langchain入门笔记03:使用fastapi部署本地大模型后端接口,优化局域网内的问答响应速度
文章目录
前言
在上一篇博客中,尝试构建了多种mcp_server。接下来考虑,如何将我们的多mcp_server给前端提供api接口。
一、fastapi的简单入门
参考文献:https://www.bilibili.com/video/BV18F4m1K7N3
1:安装必要的包(python=3.11):
conda activate langchain
pip install fastapi
2:快速搭建一个fastapi:
文件目录如下图:
# 导入必要的模块
from fastapi import FastAPI # 导入 FastAPI 框架,用于构建 API
import uvicorn # 导入 Uvicorn,一个基于 asyncio 的 ASGI web 服务器,用于运行 FastAPI 应用
from fastapi import Request # 导入 Request 对象,用于获取请求的详细信息(如查询参数、请求体等)
from fastapi.staticfiles import StaticFiles # 用于挂载静态文件目录(如图片、CSS、JS 等)
from api.book import api_book # 导入图书相关的路由模块
from api.cbs import api_cbs # 导入出版社相关的路由模块
from api.zz import api_zz # 导入作者相关的路由模块
# 创建 FastAPI 应用实例
app = FastAPI()
# 挂载静态文件目录
# 将 "/upimg" 路径映射到本地 "upimg" 文件夹,允许用户通过 URL 访问该目录下的静态文件(如上传的图片)
# 例如:访问 http://127.0.0.1:8080/upimg/test.jpg 会返回 upimg/test.jpg 文件
# app.mount("/upimg", StaticFiles(directory="upimg"), name="upimg")
# 注册路由(API 子应用)
# 使用 include_router 将不同模块的 API 路由注册到主应用中,并设置统一前缀和标签(用于文档分类)
app.include_router(api_book, prefix="/book", tags=["图书接口"]) # 图书相关接口,路径前缀为 /book
app.include_router(api_cbs, prefix="/cbs", tags=["出版社接口"]) # 出版社相关接口,路径前缀为 /cbs
app.include_router(api_zz, prefix="/zz", tags=["作者接口"]) # 作者相关接口,路径前缀为 /zz
# 根路径接口,用于测试服务是否正常运行
@app.get("/")
async def root():
return {"message": "Hello World"}
# 自定义测试接口,返回固定消息
@app.get("/xixi")
async def xixi():
return {"message": "Hello xixi"}
# GET 请求测试接口
# 接收查询参数(query parameters),并打印到后端控制台
@app.get("/get_test")
async def get_test(request: Request):
get_test_message = request.query_params # 获取 URL 中的查询参数(如 ?name=abc&age=123)
print("收到 GET 请求参数:", get_test_message) # 打印参数到控制台
return {"message": "Hello xixi"}
# POST 请求测试接口
# 接收 JSON 格式的请求体(request body),并打印内容
@app.post("/post_test")
async def post_test(request: Request):
post_test_message = await request.json() # 异步读取请求体中的 JSON 数据
print("收到 POST 请求数据:", post_test_message) # 打印接收到的 JSON 数据
return {"message": "Hello xixi"}
# 主程序入口
# 当直接运行此脚本时,启动 Uvicorn 服务器
if __name__ == '__main__':
# 运行 FastAPI 应用
# 参数说明:
# "myfastapi:app" -> 模块名:应用实例名(即当前文件名为 myfastapi.py,app 是 FastAPI 实例)
# host="127.0.0.1" -> 绑定本地回环地址
# port=8080 -> 使用 8080 端口
# reload=True -> 开启热重载,代码修改后自动重启服务(适合开发环境)
uvicorn.run("myfastapi:app", host="127.0.0.1", port=8080, reload=True)
运行后可以浏览访问http://127.0.0.1:8080/docs查看接口文档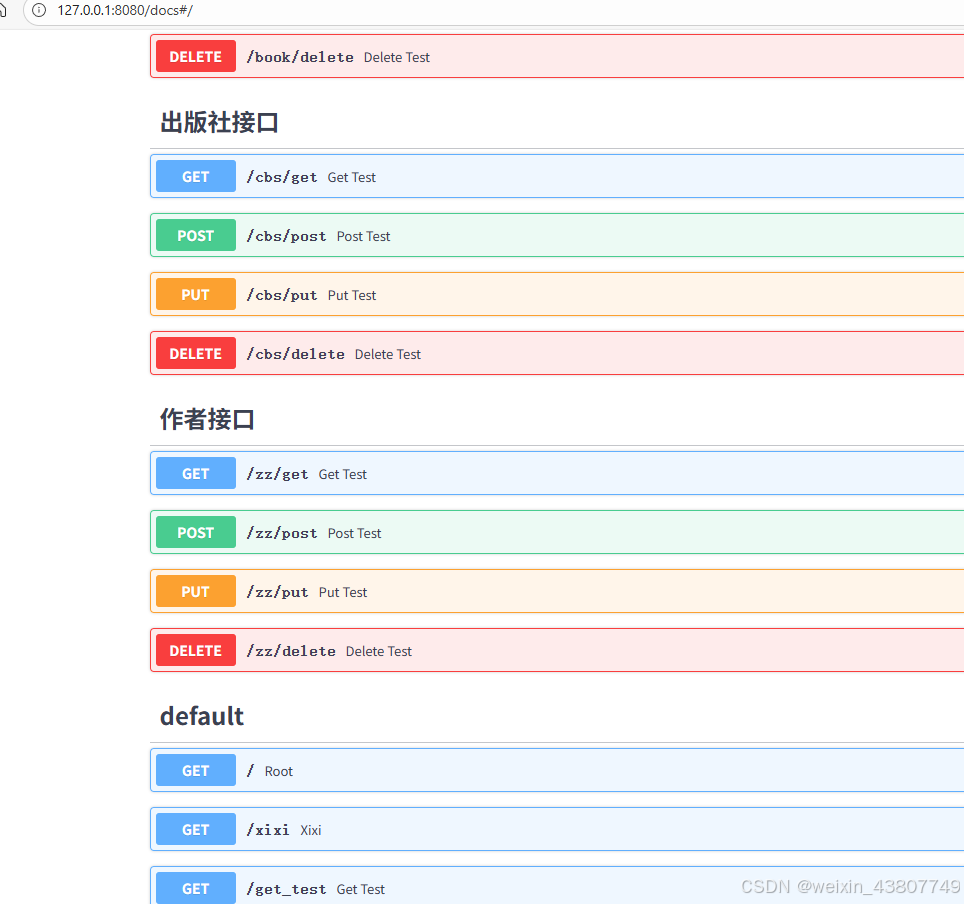
二、提升问答的响应速度
基于第一小节的fastapi,笔者搭建了一个chat接口,用于调用本地大模型。
1. fastapi部署后端接口,在局域网内访问的方法
首先把ip改为0.0.0.0,
if __name__ == '__main__':
# uvicorn.run("myfastapi2:app", host="127.0.0.1", port=8080, reload=True)
uvicorn.run("myfastapi2:app", host="0.0.0.0", port=8080, reload=True)
然后把本机的8080端口放开,具体操作,可参考博客,然后局域网内的其他主机就可以访问了: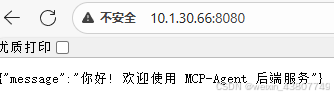
2. 局域网内的测试:“未来科技有限公司的差旅费标准”PDF的RAG问答:
PDF原文件部分截图如下: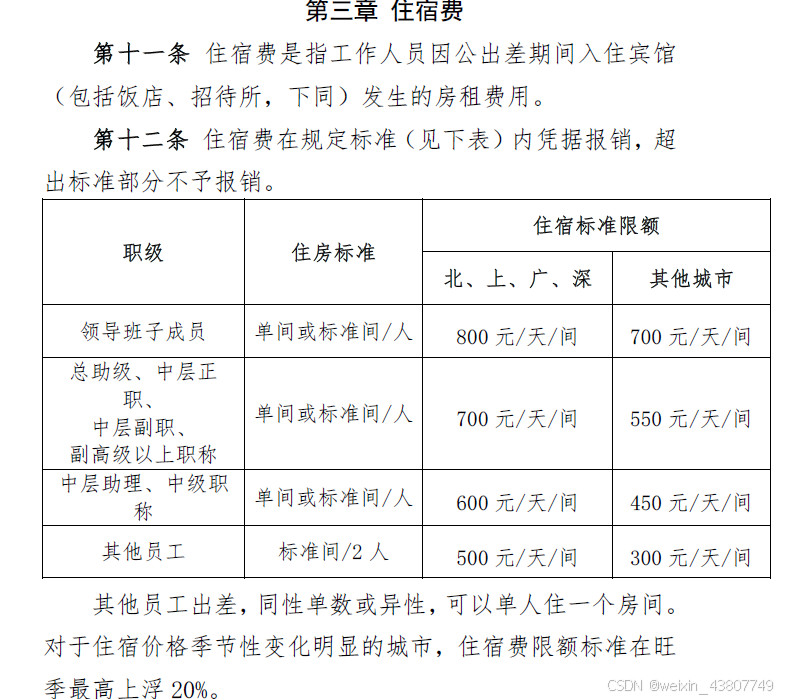
2.1 使用qwq32b模型(19GB)
在我的电脑上用postman测试下。结果还是比较准确的,对于这个文档,RAG的效果还是可以的。可以看到一次提问的响应时间是52.39s。模型需要的响应时间太长了,接下来考虑如何提速。这里使用的是qwq32b模型(19GB),因此考虑换一个更小的模型试一下。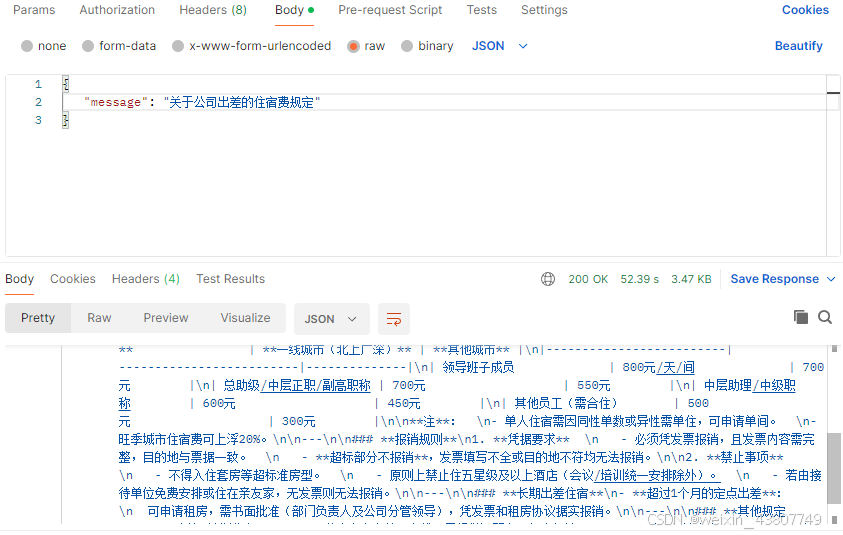
2.2 使用qwen3:8b模型(5.2GB),平均30s
这里使用qwen3:8b(5.2GB),使用相同的问题调用接口,结果如下。可以看到,看模型的输出结果,也是没有问题的,但是所需要的时间大幅度缩小,变为了26.55s。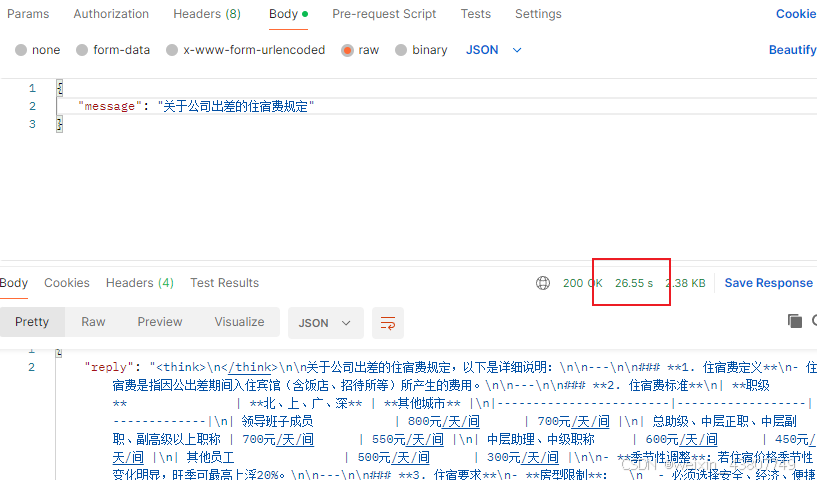
2.3 使用qwen3:8b模型(5.2GB),改进了rag_server的写法,,平均18s
通过chatgpt,进一步优化了rag_server,代码如下:
async def get_answer(question: str) -> str:
"""使用 RAG Chain 回答问题"""
try:
start = time.time()
context_text = await retriever.ainvoke(question.strip())
# LLM 调用
start_llm = time.time()
final_prompt = prompt.format(context=context_text, input=question)
response = await llm.ainvoke(final_prompt)
logger.info(f"🟢 LLM 生成完成,耗时: {time.time() - start_llm:.2f}s")
logger.info(f"✅ 总耗时: {time.time() - start:.2f}s")
return StrOutputParser().invoke(response)
except Exception as e:
logger.exception("❌ 问答过程中发生异常")
return f"问答过程中出错:{str(e)}"
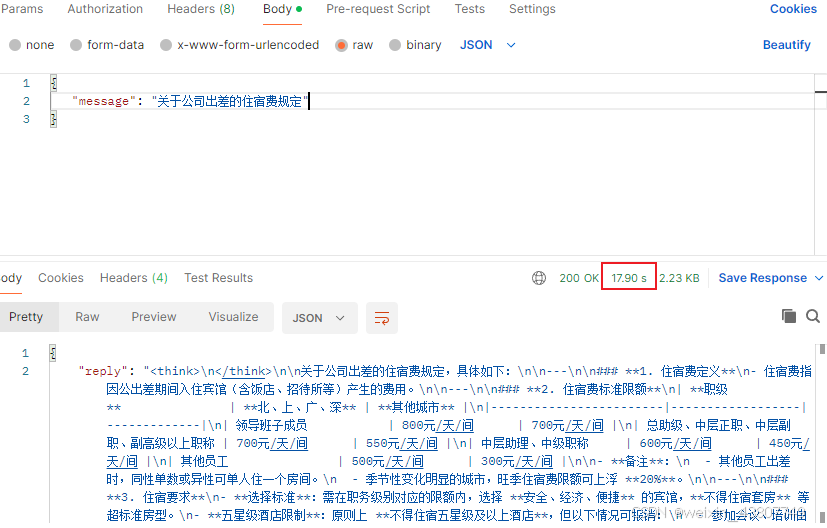
3. 如何进一步提速?
3.1 模型推理优化
(1) 使用更小的模型;(暂不采纳)
(2) 减少生成的token数;(暂不采纳)
LLM推理时间 = 上下文长度 + 输出长度;如果只是回答文档中的问题,不必生成很长的上下文,在 LangChain 调用时传:llm = ChatOllama(model="qwen3:8b", temperature=0, num_predict=200) num_predict默认是256???
让我们来试一下看看效果。设num_predict=200,时间数据表明,的确提速了!但是,答案被强制截断了,输出是不完整的,只输出了< think >中的内容。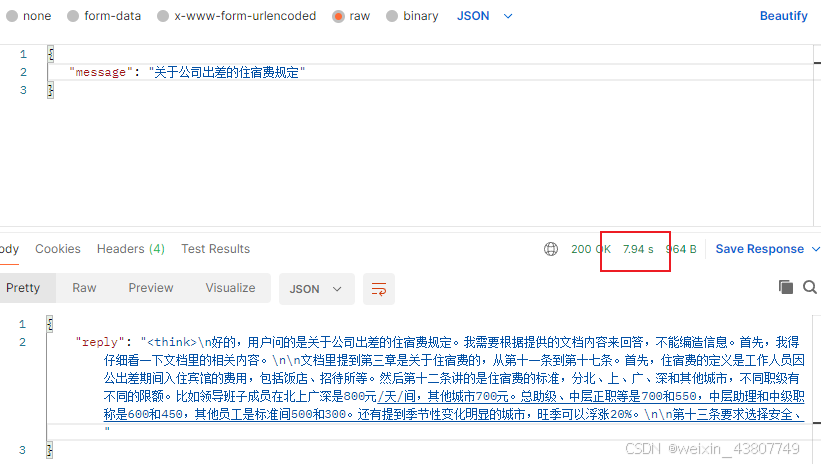
(3) 控制上下文窗口(prompt压缩)(暂不采纳)
(4) 将Ollama替换成vllm(有效)
cmd中查看Ollama,显示已经100%运行在GPU上了(燃尽了)
经同事的提醒,决定使用为vllm部署模型。安装教程可见视频教程:https://www.bilibili.com/video/BV1BijSzfEmQ/。
在wsl2安装linux,激活vllm虚拟环境,下载模型:
modelscope download --model Qwen/Qwen3-30B-A3B-Instruct-2507-FP8 --local_dir /mnt/d/scripts/python/myvllm/model/Qwen3-30B
Qwen3-30B-A3B-Instruct-2507-FP8(29GB)支持最长262144个token的上下文长度。使用双卡运行模型(四卡运行会报错):
export TORCH_CUDA_ARCH_LIST="8.9"
export CUDA_VISIBLE_DEVICES=1,2
vllm serve model/Qwen3-30B \
--tensor-parallel-size 2 \
--max-model-len 65536 \
--dtype bfloat16 \
--gpu-memory-utilization 0.90 \
--port 8090 \
--host 0.0.0.0 \
--enable-auto-tool-choice \
--tool-call-parser hermes \
--enable-chunked-prefill
实测效果如下,平均也是18s,不过这里使用的30B模型是比qwen:8b模型强很多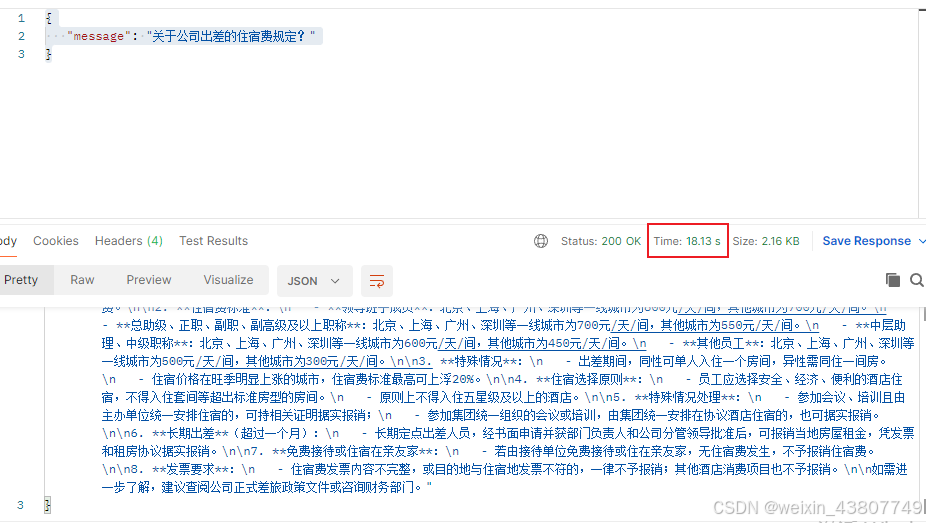
3.2 调用链路优化
(1) 流式输出(可行)
虽然从向量数据库中查询并提交给LLM的所花时间不可省略,但是最后给LLM所得到的输出可以流式输出,给人一种时间缩短的感觉。让前端边生成边显示,不用等 全部生成完才显示,LangChain 里可以改成:
@app.post("/chat")
async def general_chat_stream(request: Request):
start_total = time.time()
agents: dict = request.app.state.agents
agent_executor = agents.get("general")
if not agent_executor:
return JSONResponse(status_code=500, content={"error": "通用Agent未初始化"})
try:
data = await request.json()
user_input = data.get("message", "").strip()
if not user_input:
return JSONResponse(status_code=400, content={"error": "请输入有效消息"})
# 调用通用agent
input_data = {"input": user_input}
response_stream = stream_agent_response(agent_executor, input_data)
# 返回 StreamingResponse,指定媒体类型为 text/event-stream (用于 SSE) 或 text/plain
return StreamingResponse(response_stream, media_type="text/plain") # 或 "text/event-stream"
except Exception as e:
logging.error(f"通用聊天出错: {e}")
return JSONResponse(status_code=500, content={"error": str(e)})
在powershell中测试下流式响应的效果:
curl.exe -X POST -N http://10.1.1.199:1234/chat/rag -H "Content-Type: application/json" -d "@data.json"
data.json:
{"message": "关于公司出差的住宿费规定"}
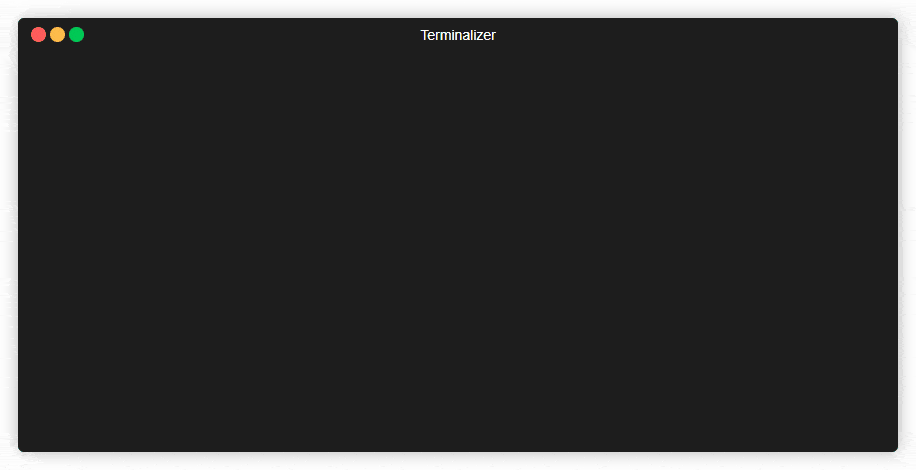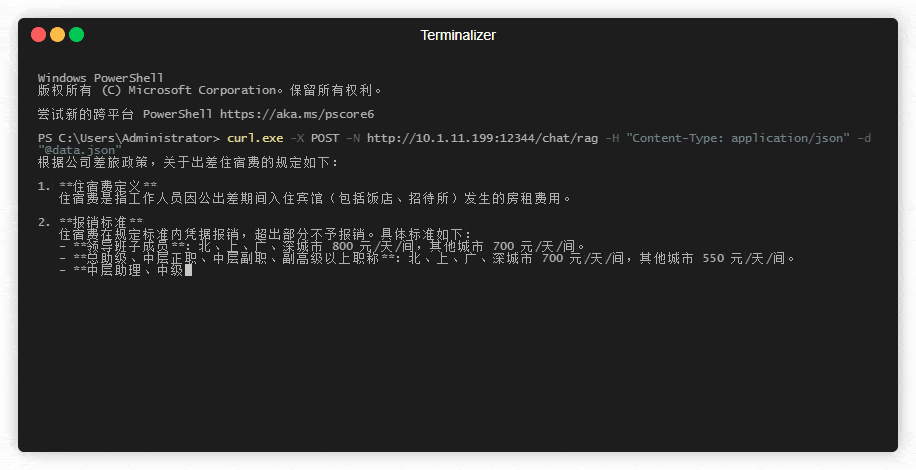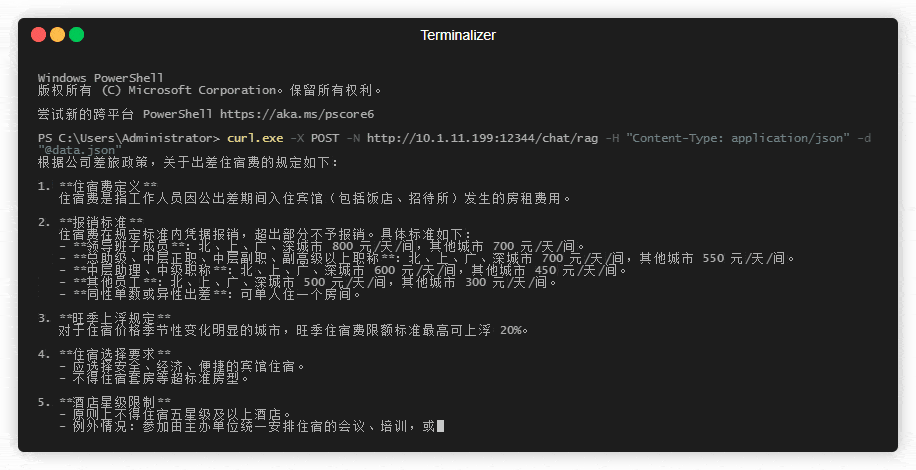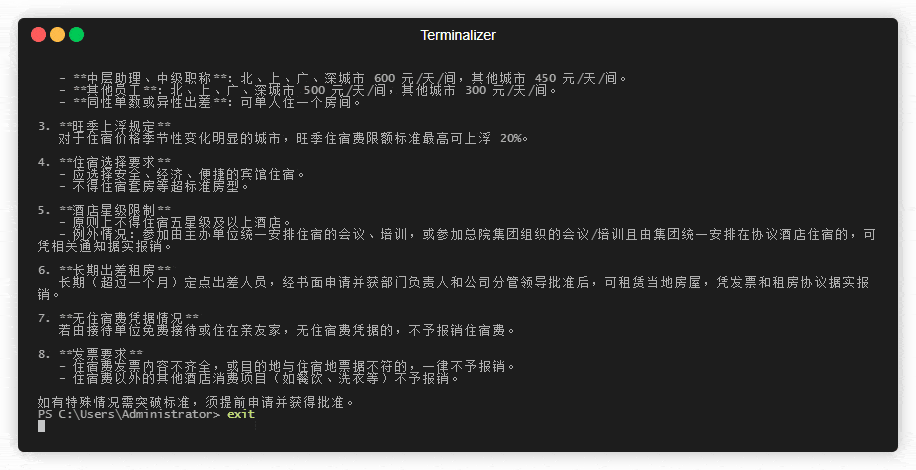
(2) 缓存相似查询(可以一试)
对相同 embedding 检索结果的 Prompt → LLM 输出做缓存;
Python 可以直接用 functools.lru_cache 或 Redis 做缓存

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 6
6 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)