多模态大模型位置编码梳理笔记(一):绝对位置编码(正弦,可学习),相对位置编码(XL, T5, RoPE, ALiBi)
详细介绍绝对位置编码(正弦,可学习),相对位置编码(XL, T5, RoPE, ALiBi)
·
【如果笔记对你有帮助,欢迎关注&点赞&收藏,收到正反馈会加快更新!谢谢支持!】
一、位置编码介绍
- 为什么需要位置编码(Position Encoding)?
- Transformer架构的核心是自注意力机制,通过计算序列中任意两个元素之间的关系来提取信息。然而,自注意力机制本身是位置无关的(例如,对于“猫在椅子上”和“椅子在猫上”,自注意力机制在没有位置信息的情况下会认为这两个序列是等价的)
- 多模态大模型中位置编码的作用:
- 提供顺序信息
- 增强模型表达能力(理解句子的语法结构、图像的空间位置、图像中对象的位置与文本描述之间的对应关系等)
- 捕捉长距离的依赖关系
- 常用的位置编码类型:
- 绝对位置编码:正弦位置编码,可学习位置编码
- 相对位置编码:Transformer-XL相对位置编码,T5相对位置编码,旋转位置编码(RoPE),ALiBi位置编码
二、绝对位置编码
2.1 正弦位置编码(Transformer的位置编码)
- sin和cos交替,通过线性变换矩阵得到位置编码
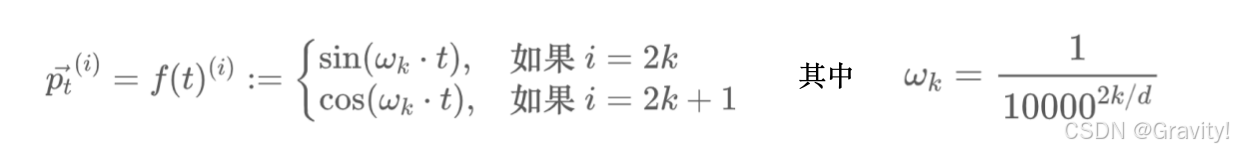
- 为什么不是相对位置编码【也是正弦位置编码的缺点】:在计算Attention的时候要通过projection变成qkv(投影矩阵变换破坏掉位置的相对性),映射后的正余弦波乘积不再具有单调性
- 代码:
import numpy as np import torch def sinusoidal_position_encoding(max_len, d_model): """ 生成正弦位置编码矩阵 :param max_len: 序列的最大长度 :param d_model: 嵌入的维度 :return: 位置编码矩阵,形状为 (max_len, d_model) """ # 创建一个空的位置编码矩阵 position_encoding = np.zeros((max_len, d_model)) # 计算位置编码的每个维度 for pos in range(max_len): for i in range(0, d_model, 2): position_encoding[pos, i] = np.sin(pos / (10000 ** (2 * i / d_model))) if i + 1 < d_model: position_encoding[pos, i + 1] = np.cos(pos / (10000 ** (2 * i / d_model))) # 将位置编码矩阵转换为张量 position_encoding = torch.tensor(position_encoding, dtype=torch.float32) return position_encoding # 示例:生成一个长度为50,维度为128的位置编码矩阵 max_len = 50 d_model = 128 position_encoding = sinusoidal_position_encoding(max_len, d_model)
2.2 可学习位置编码(BERT)
- 把位置编码当成可学习的参数
- 缺点:没有长度的外推性(长度是固定死的)
self.position_embedding = nn.Embedding(max_len, d_model)
三、相对位置编码
3.0 相对位置编码如何实现
- 绝对位置编码只在输入时添加,相对位置编码在每一层中根据键和查询之间的偏移量进行计算
- 相对位置编码通常会进行截断处理(需要有限个)
3.1 Transformer-XL相对位置编码

3.2 T5相对位置编码
- 认为输入(x)和位置编码(p)是可以解耦的,即删除了x*p 的项
【即 Attention矩阵 + 偏置项 】
3.3 RoPE 旋转位置编码
- 结合绝对和相对位置编码优点
- 绝对位置编码:简单,但是不能扩展、不能表示相对位置
- 相对位置编码:关注相对距离,捕捉相对关系,但是使模型架构复杂化
- RoPE:用绝对位置编码的方式实现相对位置编码,简单高效
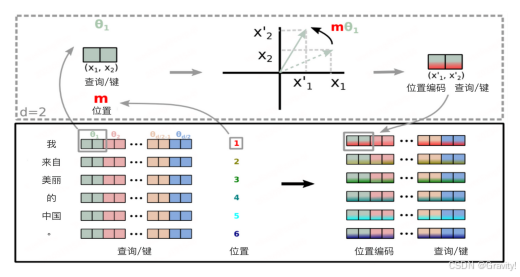
- 原理:利用三角函数(sin,cos)的特性,将
→

计算: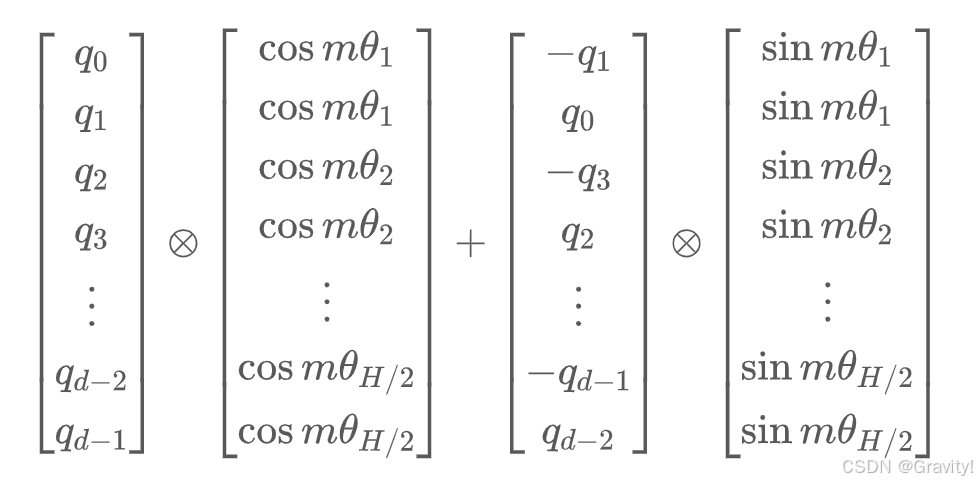
- 代码实现(参考上面公式):
import torch import torch.nn as nn import torch.nn.functional as F import math def sinusoidal_position_embedding(batch_size, num_head, max_len, output_dim, device): position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(-1) # (output_dim//2) ids = torch.arange(0, output_dim // 2, dtype=torch.float) theta = torch.pow(10000, -2 * ids / output_dim) embeddings = position * theta # shape: (max_len, output_dim//2) embeddings = torch.stack([torch.sin(embeddings), torch.cos(embeddings)], dim=-1) # shape: (max_len, output_dim//2, 2) embeddings = embeddings.repeat((batch_size, nums_head, *([1] * len(embeddings.shape)))) # shape: (batch_size, nums_head, max_len, output_dim//2, 2) # (bs, head, max_len, output_dim) embeddings = embeddings.reshape(batch_size, nums_head, max_len, output_dim) embeddings = embeddings.to(device) return embeddings def RoPE(q, k): # q,k: (bs, head, max_len, output_dim) batch_size, num_head, max_len, output_dim = q.shape # (bs, head, max_len, output_dim) pos_emb = sinusoidal_position_embedding(batch_size, nums_head, max_len, output_dim, q.device) # cos_pos,sin_pos: (bs, head, max_len, output_dim) cos_pos = pos_emb[..., 1::2].repeat_interleave(2, dim=-1) # 将奇数列信息抽取出来也就是cos 拿出来并复制 sin_pos = pos_emb[..., ::2].repeat_interleave(2, dim=-1) # 将偶数列信息抽取出来也就是sin 拿出来并复制 # q,k: (bs, head, max_len, output_dim) q2 = torch.stack([-q[..., 1::2], q[..., ::2]], dim=-1) q2 = q2.reshape(q.shape) # reshape后就是正负交替了 # 更新qw, *对应位置相乘 q = q * cos_pos + q2 * sin_pos k2 = torch.stack([-k[..., 1::2], k[..., ::2]], dim=-1) k2 = k2.reshape(k.shape) # 更新kw, *对应位置相乘 k = k * cos_pos + k2 * sin_pos return q, k
3.4 ALiBi (Attention with Linear Biases)
- 在注意力计算公式上,引入惩罚因子(相对距离成正比例关系)来调整注意力分数
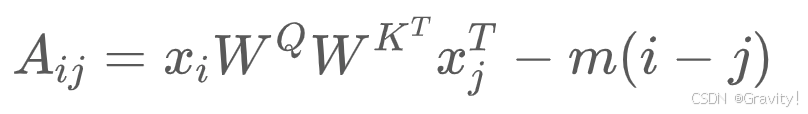
- 用来增强Transformer模型的长度外推能力

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 37
37 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)