PowerInfer:使用消费级 GPU 提供快速大语言模型
23年12月来自上交大的论文“PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU”。
23年12月来自上交大的论文“PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU”。
PowerInfer是一款在单个消费级 GPU 个人计算机 (PC) 上运行的高速大语言模型 (LLM) 推理引擎。PowerInfer 设计的关键是利用 LLM 推理固有的高局部性,其特点是神经元激活呈幂律分布。这种分布表明,一小部分神经元(称为热神经元)在不同输入之间持续激活,而大多数冷神经元则根据特定输入而变化。据此 PowerInfer 设计 GPU-CPU 混合推理引擎:热-激活神经元预加载到 GPU 上以便快速访问,而冷-激活神经元在 CPU 上计算,从而显著减少 GPU 内存需求和 CPU-GPU 数据传输。PowerInfer 进一步集成自适应预测器和神经元-觉察稀疏算子,优化了神经元激活效率和计算稀疏性。评估表明,PowerInfer 在单个 NVIDIA RTX 4090 GPU 上对各种 LLM(包括 OPT-175B)的平均tokens生成率为 13.20 个tokens/秒,峰值为 29.08 个tokens/秒,仅比顶级服务器级 A100 GPU 低 18%。这显著优于 llama.cpp,最高可达 11.69 倍,同时保持模型精度。
在消费级 GPU 上部署 LLM 面临着巨大的挑战,因为它们需要大量的内存。LLM 通常用作自回归 Transformer,按顺序逐个生成文本tokens,每个token都需要访问由数千亿个参数组成的整个模型。因此,推理过程从根本上受到 GPU 内存容量的限制。这种限制在本地部署中尤其严重,因为本地部署中单个请求的处理(通常一次只处理一个)[6] 几乎没有并行处理的机会。
解决此类内存问题的现有方法包括模型压缩和卸载。量化 [12, 46]、蒸馏 [48] 和修剪 [23] 等压缩技术可以减小模型大小。然而,即使是深度压缩的模型对于消费级 GPU 来说仍然太大。例如,一个具有 4 位精度的 OPT-66B 模型需要大约 40GB 内存才能加载其参数 [20],甚至超过 NVIDIA RTX 4090 等高端 GPU 的容量。模型卸载在 Transformer 层级别将模型划分到 GPU 和 CPU 之间 [3, 14, 37]。像 llama.cpp [14] 这样最先进的系统将层分布在 CPU 和 GPU 内存之间,利用两者进行推理,从而减少所需的 GPU 资源。然而,这种方法受到 PCIe 互连速度慢和 CPU 计算能力有限的阻碍,导致推理延迟高。
LLM 推理中内存问题的关键原因是硬件架构与 LLM 推理特性之间的局部性不匹配(locality mismatch)。当前的硬件架构采用针对数据局部性(data locality)优化的内存层次结构设计。理想情况下,小型、频繁访问的工作集应存储在 GPU 中,GPU 提供更高的内存带宽但容量有限。相反,较大、不常访问的数据更适合 CPU,CPU 提供更广泛的内存容量但带宽较低。然而,每次 LLM 推理迭代所需的大量参数导致工作集对于单个 GPU 来说太大,从而阻碍了有效的局部性利用。
LLM 推理固有地表现出高度局部性。具体而言,在每次推理迭代期间,只有有限数量的神经元被激活,从而显著影响 token 推理的结果。这些特定于输入的激活可以在运行时准确预测。例如,在 OPT 模型中,激活图中不到 10% 的元素是非零的,这些元素在运行时的预测准确率超过 93% [21]。值得注意的是,LLM 中的神经元激活遵循斜幂律分布:一小部分神经元始终对各种输入中大多数激活(超过 80%)做出贡献(热激活),而大多数神经元参与剩余的激活,这些激活根据运行时的输入确定(冷激活)。
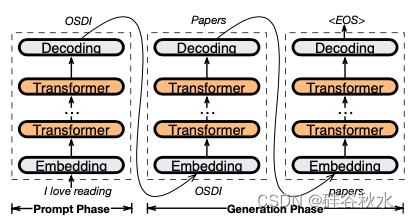
LLM 推理是一种自回归模型,它根据之前的tokens生成每个token。如图所示,该过程从提示(例如“我喜欢阅读(I love reading)”)开始,分为两个阶段:首先,提示阶段输出初始token(“OSDI”),然后生成阶段按顺序生成tokens,直到达到最大限制或序列结束()token。每个token生成(推理迭代)都需要运行完整的 LLM 模型。
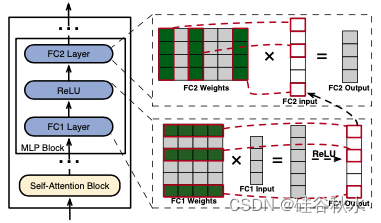
这些不同头部的计算结果被汇总,然后用作 MLP 块的输入。MLP 块通过全连接层和激活函数应用非线性变换来细化输入序列表示。输出要么前进到后续层,要么形成 LLM 的最终输出。
在下图(右)中,MLP 块的层 FC1 和 FC2 通过矩阵乘法生成向量。每个输出元素来自输入向量和神经元(权重矩阵中的行/列)的点积。激活函数(如 ReLU [1])充当门控,有选择地保留或丢弃向量中的值,从而影响 FC1 和 FC2 中的神经元激活。例如,此图中的 ReLU 会过滤掉负值,只允许 FC1 中的正值神经元影响输出。这些对输出有贡献的神经元被视为激活。同样,这些值也会影响 FC2 中哪些神经元被激活并参与其输出向量的计算。
激活稀疏性。LLM 推理在神经元激活方面表现出明显的稀疏性 [19,21,50]。例如,OPT-30B 模型中大约 80% 的神经元在推理过程中保持未激活状态。这种激活稀疏现象存在于自注意块和 MLP 块中。在自注意块中,近一半的注意头(神经元)贡献很小,导致其稀疏性很高。在 MLP 块中观察到的稀疏性主要归因于激活函数的特性。至关重要的是,激活稀疏性是输入特定的,这意味着特定神经元的激活直接受当前输入的影响,并且在模型的推理迭代开始之前无法预先确定。虽然在整个模型运行之前无法知道哪些神经元将被激活,但可以在正在进行的模型迭代中提前几层预测神经元激活。例如,DejaVu [21] 在推理过程中利用基于 MLP 的预测器,在预测神经元激活方面实现了至少 93% 的显著准确率。
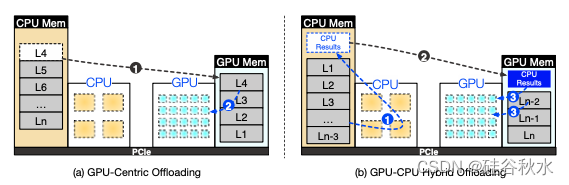
当前的模型压缩技术不足以在资源有限的消费级 GPU 中拟合大语言模型 (LLM)。相比之下,利用 CPU 额外的计算和内存资源的卸载技术为在此类硬件上容纳 LLM 提供了更可行的解决方案。如图说明两种主要的卸载方法:(a)GPU为中心和(b)CPU为中心。
如图所示:在 NVIDIA RTX 4090 GPU 上服务 OPT-30B 的性能比较和分析。黄色块代表 Flex-Gen,灰色块代表 DejaVu (UM),蓝色块代表 llama.cpp。(a)Y 轴表示一次迭代的执行时间,X 轴表示输入的批量大小。(b)Y 轴表示执行时间比,X 轴表示输入的批量大小。
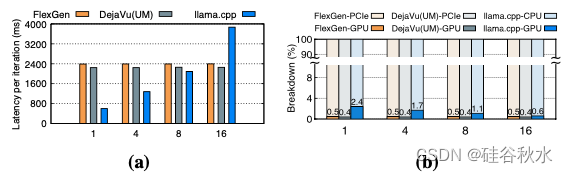
以 GPU 为中心的卸载利用 CPU 内存来存储超出 GPU 容量的模型参数部分。在每次迭代期间,如图 a 所示,它处理位于 GPU 内存中的参数,并根据需要从 CPU 传输更多参数。只要有足够的 CPU 内存和硬盘存储组合,此策略就可以推理不同大小的 LLM。FlexGen [37] 是一个典型的例子,它采用之字形(zig-zag)调度方法,优先考虑吞吐量而不是延迟,按顺序处理每一层的批次。尽管如此,这种方法在延迟-敏感场景中会导致每个 token 的延迟显著增加(如图a所示),这主要是由于 GPU 和 CPU 之间频繁传输数据,尤其是批量大小为 1 时。超过 99.5% 的处理时间都花在将 LLM 权重从 CPU 传输到 GPU 上,这严重影响了整体延迟,如图 b 所示。
混合卸载在 GPU 和 CPU 之间分配模型参数,在 Transformer 层级别对其进行拆分,如 llama.cpp [14] 所示。CPU 首先处理其层,然后将中间结果发送到 GPU 以生成 token。这种卸载方法通过最小化数据传输和缓解较慢的 PCIe 带宽,将推理延迟降低到 600 毫秒左右。
然而,混合卸载仍然面临局部不匹配问题,导致延迟不理想。每次推理迭代都会访问整个模型,造成分层 GPU-CPU 内存结构的局部性较差。GPU 虽然计算能力强大,但受到内存容量的限制。例如,24GB NVIDIA RTX 4090 GPU 上的 30B 参数模型意味着只有 37% 的模型在 GPU 上,将大多数计算任务转移到 CPU。内存较大但计算能力较低的 CPU 最终处理了 98% 的总计算负载。
LLM推理的局部性有两大点洞察:
- 尽管 LLM 激活稀疏性依赖于输入,但激活的神经元之间仍存在明显的幂律分布;
- 如果激活的神经元驻留在 CPU 内存中,则在 CPU 上计算它们比将它们传输到 GPU 计算更快。
如图展示 PowerInfer 的架构概览,包括离线和在线组件。由于不同 LLM 之间的局部性属性存在差异,离线组件应分析 LLM 的激活稀疏性,区分热神经元和冷神经元。在线阶段,推理引擎将两种类型的神经元加载到 GPU 和 CPU 中,在运行时以低延迟处理 LLM 请求。
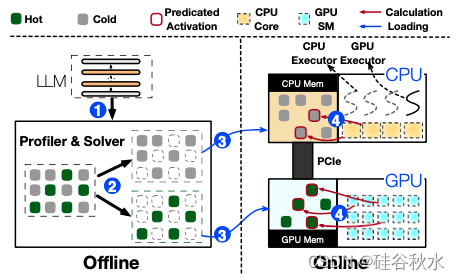
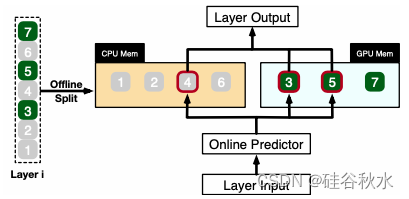
如图说明 PowerInfer 如何协调 GPU 和 CPU 来处理某一层的神经元。它根据离线数据对神经元进行分类,将热激活的神经元(例如,索引 3、5、7)分配给 GPU 内存,将其他神经元分配给 CPU 内存。在接收到输入后,预测器会识别当前层中的哪些神经元可能被激活。例如,它预测神经元 3、4 和 5 的激活。必须注意的是,通过离线统计分析识别的热激活神经元可能与运行时激活行为不一致。例如,神经元 7 虽然被标记为热激活,但在这种情况下预计是不活跃的。然后,CPU 和 GPU 都会处理预测的活跃神经元,忽略不活跃的神经元。GPU 计算神经元 3 和 5,而 CPU 处理神经元 4。一旦神经元 4 的计算完成,其输出就会发送到 GPU 进行结果集成。
神经元-觉察推理引擎
自适应稀疏预测器
PowerInfer 中在线推理引擎,仅处理预测会被激活的神经元来减少计算负荷。DejaVu [21] 也使用这种方法,它主张训练一组固定大小的 MLP 预测器。在每个 Transformer 层中,DejaVu 使用两个独立的预测器来预测自注意和 MLP 块中神经元的激活。因此,推理计算仅限于预计会活跃的神经元。
然而,为资源有限的本地部署设计有效的预测器具有挑战性,需要平衡预测准确度和模型大小。这些预测器经常用于神经元激活预测,应存储在 GPU 内存中以便快速访问。然而,大量固定大小预测器的大量内存需求可能会侵占存储 LLM 参数所需的空间。例如,OPT-175B 模型的预测器需要大约 27GB 的 GPU 内存,超过了 NVIDIA RTX 4090 GPU 的容量。另一方面,天真地减小预测器大小可能会损害准确性;预测器大小从 480MB 减少到 320MB 会导致其准确率从 92% 降至 84%,从而进一步对整体 LLM 准确率产生不利影响(例如,winogrande [35] 任务准确率从 72.77% 降至 67.96%)。
预测器的大小受两个主要因素影响:LLM 层的稀疏度及其内部倾斜度。如图所示,激活稀疏度较高的层,简化了识别激活神经元的任务,从而允许使用较小的预测器模型。相反,激活稀疏度较低的层,需要有更多参数的较大模型,因为准确定位激活的神经元变得越来越具有挑战性。此外,在高倾斜度的情况下,激活高度集中在少数神经元中,即使是紧凑的预测器也可以实现高精度。
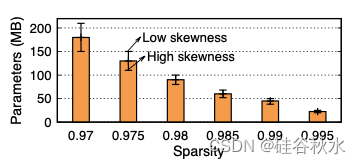
为了针对这些因素进行优化,PowerInfer 为每个 Transformer 层设计了一种非固定大小预测器的迭代训练方法。该过程首先根据层的稀疏度分布建立基线模型大小(如上图所示)。随后,迭代地调整模型大小,同时考虑内部激活斜度以保持准确性。MLP 预测器通常包括输入层、隐层和输出层。由于输入层和输出层的大小由 Transformer 层的结构决定,因此修改主要针对隐层。在迭代调整过程中,隐层的维度会根据观察的斜度进行修改。对于表现出明显斜度的层,隐层大小会逐渐减小,直到准确度降至 95% 以下。相反,对于斜度最小的层,则增加维度以提高准确性。通过这种方法,PowerInfer 有效地将预测器参数限制为总 LLM 参数的 10%。
神经元放置和管理
当离线求解器确定神经元放置策略时,PowerInfer 在线推理引擎会根据该策略将模型加载到 CPU 和 GPU 内存中。对于可能由多个权重矩阵组成的每一层,PowerInfer 根据神经元是否热激活将每个神经元分配给 GPU 或 CPU。
确保以正确的顺序准确计算这些分割神经元,对于获得精确结果至关重要。为此,PowerInfer 创建两个神经元表,一个位于 CPU 中,另一个位于 GPU 内存中。这些表将每个神经元与其在矩阵中的原始位置相关联。在与输入张量相乘的过程中,每个神经元都会与其相应的张量值交互,并由神经元表中映射引导。对于像 OPT-175B 这样需要 350GB 存储空间的 LLM 来说,这些神经元表所需的附加内存相对较少,总共只有大约 9MB。
GPU-CPU混合执行
鉴于 PowerInfer 仅处理有限数量预测为活跃的神经元,例如 MLP 层中不到 10%,GPU 和 CPU 协作的一种潜在方法涉及将冷激活神经元权重从 CPU 传输到 GPU 进行计算。但是,根据 “洞察点-2”,将激活的神经元传输到 GPU 所花费的时间超过了在 CPU 上直接计算所需的时间。因此,PowerInfer 实现 GPU-CPU 混合执行模型,其中两个单元独立计算各自的激活神经元,然后在 GPU 上合并结果。这种方法有效地平衡计算工作量,充分利用每个单元的优势,同时减少传输时间效率低下的问题。
在推理之前,PowerInfer 构建一个计算有向无环图 (DAG),每个节点代表一个计算的 LLM 推理算子,并将其存储在 CPU 内存中的全局队列中。队列中的每个算子都标有其先决条件算子。在推理过程中,两种类型的执行器(由主机操作系统创建的 pthreads)管理 CPU 和 GPU 上的计算。它们从全局队列中提取算子,检查依赖关系,并将它们分配给适当的处理单元。GPU 和 CPU 使用它们的神经元-觉察算子,GPU 执行器使用 cudaLaunchKernel 等 API 启动 GPU 算子,CPU 执行器协调未占用的 CPU 核进行计算。在执行算子之前,CPU 执行器还会确定并行计算所需的线程数。为了管理算子依赖关系,尤其是当 CPU 算子的父节点在 GPU 上处理时,屏障可确保在 CPU 启动算子之前 GPU 计算已完成。
在激活的神经元在 GPU 和 CPU 之间分配这个场景中,这些处理单元之间的同步也变得至关重要。一个单元完成其神经元计算后,它会等待另一个单元合并结果。随着 GPU 神经元被更频繁地激活,PowerInfer 会将合并操作分配给 GPU。为了优化同步开销,用一种选择性同步策略,当 CPU 执行器中没有激活的神经元时,绕过结果同步,允许其继续执行后续块,从而提高整体效率。
神经元-觉察算子
考虑到 LLM 中的激活稀疏性,矩阵乘法运算可以绕过非激活神经元及其权重,因此必须使用稀疏算子。然而,当前的稀疏矩阵乘法工具(包括最先进的稀疏-觉察编译器,如 SparTA [52] 和 Flash-LLM [45])以及库,如 cuSPARSE [30] 和 Spunik [33],在这方面都存在不足。它们要么仅支持稀疏-觉察内核的静态编译,要么需要将稀疏矩阵动态转换为密集格式,从而导致显著的性能开销,尤其是这种动态稀疏性。此外,动态 JIT 编译器 PIT [51] 虽然对于 GPU 上的一般稀疏矩阵乘法很有效,但不适合 CPU-GPU 混合执行,因为 CPU 计算能力有限。
为了克服这些限制,PowerInfer 引入了神经元-觉察算子,这些算子可直接在 GPU 和 CPU 上计算激活的神经元及其权重,而无需在运行时转换为密集格式。这些算子与传统算子不同,因为它们关注矩阵中的单个行/列向量,而不是整个矩阵。它们首先确定神经元的激活状态,如果是就处理它,以及参数矩阵相应行或列。
神经元放置策略
为了充分释放 GPU 和 CPU 的计算能力,PowerInfer 的离线组件提供了放置策略来指导每个神经元分配给 GPU 还是 CPU。该策略由求解器输出,控制每个层内的神经元放置,从而定义各个处理单元的运行计算工作量。求解器会考虑一系列因素,包括每个神经元的激活频率、通信开销以及处理单元的计算能力,例如其内存大小和带宽。
求解器为每个神经元定义一个影响度量(impact metric)来模拟其激活信息。通过将神经元影响与不同计算单元的能力相结合,求解器构建了一个整数线性规划(ILP)模型来生成最佳神经元放置。
实现
PowerInfer 在线推理引擎将附加的 4,200 行 C++ 和 CUDA 代码合并到 llama.cpp [14] 中来实现,llama.cpp 是一个为 PC 设计的最先进的开源 LLM 推理框架。PowerInfer 所做的扩展包括对模型加载器的修改,以便根据离线求解器的输出指导在 GPU 和 CPU 之间分配 LLM。还优化了 GPU-CPU 混合执行的推理引擎,并为两个处理单元引入了 10 个神经元-觉察算子。llama.cpp 的所有其他组件和功能保持不变。例如,KV 缓存继续驻留在 CPU 内存中,为热激活神经元提供更多的 GPU 内存,因为它的访问对推理延迟的影响最小,特别是在小批次情况下。
此外,大约 400 行 Python 代码被添加到 transformers 框架 [44],使其能够用作 PowerInfer 的离线分析器和求解器。 PowerInfer 的当前实现支持一系列主流 LLM 系列,这些系列的参数大小各不相同,包括 OPT [49] 系列(参数大小从 7B 到 175B)、LLaMA [42] 系列(参数大小从 7B 到 70B)和 Falcon-40B [2]。对于这些模型,PowerInfer 使用 DejaVu [21] 来训练在线激活预测器,并通过自适应训练方法进行增强。虽然训练 LLM 是一个漫长的过程,通常需要几个小时,但它是一次性任务。通过使用多个高端 GPU,可以显著缩短此过程的持续时间。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 13
13 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)