GLM-4.6V:多模态大模型首次打通“看图—理解—执行”闭环
GLM-4.6V开源,首次在视觉大模型中原生集成工具调用能力,实现从图像感知到可执行动作的端到端闭环,支持图文创作、识图购物、前端复刻与长文档视频理解四大典型场景,9B轻量版免费开放。

前言
多模态大模型在过去两年经历了从“能看”到“会想”的演进,但真正落地到复杂业务场景时,仍面临一个核心瓶颈:模型即便理解了图像内容,也难以直接触发后续操作。传统方案依赖人工设计中间转换逻辑,将视觉信息转为文本再交由工具调用模块处理,不仅效率低下,还容易丢失关键细节。智谱此次发布的 GLM-4.6V 系列,正是试图打破这一割裂状态。它不再满足于“看懂图片”,而是让模型具备“看完就能动手”的能力——图像可直接作为工具参数,工具返回的视觉结果也能被再次理解并纳入推理链路。这种原生多模态工具调用架构,标志着多模态 Agent 从概念走向实用的关键一步。更值得开发者关注的是,其轻量版 GLM-4.6V-Flash 不仅性能超越同规模竞品,还完全免费开放,大幅降低了多模态应用的实验门槛。本文将系统拆解 GLM-4.6V 的技术突破、能力边界与典型应用场景,并探讨这一范式对开发者工作流可能带来的深远影响。
1. 多模态模型的能力跃迁:从感知到行动
1.1 传统多模态工具调用的断层问题
过去大多数多模态系统采用“视觉→文本→工具”的串行架构。用户上传一张商品截图,模型首先生成文字描述如“蓝色连帽卫衣”,再将该描述传递给搜索接口。这一过程存在明显缺陷:
- 视觉细节(如纹理、剪裁、品牌Logo)在文本化过程中被简化或丢失;
- 工具返回的结果(如商品列表含图片)需再次转为文本供模型分析,形成二次信息损耗;
- 整个链路涉及多个模块协同,工程复杂度高,调试困难。
这种割裂导致模型无法形成真正的“感知-决策-执行”闭环,更像是一个被动的信息翻译器,而非主动的问题解决者。
1.2 GLM-4.6V 的原生多模态工具调用架构
GLM-4.6V 从根本上重构了这一流程,提出“图像即参数,结果即上下文”的设计理念。其核心在于:
- 工具调用接口直接接受原始图像、截图或多页PDF作为输入参数,无需前置OCR或描述生成;
- 工具执行后返回的视觉内容(如检索到的商品图、生成的图表)可被模型直接解析,并作为后续推理的上下文;
- 整个过程在一个统一的128k上下文窗口内完成,避免跨模块状态同步问题。
这种设计使得模型能像人类一样,在看到图片后直接“动手”操作——比如圈出设计稿中的按钮并修改颜色,或对比多家平台的商品图后生成导购清单。笔者认为,这不仅是技术实现的优化,更是智能体交互范式的转变:模型从“回答问题”升级为“完成任务”。
2. 四大典型场景的技术实现逻辑
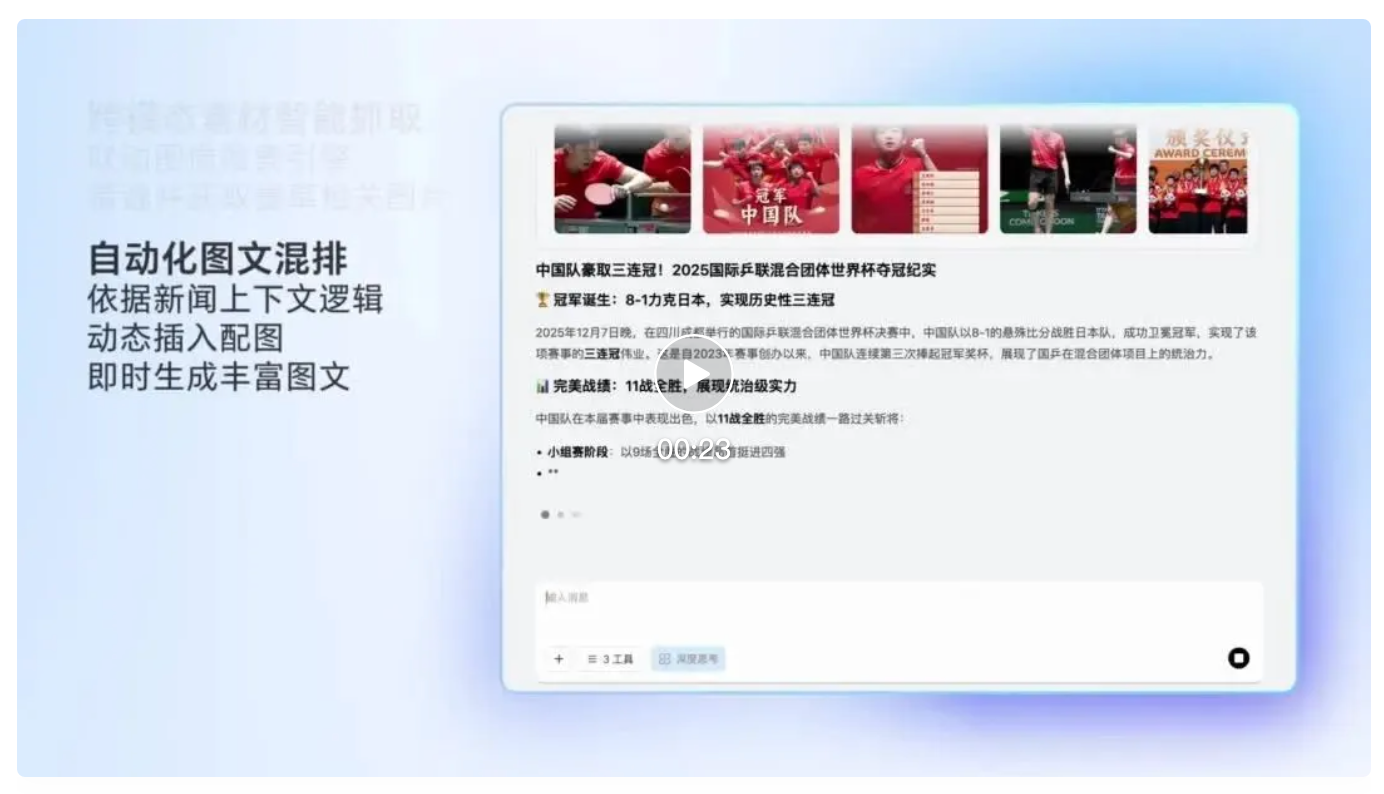
2.1 智能图文混排与内容创作
在内容生产场景中,GLM-4.6V 展现出端到端的自动化能力:
- 输入可为纯文本主题、图文混排PDF或PPT;
- 模型自动识别关键信息点(如数据图表、公式、结论段落);
- 调用内部检索工具,为每一段落匹配候选配图;
- 对候选图进行视觉相关性评分,剔除低质或无关图片;
- 输出结构化Markdown或HTML,包含精准嵌入的图文组合。
这一流程中,所有步骤均由单一模型完成,无需外部编排。我的体会是,这种能力将极大解放内容运营人员,使其从繁琐的素材筛选与排版中抽身,专注于创意本身。
2.2 视觉驱动的识图购物与导购 Agent
电商场景是检验多模态任务能力的试金石。GLM-4.6V 在此场景下的处理链路如下:
- 用户上传街拍图并指令“搜同款”;
- 模型识别服装品类、颜色、风格等视觉特征;
- 自主调用 image_search 工具,对接多个电商平台API;
- 接收各平台返回的非结构化结果(含商品图、价格、标题);
- 执行跨平台字段对齐、去重与噪声过滤;
- 生成标准化导购表,含缩略图、价格、匹配度说明及跳转链接。
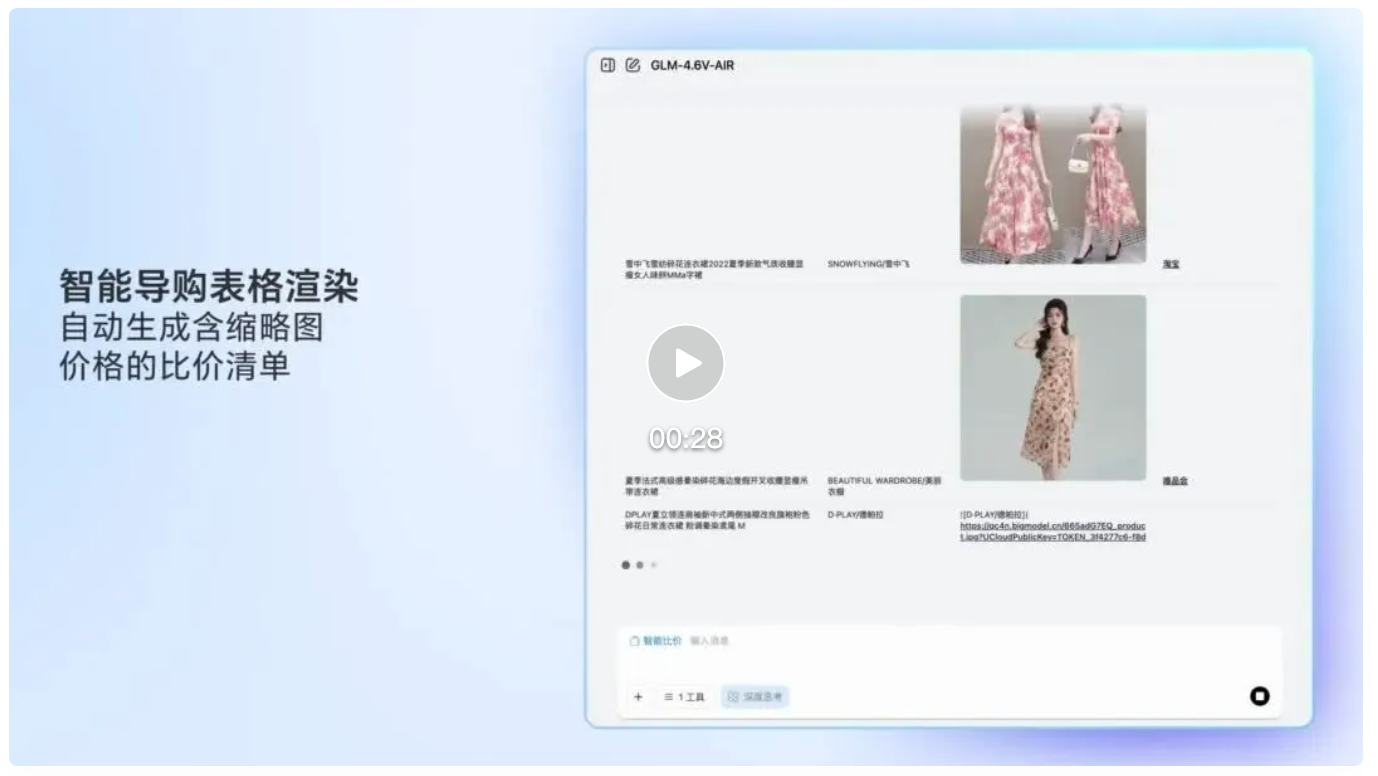
值得注意的是,模型能理解“相似但不相同”的差异,例如指出“该商品袖口设计略有不同”。这种细粒度比对能力,依赖于其对视觉特征的深度编码,而非简单关键词匹配。
2.3 前端复刻与多轮视觉交互开发
前端开发长期存在“设计稿到代码”的鸿沟。GLM-4.6V 通过像素级还原与交互式调试弥合这一差距:
- 上传网页截图后,模型解析布局结构、组件类型、色彩值与字体;
- 生成高保真 HTML/CSS/JS 代码,还原度接近人工水平;
- 支持基于新截图的迭代指令,如“将导航栏高度增加20px”;
- 模型定位对应代码区域并自动修正,实现“所见即所得”的开发体验。
笔者观察到,这一能力若集成至Figma或VS Code插件,将显著缩短UI开发周期。尤其对于重复性高的营销页面,自动化生成可节省大量人力。
2.4 长上下文的文档与视频理解
128k上下文窗口赋予 GLM-4.6V “过目不忘”的记忆能力:
- 单次推理可处理约150页PDF或1小时视频;
- 跨文档抽取关键指标(如四家财报的营收、利润率);
- 理解图表中的隐性趋势(如折线图拐点对应的业务事件);
- 在长视频中定位关键事件(如足球比赛进球时刻),生成时间轴摘要。
这种能力突破了传统多模态模型只能处理单帧或短片段的限制。我的感受是,长上下文+视觉理解的组合,为知识密集型任务(如法律尽调、医学影像分析)提供了新的自动化可能。
3. 性能、成本与开源生态
3.1 同规模下的SOTA表现
GLM-4.6V 在30+多模态基准测试中验证其领先性:
| 模型版本 | 参数规模 | 关键评测表现 |
|---|---|---|
| GLM-4.6V-Flash | 9B | 超越 Qwen3-VL-8B |
| GLM-4.6V (106B-A12B) | 106B(12B激活) | 比肩 Qwen3-VL-235B(2倍参数量) |
尤其在 MMBench(综合视觉理解)、MathVista(数学图表推理)和 OCRBench(复杂文档识别)上,其得分显著领先同代产品。这表明模型不仅在通用理解上优秀,在专业领域也具备深度推理能力。
3.2 成本与部署灵活性
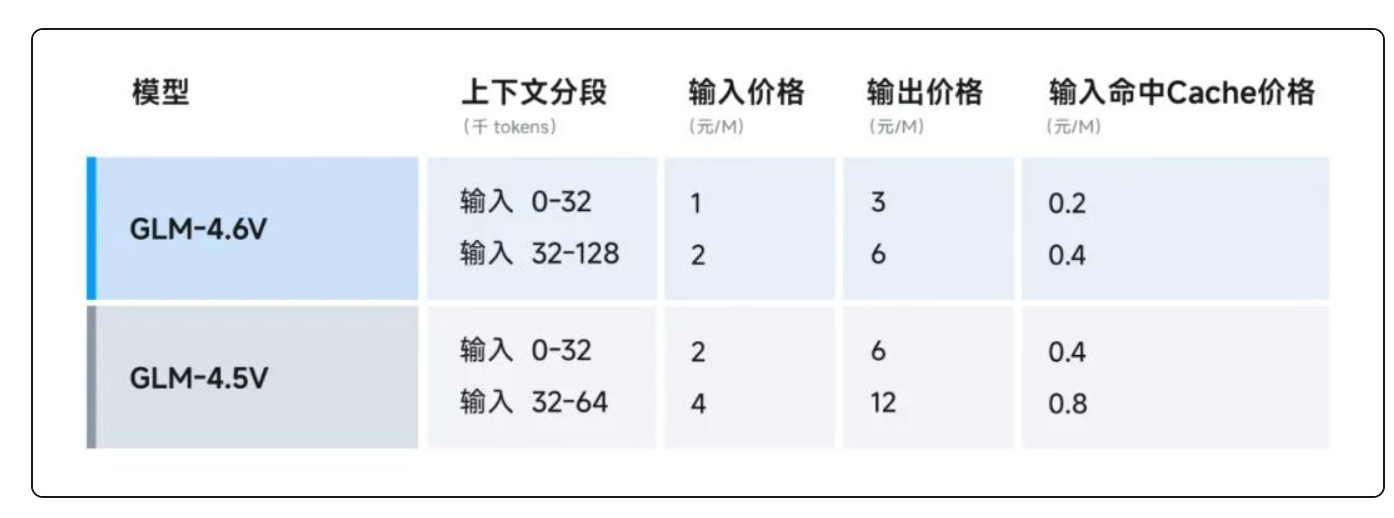
智谱大幅降低使用门槛:
- API 价格降至输入1元/百万tokens,输出3元/百万tokens,较上一代降价50%;
- GLM-4.6V-Flash 完全免费开放,适合本地部署与低延迟场景;
- 支持 SGLang、vLLM、transformers 等主流推理框架;
- 兼容 GPU 与国产 NPU(如昇腾),适配多样化硬件环境。
这种“高性能+低成本+多硬件支持”的策略,有望加速多模态技术在中小企业和研究机构的普及。
3.3 开源资源与开发者支持
模型权重、推理代码与示例工程已在三大平台开放:
- GitHub:提供基础推理与微调脚本;
- Hugging Face:支持一键加载与推理;
- 魔搭社区:集成国产芯片优化方案。
此外,GLM Coding Plan 提供8类专用 MCP 工具,覆盖电商、金融、教育等场景,开发者可直接调用预置接口,无需从零构建工具链。
4. 技术启示与行业影响
4.1 多模态Agent的工程范式转变
GLM-4.6V 的原生工具调用能力,正在推动多模态Agent从“模块拼接”走向“一体化推理”。过去需要编排视觉模型、LLM、工具网关等多个服务,现在只需一个模型即可完成端到端任务。这种简化不仅降低开发成本,也提升系统鲁棒性。笔者认为,未来多模态Agent的核心竞争力,将不再仅仅是理解精度,而是“感知-决策-执行”闭环的流畅度与可靠性。
4.2 对开发者工作流的潜在重塑
前端、内容运营、电商运营等岗位的工作方式可能被重新定义:
- 设计师可直接用自然语言修改自动生成的页面;
- 运营人员上传竞品报告,模型自动生成对比分析图;
- 买手上传时尚杂志页,模型推荐供应链匹配商品。
这些场景的共性是:人类提供意图与素材,模型负责执行与产出。我的推断是,随着此类模型普及,人机协作的重点将从“操作工具”转向“定义任务”。
4.3 开源策略背后的生态考量
智谱选择开源轻量版并大幅降价API,意在快速建立开发者生态。免费的 GLM-4.6V-Flash 降低了实验门槛,吸引更多团队尝试多模态应用;而高性能版则通过性价比优势争夺企业客户。这种“开源引流+商业变现”的双轨策略,与早期 Hugging Face 和 Llama 的路径相似。业界公认,模型的真正价值不仅在于技术指标,更在于其能否催生丰富的上层应用。GLM-4.6V 的工具调用原生支持,正是为应用创新铺设基础设施。
多模态大模型正从“看得见”迈向“做得成”。GLM-4.6V 通过原生集成工具调用,首次在开源模型中实现了视觉感知到可执行行动的完整闭环。它不再是一个被动的回答者,而是一个能看图、会思考、可动手的数字助手。当模型能直接操作世界,而不仅是描述世界,人机协作的边界就被彻底拓宽了。技术的意义,终究在于解放人的创造力——而 GLM-4.6V 正在为此铺路。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 11
11 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)