大模型论文 | MaAS框架与“智能体超网” (Agentic Supernet)_multi-agent architecture search via agentic supern
在本文中,多智能体系统设计的范式从“寻找最优的单个系统”,转变为“优化一个系统的动态分布”。所提出的MaAS框架,通过其核心的“智能体超网”概念,实现了对不同任务的“量体裁衣”,在大幅提升资源效率的同时,取得了SOTA的性能表现。我们相信,MaAS为构建更通用、更经济、更智能的自动化AI系统铺平了道路。
最近,由多个AI智能体(Agent)协作完成复杂任务的“智能体社会”概念越来越火,从 AutoGen 到 MetaGPT,我们见证了“群聊”模式解决问题的强大潜力。
然而,在繁荣之下,一个“隐藏问题”逐渐浮现:我们精心设计的,或者用自动化方法找到的智能体团队,往往是一个 “一刀切”的重量级解决方案。譬如在AFlow或者ADAS这样的框架中,无论是简单的小学算术,还是复杂的物理难题,都用同一套“豪华阵容”来应对。
这种“大力出奇迹”的模式,可能导致两个“隐形痛点”:
- 资源浪费:简单任务根本不需要复杂的协作流程,导致大量的LLM调用和Token被白白浪费。
- 泛化难题:一个在A领域(比如网页搜索)表现优异的固定团队,换到B领域(比如文献总结)可能就“水土不服”,难以实现跨领域的最佳性能。
那么,如何打破这种僵局,让AI智能体团队学会“看菜下碟”,专事专办呢?为了解决上述挑战,来自新加坡国立大学、南洋理工大学等高校的团队提出了一种全新的自动化框架 MaAS (Multi-agent Architecture Search)。论文已被录用为ICML 2025 Oral。

论文: 【ICML 2025 Oral】**Multi-agent Architecture Search via Agentic Supernet (MaAS)**
链接: https://arxiv.org/abs/2502.04180
代码: https://github.com/bingreeky/MaAS
范式转换: MaAS框架与“智能体超网” (Agentic Supernet)
在这篇工作中,研究者们不再追求寻找一个“万能”的智能体系统,而是转变思路:构建并优化一个 “智能体超网”(Agentic Supernet)。
你可以把这个“超网”想象成一个经验丰富的“项目总监”。它内部包含了各种可能的工作流(由CoT、ReAct、Debate等基础智能体算子组成),而不是一个固定的团队。当一个新任务(Query)到来时,这位“总监”会:
- 评估任务:快速分析任务的类型、难度和特点。
- 动态组队:从“超网”中即时采样、组合出一个量身定制、恰到好处的智能体团队(工作流)。
- 高效执行:用最精简的团队、最合理的流程来解决问题。
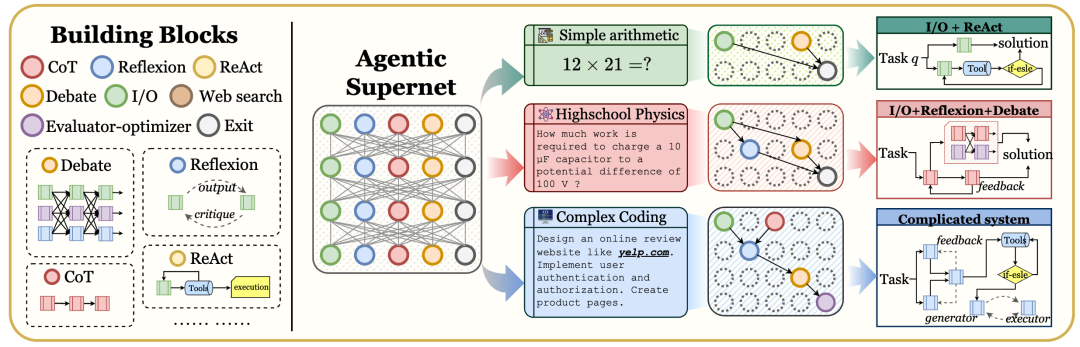
图1:MaAS框架总览。左侧是智能体“工具箱”,右侧展示了“超网”如何根据不同任务(简单算术 vs 高中物理 vs 复杂编码)动态采样出不同的解决方案。
通过这种方式,MaAS实现了从“静态重团队”到“动态轻组合”的范式转变,真正让智能体协作变得智能、高效且经济。
技术探秘:MaAS是如何工作的?
MaAS框架的“智能”并非魔法,而是一套设计精巧、环环相扣的机制。我们可以将其核心工作流拆解为三大步骤:构建“可能性宇宙”、“看菜下碟”式采样、以及 “自我进化”式优化。
第1步:构建智能体超网 (Agentic Supernet)
想象一下,我们不是去设计一辆固定的“汽车”,而是建造一个巨大的、模块化的“超级底盘”(Supernet)。这个底盘上预留了所有可能的接口,可以安装任何型号的引擎(大语言模型)、任何类型的工具(计算器、搜索引擎)、以及任何驾驶策略(智能体算子,如CoT、ReAct、Debate)。
这个“超级底盘”就是我们的智能体超网。它是一个多层的概率图,包含了我们预定义的所有智能体算子。它本身不执行任务,而是代表了解决一个问题的所有潜在路径的集合。
第2步:查询依赖的动态采样
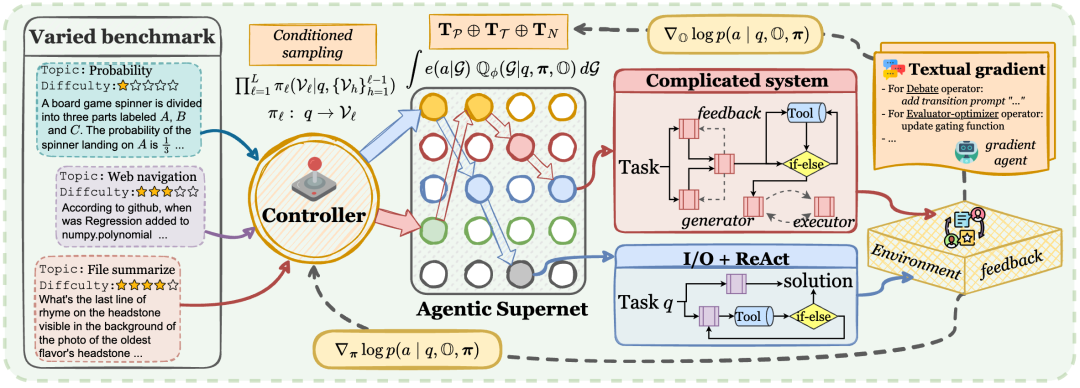
这是MaAS最核心的智慧所在。当一个任务(Query)到来时,一个轻量级的**“总调度师”(Controller Network)**会立即介入。它会实时分析任务,然后从庞大的“超网”中,动态地构建出一条最优、最经济的执行路径。
让我们通过两个具体案例来看看它是如何工作的:
案例一:简单计算任务
-
输入查询 (Query):
"计算 42! (42的阶乘) 末尾有多少个零?" -
调度师分析: “调度师”通过对查询文本的理解,迅速识别出这是一个定义明确、有固定解法的数学计算题。它不需要复杂的网络搜索或多方辩论。
-
路径采样过程:
-
- 第1层 (Layer 1): “调度师”会给那些最直接、最高效的算子打高分。比如,它会大力推荐
ReAct算子,并为其配备一个代码解释器工具,因为执行一段简单的Python代码就能完美解决这个问题。同时,I/O(直接输出)也获得了一定的分数。而像Debate(辩论)这种重量级算子,则几乎不会被考虑。 - 第2层 (Layer 2): 由于第1层的
ReAct已经得出了正确答案(通过计算因子5的数量),任务已经完成。“调度师”在这一层会极大地提高Early-Exit(提前退出)算子的被选中概率(例如,概率高达 47%)。
- 第1层 (Layer 1): “调度师”会给那些最直接、最高效的算子打高分。比如,它会大力推荐
-
最终路径:
Query→ReAct(with_Code_Interpreter)→Early-Exit→Solution。 -
结果: MaAS用一个极短、高效的路径解决了问题,只进行了一次核心的工具调用,避免了不必要的资源浪费。
案例二:复杂研究任务
-
输入查询 (Query):
"根据维基百科,在2021年,亚洲有哪些国家既保留了君主制,又拥有海岸线?" -
调度师分析: “调度师”识别出这是一个复杂的研究型任务,需要:①信息检索(哪些是亚洲国家、哪些是君主制国家),②信息交叉验证(同时满足三个条件),③综合整理。
-
路径采样过程:
-
- 第1层 (Layer 1): 这次,“调度师”会优先选择具备探索能力的算子。
ReAct算子再次被选中,但这次配备的是Web Search(网络搜索)工具。它可能会启动多个并行的搜索任务。 - 第2层 (Layer 2): 搜索结果回来了,但可能包含一些错误或矛盾的信息(比如,某个内陆国被误标为有海岸线)。此时,“调度师”会给整合与批判性思维的算子打高分。比如,它会激活
Debate算子,让两个独立的智能体分别基于搜索结果进行论证和反驳,以去伪存真。同时,Refine(精炼)算子也会被激活,用于整理初步的候选名单。Early-Exit的概率会非常低。 - 第3层 (Layer 3): 经过辩论和初步精炼,一个比较可靠的国家列表形成了。最后,“调度师”可能会调用一个
Summarize(总结)算子,将最终结果整理成清晰、格式化的文本。
- 第1层 (Layer 1): 这次,“调度师”会优先选择具备探索能力的算子。
-
最终路径: 一个长而复杂的路径,如
Query→ReAct(Web_Search)→Debate→Refine→Summarize→Solution。 -
结果: MaAS构建了一个强大的研究团队来应对复杂挑战。虽然成本更高,但它确保了答案的准确性和全面性,实现了“好钢用在刀刃上”。
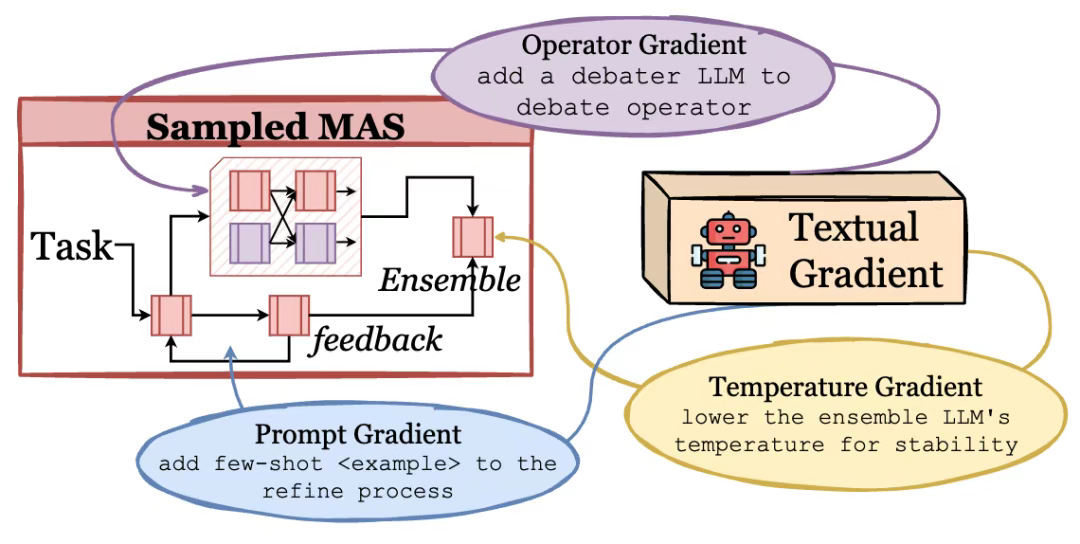
第3步:联合优化与文本梯度
MaAS不仅会“用”,更会“学”。在每次任务执行后,它都会根据结果的正确性和过程的成本进行复盘和优化。
- 优化“调度师” (Controller): 如果一条路径(比如案例一中的短路径)以低成本获得了高分答案,那么“调度师”就会得到正向激励。下次遇到类似的简单任务时,它选择这条短路径的概率就会更高。这就像是在训练“调度师”的“直觉”。
- 优化“工具箱” (Operators) - 文本梯度 (Textual Gradient): 如果一个算子(比如某个
CoT的Prompt)在任务中表现不佳,我们不是简单地弃用它,而是让AI来“修复”AI。
- 一个“梯度智能体”会审查失败的执行过程。
- 它会生成一段“优化指令”,这就是所谓的“文本梯度”。比如:“你在进行多步推理时,逻辑跳跃太快,导致结论错误。你应该在Prompt中加入一个要求,强制模型先列出所有已知条件,再进行推导。”
- 这段文本指令会被自动应用,去更新那个表现不佳的
CoT算子的Prompt。 - 通过这种方式,我们的“工具”本身也在不断地迭代和进化,变得越来越强大和可靠。
总结来说,MaAS就像一个能自我学习的“项目管理大脑”,它不仅能为每个任务动态组建最合适的团队,还能在实践中不断培训团队成员、优化工作流程,最终实现效率与效果的完美平衡。
实验解析:性能与成本的双重优化
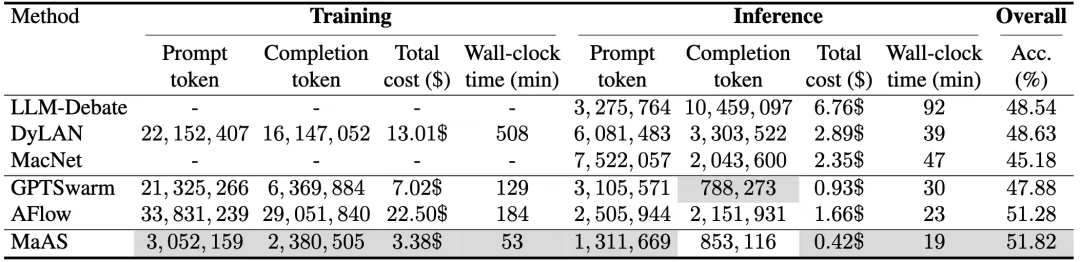
MaAS在数学、代码、工具使用等6个主流基准测试上进行了全面评估。相比于现有SOTA方法,MaAS不仅在各项任务上取得了最优的平均性能(83.59%),更在资源效率上展现了惊人的优势。
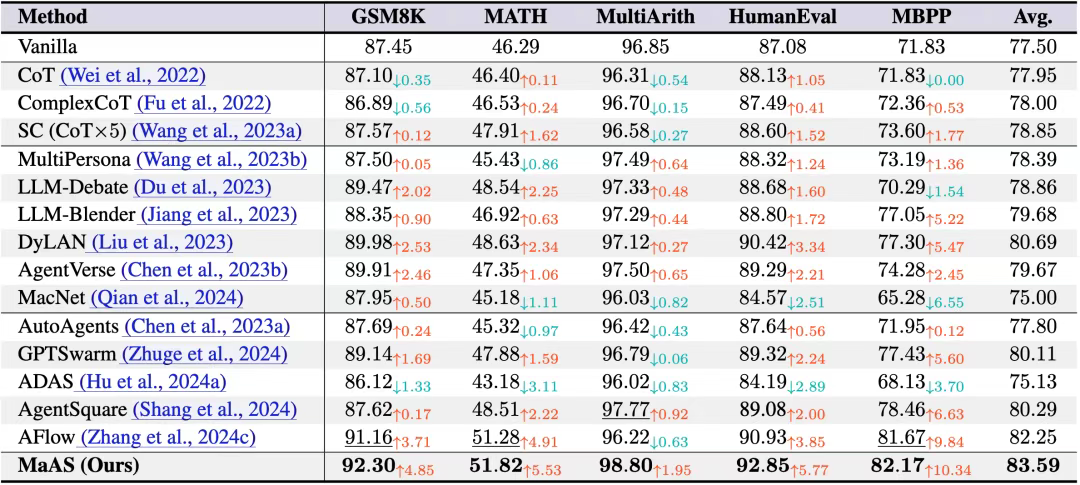
在最具挑战的MATH基准上,与强大的基线方法AFlow相比,MaAS的训练成本仅为其15%,推理成本更是低至其25%,最终推理API开销仅为 $0.42!
MaAS最智能的地方在于,它能根据任务难度自适应地调整策略。
- 面对简单任务:如下图(a)和(b),当遇到简单的数学问题时,MaAS会大概率在第二层就选择
Early-exit算子,提前终止复杂的流程,用最简单的I/O或ReAct快速给出答案,概率高达37%和47%。 - 面对复杂任务:而当遇到难题时(图d),MaAS则会=调用更多层的、更复杂的算子组合(如Ensemble、Refine)来确保解题的准确性,并且几乎不会提前退出。
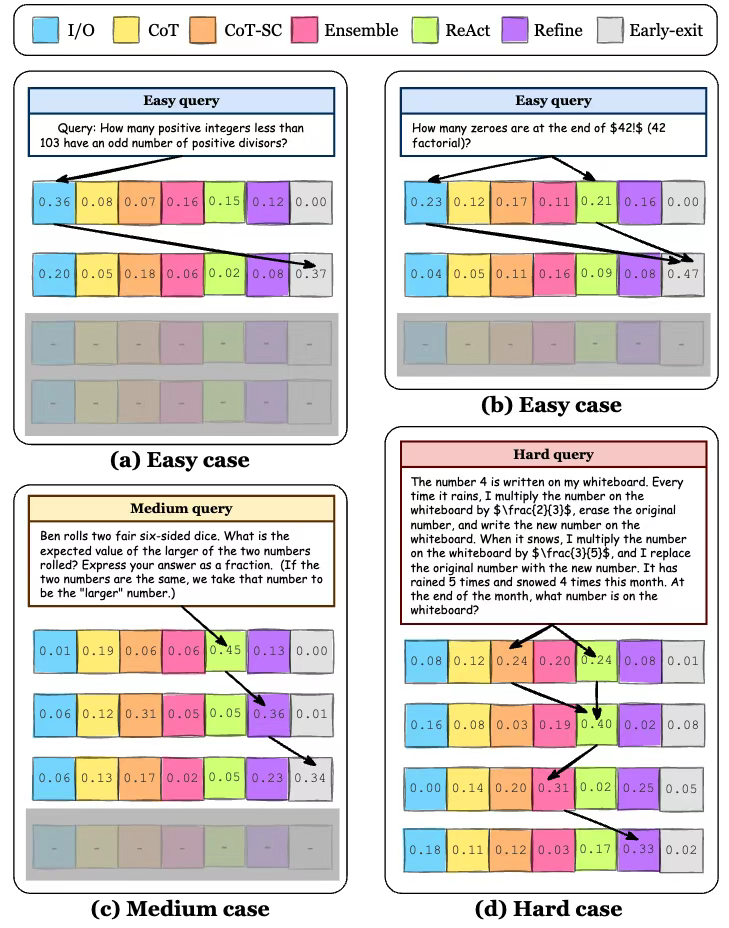
这种查询感知的动态资源分配能力,正是MaAS能够兼顾性能与效率的核心原因。
总结与展望
在本文中,多智能体系统设计的范式从“寻找最优的单个系统”,转变为“优化一个系统的动态分布”。所提出的MaAS框架,通过其核心的“智能体超网”概念,实现了对不同任务的“量体裁衣”,在大幅提升资源效率的同时,取得了SOTA的性能表现。我们相信,MaAS为构建更通用、更经济、更智能的自动化AI系统铺平了道路。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 18
18 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)