开源的多语言多情感文本转语音(TTS)模型速览:openaudio-s1-mini
OpenAudio S1是一款先进的文本转语音(TTS)模型,支持13种语言,在200万小时音频数据上训练。提供两种模型版本:4B参数的完整版和0.5B参数的mini版。其独特之处在于支持50多种情感表达(如愤怒、快乐、悲伤等),多种语调(如耳语、喊叫)以及特殊声音效果(笑声、哭声等)。模型采用强化学习优化,在语音准确性评测中表现优异,词错误率低至0.008。该技术可用于各类需要自然语音合成的应用
OpenAudio S1
一、总体介绍
OpenAudio S1 是一款先进的文本转语音(TTS)模型,其在多种语言的超过200万小时的音频数据上进行训练,具备强大的语音合成能力。
二、多语言支持
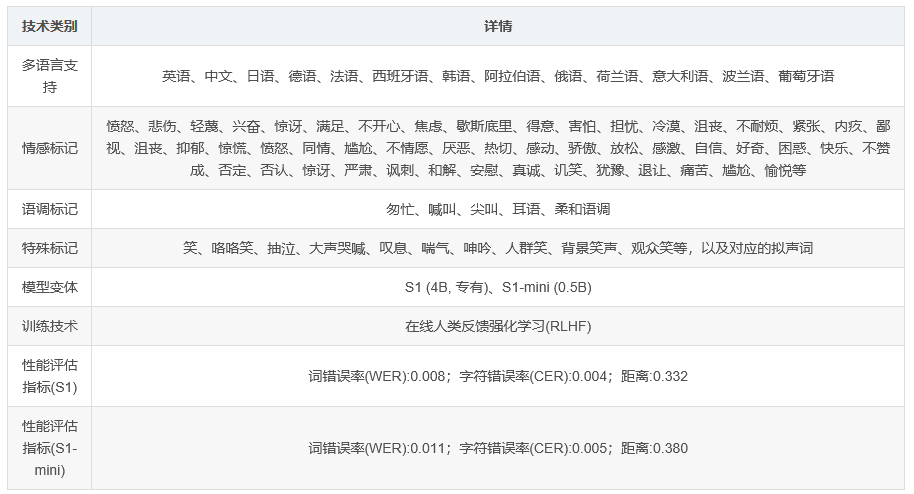
该模型支持多种语言,包括英语(en)、中文(zh)、日语(ja)、德语(de)、法语(fr)、西班牙语(es)、韩语(ko)、阿拉伯语(ar)、俄语(ru)、荷兰语(nl)、意大利语(it)、波兰语(pl)、葡萄牙语(pt),使其能够满足不同语言背景用户的需求。
三、情感和语调支持
OpenAudio S1 提供丰富的情感、语调以及特殊标记,以增强语音合成效果。具体包括:
情感标记
涵盖愤怒(angry)、悲伤(sad)、轻蔑(disdainful)、兴奋(excited)、惊讶(surprised)、满足(satisfied)、不开心(unhappy)、焦虑(anxious)、歇斯底里(hysterical)、得意(delighted)、害怕(scared)、担忧(worried)、冷漠(indifferent)、沮丧(upset)、不耐烦(impatient)、紧张(nervous)、内疚(guilty)、鄙视(scornful)、沮丧(frustrated)、抑郁(depressed)、惊慌(panicked)、愤怒(furious)、同情(empathetic)、尴尬(embarrassed)、不情愿(reluctant)、厌恶(disgusted)、热切(keen)、感动(moved)、骄傲(proud)、放松(relaxed)、感激(grateful)、自信(confident)、好奇(interested)、困惑(confused)、快乐(joyful)、不赞成(disapproving)、否定(negative)、否认(denying)、惊讶(astonished)、严肃(serious)、讽刺(sarcastic)、和解(conciliative)、安慰(comforting)、真诚(sincere)、讥笑(sneering)、犹豫(hesitating)、退让(yielding)、痛苦(painful)、尴尬(awkward)、愉悦(amused)等多种情感。
语调标记
包含匆忙(in a hurry tone)、喊叫(shouting)、尖叫(screaming)、耳语(whispering)、柔和语调(soft tone)等。
特殊标记
包括笑(laughing)、咯咯笑(chuckling)、抽泣(sobbing)、大声哭喊(crying loudly)、叹息(sighing)、喘气(panting)、呻吟(groaning)、人群笑(crowd laughing)、背景笑声(background laughter)、观众笑(audience laughing)等。此外,特殊标记还配有相应的拟声词,例如笑对应“Ha,ha,ha”,咯咯笑对应“Hmm,hmm”。
四、模型变体与性能
OpenAudio S1 包括以下两种模型:
S1 (4B, 专有)
完整尺寸的模型,具备强大的语音合成能力。
S1-mini (0.5B)
S1 的蒸馏版本,虽然模型尺寸较小,但仍能提供良好的语音合成效果。
两种模型均采用在线人类反馈强化学习(RLHF)技术进行训练,以提升模型性能。
在Seed TTS评估指标(基于OpenAI gpt-4o-transcribe的英语自动评估,使用Revai/pyannote-wespeaker-voxceleb-resnet34-LM的说话人距离)方面,S1的词错误率(WER)为0.008,字符错误率(CER)为0.004,距离为0.332;S1-mini的词错误率(WER)为0.011,字符错误率(CER)为0.005,距离为0.380。
五、附加信息
更多详细信息可参考 Fish Speech Github 。演示可在 Fish Audio Playground 进行体验。OpenAudio 网站 提供博客和技术报告。
OpenAudio S1 核心技术汇总

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 24
24 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)