2025年ASR技术前沿:从端到端模型专利到AI语音就业机会,全方位解析自动语音识别的未来
摘要:AI大模型推动自动语音识别(ASR)技术革新,端到端模型突破传统级联架构局限。开源工具Wenet-e2e等提供工业级解决方案,全链路对话模型将延迟降至650ms。2025年全球语音市场预计超500亿美元,开发者可通过GitHub资源库入门,关注多模态融合和低延迟优化等趋势,把握语音AI时代机遇。
在AI大模型时代,自动语音识别(ASR)技术正迎来爆发式创新。从智能手机助手到智能家居,再到企业级语音评估系统,ASR不仅仅是“听懂”人类说话,更是实现自然交互的核心引擎。根据最新行业报告,到2025年,全球语音技术市场规模预计将超过500亿美元。本文将基于前沿专利、开源资源、基准测试和开发者洞察,带你深入探索ASR的最新进展,并分享如何抓住这一波AI语音浪潮的就业机会。无论你是技术爱好者还是从业者,这篇文章将为你提供实用指南。
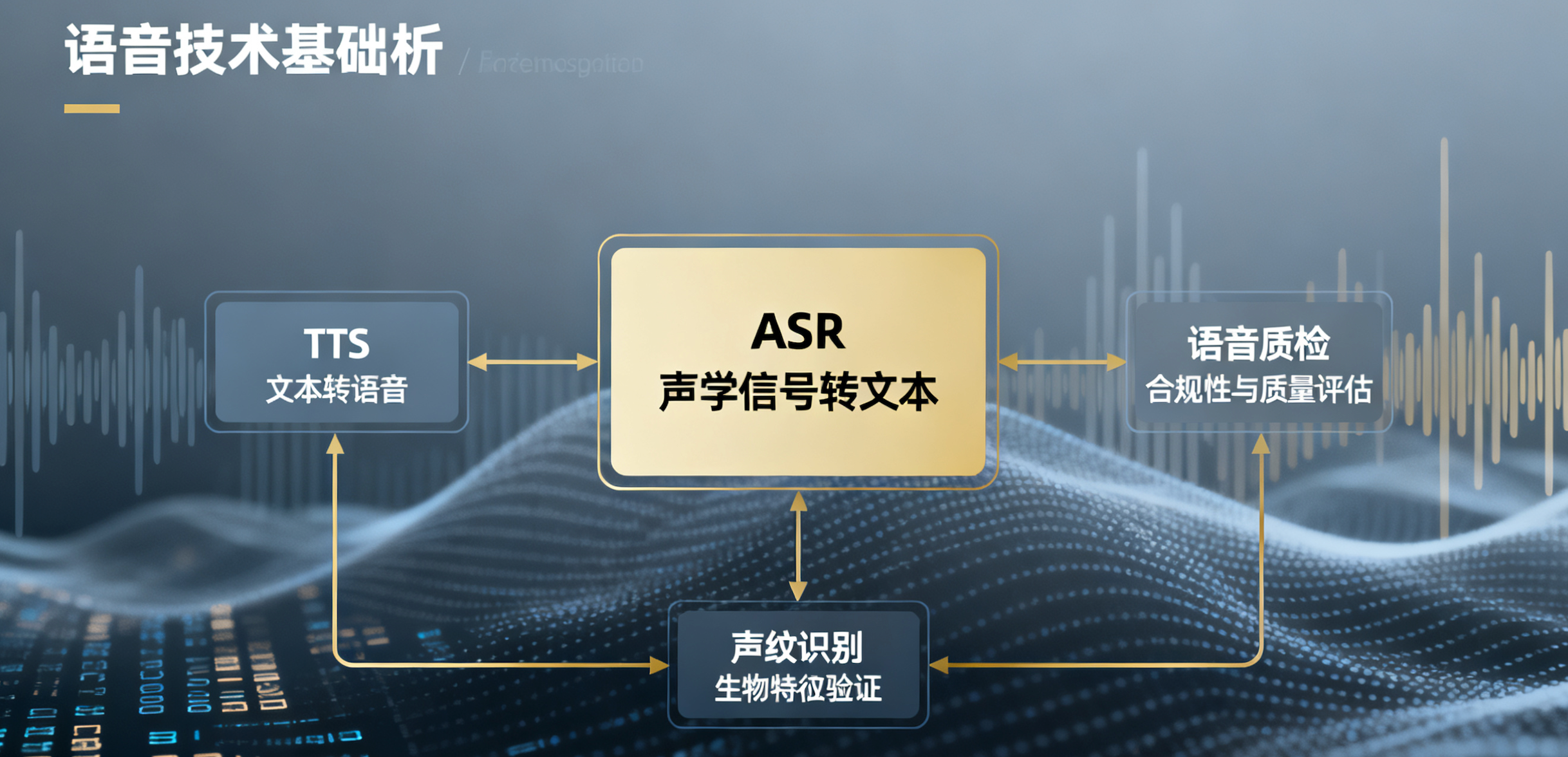
1.语音技术基础:ASR、TTS、质检与声纹详解
ASR是 自动语音识别(Automatic Speech Recognition)的缩写。 它的核心任务是将一段语音的声学信号自动转换为对应的文本。您可以将其理解为让计算机“听懂”人说的话。
TTS是一种将文本数据转换为可听见的语音输出的AI技术,它让计算机或其他设备能够“读出”文字,实现人机自然交互。
语音质检是指利用AI技术对语音通话或录音进行自动化分析和评估的过程,主要用于检查合规性、质量和服务水平。它将语音转换为文本后,通过规则或模型检测问题,取代传统人工抽检,提高效率和覆盖率。
声纹识别也称说话人识别(Speaker Recognition),是一种生物识别技术,通过分析声音中的独特生理和行为特征(如声带振动、口腔结构)来验证或识别个人身份。每个人的声纹如指纹般唯一,即使模仿也难以复制。
2.ASR技术演进:端到端模型的突破
2.1 传统ASR架构
传统ASR系统依赖级联架构,如GMM-HMM模型,但它存在模块隔离、误差累积的问题。
2.2 端到端LSTM和CTC的架构
近年来,端到端(E2E)模型成为主流,常见的端到端 ASR 模型包括 DeepSpeech、Wav2Vec 等。
例如结合LSTM和CTC的架构,能直接从音频输入映射到文本输出,简化流程并提升准确率。
一项2022年发布的中文专利(CN114863914A)提出了一种深度学习方法,用于构建端到端语音评测模型。发明人包括黎天宇、张句等,该模型使用Fbank特征提取、LSTM+CTC声学模型,并集成语言模型进行解码。关键优势在于多维度评估(如音素、语调、流利度),准确率通过编辑距离计算,流利度公式为:流利度 = (最小操作数) / 目标句子长度。该专利强调E2E优化,避免传统级联错误,适用于智能语音产品测试和语言学习App。
2.3 智能家居设备的部署
在实际部署中,通过使用 PyTorch 对端到端 ASR 模型通过模型剪枝、量化和知识蒸馏等轻量化技术能够显著减小模型的大小和计算复杂度,提高模型在资源受限环境中的部署效率,显著降低了计算资源需求,支持高精度、低延迟设备。例如,在嘈杂环境中,通过数据增强(如添加10,000种噪声样本),识别准确率可提升15%以上。这为开发者提供了从研究到生产的桥梁。
3. ASR开源资源宝库:从论文到工具一网打尽
如果你是ASR初学者或研究者,GitHub仓库“ASR_awesome”是一个必备资源库。它汇集了语音识别的前沿论文、工具和数据集,聚焦E2E模型如CTC、AED和RNN-T。仓库强调工业级解决方案,如Wenet-e2e工具包,解决流式处理、语言模型集成和端点检测等问题。
顶级资源包括:
- Wenet-e2e:生产级ASR工具,支持流式、低延迟部署。
- Efficient Conformer with Prob-Sparse Attention:基于概率稀疏注意力的高效模型,推理速度提升8%-45%,内存节省15%-45%。
- The People's Speech Dataset:30,000小时多样化英语语音数据集,可商用。
- Casual Conversations Dataset:注重公平性,包含性别、年龄等元数据,用于偏置评估。
- Wav2vec 2.0:自监督学习模型,支持跨语言ASR。
这个仓库特别适合AI爱好者,涵盖从上下文偏置(如识别专有名词)到多模态融合(如音频-视觉ASR)。通过这些资源,你可以快速搭建原型,例如使用TensorFlow Lingvo框架训练自定义模型。
4.全链路对话模型:从ASR到TTS的基准测试与优化
在AI基准测试中,全链路对话模型(ASR + LLM + TTS)正成为焦点。传统级联架构响应延迟高(3秒+),而大模型如GPT-4驱动的端到端系统可将延迟降至500-600ms。
关键基准指标:
- ASR准确率:安静环境93%以上,嘈杂环境55%(需优化降噪)。
- LLM首字延迟:轻量模型几十ms,GPT-4约2秒。
- TTS首字节延迟:顶级厂商100ms。
- 全链路延迟:声网引擎中位数650ms,极限打断340ms。
优化方法包括流式输出、智能VAD(降低85%中断率)和端云协同。评测平台对比显示,腾讯云ASR + 阿里通义千问Turbo LLM + 火山引擎TTS是最优组合,总延迟1125.36ms。这对开发者意味着:在车载交互或智能客服中,低延迟是关键竞争力。
5.开发者关心的话题:级联 vs 端到端、全双工与商业模式
语音AI开发者痛点:级联架构(ASR+LLM+TTS)灵活但延迟高,全双工端到端模型(如SoulX-Voice V2)实现无VAD嵌入,支持实时打断。开发者关注方言语种支持、低资源语言基准(如OpenASR20)和商业模式(底层技术 vs 垂直行业)。
例如,智谱MaaS平台提供实时音视频交互,融合多模态(音频+视频),记忆上限2分钟。挑战包括多模型集成和情绪识别,未来趋势是自适应路由和多智能体协同。
6.结语:抓住2025 ASR浪潮
2025年将是Voice Agent元年,端到端模型和多模态融合将重塑行业。无论是探索专利创新,还是利用开源资源搭建系统,都能让你领先一步。建议从ASR_awesome仓库起步,结合基准测试优化项目。如果你正求职,大模型语音识别的岗位值得关注。欢迎在评论区分享你的ASR经验,一起推动语音AI发展!
参考文章

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)