阿里QwQ-32B发布:国产推理模型强势登场,直面DeepSeek和OpenAI!
QwQ-32B 是一款专为“复杂推理任务”打造的大型语言模型(LRM, Large Reasoning Model),具备高达320 亿参数的能力。✅比起 DeepSeek-R1 的主模型(6710 亿参数)要小一个数量级;✅远比 o1-mini、Claude Haiku 等轻量模型要强;✅ 同时具备实用性和计算效率,在资源有限场景下依然表现优异。

💡 阿里QwQ-32B发布:国产推理模型强势登场,直面DeepSeek和OpenAI!
近日,阿里巴巴旗下的 Qwen 团队发布了自研大型推理模型 QwQ-32B 正式版,悄然在大模型技术圈内掀起波澜。作为一款定位于高性能通用推理任务的模型,QwQ-32B 不仅具备强悍的数学与编程能力,其在推理路径优化、资源效率和人类对齐方面的创新也令人印象深刻。
这不仅是对 DeepSeek-R1 和 OpenAI o1-mini 的直接回应,更是中国本土模型在 LLM 实际能力竞赛中的一次漂亮发力。
🚀 什么是 QwQ-32B?为什么它很重要?
QwQ-32B 是一款专为“复杂推理任务”打造的大型语言模型(LRM, Large Reasoning Model),具备高达 320 亿参数 的能力。在业界内,这个参数规模可以说是介于中型通用模型和超大规模专家模型之间的“黄金区间”:
- ✅ 比起 DeepSeek-R1 的主模型(6710 亿参数)要小一个数量级;
- ✅ 远比 o1-mini、Claude Haiku 等轻量模型要强;
- ✅ 同时具备实用性和计算效率,在资源有限场景下依然表现优异。
值得注意的是:虽然 DeepSeek-R1 参数量庞大,但它采用的是 MoE(混合专家)结构,单次推理中实际只激活部分参数,而 QwQ-32B 是密集模型,在计算效率和响应一致性方面更为稳定。
📈 QwQ-32B能做什么?真的能“思考”了吗?
目前,大语言模型在多个垂直任务上表现已十分出色,但“推理”能力却一直是评价模型“是否真正聪明”的关键。
QwQ-32B 的目标正是让模型不仅仅“记住知识”,而是能够“深度思考,逐步求解问题”。
✅ 技术突破:强化学习+结果驱动奖励机制
传统 LLM 在复杂任务中常常“胡说八道”,因为它们并不理解推理步骤。QwQ-32B 使用了一个非常有趣的两阶段训练方法:
-
第一阶段:基于结果的奖励(Result-based RL)
- 模型先自己“猜”一个答案;
- 然后通过外部工具(如数学求解器、代码执行器)验证结果;
- 验证正确后给予正向奖励,错误则重新尝试。
-
第二阶段:泛化训练(Generalized RL)
- 引入了通用指令、代理行为、人类偏好等多样化任务;
- 使用少量人工规则(如对话风格评分器)进行强化训练;
- 目标是让模型在保持推理能力的同时,能更好理解任务、听懂人话。
这种策略的亮点在于:只奖励结果,不管中间过程,但却通过“尝试-反馈-改进”的强化学习逐步靠近理想推理路径。相比以往“强行塞答案”的方式,这种做法更像是在训练一个会用脑子解决问题的AI助手。
💡 举个例子:让QwQ-32B解一道高考数学压轴题
比如你输入:
某函数 f(x)=ax^2+bx+c 满足 f(1)=1,f(2)=4,f(3)=9,求 a, b, c。
普通模型可能会直接扔出一个错乱的结果。但 QwQ-32B 会尝试构建方程组:
- f(1)=a + b + c = 1
- f(2)=4a + 2b + c = 4
- f(3)=9a + 3b + c = 9
然后一步步解方程,最终输出:
- a=1,b=0,c=0。
这就是“会思考”的体现。
🧠 超长上下文:支持13万个Token,理解复杂场景更容易
很多推理问题不是一句话能说清的,比如你给模型一个复杂需求文档、几十行代码、或者一个小说章节,普通模型很快就“记不住”上下文。
QwQ-32B 最大支持 131,072 tokens,相当于100多页文档!这意味着它可以处理整段代码、复杂推理链、或跨页面的问答任务,能力已对标 Claude 3.7 Sonnet 和 Gemini 1.5 Pro 级别。
📉 性能对比图没写但结论很清晰:
- 🏆 在数学与代码测试中,QwQ-32B 几乎追平 DeepSeek-R1;
- ✅ 超越 o1-mini 与 DeepSeek-R1 的精简版;
- ❌ 但仍略逊于 OpenAI o1 和 Claude Sonnet 等顶级模型。
不过别忘了:QwQ-32B 是开源的,可以自己部署,这点就赢了一大截!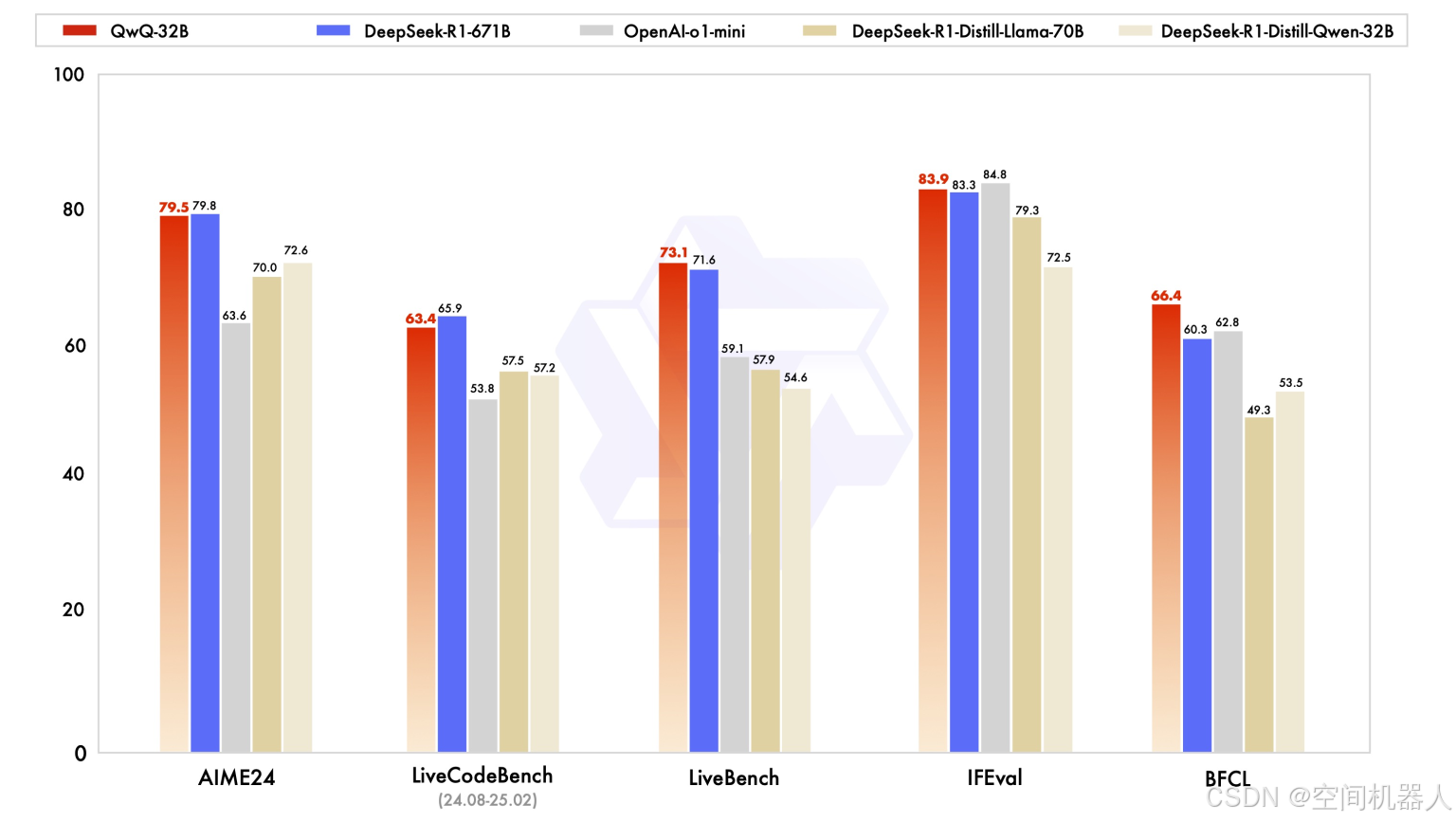
🧪 开源与部署:可以商用但源码尚未公开
- ✅ Hugging Face模型仓库
- ✅ ModelScope 模型库
- ✅ Apache 2.0 授权,可商用
- ❌ 未公布预训练语料与完整源代码
你可以直接部署到本地服务器、内网环境或云端集群,在隐私敏感场景(如金融、车载、医疗等)中具有明显优势。
🧭 总结观点:QwQ-32B的发布意味着什么?
- 国产推理模型已站稳前排:不是每个模型都能挑战 DeepSeek 和 OpenAI,但 QwQ-32B 确实做到了;
- 强化学习终于“上道”了:以结果为导向的训练方式表明,模型可以更靠近人类思维方式,而非仅靠死记硬背;
- 下一阶段,可能不是“谁更大”,而是“谁更聪明”:参数不再是一切,结构、训练方式与使用场景匹配才是关键。
📚 如果你是一名AI开发者、技术研究员或产品设计师,不妨下载 QwQ-32B 玩一玩,尝试让它解一道你做不出的数学题,说不定会让你大开眼界。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)