SayPlan:使用 3D 场景图为可扩展的机器人任务规划落地大语言模型
23年7月来自澳洲昆士兰科技大学和阿德莱德大学的论文“SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning”。
23年7月来自澳洲昆士兰科技大学和阿德莱德大学的论文“SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning”。
大语言模型 (LLM) 在开发用于各种任务的通用规划智体方面,已显示出令人瞩目的成果。然而,在广阔的多层楼和多房间环境中实施这些规划对机器人来说是一个巨大的挑战。SayPlan,这是一种基于 LLM 的可扩展方法,使用 3D 场景图 (3DSG) 表示为机器人进行大规模任务规划。为了确保方法的可扩展性,(1) 利用 3DSG 的层次结构特性,让 LLM 从完整图的一个较小、折叠表示中对任务相关的子图进行语义搜索;(2) 通过集成一个经典路径规划器来缩短 LLM 的规划范围;(3) 引入迭代重规划流水线,使用来自场景图模拟器的反馈来细化初始规划,纠正不可行的操作并避免规划失败。在两个大规模环境中评估方法,这两个环境多达 3 层楼和 36 个房间,拥有 140 项资产和目标,表明该方法能够从抽象和自然语言指令中为移动机械手机器人落地大规模、长期任务规划。
“给我泡杯咖啡,放在我的桌子上”——成功执行这样一个看似简单的命令,对今天的机器人来说仍然是一项艰巨的任务。相关挑战渗透到机器人技术的方方面面,包括导航、感知、操控以及高级任务规划。大语言模型 (LLM) [1, 2, 3] 的最新进展,已在将常识知识融入机器人技术方面取得了重大进展 [4, 5, 6]。这使机器人能够为需要大量背景知识和语义理解的各种任务规划复杂的策略。
要使 LLM 成为机器人技术中的有效规划者,它们必须立足于现实,也就是说,它们必须遵守机器人运行的物理环境所提出的约束,包括可用的affordance、相关谓词以及动作对当前状态的影响。此外,在广阔的环境中,机器人还必须了解它在哪里,找到感兴趣的项目,并理解环境的拓扑排列,以便在必要的区域内进行规划。为了解决这个问题,最近的研究探索利用基于视觉的价值函数 [4]、目标检测器 [7, 8] 或场景的规划域定义语言 (PDDL) 描述 [9, 10] 使基于 LLM 规划器的输出落地。然而,这些努力主要局限于小规模环境,通常是单个房间,其中预先编码所有现有资产和目标的信息。面临的挑战在于,扩展这些模型。随着环境的复杂性和维度的扩大,以及越来越多的房间和实体进入场景,在 LLM 的上下文中预先编码所有必要的信息变得越来越不可行。
为此,本文提出一种可扩展的方法 SayPlan,用于在跨多个房间和楼层的环境中落地基于 LLM 任务规划器。利用越来越多的 3D 场景图 (3DSG) 研究来实现这一目标 [11, 12, 13, 14, 15, 16]。 3DSG 可以捕捉环境的丰富拓扑和层次化语义图形表示,并能够使用自然语言对任务规划所需的必要信息进行编码,包括目标状态、谓词、可供性和属性,适合由 LLM 进行解析。
如图所示SayPlan概述。SayPlan 分为两个阶段运行,以确保可扩展性:(左)给定一个折叠的 3D 场景图和任务指令,LLM 进行语义搜索以识别包含解决任务所需项目的合适子图;(右)LLM 然后使用探索的子图生成高级任务规划,其中一个经典路径规划器完成规划的导航部分;最后,该规划通过场景图模拟器的反馈进行迭代重规划过程,直到确定可执行规划。左上角的数字代表操作流程。
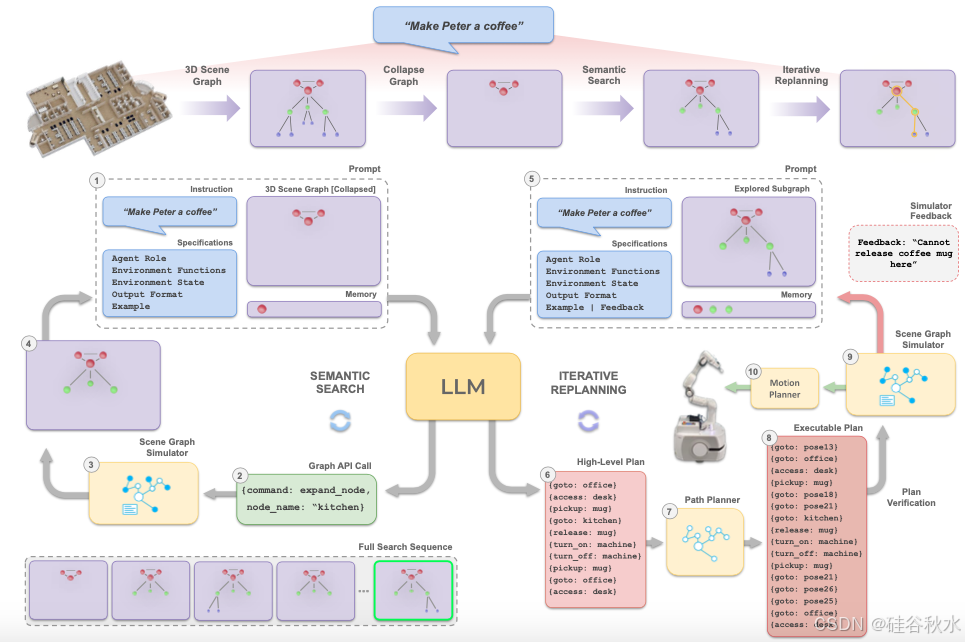
假设使用现有技术 [15、13、11] 生成一个预先构建的大规模环境 3DSG 表示。整个 3DSG 可以表示为 NetworkX Graph 目标 [42],并以文本序列化为 JSON 数据格式,可由预训练的 LLM 直接解析。3DSG 中单个资产节点的示例表示为:{名称:咖啡机,类型:资产,位置:厨房,功能:[开启,关闭,释放],状态:关闭,属性:[红色,自动],位置:[2.34,0.45,2.23]},节点之间的边表示为 {厨房↔咖啡机}。3DSG 以分层方式组织,主要分为四个级别:楼层、房间、资产和目标,如图所示。
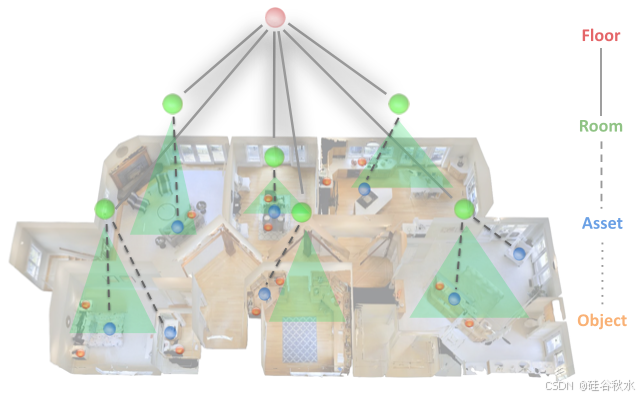
顶层包含楼层,每层都分支到几个房间。这些房间通过姿势节点相互连接,以表示环境的拓扑结构。在每个房间内,我找到资产(不可移动实体)和目标(可移动实体)。资产和目标节点都编码细节,包括状态、affordance、颜色或重量等附加属性以及 3D 姿势。该图还包含一个动态智体节点,表示机器人在场景中的位置。注:此层次结构是可扩展的,节点级别可以调整以捕获更大的环境,例如校园和建筑物。
场景图模拟器 ψ 是指一组 API 调用,用于操纵和操作 JSON 格式的 3DSG,使用以下函数:1) collapse (G):给定一个完整的 3DSG,此函数返回一个更新的场景图,该场景图仅显示 3DSG 层次结构中的最高级别,例如楼层节点。 2) expand (node_name):返回更新后的 3DSG,显示与节点名称相连的下一级所有节点。 3) contract (node_name):返回更新后的 3DSG,隐藏与节点名称相连的下一级所有节点。 4) verify_plan (plan):在 3DSG 捕获的抽象图级别上正向模拟生成的规划,检查每个动作是否符合环境的谓词、状态和affordance。比如,如果装有香蕉的冰箱已关闭,则返回文本反馈,例如“无法拿起香蕉”。
其提出一个可扩展的框架,用于使用 3DSG 表示在跨多个楼层和房间的大规模环境中支持预训练 LLM 的通用任务规划能力。给定一个 3DSG G 和一个用自然语言定义的任务指令 I,可以将框架 SayPlan 视为一个高级任务规划器 π(a|I, G),它能够生成基于移动机械手运行环境的长期规划 a。然后,该规划被输入到低级的基于视觉运动规划器中进行实际执行。为了确保 SayPlan 的可扩展性,引入了两个阶段:语义搜索和迭代重规划。 SayPlan 流程的伪代码见算法 1。

除非另有说明,否则使用 GPT-4 [3] 作为底层 LLM 智体。遵循与 Wake [5] 类似的提示结构。定义智体的角色、与场景图环境有关的详细信息、所需的输出结构和一组输入输出示例,它们共同构成用于上下文学习的静态提示。这个静态提示与任务和环境无关,占用了 LLM 输入的约 3900 个 tokens。在语义搜索期间,输入提示的 3D 场景图和内存组件都会在每一步更新;而在迭代重规划期间,只有反馈组件会使用来自场景图模拟器的信息进行更新。在所有情况下,都会提示 LLM 输出一个 JSON 目标,其中包含调用提供的 API 函数的参数。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 26
26 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)