
万字长文,深度解剖大语言模型(LLM)底层工作原理
以下是一篇纯粹技术干货、深入到实现细节的万字长文,旨在从根本上解析大型语言模型(LLM)的工作原理。我们来直接解剖LLM的核心——Transformer架构,并系统性地阐述其从零开始的训练过程,以及当前最前沿的优化与扩展技术。现代所有最先进的LLM,无论其名称或开发者,其根基都是2017年提出的Transformer架构。理解Transformer,就是理解LLM的第一性原理。其设计的核心在于,通

以下是一篇纯粹技术干货、深入到实现细节的万字长文,旨在从根本上解析大型语言模型(LLM)的工作原理。
我们来直接解剖LLM的核心——Transformer架构,并系统性地阐述其从零开始的训练过程,以及当前最前沿的优化与扩展技术。
Transformer架构的彻底解构
现代所有最先进的LLM,无论其名称或开发者,其根基都是2017年提出的Transformer架构。理解Transformer,就是理解LLM的第一性原理。其设计的核心在于,通过自注意力机制,实现了高效的并行计算和对长距离依赖的精确捕捉。
输入端:从文本到向量表示
计算机不理解文本,只理解数字。因此,在任何计算开始之前,输入文本必须被转换成高维向量。这个过程包含两个关键步骤:分词和嵌入。
分词(Tokenization)
分词是将原始文本字符串分解为模型能够处理的最小单元(Token)的过程。早期的模型使用单词或字符作为Token,但都存在明显缺陷:按单词分词会导致词汇表过大且无法处理未登录词(Out-of-Vocabulary, OOV);按字符分词则会丢失单词层面的语义信息并使得序列过长。
现代LLM普遍采用子词(Subword)分词算法,如:
-
字节对编码(Byte-Pair Encoding, BPE):一种数据压缩算法的变体。它首先将词汇表初始化为所有单个字符。然后,它迭代地合并频率最高的相邻Token对,形成一个新的Token,并加入词汇表。例如,
"low", "low", "low", "lower", "newest"这个语料,"l"+"o"出现最多,合并成"lo";然后可能是"lo"+"w"合并成"low";再然后是"low"+"er"合并成"lower"。通过这种方式,高频词被表示为单个Token,而罕见词可以被拆分为有意义的子词单元(如unbelievable->un,believe,able),极大地平衡了词汇表大小和语义表达能力。 -
WordPiece:与BPE类似,但它不选择频率最高的Token对,而是选择一个能够最大化训练数据似然(likelihood)的合并。这是Google BERT系列模型所采用的方法。
-
SentencePiece:这是Google开源的一个分词工具,它将所有文本(包括空格)都视为普通符号序列进行处理,可以直接从原始文本训练,不依赖于语言特定的预分词规则,在多语言处理上表现更佳。
分词后,每个Token都对应一个唯一的整数ID。"Hello, world!" 可能会被转换为 [15496, 11, 999, 0]。
词嵌入(Token Embeddings)
分词后的ID序列需要被转换为包含语义信息的向量。这是通过一个嵌入层(Embedding Layer)实现的。这个嵌入层本质上是一个巨大的查找表(Look-up Table),它是一个形状为 (V, d_model) 的权重矩阵,其中 V 是词汇表的大小,d_model 是模型的隐藏维度(例如,GPT-3中为12288)。
当ID为 15496 的Token输入时,模型会直接从这个矩阵中取出第15496行,这一行就是一个 d_model 维的向量,即该Token的初始词嵌入。这个嵌入矩阵是模型的重要参数之一,它会在训练过程中被不断优化,使得语义相近的Token在向量空间中也相互靠近。
位置编码(Positional Encodings)
Transformer架构本身是排列不变的(Permutation-Invariant),它通过自注意力并行处理所有Token,无法感知它们的顺序。但语序至关重要。为了解决这个问题,需要向输入向量中注入位置信息。
最经典的方法是源自原论文的正弦/余弦位置编码。其公式为:
其中:
-
pos是Token在序列中的位置(0, 1, 2, ...)。 -
i是向量中的维度索引(0, 1, 2, ...,d_model/2 - 1)。 -
d_model是嵌入向量的维度。
这种设计有几个精妙之处:
-
唯一性:每个位置都有一个独一无二的位置编码向量。
-
相对位置信息:对于任意固定的偏移量
k,PE_{pos+k}可以表示为PE_{pos}的一个线性函数。这使得模型可以轻易地学习到词语之间的相对位置关系。 -
泛化能力:即使模型在训练中只见过长度为512的序列,理论上它也能生成更长序列的位置编码,具备一定的外推能力。
这个位置编码向量会直接加到对应Token的词嵌入向量上,形成最终的输入向量。近年来,也出现了其他方法,如可学习的位置嵌入(Learned Positional Embeddings)(如BERT)和旋转位置嵌入(Rotary Positional Embeddings, RoPE)(如PaLM, Llama),RoPE通过在注意力计算中旋转Query和Key向量来引入相对位置信息,被证明在长序列任务上表现更优。
自注意力与多头注意力
这是Transformer的心脏。它动态地计算序列中每个Token与其他所有Token之间的关联度,并据此重新加权聚合信息,生成新的、富含上下文的Token表示。
自注意力机制(Self-Attention)的数学原理
对于每个输入向量 x_i,我们通过乘以三个可学习的权重矩阵 W^Q, W^K, W^V 来生成它的查询(Query)、键(Key)和值(Value)向量:
-
q_i = x_i W^Q -
k_i = x_i W^K -
v_i = x_i W^V
所有Token的Q, K, V向量可以组合成矩阵Q, K, V。注意力的计算遵循以下公式:
让我们分解这个公式:
-
QK^T(计算注意力分数):将查询矩阵Q与键矩阵K的转置相乘。这本质上是计算每个Token的Query向量与所有其他Token的Key向量之间的点积。点积的结果越大,表明两个Token的关联性越强。结果是一个(seq_len, seq_len)的分数矩阵。 -
/ sqrt(d_k)(缩放):d_k是Key向量的维度。这个缩放步骤至关重要。当d_k很大时,点积QK^T的结果可能会变得非常大,这将导致Softmax函数的梯度变得极小,造成梯度消失问题,使训练不稳定。除以sqrt(d_k)可以将方差稳定在1附近,保持梯度健康。 -
softmax(...)(归一化):对分数矩阵的每一行应用Softmax函数。这会将每一行的分数转换成总和为1的概率分布。这个分布就是注意力权重,表示在计算某个Token的新表示时,应该对其他所有Token赋予多大的权重。 -
...V(加权求和):将上一步得到的注意力权重矩阵与值矩阵V相乘。对于每个Token,其最终的输出向量是所有Token的Value向量根据注意力权重进行的加权平均。这样,输出向量就聚合了整个序列中所有相关Token的信息。
多头注意力机制(Multi-Head Attention)
一次自注意力计算只能让模型从一个“表示子空间”中学习关联性。为了让模型能够综合来自不同子空间的信息(例如,一个头关注句法关系,另一个头关注语义关联),Transformer采用了多头注意力。
其过程如下:
-
投影:将原始的Q, K, V通过
h组不同的线性投影(即乘以不同的W^Q_i, W^K_i, W^V_i矩阵,i从1到h)生成h套Q, K, V。通常,每个头的维度d_k会被设置为d_model / h。 -
并行注意力计算:对这
h套Q, K, V并行地执行上文所述的自注意力计算,得到h个输出矩阵head_i。 -
拼接与再投影:将这
h个输出矩阵在特征维度上拼接(Concatenate)起来,形成一个大的特征矩阵。然后,将这个拼接后的矩阵再乘以一个输出权重矩阵W^O,将其投影回原始的d_model维度。
多头机制允许模型在不同位置共同关注来自不同表示子空间的信息,极大地增强了模型的表达能力。
残差连接、层归一化与前馈网络
一个完整的Transformer层不仅仅是多头注意力。它还包括另外两个关键组件,以确保模型可以被深度堆叠并有效训练。
残差连接(Residual Connections)与层归一化(Layer Normalization)
深度神经网络面临一个严重的问题:梯度消失/爆炸。随着网络层数加深,梯度在反向传播过程中可能变得过小或过大,导致训练失败。Transformer通过在每个子层(多头注意力和前馈网络)周围使用残差连接和层归一化来解决这个问题。
其结构为:LayerNorm(x + Sublayer(x))
-
残差连接
(x + Sublayer(x)):Sublayer(x)是子层(如多头注意力)的输出。x是子层的输入。这种“捷径”连接允许梯度在反向传播时可以直接流过,极大地缓解了梯度消失问题,使得训练非常深的网络成为可能。 -
层归一化
(LayerNorm):层归一化对单个样本在特征维度上进行归一化,即计算该样本所有特征的均值和方差,并用它们来缩放特征。这与批量归一化(Batch Normalization)不同,后者是在一个批次内对每个特征进行归一化。层归一化有助于稳定训练过程中的隐藏层动态,平滑损失曲面,加速模型收敛。
位置全连接前馈网络(Position-wise Feed-Forward Network, FFN)
在每个注意力子层之后,Transformer层会应用一个FFN。这个网络独立且相同地应用于序列中的每个位置。它由两个线性变换和一个非线性激活函数组成:
或者更现代的实现中使用GELU(Gaussian Error Linear Unit)替代ReLU。
FFN的作用是:
-
增加非线性:注意力计算本身是线性的(Softmax除外),FFN引入了非线性能力,增强了模型的表达能力。
-
特征变换:它将注意力层聚合的信息进行进一步的变换和提炼,可以看作是特征的深度加工。通常,FFN的中间层维度(
d_ff)会远大于模型维度(d_model),例如4倍,这提供了一个扩展和收缩的瓶颈结构来提取更丰富的特征。
架构变体:Encoder-Only, Decoder-Only, Encoder-Decoder
基于上述基本组件,可以构建出不同类型的LLM架构:
-
Encoder-Decoder (编码器-解码器):这是原始Transformer的结构,用于序列到序列任务(如机器翻译)。编码器处理输入序列,生成其上下文表示。解码器则在此基础上,结合已生成的部分,自回归地生成输出序列。解码器比编码器多了一个交叉注意力(Cross-Attention)层,其Q来自解码器自身,而K和V则来自编码器的最终输出,从而在生成时“关注”输入序列的信息。代表模型:T5, BART。
-
Encoder-Only (仅编码器):这类模型(如BERT, RoBERTa)堆叠了多个编码器层。它们通过自注意力机制能够看到整个输入序列(双向上下文),因此非常适合做自然语言理解(NLU)任务,如文本分类、情感分析、命名实体识别。其预训练目标通常是掩码语言建模(MLM)。
-
Decoder-Only (仅解码器):这类模型(如GPT系列, Llama, PaLM)堆叠了多个解码器层。其核心特征是在自注意力层中使用了掩码(Masking)。在计算第
i个Token的注意力时,会将其后的所有Token(i+1,i+2, ...)的分数设置为负无穷,这样经过Softmax后它们的注意力权重就为0。这确保了模型在预测当前词时只能看到前面的词(单向上下文),完全符合文本生成的自回归特性。这类模型是当前主流生成式AI的基础。
LLM的训练与对齐
拥有了架构,还需要通过一个极其消耗资源的训练过程,将一个随机初始化的网络变成一个博学的模型。
预训练(Pre-training)
预训练的目标是在海量的无标签数据上学习通用的语言规律和世界知识。
数据管道
-
数据源:来源极其广泛,包括Common Crawl(一个庞大的网页抓取存档)、维基百科、书籍(如Google Books)、GitHub上的代码、科学论文(arXiv)等。目标是覆盖尽可能多样化的领域、语言和文体。
-
数据清洗:这是决定模型质量上限的关键一步。原始数据充满了噪声和毒性。清洗流程包括:
-
去重:在文档级别、句子级别甚至n-gram级别进行精确或模糊去重,防止模型在重复内容上过拟合,提高训练效率。
-
质量过滤:使用基于规则的启发式方法(如去除HTML标签、过滤掉短文本或符号比例过高的文本)和基于模型的分类器来筛掉低质量内容(如乱码、广告、自动生成的文本)。
-
去毒与去偏见:使用分类器识别并移除仇恨言论、色情内容、极端偏见等有害文本。同时,对数据进行平衡,避免在特定群体或观点上存在过多偏向。
-
个人身份信息(PII)移除:使用模式匹配和命名实体识别等技术,检测并移除姓名、电话号码、邮箱地址等个人隐私信息。
最终得到的预训练数据集规模可达数万亿(Trillions of)Token。
训练目标(Training Objectives)
-
因果语言建模(Causal Language Modeling, CLM):这是Decoder-only模型的标准训练方式,模型的目标是最大化序列的联合概率。在实践中,这意味着在每个时间步
t,模型根据前面的所有Tokenx_1, ..., x_{t-1},通过一个线性层加Softmax输出一个在整个词汇表上的概率分布,然后使用交叉熵损失函数来惩罚其与真实下一个Tokenx_t之间的差异。 -
掩码语言建模(Masked Language Modeling, MLM):Encoder-only模型的训练方式。在输入序列中随机选择15%的Token,其中80%用一个特殊的
[MASK]Token替换,10%用一个随机Token替换,10%保持不变。模型的目标是仅根据未被破坏的上下文,预测出这些被掩盖位置的原始Token。这强迫模型学习双向的、深度的上下文表示。
训练过程与扩展法则(Scaling Laws)
LLM的训练是一个巨大的工程。它需要在数千个GPU上并行训练数周甚至数月。训练过程使用AdamW等优化器,配合学习率预热(Warm-up)和衰减(Decay)策略。为了在海量GPU上进行训练,需要复杂的并行计算策略,如数据并行、张量并行、流水线并行和ZeRO(Zero Redundancy Optimizer)等技术。
扩展法则是指导LLM研发的重要经验性定律。研究表明,模型的损失(Loss)与模型大小(N,参数量)、数据集大小(D)和计算量(C)之间存在幂律关系。例如,L(N, D) ≈ (N_c/N)^α + (D_c/D)^β。这意味着,只要持续增加模型、数据和算力,模型的性能就会可预测地提升。DeepMind的Chinchilla研究进一步优化了这一法则,指出为了达到最优性能,模型大小和数据大小应该按比例同步增长,这对后续模型的训练资源分配起到了重要的指导作用。
对齐(Alignment):让模型有用且无害
预训练出的基础模型(Base Model)虽然知识渊博,但它只会做一件事:续写文本。它不理解“指令”,也可能生成有害内容。对齐(Alignment)就是通过微调,使其行为与人类的意图和价值观保持一致。RLHF是实现对齐的核心技术。
有监督微调(Supervised Fine-Tuning, SFT)
SFT是第一步,旨在教会模型遵循指令。
-
数据:需要一个高质量的、由人工编写的“指令-回答”数据集。这个数据集的质量远比数量重要。指令需要覆盖极广的范围,包括问答、摘要、创作、代码、推理等。
-
过程:在基础模型之上,使用这个数据集进行标准的有监督学习。模型学习将指令作为输入,生成期望的回答。SFT后的模型具备了初步的指令遵循能力,可以称之为“指令微调模型”。
基于人类反馈的强化学习(RLHF)
SFT只能教会模型“做什么”,但无法教会它“做得多好”。RLHF通过引入人类的偏好,进一步优化模型的输出质量。
训练奖励模型(Reward Model, RM)
-
数据收集:从一个指令库中采样指令,用SFT模型对每个指令生成多个(例如4-9个)不同的回答。
-
人类排序:让人类标注者对这些回答进行排序,从最好到最差。这些排序数据构成了偏好数据集。
-
模型训练:训练一个奖励模型(RM)。RM的架构通常也是一个预训练模型。它接收一个指令和模型的一个回答作为输入,输出一个标量分数,代表人类对这个回答的偏好程度。训练时,对于一对回答
(response_A, response_B),如果人类偏好A,则RM应该给出RM(prompt, A) > RM(prompt, B)。这通常通过一个特定的损失函数(如pairwise ranking loss)来实现。
通过强化学习(RL)优化LLM
RL环境设置:
-
策略(Policy):待优化的LLM本身。
-
动作空间(Action Space):模型的词汇表。策略的每个“动作”就是生成下一个Token。
-
状态(State):当前已经生成的文本序列。
-
奖励(Reward):对于一个完整的生成结果,由上一步训练好的RM给出其偏好分数。
PPO算法:使用近端策略优化(Proximal Policy Optimization, PPO)算法来更新LLM的参数。PPO的目标是最大化奖励,但同时要避免策略跑得离原始的SFT模型太远。
-
reward(y)是RM给出的分数。 -
KL(...)是KL散度,它衡量RL策略生成的文本分布与SFT策略生成的文本分布之间的差异。这个项是一个惩罚项,防止模型为了追求高奖励而生成奇怪的、不连贯的文本(所谓的“奖励作弊”)。 -
β是控制KL惩罚项强度的超参数。
通过这个过程,LLM学会了生成能够获得高奖励分数(即人类更偏爱)的回答,使其输出更有用、更诚实、更无害。
直接偏好优化(DPO)
RLHF流程复杂且训练不稳定。直接偏好优化(Direct Preference Optimization, DPO)等新方法正在兴起。DPO巧妙地证明,可以通过一个简单的分类损失函数直接在人类偏好数据上优化LLM,其效果等价于RLHF中的KL正则化策略梯度法,但完全绕过了训练奖励模型和进行强化学习的复杂步骤,大大简化了对齐过程。
前沿技术与未来展望
LLM领域日新月异,除了核心架构和训练流程,许多前沿技术正在推动其能力边界的扩展。
参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)
对一个千亿参数模型进行全参数微调(Full Fine-tuning)需要巨大的计算资源。PEFT技术旨在只微调模型的一小部分参数(<1%),就能达到接近全参数微调的效果。
-
LoRA(Low-Rank Adaptation):这是目前最流行和有效的PEFT方法。其核心思想是,模型在微调过程中的权重更新矩阵
ΔW是低秩的。因此,我们不去直接更新庞大的原始权重矩阵W,而是将其冻结。我们通过训练两个小的、低秩的矩阵A和B来近似ΔW(即ΔW = BA)。在推理时,计算x(W + BA)。由于A和B的参数量远小于W,训练成本和存储成本都大大降低。
涌现能力(Emergent Abilities)与思维链(Chain-of-Thought)
涌现能力指那些在小模型上不存在,但当模型规模超过一定阈值后突然出现的能力。例如,多步算术推理、代码生成、理解比喻等。这表明模型的“量变”确实能引起“质变”。
思维链(Chain-of-Thought, CoT)提示是一种利用涌现能力的技术。通过在提示中向模型展示几个解决复杂问题(如数学应用题)的“逐步思考”的例子,模型在回答新问题时也会模仿这种模式,先生成一个推理步骤,然后基于这个步骤得出最终答案。这显著提高了LLM在需要逻辑推理的任务上的准确率。
多模态(Multi-modality)
未来的模型将是多模态的,能够理解和处理文本、图像、音频、视频等多种信息。
-
实现原理:其核心思想是将不同模态的信息都编码到同一个向量空间中。例如,对于图像,可以使用一个预训练的视觉编码器(如ViT, Vision Transformer)将图像转换为一系列特征向量。然后,通过一个投影层(Projection Layer)将这些视觉向量映射到与文本Token嵌入相同的维度空间。这样,对于LLM来说,一段图像的特征向量就像一段特殊的文本Token一样,可以被注意力机制统一处理。
工具使用与智能体(Agents)
LLM自身存在知识截止和计算能力弱(如精确数学计算)的缺陷。通过赋予模型使用外部工具的能力,可以极大地扩展其功能。
-
ReAct (Reason and Act) 框架是一个典型的例子。在这种模式下,LLM的生成过程被分解为思考(Thought)、行动(Act)和观察(Observation)的循环:
-
思考:LLM分析当前任务,决定下一步需要什么信息或计算,并生成一个思考过程的文本。
-
行动:LLM根据思考,生成一个对外部工具的API调用,例如
Search("周瑜老师是谁")或Calculator("123*456")。 -
观察:系统执行这个API调用,并将返回的结果(如搜索结果或计算答案)作为“观察”信息。
-
迭代:将观察到的结果拼接回提示中,让LLM进行下一轮的思考-行动,直到任务完成。
通过这种方式,LLM可以充当一个智能体的“大脑”,调度各种工具来完成现实世界的复杂任务,这是通往通用人工智能(AGI)的重要路径。
结论
大型语言模型是一个集数据工程、分布式计算、深度学习理论和认知科学洞察于一体的复杂系统。其核心是基于注意力机制的Transformer架构,通过海量数据的预训练学习通用知识,再通过SFT和RLHF等对齐技术使其变得有用和可控。当前,该领域正朝着多模态、工具使用和更高效率的方向高速发展。理解这些底层技术细节,是真正掌握并利用这一变革性力量的关键所在。
近几年AI大模型的浪潮相信大家都感受到了,各种大模型以及相关技术百花齐放,GPT、Qwen、Llama、DeepSeek、Transformer、Self-Attention、LoRA、RAG、Function Call、MCP、AI Agent等等层出不穷,我认为,这其中最关键的就是Transformer这个技术了,Transformer翻译过来叫做“变形金刚”,巧的是,从它“变形”出来了两个非常牛逼的方向,一个是Encoder-Only,对应的是BERT模型,一个是Decoder-Only,对应的就是著名的GPT模型。
那么,大模型这么牛逼,底层是如何实现的呢?Transformer这么强悍,该如何理解它呢?GPT、DeepSeek这么火热,我们能不能自己也写一个出来呢?
在我看来,只要是技术,只要是代码,就没有我研究不会的,因此最近一段时间,我花了大量时间和精力,从零开始,手写了一个AI大模型!以下是我目前的代码目录(ipynb相当于python脚本文件):
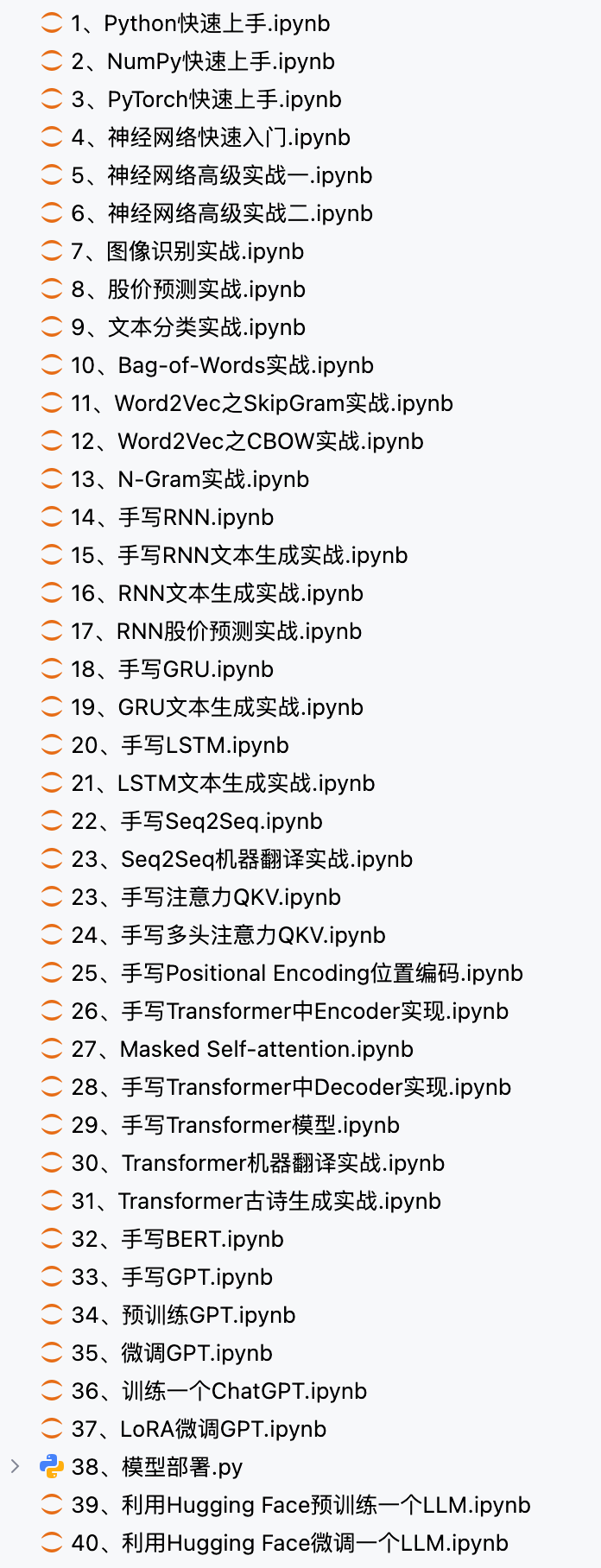
整个过程给我的感受是有难度,但是写的过程非常有趣,写出来之后也非常有成就感,轰动全世界的大模型,老子也能写出来!
不过,整个手写过程中涉及到的技术,远远不止上图中所看到的,还涉及到很多其他的概念、机制、公式和技术,要想手写一个大模型,并不是简简单单的写一个Demo,而是一个系统性的工程,需要对机器学习、自然语言处理、RNN、Seq2Seq、Transformer、模型预训练、模型微调、模型部署等全面掌握、系统学习。
如何学习AGI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取