Windows 7中的SAPI语音识别技术应用
Windows 7操作系统推出以来,其内置的语音识别技术就成为了辅助用户与计算机交互的重要工具。这项技术允许用户通过语音命令控制计算机,提供了一种更为自然的交互方式。语音识别技术在提升用户体验、满足特殊需求用户群体(如运动障碍者)等方面展现出了极大的潜力和价值。语音识别技术的应用不仅限于操作系统内置的功能,还扩展到了软件开发领域。开发者可以利用Microsoft的语音应用程序接口(SAPI)工具包

简介:Windows 7操作系统集成了微软的语音识别技术,提供用户通过语音命令与计算机交互的便利。开发者可利用SAPI工具包,开发语音识别和合成应用。SAPI包含丰富的接口和类,用于实现语音识别、音频播放和文字转语音等功能。此外,开发者还可以利用Visual Studio 2013和C++实现SAPI相关应用的开发,以构建丰富多样的语音应用程序。 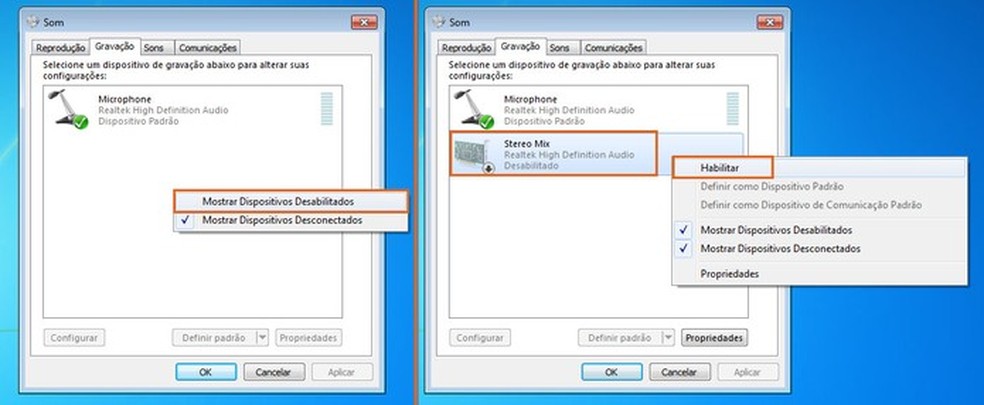
1. Windows 7语音识别技术概述
Windows 7操作系统推出以来,其内置的语音识别技术就成为了辅助用户与计算机交互的重要工具。这项技术允许用户通过语音命令控制计算机,提供了一种更为自然的交互方式。语音识别技术在提升用户体验、满足特殊需求用户群体(如运动障碍者)等方面展现出了极大的潜力和价值。
语音识别技术的应用不仅限于操作系统内置的功能,还扩展到了软件开发领域。开发者可以利用Microsoft的语音应用程序接口(SAPI)工具包,创建自己的语音识别和语音合成应用程序。这些应用程序可以实现从简单的语音控制到复杂的语音交互系统,为用户提供更丰富、更人性化的交互体验。
在本章节中,我们将重点介绍Windows 7的语音识别技术的基础知识,为后续章节中详细探讨SAPI工具包及其应用打下基础。通过本章的学习,读者应能够理解Windows 7语音识别技术的原理、功能以及它在软件开发中的作用和应用前景。
2. SAPI工具包详解
2.1 SAPI工具包结构
2.1.1 SAPI的主要组件分析
SAPI(Speech Application Programming Interface)是微软提供的一套语音应用程序接口,它使得开发者能够构建可以接收和产生语音的软件应用程序。SAPI的主要组件包括:
- 语音识别引擎 :负责将用户的语音输入转化为文本数据。
- 文本到语音转换器(TTS) :将文本内容转换为语音输出。
- 语音命令解释器 :通过语音命令控制应用程序的功能。
- 语音编辑器 :用于训练语音识别引擎,优化语音输入的准确性。
这些组件共同作用,构成了SAPI工具包的核心功能。
2.1.2 SAPI与操作系统的关系
SAPI作为操作系统级别的接口,需要与操作系统的某些核心功能紧密集成。例如,在Windows系统中,SAPI通过集成到Windows的辅助功能中,可以提供更丰富的人机交互体验。SAPI可以利用操作系统提供的音频输入输出接口,以及权限管理系统,确保语音应用程序的正常运行。此外,SAPI的安装和更新往往随操作系统的升级而进行,以保证最佳的兼容性和性能。
2.2 SAPI工具包的优势与特点
2.2.1 语音识别的准确性分析
SAPI工具包在语音识别方面的准确性是其一大卖点。准确性主要体现在以下几个方面:
- 自然语言处理能力 :SAPI支持多种自然语言,对于不同的语言和方言,它能够提供较好的识别准确率。
- 上下文理解 :SAPI的语音识别引擎通过分析上下文,提高识别的准确性,减少歧义和错误。
- 音素级别识别 :SAPI在识别过程中能够处理音素级别的细节,例如区分“s”和“th”的发音,提升整体的识别质量。
2.2.2 对开发者友好的接口设计
对于开发者来说,SAPI提供的接口非常友好,易于集成和使用。具体表现在:
- API的一致性 :SAPI遵循微软的COM(Component Object Model)技术规范,保证了接口的一致性,降低了学习成本。
- 丰富的文档和示例 :微软为SAPI提供了详尽的文档和多种语言的示例代码,帮助开发者快速上手。
- 良好的可扩展性 :开发者可以通过SAPI提供的接口,实现自定义的功能,如扩展词汇、定制语音识别逻辑等。
2.3 SAPI工具包的版本演变
2.3.1 SAPI 4.x到SAPI 5.x的升级改进
从SAPI 4.x升级到SAPI 5.x,微软进行了大量的改进,包括但不限于:
- 架构的优化 :SAPI 5.x引入了流式处理,使得语音识别更加实时和高效。
- 模块化设计 :SAPI 5.x支持更细粒度的模块化设计,使得开发者可以根据需要选择特定的功能模块。
- 性能的提升 :新的架构设计和算法优化使得SAPI 5.x在语音识别和语音合成上都有显著的性能提升。
2.3.2 不同版本的SAPI适用场景
不同的SAPI版本适用于不同的开发场景:
- SAPI 4.x :适用于需要稳定运行的旧系统或者应用程序,它在兼容性方面拥有优势。
- SAPI 5.x :适用于新项目和对实时性能有较高要求的应用程序。SAPI 5.x的高级功能,如流式识别和多语言支持,使其成为开发现代语音应用的首选。
在实际开发中,开发者需要根据具体的应用需求和技术条件选择合适的SAPI版本。
3. SAPI接口使用与音频文件处理
3.1 SAPI接口使用方法
3.1.1 SAPI接口的初始化与配置
在使用SAPI接口进行语音识别之前,开发者必须先进行初始化和配置。SAPI提供了几个核心的COM接口,包括 ISpRecognizer 、 ISpRecoContext 和 ISpRecoGrammar ,它们都是语音识别流程中的关键组件。
初始化SAPI接口的第一步是创建一个 ISpRecognizer 对象实例,它是语音识别引擎的代表。使用CoCreateInstance函数或者类厂模式创建实例,然后将其与一个合适的语言环境或者语音识别引擎进行绑定。
接下来,需要创建一个 ISpRecoContext 对象,该对象代表了一个识别会话。在该对象中,开发者可以指定如何识别语音输入,比如是在前台模式下工作还是后台模式,以及设置音频流的配置。
ISpRecoGrammar 接口用于管理识别引擎的语法。它允许开发者添加、删除和激活语法,语法可以是预先定义好的也可以是动态生成的。
除了这三个核心接口外,开发者还可以利用其他SAPI接口来优化识别效果,比如 ISpObjectTokenCategory 可用于选择不同的音频设备。
3.1.2 实现基本的语音识别流程
实现基本的语音识别流程通常包括以下步骤:
- 创建并初始化SAPI接口。
- 设置音频输入设备和采样参数。
- 从麦克风或其他音频输入设备接收音频数据。
- 将音频数据发送到
ISpRecognizer对象进行识别。 - 获取识别结果,并将其转换为文本。
- 清理并释放所有已创建的接口。
以下是一个简单的代码示例,演示如何使用SAPI接口进行基本的语音识别:
#include <sapi.h>
#pragma comment(lib, "sapi.lib")
int main(int argc, char* argv[]) {
CoInitialize(NULL);
ISpRecognizer *pRecognizer = NULL;
ISpRecoContext *pRecoContext = NULL;
ISpRecoGrammar *pRecoGrammar = NULL;
HRESULT hr = CoCreateInstance(CLSID_SpRecognizer, NULL, CLSCTX_ALL, IID_ISpRecognizer, (void**)&pRecognizer);
if (SUCCEEDED(hr)) {
hr = pRecognizer->CreateRecoContext(&pRecoContext);
}
if (SUCCEEDED(hr)) {
hr = pRecoContext->CreateGrammar(1, &pRecoGrammar);
}
if (SUCCEEDED(hr)) {
pRecoGrammar->LoadCmdFromFile(SPPF\Console, NULL, L"grammar.grxml");
}
if (SUCCEEDED(hr)) {
pRecoContext->SetNotifyWin32Event();
pRecoContext->Start();
hr = pRecoContext->WaitForRecognition(0);
if (SUCCEEDED(hr)) {
// 识别结果处理
}
}
// 释放资源
pRecoGrammar->Release();
pRecoContext->Release();
pRecognizer->Release();
CoUninitialize();
return 0;
}
在这个示例中,我们首先初始化了COM环境,然后创建了一个语音识别器对象,并为其创建了一个识别上下文。接着,我们创建了一个语法对象,并从一个GRXML文件加载了语法。之后,我们设置了一个事件通知,并启动了识别过程。最后,我们等待识别结果并处理这些结果,最后释放所有资源。
3.2 WAV文件播放实现
3.2.1 WAV文件格式解析
WAV文件是一种标准的音频文件格式,它包含了数字音频信息,通常以未压缩的线性脉冲编码调制(PCM)格式存储。一个WAV文件由几个主要部分组成:文件头(包含文件的基本信息),以及数据块(包含音频样本数据)。
文件头包含了关于音频数据的重要信息,如采样率、声道数、采样大小等。数据块包含实际的音频样本,以字节流形式存储。
由于WAV文件格式的广泛使用和简单性,它成为开发音频处理应用的理想选择。开发者可以通过读取文件头信息来获取音频文件的基本属性,然后进行音频处理。
3.2.2 利用SAPI播放音频文件
使用SAPI播放WAV文件的过程十分直接。SAPI提供了ISpStream接口,可以用来读取和播放音频流。
首先,需要创建一个 IStream 对象,并将其与WAV文件关联。然后,使用该 IStream 对象创建一个 ISpStream 接口的实例。之后,这个 ISpStream 对象可以通过 ISpAudio 接口与SAPI集成,以实现音频的播放。
以下是一个示例代码,演示如何使用SAPI播放一个WAV文件:
#include <iostream>
#include <sapi.h>
#pragma comment(lib, "sapi.lib")
int main() {
CoInitialize(NULL);
IStream *pStream;
if (SUCCEEDED(SHCreateStreamOnFile(L"test.wav", STGM_READ, &pStream))) {
ISpStream *pSpStream = NULL;
ISpAudio *pSpAudio = NULL;
HRESULT hr = CoCreateInstance(CLSID_SpStream, NULL, CLSCTX_INPROC_SERVER, IID_ISpStream, (void**)&pSpStream);
if (SUCCEEDED(hr)) {
hr = pSpStream->BindToStream(pStream);
}
if (SUCCEEDED(hr)) {
hr = CoCreateInstance(CLSID_SpAudio, NULL, CLSCTX_INPROC_SERVER, IID_ISpAudio, (void**)&pSpAudio);
}
if (SUCCEEDED(hr)) {
hr = pSpAudio->SetState(SPAudioStatePlaying, NULL);
}
// 清理资源
pStream->Release();
pSpStream->Release();
pSpAudio->Release();
}
CoUninitialize();
return 0;
}
在这个代码段中,我们首先创建了一个文件流对象 pStream ,它指向一个WAV文件。然后我们创建了 ISpStream 对象 pSpStream ,并通过 BindToStream 方法将其与文件流关联。接着我们创建了一个 ISpAudio 对象 pSpAudio 并通过调用 SetState 方法将音频设置为播放状态。最后,我们清理了创建的对象并释放了资源。
3.3 文字转语音技术实现
3.3.1 从文本到语音的转换流程
文字转语音(Text-to-Speech, TTS)技术允许计算机将文本信息转换为语音输出。实现TTS的流程一般包括以下步骤:
- 选择一个合适的TTS引擎或服务。
- 准备或接收需要转换的文本信息。
- 将文本信息传递给TTS引擎或服务。
- TTS引擎或服务将文本转化为语音信号。
- 播放生成的语音信号。
在Windows平台上,SAPI提供了强大的TTS功能。开发者可以通过 ITextToSpeech 接口来实现TTS,或者使用SAPI的 ISpVoice 接口来简化TTS的实现过程。
3.3.2 语音合成的质量优化
语音合成的质量优化可以从多个方面入手:
- 文本清洗:对于数字、缩写和专有名词进行格式化,以确保它们被正确读出。
- 语速和音调调整:调整TTS引擎的语速和音调,以获得更自然的语音输出。
- 语境考虑:对于特定上下文中的词组,使用合成器中的标记或预录制片段替换自动生成的语音。
- 立体声和3D音效:通过立体声输出和3D音效技术增强语音的立体感和现场感。
- 错误检测与纠正:实施反馈机制,通过用户反馈优化文本到语音的转换过程。
使用SAPI进行TTS的一个示例代码如下:
#include <sapi.h>
#pragma comment(lib, "sapi.lib")
int main() {
CoInitialize(NULL);
ISpVoice *pVoice = NULL;
HRESULT hr = CoCreateInstance(CLSID_SpVoice, NULL, CLSCTX_ALL, IID_ISpVoice, (void**)&pVoice);
if (SUCCEEDED(hr)) {
hr = pVoice->Speak(L"Hello, this is a text-to-speech example.", SPF_DEFAULT, NULL);
}
pVoice->Release();
CoUninitialize();
return 0;
}
在这段代码中,我们首先初始化了COM环境,然后创建了一个 ISpVoice 对象。通过 Speak 方法将一段文本信息转换为语音输出,其中第一个参数是我们希望读出的文本,第二个参数是语音合成的选项,第三个参数是一个指向事件对象的指针(这里我们不使用事件)。最后,我们释放了 ISpVoice 对象并进行了COM清理。
通过以上步骤,我们可以利用SAPI实现基本的文字转语音功能,并在实际应用中针对特定需求进行进一步的质量优化。
4. 语音识别与文字转语音的高级应用
语音识别技术的发展已经达到了一个相对成熟的阶段,它能够将人类的语音信息转换为文本形式,这不仅极大地提升了人机交互的便捷性,也为很多应用场景提供了高效的解决方案。与此同时,文字转语音技术也逐渐成熟,让计算机能够以自然的语音朗读出文本内容,拓展了交互的可能性。本章将深入探讨在高级应用领域,如何实现批量文字转语音和实时语音识别这两种技术的深度应用。
4.1 批量文字转语音技术
批量文字转语音技术的出现,为有大量文本需要转换为语音内容的场景提供了有效的解决方案,如为视障人士提供大量电子书籍的语音内容,或是为语言学习平台提供大量的语音资料等。以下是批量文字转语音技术的策略与实现,以及提升转换效率的方法。
4.1.1 批量处理的策略与实现
在处理大量文本转换为语音时,如果采用单条文本单次转换的方法,将会非常耗时且效率低下。因此,批量处理成为了必要的策略。为了实现高效的批量处理,可以将需要转换的文本分为多个批次,每个批次包含一定数量的文本片段。
代码实现示例:
#include <iostream>
#include <vector>
#include <sapi.h> // SAPI 头文件
ISpVoice *g_pVoice = NULL;
// 文本转语音的函数实现
HRESULT TextToSpeech(const std::wstring &text) {
HRESULT hr = CoInitialize(NULL);
if (FAILED(hr)) return hr;
// 创建语音合成接口实例
hr = CoCreateInstance(CLSID_SpVoice, NULL, CLSCTX_ALL, IID_ISpVoice, (void **)&g_pVoice);
if (SUCCEEDED(hr)) {
// 进行语音合成
hr = g_pVoice->Speak((LPCWSTR)text.c_str(), SPF_DEFAULT, NULL);
}
// 释放资源
if (g_pVoice) g_pVoice->Release();
g_pVoice = NULL;
CoUninitialize();
return hr;
}
int main() {
// 分批处理文本
std::vector<std::wstring> texts = {/* 大量文本数据 */};
for (const auto &text : texts) {
if (FAILED(TextToSpeech(text))) {
std::cerr << "语音合成失败" << std::endl;
}
}
return 0;
}
在上述代码中,我们将大量文本数据分批传递给 TextToSpeech 函数,该函数负责将文本内容转换成语音并播放。通过循环调用该函数,即可实现批量文本的语音转换。
4.1.2 批量转换效率的提升方法
为了进一步提升批量转换的效率,可以考虑以下几个方面的优化策略:
-
多线程处理 :利用多线程技术,允许系统同时处理多个文本片段的语音转换,从而显著提升处理速度。
-
异步合成 :使用异步语音合成可以避免主线程阻塞,使得应用界面保持响应,提升用户体验。
-
资源优化 :合理管理语音合成过程中的资源,如语音引擎的初始化和释放,确保系统资源的有效利用,避免不必要的资源浪费。
-
错误处理机制 :在批量处理过程中,应增加错误处理和异常捕获机制,保证一个任务的失败不会影响到整个批量转换的进度。
4.2 实时语音识别实现
实时语音识别技术能够将用户的语音实时转换为文本,具有广泛的使用场景,例如实时字幕、语音控制设备、实时翻译等。实现这一技术需要解决一些技术难点,包括语音到文本的实时转换流程以及如何保持转换过程的低延迟和高准确率。
4.2.1 实时语音识别的技术难点
在进行实时语音识别时,需要特别注意以下技术难点:
-
延迟问题 :实时语音识别必须保持极低的延迟,以便用户能够几乎无感知地进行语音与文字的转换。
-
噪声干扰 :真实环境中的背景噪音会影响语音识别的准确性。因此,需要有效的噪声抑制算法来提高识别率。
-
识别准确性 :提高识别的准确性是实时语音识别的核心,这需要强大的语音模型和算法支持。
-
计算资源 :实时语音识别对计算资源的要求较高,如何优化算法以减少资源消耗,也是实现难点之一。
4.2.2 实时语音到文本的转换流程
实时语音到文本的转换流程通常包括以下步骤:
-
麦克风录音 :从麦克风捕获用户的语音输入。
-
预处理 :对捕获的音频信号进行预处理,包括降噪、分帧等。
-
特征提取 :从预处理后的音频信号中提取出有助于识别的特征,如MFCC(梅尔频率倒谱系数)。
-
声学模型匹配 :将提取的特征与声学模型进行匹配,输出声学模型的得分。
-
语言模型解码 :将声学模型的得分与语言模型结合,解码得到最终的文本结果。
-
文本输出与反馈 :将解码得到的文本输出,同时提供反馈机制以优化识别过程。
代码实现示例:
#include <iostream>
#include <sapi.h>
ISpRecognizer *g_pRecognizer = NULL;
ISpStream *g_pStream = NULL;
// 实时语音识别回调函数
HRESULT OnEvent(SPEVENT const *pEvent) {
if (pEvent->eEventId == SPEI_END_SR_STREAM) {
// 语音识别结束,获取并输出识别结果
ISpRecoResult *pRecoResult = NULL;
g_pRecognizer->GetRecoResult(&pRecoResult);
// 这里需要进一步调用其他接口来获取识别文本
pRecoResult->Release();
}
return S_OK;
}
// 初始化语音识别器和流
void InitializeASR() {
HRESULT hr = CoInitialize(NULL);
if (FAILED(hr)) return;
// 创建语音识别器
hr = CoCreateInstance(CLSID_SpInprocRecognizer, NULL, CLSCTX_ALL, IID_ISpRecognizer, (void **)&g_pRecognizer);
if (SUCCEEDED(hr)) {
// 创建语音流
hr = g_pRecognizer->CreateStream(&g_pStream, SPDF_DEFAULT, NULL, NULL, NULL);
if (SUCCEEDED(hr)) {
// 设置语音事件回调函数
SPEVENTSOURCEOPTIONS options = {0};
hr = g_pRecognizer->SetEventInterest(SPEI_END_SR_STREAM, &options);
if (SUCCEEDED(hr)) {
// 开始录音识别
hr = g_pStream->StartInputStream();
if (SUCCEEDED(hr)) {
// ...
}
}
}
}
CoUninitialize();
}
int main() {
InitializeASR();
// ...
return 0;
}
在上述代码中,初始化了语音识别器和语音流,并设置了语音事件回调函数 OnEvent ,用于处理语音识别结束后的事件。需要注意的是,实际应用中还需要完成剩下的实现部分,包括设置语言和识别模式、处理最终识别结果等。
通过本章节的介绍,我们可以看到,批量文字转语音技术和实时语音识别技术在高级应用中的实现和优化。在下一章节中,我们将聚焦在Windows平台上如何利用Visual Studio 2013和SAPI SDK进行SAPI应用开发,包括开发环境的搭建、应用实例的编写以及在开发过程中可能遇到的问题和解决方案。
5. 基于Visual Studio 2013的SAPI应用开发
5.1 开发环境的搭建与配置
5.1.1 Visual Studio 2013的安装与设置
要开始基于Visual Studio 2013开发SAPI应用,首先需要正确安装和配置Visual Studio 2013环境。请按照以下步骤操作:
- 访问Microsoft官方网站或使用Microsoft软件安装介质安装Visual Studio 2013。
- 选择适合您开发需求的安装配置,推荐选择“通用Windows平台开发”、“C++开发”和“桌面开发”等相关工作负载。
- 完成安装后,打开Visual Studio 2013并检查是否需要任何更新,确保开发环境是最新的。
- 下载并安装SAPI SDK。可以从Microsoft的官方网站或者SDK的分发源获取SAPI SDK。
- 配置SAPI SDK到Visual Studio 2013中。通常这需要在项目属性中设置包含目录和库目录,并添加必要的库文件(如
sapi.lib)。
5.1.2 SAPI SDK的集成与配置
在集成SAPI SDK后,你需要确保开发环境可以找到SAPI的头文件和库文件。以下是集成步骤:
- 在Visual Studio中,打开项目属性。
- 导航到“C/C++”设置页,然后在“常规”选项中添加SAPI头文件所在的目录到“附加包含目录”。
- 在“链接器”设置页,选择“输入”选项,然后在“附加依赖项”中添加
sapi.lib。 - 设置项目的平台目标为x86或x64,这取决于你的SDK版本和系统架构。
- 在解决方案资源管理器中,右键单击项目名称,选择“添加” -> “现有项”,选择SAPI SDK目录下的相关头文件和库文件,以确保它们被包含在项目中。
通过以上步骤,你的Visual Studio 2013开发环境现在应该配置好了,可以开始编写和构建SAPI应用。
5.2 C++中SAPI的应用开发实例
5.2.1 开发语音识别应用的基本步骤
开发一个基本的语音识别应用涉及以下步骤:
- 创建一个新的Win32项目或控制台项目。
- 在代码中包含SAPI的头文件
sapi.h。 - 创建一个
ISpRecognizer接口的实例,用于处理语音输入。 - 使用
CoCreateInstance函数创建并初始化一个ISpVoice接口实例,用于语音输出。 - 创建一个
ISpStream接口实例来处理音频数据流。 - 实现回调函数处理语音识别事件。
- 启动语音识别引擎,将语音数据流传递给它,并开始识别。
- 等待识别过程结束并处理识别结果。
下面是一段简化的示例代码,展示了如何使用SAPI SDK创建一个基本的语音识别应用:
#include <sapi.h>
int main() {
HRESULT hr;
CLSID clsid;
hr = CLSIDFromProgID(L"SpeechLib.SpeechRecognizerObject", &clsid);
if (FAILED(hr)) {
return -1;
}
ISpRecognizer *pRecognizer = NULL;
hr = CoCreateInstance(clsid, NULL, CLSCTX_ALL, IID_ISpRecognizer, (void **)&pRecognizer);
if (FAILED(hr)) {
return -1;
}
// Initialize recognizer...
// Implement voice recognition using callbacks...
// Start and run the recognition process...
// Cleanup
pRecognizer->Release();
return 0;
}
5.2.2 开发文字转语音应用的基本步骤
为了将文本转换成语音,你可以使用 ISpVoice 接口,具体步骤如下:
- 创建一个
ISpVoice实例。 - 使用
Speak方法将指定的字符串文本转换为语音输出。 - 可以使用
SetRate和SetVolume等方法调整语音的语速和音量。
下面是一个简单的示例,演示如何使用SAPI将字符串转换成语音:
#include <sapi.h>
#pragma comment(lib, "sapi.lib")
int main() {
HRESULT hr;
ISpVoice *pVoice = NULL;
hr = CoCreateInstance(CLSID_SpVoice, NULL, CLSCTX_ALL, IID_ISpVoice, (void **)&pVoice);
if (FAILED(hr)) {
return -1;
}
// Convert text to speech
BSTR bstrText = SysAllocString(L"Hello, World!");
hr = pVoice->Speak(bstrText, SPF_DEFAULT, NULL);
if (FAILED(hr)) {
// Handle error
}
// Cleanup
pVoice->Release();
SysFreeString(bstrText);
return 0;
}
5.3 开发过程中的常见问题与解决方案
5.3.1 遇到的问题梳理与分析
在开发使用SAPI的应用时,开发者可能会遇到以下问题:
- COM初始化错误 :例如
CoInitialize或CoCreateInstance失败,这可能是由于COM库未正确初始化。 - 无法找到SAPI SDK :这通常是因为环境变量未设置正确,或者SAPI库文件未被添加到项目中。
- 权限问题 :运行应用程序可能需要管理员权限才能访问某些系统资源。
- 语音识别不准确 :可能是因为噪声干扰、发音不清晰或麦克风质量不佳。
- 性能问题 :在处理大量数据或实时语音时可能会遇到性能瓶颈。
5.3.2 针对问题的有效解决办法
对于上述问题,以下是一些可能的解决方案:
- COM初始化错误 :确保在使用SAPI之前调用了
CoInitialize。 - 无法找到SAPI SDK :检查项目的依赖库设置,并确保SDK的头文件和库文件的路径被正确添加到项目中。
- 权限问题 :确保应用程序以管理员权限运行,或调整应用程序的UAC设置。
- 语音识别不准确 :改善麦克风质量、减少背景噪声或优化语音识别引擎的配置。
- 性能问题 :优化代码,使用更高效的算法,或升级硬件以提高处理速度。
正确处理和解决这些常见问题,将大大提高开发SAPI应用的成功率和效率。
简介:Windows 7操作系统集成了微软的语音识别技术,提供用户通过语音命令与计算机交互的便利。开发者可利用SAPI工具包,开发语音识别和合成应用。SAPI包含丰富的接口和类,用于实现语音识别、音频播放和文字转语音等功能。此外,开发者还可以利用Visual Studio 2013和C++实现SAPI相关应用的开发,以构建丰富多样的语音应用程序。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)