基于大语言模型的档案数字化错别字检测工具,支持多线程加速处理
一款基于大语言模型的高效错别字检测工具,支持多线程运行,提升档案数字化处理速度。
·
温馨提示:文末有联系方式
产品简介:智能错别字检测助力档案数字化
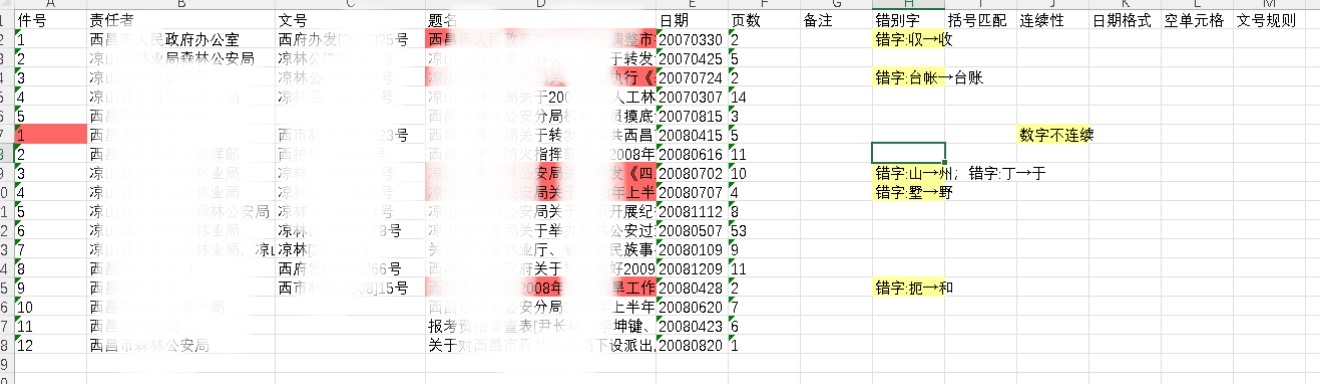
本工具是一款专为档案数字化设计的错别字检测软件,依托大语言模型技术实现高精度文本校对。
通过引入多线程机制,在硬件配置允许的前提下显著提升检测效率。
操作流程简单直观
启动软件后,只需将需要检查的xlsx表格文件直接拖入程序界面。
根据实际需求勾选各列的检测项目,点击“运行”按钮即可开始分析。
任务完成后,系统将在原文件所在目录自动生成一份详细的检测报告。
广泛支持主流AI模型
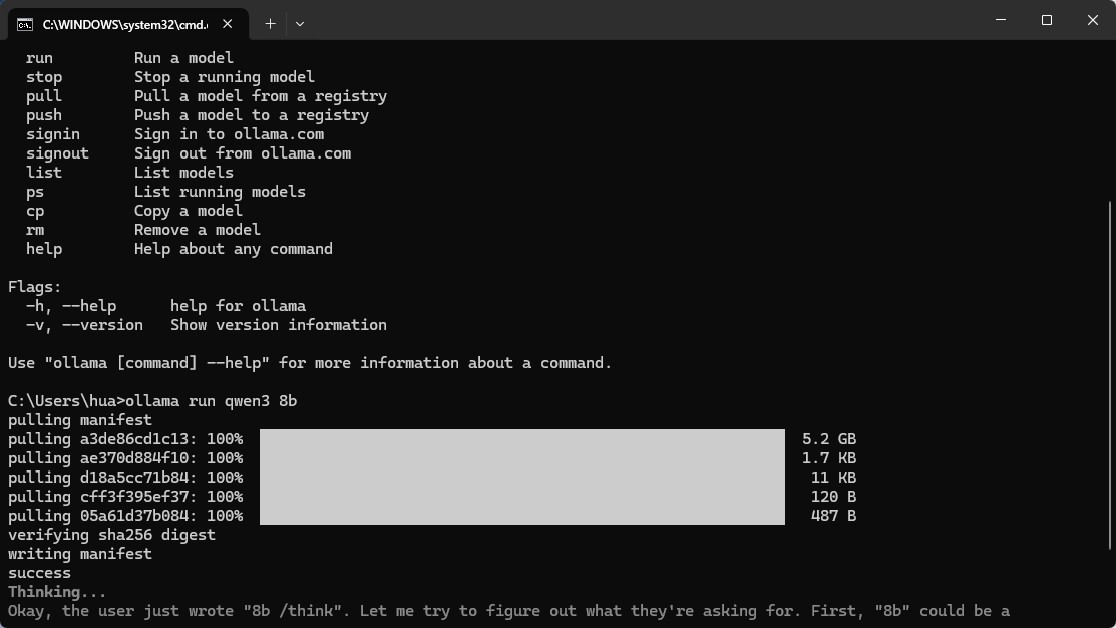
软件兼容所有可通过ollama运行的大语言模型,包括但不限于DeepSeek、Qwen、GPT系列等。
实测环境中使用qwen3:8b模型表现稳定,用户可根据自身需求选择合适的模型进行部署。
仅支持xlsx格式文件
请注意,当前版本仅支持.xlsx格式的Excel文件导入与检测,不支持xls或其他表格格式,请提前转换文件类型以确保正常使用。
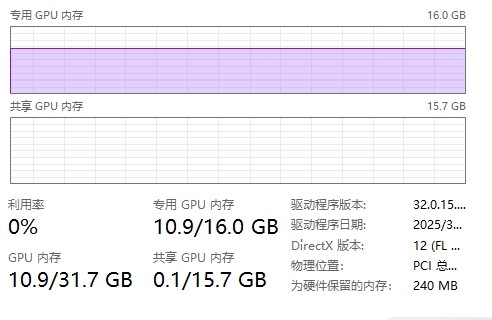
推荐硬件配置要求
建议使用配备独立显卡的电脑运行本软件,无独显设备可能导致处理速度极慢。
参考配置(如图3)在15秒左右可完成单条内容检测,并发处理约5条任务,显存占用超过10GB。
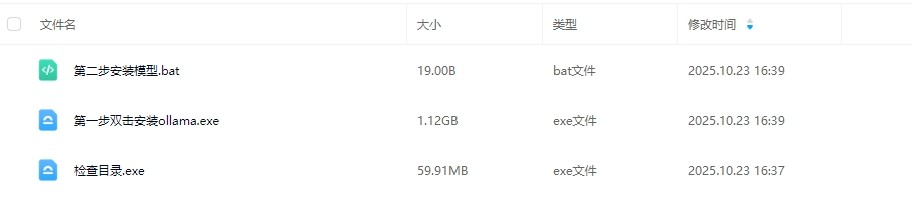
本地环境部署说明
请先在本地完成ollama平台及所需模型的安装,并测试对话功能正常后再进行软件使用。
整合包内含ollama安装程序与模型自动下载脚本,需保持网络连接直至模型下载完毕。
模型下载与网络要求
首次使用必须联网下载模型文件。
若下载速度下降,可关闭命令行窗口后重新启动脚本,支持断点续传继续下载未完成部分。
系统运行环境限制
本软件仅支持Windows 10及以上操作系统运行,不兼容旧版系统或Mac/Linux平台。
【资源编号:986638696854-----29.90】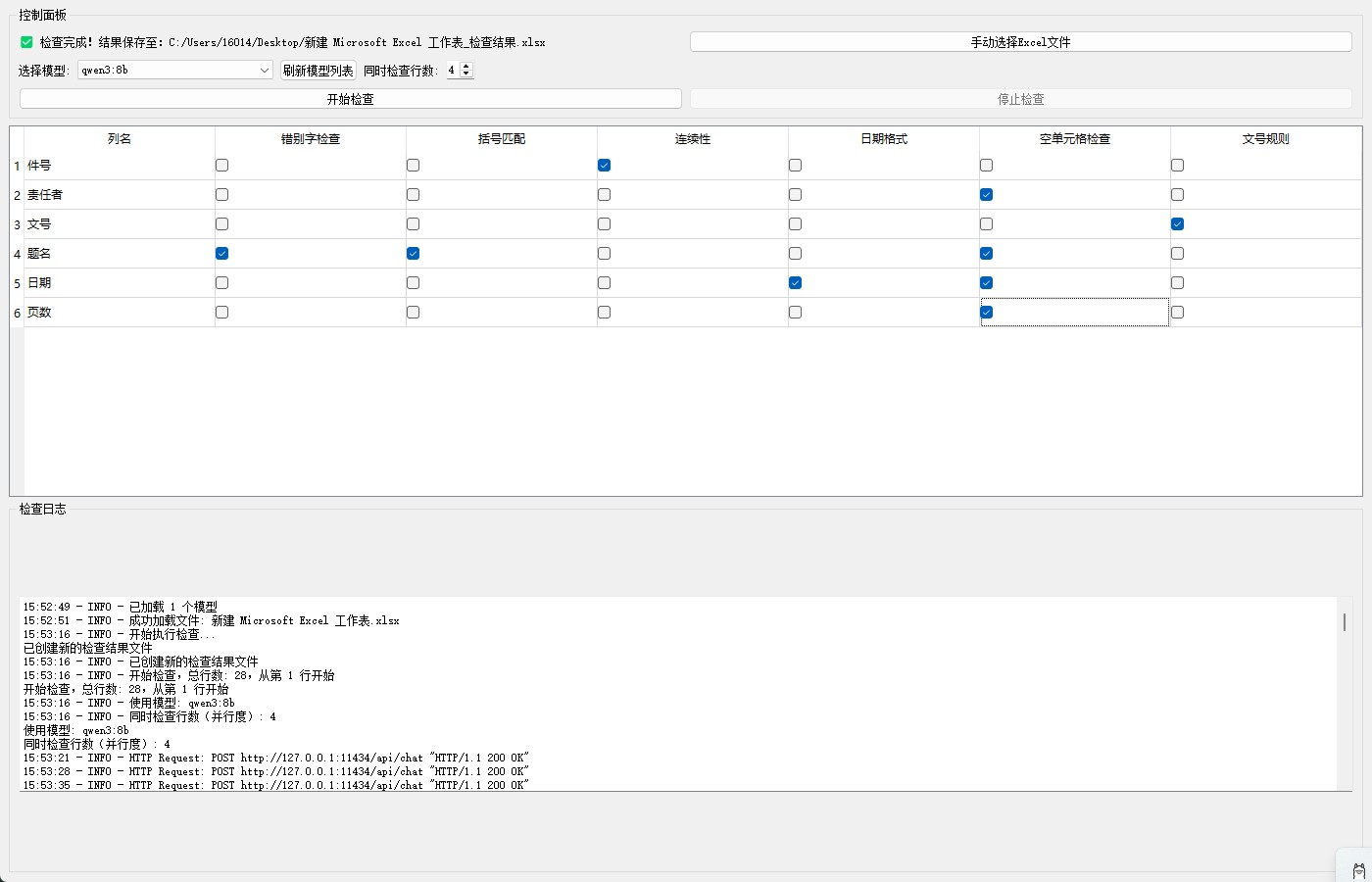

点击下面名片联系我
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)