【AI大模型前沿】Bee:腾讯混元与清华联合开源的全栈多模态大模型创新项目
Bee是由腾讯混元团队与清华大学联合推出的全栈开源多模态大模型解决方案,旨在通过提升数据质量来缩小开源模型与闭源模型之间的性能差距。该项目包含三大核心成果:首先是1500万规模的高质量双层CoT数据集Honey-Data-15M,它经过多步清洗和双层思维链扩充,覆盖多模态理解与生成任务,显著提升了数据的准确性和推理深度;其次是开源的数据增强工具HoneyPipe及DataStudio,为开发者提供
系列篇章💥
目录
前言
在人工智能领域,多模态大模型的发展如火如荼,但开源模型与闭源模型之间仍存在一定的性能差距。为了缩小这一差距,腾讯混元团队与清华大学携手推出了Bee项目,它以提升数据质量为核心,致力于为开源社区提供一套全栈开源的多模态大模型解决方案。
一、项目概述
Bee是由腾讯混元团队与清华大学联合推出的全栈开源多模态大模型解决方案,旨在通过提升数据质量来缩小开源模型与闭源模型之间的性能差距。该项目包含三大核心成果:首先是1500万规模的高质量双层CoT数据集Honey-Data-15M,它经过多步清洗和双层思维链扩充,覆盖多模态理解与生成任务,显著提升了数据的准确性和推理深度;其次是开源的数据增强工具HoneyPipe及DataStudio,为开发者提供了高效的数据处理和标注增强能力;最后是基于该数据集训练的8B模型Bee-8B,它在多项基准测试中刷新了全开源多模态大模型的性能纪录,展现出强大的推理和复杂任务处理能力。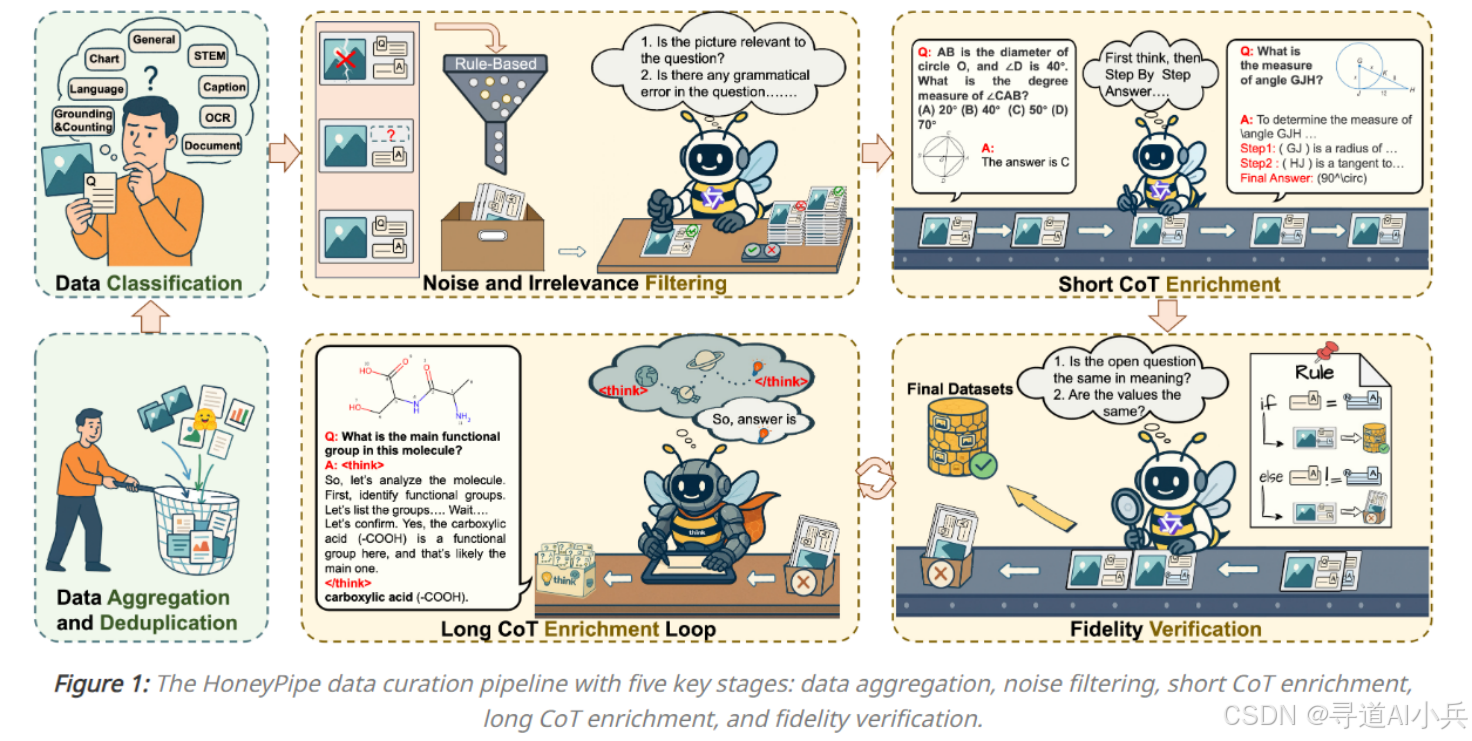
二、核心功能
(一)高质量数据集
Bee项目提供了Honey-Data-15M数据集,包含1500万条高质量多模态数据。该数据集经过多步清洗和双层思维链扩充,覆盖多模态理解与生成任务,显著提升了数据的准确性和推理深度,为模型训练提供了坚实基础。
(二)全栈开源工具
Bee项目开源了HoneyPipe和DataStudio工具。HoneyPipe是高效的数据清洗工具,可对原始数据进行预处理;DataStudio支持多模态数据标注和思维链扩充,帮助用户提升数据质量,构建更优质的数据集。
(三)高性能模型
Bee-8B是基于Honey-Data-15M训练的8B模型,采用五阶段训练配方,包括MLP预热、视觉-语言对齐、多模态SFT、高效精炼SFT和策略优化RL。该模型在多项基准测试中刷新了全开源多模态大模型的性能纪录,展现出强大的推理和复杂任务处理能力。
三、技术揭秘
(一)数据处理技术
Bee项目采用了先进的数据处理技术,通过多步清洗和双层思维链扩充,构建了高质量的Honey-Data-15M数据集。这种数据处理方式不仅提升了数据的准确性,还增强了模型的推理能力。
(二)模型训练技术
Bee-8B模型采用了五阶段训练配方,包括MLP预热、视觉-语言对齐、多模态SFT、高效精炼SFT和策略优化RL。这种训练方式能够充分发挥模型的性能,使其在多项基准测试中表现出色。
(三)系统架构设计
Bee项目的技术架构以模块化为核心理念,从数据预处理、模型训练到推理优化,每一个环节都实现了代码、参数与流程的全面公开,真正做到了可复现、可迭代、可扩展。
四、应用场景
(一)教育领域
Bee模型在教育领域具有广泛的应用前景。它可以作为智能辅导系统的核心,为学生提供个性化的学习指导。例如,在数学和逻辑推理方面,Bee能够生成详细的解题步骤和推理过程,帮助学生更好地理解和掌握知识。此外,它还可以用于智能批改作业、生成学习报告等,提升教育效率。
(二)金融领域
在金融行业,Bee模型可用于风险评估和投资决策。通过对大量金融数据的分析和理解,Bee能够为金融机构提供更准确的风险预测和投资建议。例如,它可以帮助分析市场趋势、评估信贷风险,甚至生成投资策略报告,助力金融机构做出更明智的决策。
(三)医疗领域
Bee模型在医疗领域同样展现出巨大潜力。它可以用于医学影像分析和疾病诊断,通过对医学影像和病历数据的分析,为医生提供辅助诊断建议。此外,Bee还可以用于医学研究,帮助研究人员分析复杂的生物医学数据,加速药物研发和疾病研究进程。
五、快速使用
以下是使用vLLM推理的代码示例
(一)安装依赖
pip install vllm>=0.11.1
(二)离线推理
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
from PIL import Image
import requests
def main():
model_path = "Open-Bee/Bee-8B-RL"
llm = LLM(
model=model_path,
limit_mm_per_prompt={"image": 5},
trust_remote_code=True,
tensor_parallel_size=1,
gpu_memory_utilization=0.8,
)
sampling_params = SamplingParams(
temperature=0.6,
max_tokens=16384,
)
image_url = "https://huggingface.co/Open-Bee/Bee-8B-RL/resolve/main/assets/logo.png"
image = Image.open(requests.get(image_url, stream=True).raw)
messages = [
{
"role":
"user",
"content": [
{
"type": "image",
"image": image
},
{
"type":
"text",
"text":
"Based on this picture, write an advertising slogan about Bee-8B (a Fully Open Multimodal Large Language Model)."
},
],
},
]
processor = AutoProcessor.from_pretrained(model_path,
trust_remote_code=True)
prompt = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True,
)
mm_data = {"image": image}
llm_inputs = {
"prompt": prompt,
"multi_modal_data": mm_data,
}
outputs = llm.generate([llm_inputs], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
print(generated_text)
if __name__ == '__main__':
main()
(三)在线服务
vllm serve \
Open-Bee/Bee-8B-RL \
--served-model-name bee-8b-rl \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.8 \
--host 0.0.0.0 \
--port 8000 \
--trust-remote-code
(四)服务端调用
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
# image url
image_messages = [
{
"role":
"user",
"content": [
{
"type": "image_url",
"image_url": {
"url":
"https://huggingface.co/Open-Bee/Bee-8B-RL/resolve/main/assets/logo.png"
},
},
{
"type":
"text",
"text":
"Based on this picture, write an advertising slogan about Bee-8B (a Fully Open Multimodal Large Language Model)."
},
],
},
]
chat_response = client.chat.completions.create(
model="bee-8b-rl",
messages=image_messages,
max_tokens=16384,
extra_body={
"chat_template_kwargs": {
"enable_thinking": True
},
},
)
print("Chat response:", chat_response.choices[0].message.content)
六、结语
随着人工智能技术的飞速发展,多模态大模型正逐渐成为推动各行业创新的关键力量。Bee项目作为腾讯混元团队与清华大学联合推出的全栈开源多模态大模型解决方案,凭借其高质量的数据集、全栈开源工具和高性能模型,为开源社区提供了一套完整的多模态大模型开发框架。它不仅在技术上实现了创新突破,更通过开源模式为全球开发者提供了平等的学习和创新机会,推动了多模态大模型技术的普及和应用。
项目地址
- 1、项目官网:https://open-bee.github.io/
- 2、Hugging Face模型库:https://huggingface.co/collections/Open-Bee/bee
- 3、arXiv技术论文:https://arxiv.org/pdf/2510.13795
- 4、Honey-Data-15M数据集:https://huggingface.co/datasets/Open-Bee/Honey-Data-15M

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 35
35 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)