科大讯飞语音识别与合成技术详解及C#实现
科大讯飞是中国领先的智能语音技术企业,其语音识别技术经过多年的研发与优化,已经成为全球领先的语音识别引擎之一。从最初的语音输入法到现如今复杂的对话系统,科大讯飞的语音识别技术在不同领域得到了广泛应用。语音合成技术是人工智能领域的一个重要分支,它旨在将输入的文本信息转化为自然流畅的语音信息,使计算机可以像人类一样用语言进行交流。科大讯飞作为中国领先的智能语音和人工智能公众公司,在语音合成技术上也取得

简介:科大讯飞是智能语音技术领域的领先企业,尤其在语音识别和合成技术方面。文章深入探讨了科大讯飞的技术优势,并指导开发者如何使用C#语言调用科大讯飞提供的DLL文档进行语音识别与合成的应用开发。介绍了语音识别技术如何将口语转化为文字,以及语音合成技术如何将文本转化为自然语音,还详细说明了如何集成这些技术到C#程序中,并提供了基于“测试123”文件的开发测试指南。 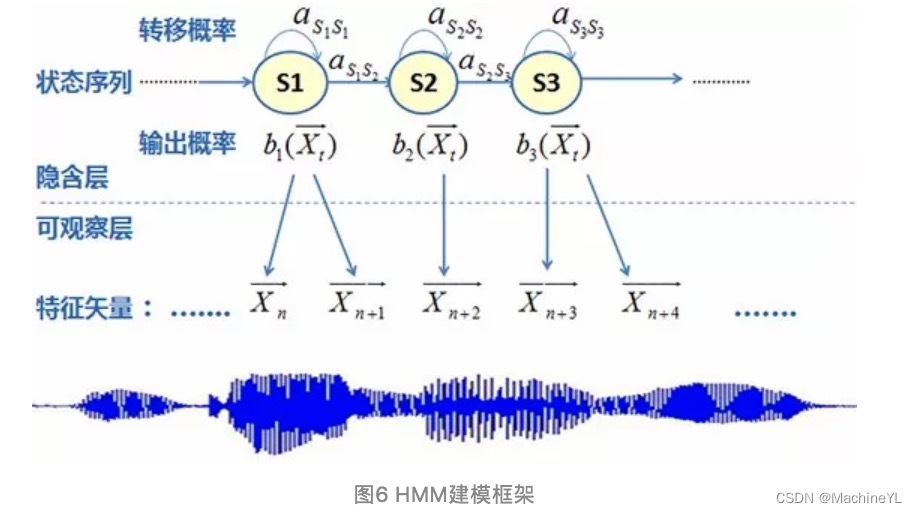
1. 科大讯飞的语音识别技术概述
1.1 技术背景与发展历程
科大讯飞是中国领先的智能语音技术企业,其语音识别技术经过多年的研发与优化,已经成为全球领先的语音识别引擎之一。从最初的语音输入法到现如今复杂的对话系统,科大讯飞的语音识别技术在不同领域得到了广泛应用。
1.2 技术核心与优势
该技术的核心在于高效的声学模型、精确的语言模型和大规模的语音数据处理能力。这些技术优势使得科大讯飞的语音识别产品在噪声环境下的识别率、准确率上均优于竞争对手。此外,对不同口音和方言的适应性也是其技术优势之一。
1.3 应用场景与案例
科大讯飞语音识别技术已被广泛应用于智能助手、车载系统、客服机器人和教育领域。例如,阿里巴巴的智能音箱、小米的智能设备均有科大讯飞技术的支持。通过实际案例的分析,我们可以深入理解这项技术如何解决实际问题,并提升用户体验。
以上就是第一章的内容概要,展示了科大讯飞语音识别技术的发展历程、核心优势以及应用场景,为后续章节中更深入的技术探讨和实践应用做了铺垫。
2. 科大讯飞的语音合成技术概述
语音合成技术是人工智能领域的一个重要分支,它旨在将输入的文本信息转化为自然流畅的语音信息,使计算机可以像人类一样用语言进行交流。科大讯飞作为中国领先的智能语音和人工智能公众公司,在语音合成技术上也取得了突破性的进展,形成了成熟的产品线和应用案例。
5.1 语音合成技术的理论基础
5.1.1 文字分析和语音单元
语音合成的过程首先涉及到的是文字分析。它需要准确理解输入文本的语法结构、语义内容,并在此基础上,通过特定的算法将文字信息转换为可发音的音素序列。这个过程中,重点在于语音单元的选择和处理。
语音单元是指语音中最小的可发音单元,比如声母、韵母、音节等。现代的语音合成系统普遍采用的是基于单元选择的合成方法。系统会预存大量的语音单元,并在合成过程中通过语音单元的组合,尽可能准确地复现输入文本的发音。
graph LR
A[输入文本] --> B[文本分析]
B --> C[语音单元选择]
C --> D[音素序列生成]
D --> E[语音波形合成]
E --> F[输出语音]
5.1.2 合成算法和语音库
语音合成算法的核心在于语音库的构建和合成算法的设计。语音库包含了大量预先录制好的单词、短语甚至句子的发音数据。合成算法会根据语音单元的组合规则和文本内容,从语音库中挑选合适的语音单元,然后进行拼接和融合,最终生成连贯的语音输出。
为了提高语音合成的自然度和可懂度,科大讯飞在其语音合成技术中使用了深度学习技术进行算法的训练。这种基于深度神经网络的合成技术能够有效减少合成语音中的“机器感”,让合成语音更加自然和流畅。
flowchart LR
A[文本输入] -->|分析| B[文本转音素]
B -->|选择| C[语音单元提取]
C -->|合成| D[生成语音波形]
D -->|转换| E[输出合成语音]
5.2 实现文字到语音的转换过程
5.2.1 文本的预处理
在进行文字到语音的转换之前,需要对输入的文本进行预处理。预处理通常包括去除标点符号、将繁体中文转换为简体中文、数字和时间的标准化等步骤。此外,对于一些专有名词或者特殊用词,可能还需要进行专有处理,以确保合成语音的准确性。
// 示例代码段:对文本进行预处理
public string PreprocessText(string inputText)
{
// 去除标点符号
string processedText = Regex.Replace(inputText, @"[\p{P}\p{S}]", "");
// 数字和时间标准化处理
processedText = NormalizeNumbersAndTimes(processedText);
// 转换繁体中文到简体中文
processedText = SimplifyTraditionalChinese(processedText);
// 返回预处理后的文本
return processedText;
}
5.2.2 文本到语音的代码实现
在文本预处理完成后,接下来就是通过编程实现文本到语音的转换。这一步骤通常涉及到调用科大讯飞提供的API接口。通过这些接口,开发者可以将处理好的文本数据发送给语音合成服务,并接收服务端合成后的音频数据流。
以下是使用C#调用科大讯飞语音合成API的一个简单示例:
using System;
using System.Net.Http;
using System.Threading.Tasks;
public class TextToSpeech
{
private readonly string _apiKey;
private readonly string _apiSecret;
private readonly HttpClient _httpClient = new HttpClient();
public TextToSpeech(string apiKey, string apiSecret)
{
_apiKey = apiKey;
_apiSecret = apiSecret;
}
public async Task<string> SynthesizeSpeech(string text)
{
// 这里省略了HTTP请求的详细实现代码,包括构建请求、认证、发送请求等步骤
// 例如,构建请求体、计算签名、设置请求头等
// 请参考科大讯飞的API文档进行正确的实现
// 假设请求成功后,从API返回的数据流中获取音频数据
var audioData = await _httpClient.GetByteArrayAsync("http://api.xfyun.cn/v1/service/v1/tts");
// 将音频数据写入文件或其他媒介
File.WriteAllBytes("output.mp3", audioData);
// 返回合成结果,这里以文件名为例
return "output.mp3";
}
}
5.2.3 语音合成结果的优化和调整
合成出的语音在默认情况下可能并不能完全满足特定场景的需求。这就需要对合成语音进行适当的优化和调整,比如调整语速、语调、音量、音色等,以达到最佳的听感效果。科大讯飞提供的语音合成API往往支持一些基本的参数设置,允许开发者进行一定程度的个性化调整。
结语
科大讯飞的语音合成技术通过先进的算法和庞大的语音库,为开发者提供了强大的语音合成能力,从而让机器能够更加自然地与人类进行语言交互。本章从语音合成的理论基础到实现过程,再到优化调整,全面介绍了科大讯飞的语音合成技术以及如何通过代码实现文本到语音的转换。在后续章节中,我们还将探讨如何将科大讯飞的语音技术集成到各类应用中,并进一步提升开发流程的效率和效果。
3. 使用C#调用科大讯飞API的指南
3.1 掌握科大讯飞API的基础
3.1.1 API的注册和获取
科大讯飞API的使用开始于注册和获取。用户首先需要访问科大讯飞开放平台官网,注册成为开发者,并创建相应的应用以获取API的调用权限。在创建应用时,必须填写应用名称、应用类型等信息,并设置合适的回调地址,以便于应用在调用API时能正确返回结果。
完成应用创建后,系统会分配一个唯一的 AppID 和 AppKey 。 AppID 用于标识应用,而 AppKey 则用于API调用的身份验证。将这两个密钥安全地保存起来是非常重要的,因为它们是API调用安全性的保障。
3.1.2 API的调用流程和基本参数
科大讯飞API的调用流程遵循标准的HTTP请求模式。用户需要使用 HTTPS 协议发起请求,并在请求中包含必要的参数。以下为API调用的基本步骤:
- 构建请求URL:URL通常由API的基础地址和接口相对路径组成,如
https://api.xfyun.cn/v1/service/。 - 添加认证信息:将
AppID和AppKey加入到请求中,通常是通过添加appid和key参数来实现。 - 设置请求参数:根据API的具体要求设置调用参数,如语言代码、音频格式等。
- 发送请求并接收响应:通过网络请求发送带有上述参数的HTTP请求,并获取返回的JSON或XML格式的响应数据。
3.1.3 常见API调用示例
以下是一个简单的C#调用科大讯飞API的示例,使用 HttpClient 类:
using System;
using System.Net.Http;
using System.Threading.Tasks;
public class IFlytekApiExample
{
private readonly string _appid = "你的AppID";
private readonly string _appKey = "你的AppKey";
private readonly string _apiUrl = "https://api.xfyun.cn/v1/service/";
public async Task<string> CallApiAsync(string parameters)
{
using (HttpClient client = new HttpClient())
{
// 拼接完整的请求地址
string requestUri = $"{_apiUrl}?appid={_appid}&key={_appKey}&{parameters}";
try
{
// 发起GET请求
HttpResponseMessage response = await client.GetAsync(requestUri);
response.EnsureSuccessStatusCode();
string responseBody = await response.Content.ReadAsStringAsync();
return responseBody;
}
catch (HttpRequestException e)
{
// 输出请求过程中遇到的错误信息
Console.WriteLine("\nException Caught!");
Console.WriteLine("Message :{0} ", e.Message);
return string.Empty;
}
}
}
}
在此代码中, CallApiAsync 方法通过 HttpClient 发送了一个带有必要参数的GET请求,并接收返回的响应内容。
3.2 C#环境中调用API的实践
3.2.1 创建C#项目与环境配置
在调用科大讯飞API之前,首先需要在Visual Studio中创建一个新的C#项目。推荐选择.NET Framework或者.NET Core,并为项目添加必要的NuGet包,例如 System.Net.Http 用于网络请求。
项目创建完成后,需要配置应用的环境,包括设置 AppID 和 AppKey 。为了避免在代码中硬编码这些敏感信息,可以将它们存放在配置文件中,例如 appsettings.json 或 web.config 。使用时,通过读取配置文件来获取这些值。
3.2.2 编写代码实现API的调用
在完成了项目创建和环境配置之后,接下来要编写核心的调用代码。根据不同的API功能,代码实现会有所不同。以语音识别API为例,代码需要完成以下步骤:
- 获取用户的音频文件并读取为字节数组。
- 构造API请求的参数。
- 发送请求并接收响应。
- 解析响应,提取出识别结果。
以下是一个简化的代码示例,展示了如何在C#中构造请求并发送给科大讯飞API:
public class AudioRecognitionExample
{
private readonly HttpClient _httpClient;
public AudioRecognitionExample()
{
_httpClient = new HttpClient();
}
public async Task<string> RecognizeAudioAsync(byte[] audioBytes, string format)
{
var parameters = $"format={format}";
var content = new ByteArrayContent(audioBytes);
content.Headers.ContentType = new System.Net.Http.Headers.MediaTypeHeaderValue("audio/" + format);
try
{
var response = await _httpClient.PostAsync(_apiUrl, content);
response.EnsureSuccessStatusCode();
var responseBody = await response.Content.ReadAsStringAsync();
return responseBody;
}
catch (HttpRequestException e)
{
Console.WriteLine("\nException Caught!");
Console.WriteLine("Message :{0} ", e.Message);
return string.Empty;
}
}
}
在这个例子中, RecognizeAudioAsync 方法接收音频文件的字节数组以及音频的格式,构造出POST请求发送给API,并返回识别结果。
3.3 错误处理和调试技巧
3.3.1 常见错误代码及其解决方法
在调用API的过程中,可能遇到各种错误情况,如网络问题、参数错误、API服务端的问题等。科大讯飞API会通过HTTP状态码来反馈请求结果,常见的状态码包括:
200 OK:请求成功。400 Bad Request:请求无效或参数不正确。401 Unauthorized:认证失败,可能是AppID或AppKey错误。403 Forbidden:没有权限调用该API。500 Internal Server Error:服务器内部错误。
除了HTTP状态码,响应内容中还可能包含具体的错误信息,这些信息对于问题定位非常有帮助。在编写代码时,应当根据不同的错误情况进行异常处理,记录日志,以便于快速定位和解决问题。
3.3.2 代码调试技巧和日志记录
调试是开发过程中不可或缺的环节,尤其在涉及到网络请求和第三方API调用时。以下是几个有效的调试技巧:
- 使用断点逐步执行代码,观察变量和参数的变化。
- 检查网络请求的URL、方法、头部信息和响应,确保它们符合预期。
- 利用日志记录功能,记录请求发送前后的关键信息,如请求的URL、参数、返回的响应等。
在C#中,可以使用 Console.WriteLine 或者日志框架如 NLog 或 Serilog 来记录关键信息,这对于在出现问题时分析和调试提供了便利。
此外,科大讯飞官方也提供了开发者文档和社区支持,其中包含了丰富的API使用示例和常见问题解答,这些都是帮助开发者快速解决问题的重要资源。在遇到困难时,首先应查阅官方文档,然后考虑是否需要寻求社区帮助或直接联系科大讯飞的技术支持。
4. 语音识别到文字转换的实现
4.1 语音识别技术的理论基础
语音识别技术是一种将人类的语音信号转化为可编辑和可操作的文本信息的技术。它涉及到声学、语言学、计算机科学以及信息论等多个学科领域。
4.1.1 语音信号的处理
语音信号处理是语音识别技术的首要环节。语音信号是随时间变化的非平稳随机信号,它的频率特性随着发音的不同而改变。为了有效地处理这些信号,通常需要对其进行预处理,包括去噪、端点检测、回声消除等步骤。
在预处理的过程中,常用的算法有:
- 去噪算法 :通过滤波器去除语音信号中的背景噪声。
- 端点检测 :确定语音信号的开始和结束点,以排除无关的静默部分。
- 回声消除 :利用自适应滤波器等技术消除录音过程中的回声干扰。
4.1.2 识别算法和模型
在语音识别的处理流程中,关键步骤之一是使用特定的算法和模型对语音信号进行分析和识别。典型的识别算法有隐马尔可夫模型(HMM),近年来,深度学习模型,特别是循环神经网络(RNN)和长短时记忆网络(LSTM)在语音识别领域也表现出了优越的性能。
深度学习模型之所以受到青睐,是因为其能在大规模数据集上学习复杂的声学特征和语言模式。以下是一些具体的例子:
- 深度神经网络(DNN) :用于提取语音信号的深度特征。
- 卷积神经网络(CNN) :在时频表示中用于提取局部相关特征。
- 循环神经网络(RNN)和长短时记忆网络(LSTM) :处理序列数据,捕捉时间依赖性。
4.2 实现语音到文字的转换过程
语音到文字的转换过程,通常需要将语音数据准备、上传到服务器进行识别处理,并处理返回的识别结果。
4.2.1 语音数据的准备和上传
在准备语音数据时,需要保证录音的清晰度,避免背景噪音的影响,并且确保文件格式为科大讯飞API支持的格式,如WAV或MP3。
上传数据通常通过HTTP POST请求实现。以下是使用C#上传语音数据的代码示例:
using System;
using System.Net.Http;
using System.IO;
using Newtonsoft.Json;
public class AudioUpload
{
private readonly HttpClient _httpClient;
public AudioUpload(string accessToken)
{
_httpClient = new HttpClient
{
BaseAddress = new Uri("http://api.xfyun.cn/v1/service/v1/iasr")
};
_httpClient.DefaultRequestHeaders.Add("Accept", "application/json");
_httpClient.DefaultRequestHeaders.Add("X-Appid", "YourAppId");
_httpClient.DefaultRequestHeaders.Add("X-CurTime", DateTime.Now.Ticks.ToString());
_httpClient.DefaultRequestHeaders.Add("X-Auth-Token", accessToken);
}
public async Task<string> UploadAndRecognizeAsync(string filePath)
{
using (var fileStream = new FileStream(filePath, FileMode.Open, FileAccess.Read))
{
var content = new MultipartFormDataContent();
content.Add(new ByteArrayContent(File.ReadAllBytes(filePath)), "file", Path.GetFileName(filePath));
var response = await _httpClient.PostAsync("", content);
if (response.IsSuccessStatusCode)
{
var responseContent = await response.Content.ReadAsStringAsync();
var result = JsonConvert.DeserializeObject<dynamic>(responseContent);
return result.result.ToString();
}
throw new Exception("Upload failed: " + response.ReasonPhrase);
}
}
}
上面的代码展示了如何使用 HttpClient 上传一个文件,然后用多部分表单数据来发送请求。需要确保 YourAppId 和 accessToken 替换成有效的值。
4.2.2 实时语音识别的代码实现
实时语音识别允许用户边说边转写,这对于需要即时反馈的场景非常有用。以下是一个基于HTTP长连接实现的实时语音识别的C#代码片段:
using System;
using System.IO;
using System.Net.Sockets;
using System.Text;
using Newtonsoft.Json;
public class RealTimeRecognition
{
private TcpClient _tcpClient;
private NetworkStream _networkStream;
public RealTimeRecognition(string server, int port)
{
_tcpClient = new TcpClient(server, port);
_networkStream = _tcpClient.GetStream();
}
public void SendAudio(Stream audioStream)
{
// Send audio data to server in chunks
}
public void StartListening(Action<string> onResult)
{
// Start the process of receiving the results from the server
}
public void StopListening()
{
// Stop the recognition process and close the connection
}
private void HandleServerResponse(Stream responseStream)
{
// Parse and handle the JSON response from the server
}
}
此代码段展示了实时语音识别的基础框架,实现了与服务器的连接,并准备了数据传输和接收处理的方法。具体实现需要根据科大讯飞API的文档,确定如何正确分段音频数据发送,以及如何解析返回的JSON数据。
4.2.3 语音识别结果的解析和应用
经过识别处理后,从服务器返回的通常是一个JSON格式的字符串。解析这个字符串,获取识别结果是实现语音到文字转换的最后一环。以下是一个解析结果的代码示例:
// 假设response是从服务器接收到的JSON字符串
var response = await responseStream.ReadAsStringAsync();
dynamic result = JsonConvert.DeserializeObject(response);
string recognizedText = result.result.ToString();
在获取到 recognizedText 后,就可以根据具体的应用需求将识别的文本数据展示、存储或进一步处理。
4.3 应用与优化
语音到文字转换技术已广泛应用于多个领域,如智能助理、会议记录、语音搜索等。对于开发者来说,优化识别的准确率、降低识别的延迟、提高系统的稳定性是永恒的主题。实践中,除了科大讯飞API的调用优化外,还应考虑网络条件、服务器配置以及应用场景的特点,进行综合优化。
在实际应用中,开发者应关注语音识别技术的发展动态,积极探索新技术的应用前景,如利用机器学习进行个性化训练,以及结合上下文信息提高识别准确性等方向。
5. 文字到语音合成的实现
5.1 语音合成技术的理论基础
5.1.1 文字分析和语音单元
语音合成技术的基础在于将文字文本转换为可理解的语音信号。这一过程涉及到文字的分析和处理,即从文字中提取语义信息,并将之映射到相应的语音单元上。语音单元是构成语音的基本元素,比如音素、音节或单词。合成过程需要考虑到语言的规则性、发音的多样性以及不同语境下的语调变化。
文字分析的准确性直接影响到合成语音的自然度和可理解性。在进行文字分析时,需要识别词汇的边界,并识别出数字、标点和特殊符号等,这有助于后续的语音单元选择。此外,还需要考虑语法和语义的处理,这决定了合成语音的流畅性和正确性。
5.1.2 合成算法和语音库
语音合成系统的核心是合成算法,它负责将文字转换为语音信号。常见的算法有基于规则的合成和基于统计的合成,比如隐马尔可夫模型(HMM)和深度学习技术。基于规则的合成依赖于严格的语言学规则,而基于统计的合成则依赖于大量数据训练得到的概率模型。
语音库是语音合成技术中另一个重要组成部分。它存储了所有可能的语音单元的录音样本。高质量的语音库能极大提升合成语音的真实度。语音单元按照不同的发音、语调、情感等特征分类存储,合成时,系统根据文字内容选取合适的语音单元并拼接成完整的声音流。
5.2 实现文字到语音的转换过程
5.2.1 文本的预处理
在将文本转换为语音之前,文本预处理是必要的步骤。文本预处理包括去除无意义的符号和空白、纠正错别字、进行词性标注、分词以及语言学属性的标注。分词是中文文本处理中的重要步骤,需要考虑到中文词语的组合规则,以及词的边界。语言学属性标注,如标注每个词的时态、语气、情感等,为后续的语音合成提供了重要的信息。
5.2.2 文本到语音的代码实现
在编程实现文本到语音转换的过程中,首先需要调用语音合成API,然后将处理好的文本数据发送给API,最后接收语音数据并播放。以下是一个使用Python实现文本到语音合成的基本示例代码:
import speech_recognition as sr
# 初始化识别器
recognizer = sr.Recognizer()
# 准备要转换成语音的文本
text = "你好,世界!"
# 选择语音合成的语言和语音类型
language = "zh-CN"
voice = "woman"
# 调用语音合成函数
audio_data = recognizer.synthesize_speech(text, language=language, voice=voice)
# 保存合成的语音到文件
with open("output.wav", "wb") as file:
file.write(audio_data.get_wav_data())
# 播放合成的语音文件
recognizer.play_wave("output.wav")
这段代码首先创建了一个语音识别器实例,然后使用 synthesize_speech 方法将文本转换为语音,并保存为WAV格式文件。最后,使用 play_wave 方法播放合成的语音。需要注意的是,本示例使用了 speech_recognition 这个库中的合成功能,实际上科大讯飞提供了自己的API接口,需要通过调用这些接口来获取更专业和高质量的语音合成服务。
5.2.3 语音合成结果的优化和调整
在完成基础的文本到语音转换后,可能还需要对结果进行优化和调整,以提高语音的自然度和适应性。常见的优化手段包括调整语速、音调、音量等,以及添加必要的停顿和语气词。在科大讯飞的API中,这些参数都可以通过API调用时的参数进行设置。
此外,针对不同的应用场景,可能需要对特定的词汇或短语进行优化,比如专业术语的发音或者特殊场合下的语调调整。在实际应用中,开发者可以通过反复试验和用户反馈,逐步调整参数,优化合成语音的质量。
下表展示了优化过程中可能涉及的调整参数及其作用:
| 参数 | 作用 |
|---|---|
| 语速 | 调节语音播放的速度 |
| 音调 | 调节语音的音高,可影响语调 |
| 音量 | 调节语音输出的响度 |
| 语境 | 根据上下文调整语音合成策略 |
| 重音 | 强调特定词汇或短语的发音 |
| 停顿 | 在词汇或句子间添加适当的停顿 |
在代码中,对于特定参数的调整通常看起来如下:
# 调用语音合成函数时设置参数
audio_data = recognizer.synthesize_speech(
text, language=language, voice=voice,
rate=1.2, # 调整语速
pitch=1.0, # 调整音调
volume=1.0 # 调整音量
)
通过合理的参数调整,我们可以让合成语音更加适应不同的应用场景和用户需求。最终目标是使合成语音既自然又富有表现力,为用户提供满意的听觉体验。
6. 开发者集成语音技术的步骤
在本章节中,我们将深入探讨如何将科大讯飞的语音技术集成到开发者自己的项目中。这一过程涉及到一系列的准备工作、API集成以及应用部署和维护等步骤。下面,我们将一步步地揭示这些过程。
6.1 集成前的准备工作
在开始集成语音识别或语音合成API之前,开发者需要做好一些基础的技术评估和环境准备工作。
6.1.1 技术评估和选择
首先,开发者需要对科大讯飞的语音技术进行全面的了解,包括其功能、性能、使用限制等。这一过程可以通过查看官方文档、技术论坛和用户反馈来完成。了解这些信息后,开发者应根据实际需求选择合适的服务类型,例如是仅需识别、仅需合成还是两者都需要。
其次,评估自身的技术栈以及对API的兼容性,比如选择合适的编程语言和框架,并确定如何与现有的系统或服务进行集成。
6.1.2 环境搭建和配置
接下来,开发者需要搭建开发环境。对于C#开发者来说,这通常意味着安装Visual Studio和.NET Core或.NET Framework。除了编码环境外,还需要设置API密钥,以便能够使用科大讯飞的API服务。
环境配置方面,开发者可能还需要配置网络代理、SSL证书或其他安全措施,以满足企业或项目的安全需求。
6.2 科大讯飞API的集成步骤
科大讯飞API的集成需要开发者遵循一定的步骤,以确保顺利地实现功能模块的划分和实现。
6.2.1 API密钥的管理
开发者在注册科大讯飞API服务后,会获得一对API密钥,包括AppID和AppKey,这些密钥是访问API服务的凭证。在代码中,开发者需要将这些密钥安全地存储,并在每次API调用时进行验证。
出于安全考虑,密钥不应该硬编码在代码中,而应该使用环境变量或配置文件来管理。此外,应定期检查密钥的安全性,并在必要时更新密钥。
6.2.2 功能模块的划分和实现
API集成通常包括多个功能模块,如用户认证、语音数据上传、结果接收等。开发者需要根据应用需求将这些功能模块划分出来,并逐一实现它们。
例如,在语音识别功能模块中,开发者需要编写代码处理音频数据的上传,并接收API返回的识别结果。对于语音合成模块,需要将文本数据发送到API,并在接收到合成的音频流后进行适当的处理和存储。
6.3 应用部署和维护
部署应用并进行维护是集成过程中的最后一步,但也是持续进行的工作。
6.3.1 部署流程和监控
应用部署过程中,开发者应该确保使用了适当的部署策略,比如蓝绿部署或金丝雀发布,以便在出现问题时能够快速回滚。部署后,应设置适当的监控工具来跟踪API的性能和应用的状态。
监控工具可以帮助开发者观察API的调用频率、响应时间和错误率等关键指标。同时,还应监控应用的CPU、内存和磁盘使用情况等资源消耗指标。
6.3.2 常见问题的处理和维护策略
在应用运行期间,难免会遇到各种问题,如服务中断、API调用限制超限或性能下降等。开发者需要制定出一套有效的维护策略,用于应对这些问题。
例如,对于API调用限制超限的问题,可以设置限流机制,并提供用户友好的错误提示。对于性能下降问题,则应根据监控数据进行优化,如增加硬件资源、优化代码或数据库查询等。
最后,应建立一个知识库,记录问题的解决方案和优化措施,这样不仅能够提高问题处理的效率,还能为团队成员提供宝贵的经验积累。
简介:科大讯飞是智能语音技术领域的领先企业,尤其在语音识别和合成技术方面。文章深入探讨了科大讯飞的技术优势,并指导开发者如何使用C#语言调用科大讯飞提供的DLL文档进行语音识别与合成的应用开发。介绍了语音识别技术如何将口语转化为文字,以及语音合成技术如何将文本转化为自然语音,还详细说明了如何集成这些技术到C#程序中,并提供了基于“测试123”文件的开发测试指南。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 16
16 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)