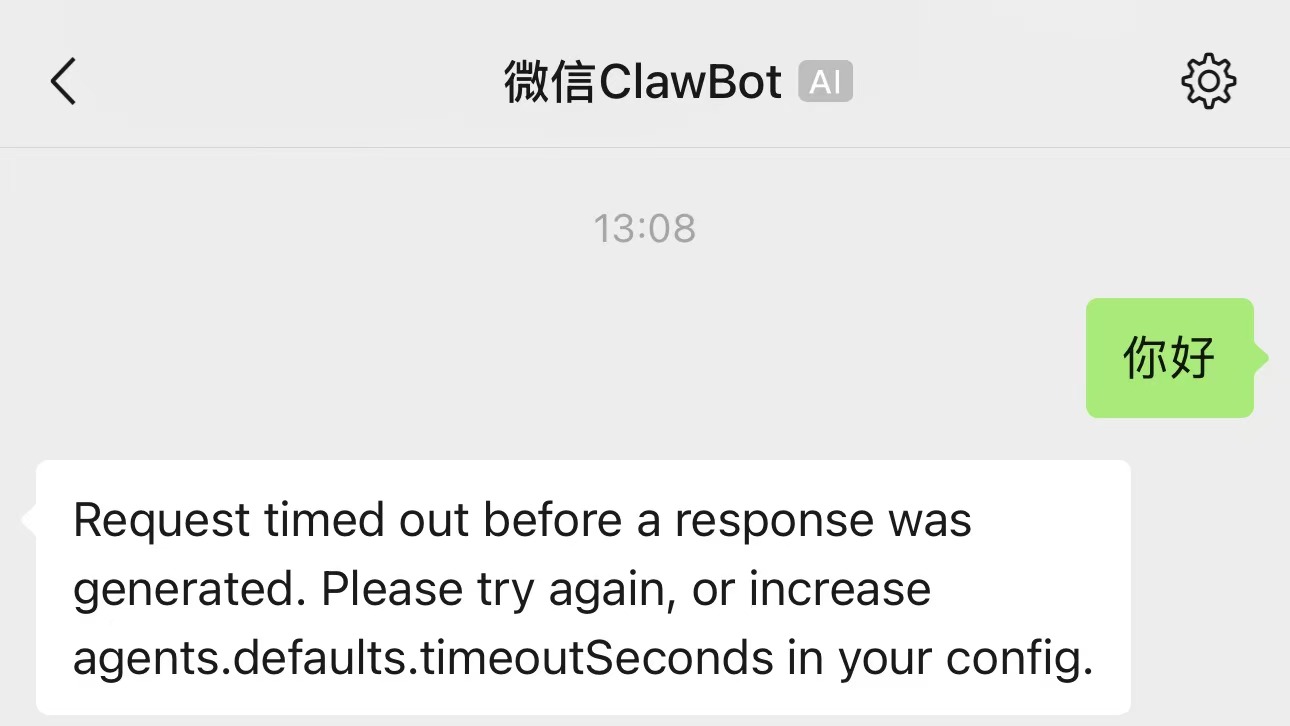
openclaw 调用本地 ollama 模型进行 cpu 推理时遇到如下回复
Request timed out before a response was generated. Please try again, or increase agents.defaults.timeoutSeconds in your config.
openclaw日志
查看 openclaw 日志,显示如下
[agent] Profile ollama:default timed out. Trying next account...

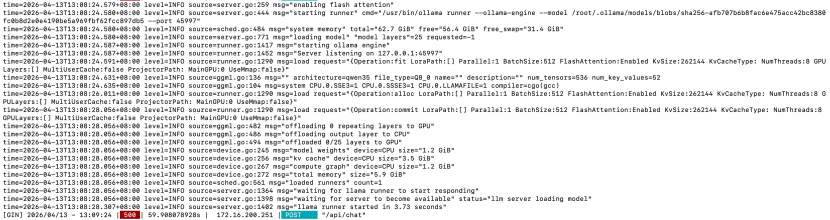
ollama日志
查看 ollama 日志,显示如下
time=2026-04-13T13:08:24.579+08:00 level=INFO source=server.go:259 msg="enabling flash attention"
time=2026-04-13T13:08:24.580+08:00 level=INFO source=server.go:444 msg="starting runner" cmd="/usr/bin/ollama runner --ollama-engine --model /root/.ollama/models/blobs/sha256-afb707b6b8fac6e475acc42bc8380fc0b8d2e0e4190be5a969fbf62fcc897db5 --port 45997"
time=2026-04-13T13:08:24.580+08:00 level=INFO source=sched.go:484 msg="system memory" total="62.7 GiB" free="56.4 GiB" free_swap="31.4 GiB"
time=2026-04-13T13:08:24.580+08:00 level=INFO source=server.go:771 msg="loading model" "model layers"=25 requested=-1
time=2026-04-13T13:08:24.587+08:00 level=INFO source=runner.go:1417 msg="starting ollama engine"
time=2026-04-13T13:08:24.587+08:00 level=INFO source=runner.go:1452 msg="Server listening on 127.0.0.1:45997"
time=2026-04-13T13:08:24.591+08:00 level=INFO source=runner.go:1290 msg=load request="{Operation:fit LoraPath:[] Parallel:1 BatchSize:512 FlashAttention:Enabled KvSize:262144 KvCacheType: NumThreads:8 GPULayers:[] MultiUserCache:false ProjectorPath: MainGPU:0 UseMmap:false}"
time=2026-04-13T13:08:24.631+08:00 level=INFO source=ggml.go:136 msg="" architecture=qwen35 file_type=Q8_0 name="" description="" num_tensors=536 num_key_values=52
time=2026-04-13T13:08:24.635+08:00 level=INFO source=ggml.go:104 msg=system CPU.0.SSE3=1 CPU.0.SSSE3=1 CPU.0.LLAMAFILE=1 compiler=cgo(gcc)
time=2026-04-13T13:08:26.011+08:00 level=INFO source=runner.go:1290 msg=load request="{Operation:alloc LoraPath:[] Parallel:1 BatchSize:512 FlashAttention:Enabled KvSize:262144 KvCacheType: NumThreads:8 GPULayers:[] MultiUserCache:false ProjectorPath: MainGPU:0 UseMmap:false}"
time=2026-04-13T13:08:28.056+08:00 level=INFO source=runner.go:1290 msg=load request="{Operation:commit LoraPath:[] Parallel:1 BatchSize:512 FlashAttention:Enabled KvSize:262144 KvCacheType: NumThreads:8 GPULayers:[] MultiUserCache:false ProjectorPath: MainGPU:0 UseMmap:false}"
time=2026-04-13T13:08:28.056+08:00 level=INFO source=ggml.go:482 msg="offloading 0 repeating layers to GPU"
time=2026-04-13T13:08:28.056+08:00 level=INFO source=ggml.go:486 msg="offloading output layer to CPU"
time=2026-04-13T13:08:28.056+08:00 level=INFO source=ggml.go:494 msg="offloaded 0/25 layers to GPU"
time=2026-04-13T13:08:28.056+08:00 level=INFO source=device.go:245 msg="model weights" device=CPU size="1.2 GiB"
time=2026-04-13T13:08:28.056+08:00 level=INFO source=device.go:256 msg="kv cache" device=CPU size="3.5 GiB"
time=2026-04-13T13:08:28.056+08:00 level=INFO source=device.go:267 msg="compute graph" device=CPU size="1.2 GiB"
time=2026-04-13T13:08:28.056+08:00 level=INFO source=device.go:272 msg="total memory" size="5.9 GiB"
time=2026-04-13T13:08:28.056+08:00 level=INFO source=sched.go:561 msg="loaded runners" count=1
time=2026-04-13T13:08:28.056+08:00 level=INFO source=server.go:1364 msg="waiting for llama runner to start responding"
time=2026-04-13T13:08:28.056+08:00 level=INFO source=server.go:1398 msg="waiting for server to become available" status="llm server loading model"
time=2026-04-13T13:08:28.307+08:00 level=INFO source=server.go:1402 msg="llama runner started in 3.73 seconds"
[GIN] 2026/04/13 - 13:09:24 | 500 | 59.908078928s | 172.16.200.251 | POST "/api/chat"
解决方法
原因:openclaw 默认超时时长为 60 秒,cpu 推理较慢所以需延长超时时间。
vi /root/.openclaw/openclaw.json
增加"llm": {"idleTimeoutSeconds": 1800}
"agents": {
"defaults": {
"workspace": "/root/.openclaw/workspace",
"model": {
"primary": "xxxxxx"
},
"models": {
"xxxxxx": {}
},
"compaction": {
"mode": "safeguard"
},
"llm": {"idleTimeoutSeconds": 1800}
}
},
Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)