月之暗面开源升级版多模态多专家推理模型:Kimi-VL-A3B-Thinking-2506
Kimi-VL-A3B-Thinking-2506是新一代多模态AI模型,在多个关键领域实现突破性提升:1) 智能思考能力增强,多模态推理准确率显著提高20.1分(MathVision)至8.4分(MathVista),同时思考效率提升20%;2) 视觉理解能力达到84.4分(MMBench-EN),支持320万像素高分辨率处理(V∗ Benchmark 83.2分);3) 视频理解能力突破,Vi
Kimi-VL-A3B-Thinking-2506
一、引言
Kimi-VL-A3B-Thinking-2506 是 Kimi-VL-A3B-Thinking 的一个更新版本,具有以下改进能力:
-
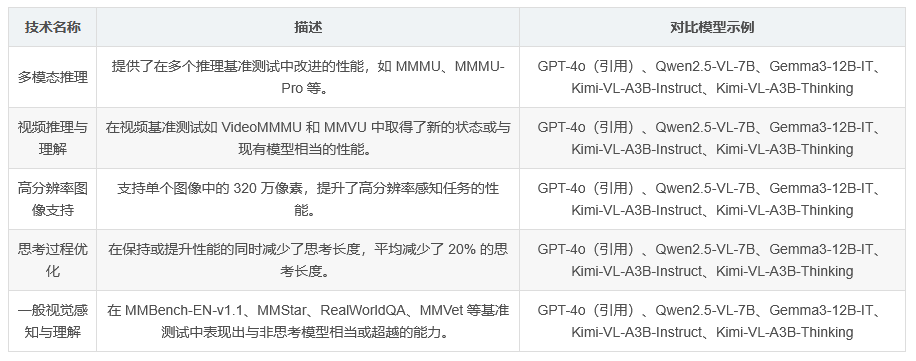
更智能的思考:在消耗更少 Tokens 的情况下,2506 版本在多模态推理基准测试中取得了更高的准确性,例如在 MathVision 上得分为 56.9(+20.1)、MathVista 上得分为 80.1(+8.4)、MMMU-Pro 上得分为 46.3(+3.3)、MMMU 上得分为 64.0(+2.1),平均思考长度减少了 20%。
-
更清晰的视觉理解:与专注于思考任务的旧版本不同,2506 版本在一般视觉感知和理解方面也能达到相同甚至更好的能力,例如在 MMBench-EN-v1.1 上得分为 84.4、MMStar 上得分为 70.4、RealWorldQA 上得分为 70.0、MMVet 上得分为 78.4,与非思考模型 Kimi-VL-A3B-Instruct 相当或超越。
-
视频场景的扩展:新版本在视频推理和理解基准测试中也有所提升,例如在 VideoMMMU 上得分为 65.2,成为开源模型中的最新状态,并且在一般视频理解方面也有良好的能力,例如在 Video-MME 上得分为 71.9,与 Kimi-VL-A3B-Instruct 相当。
-
更高分辨率的支持:新版本支持单个图像中的 320 万像素,是旧版本的 4 倍,这在高分辨率感知和 OS-agent 接地基准测试中带来了显著的改进,例如在 V∗ Benchmark 上得分为 83.2(无需额外工具)、ScreenSpot-Pro 上得分为 52.8、OSWorld-G(完整集带拒绝)上得分为 52.5。
二、性能表现
论文中提供了 Kimi-VL-A3B-Thinking-2506 在多个基准测试中与不同模型的性能对比,包括高效模型和之前的 Kimi-VL 版本,以及与开源模型(30B-70B 参数量)的对比。以下是一些关键性能指标的总结:
-
多模态推理:在 MMMU 和 MMMU-Pro 基准测试中,2506 版本在推理任务中表现出色,分别达到 64.0 和 46.3 的分数。
-
数学推理:在 MATH-Vision 和 MathVista_MINI 基准测试中,2506 版本分别取得 56.9 和 80.1 的分数,显示出在数学推理方面的强大能力。
-
视频理解:在 VideoMMMU 和 MMVU 基准测试中,2506 版本分别取得 65.2 和 57.5 的分数,表明其在视频场景中的推理和理解能力。
-
高分辨率感知:在 V∗ Benchmark 上得分为 83.2,ScreenSpot-Pro 上得分为 52.8,OSWorld-G 上得分为 52.5,显示出高分辨率图像处理的优势。
三、使用方法
论文提供了两种使用 Kimi-VL-A3B-Thinking-2506 的方法:通过 VLLM 进行推理和通过 Hugging Face Transformers 进行推理。
3.1 在 VLLM 上进行推理(推荐)
VLLM 是一个支持长解码的模型,可以生成最多 32K Tokens。论文建议使用 VLLM 进行推理,并提供了详细的安装和代码示例。
3.2 在 Hugging Face Transformers 上进行推理
论文也提供了使用 Hugging Face Transformers 进行推理的代码示例,包括安装环境要求、模型加载、图像处理和文本生成的具体步骤。
核心技术表格

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 41
41 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)